
基于CNN的监控视频事件检测
2016-08-22 09:55王梦来李想陈奇李澜博赵衍运
自动化学报 2016年6期
王梦来 李想 陈奇 李澜博 赵衍运
基于CNN的监控视频事件检测
王梦来1李想1陈奇1李澜博1赵衍运1
复杂监控视频中事件检测是一个具有挑战性的难题,而TRECVID-SED评测使用的数据集取自机场的实际监控视频,以高难度著称.针对TRECVID-SED评测集,提出了一种基于卷积神经网络(Convolutional neural network,CNN)级联网络和轨迹分析的监控视频事件检测综合方案.在该方案中,引入级联CNN网络在拥挤场景中准确地检测行人,为跟踪行人奠定了基础;采用CNN网络检测具有关键姿态的个体事件,引入轨迹分析方法检测群体事件.该方案在国际评测中取得了很好的评测排名:在6个事件检测的评测中,3个事件检测排名第一.
卷积神经网络,事件检测,行人检测,目标跟踪,轨迹分析
引用格式王梦来,李想,陈奇,李澜博,赵衍运.基于CNN的监控视频事件检测.自动化学报,2016,42(6):892-903
随着监控设备的发展与普及,研发监控视频事件检测(Surveillance event detection,SED)技术具有重要意义.TREC(Text Retrieval Conference)[1]由美国国家标准技术研究院(National Institute of Standards and Technology,NIST)[2]主办,是文本检索领域最权威的评测会议.2001年,NIST设立视频检索(TREC video retrieval evaluation,TRECVID[3])专项测评任务,每年举行一次;2008年,为带动世界上各高校、研究院所和企业对智能监控系统的研究,TRECVID加入了SED任务.SED项目数据采集自英国伦敦盖特威克国际机场的实际监控视频,视频长度为144小时.由于机场监控视频中背景环境复杂、人群密度大、人与人之间的遮挡严重、场景内光照变化等干扰因素的存在,SED评测的数据库以高难度著称,在此数据库上进行事件检测极具挑战性.
本文结构安排如下:第1节叙述相关研究内容;第2节提出头肩部检测深度级联网络(Headshoulder networks,HsNet)行人检测方法;第3节改进跟踪算法;第4节描述基于姿态的事件检测方案;第5节介绍基于轨迹分析的事件检测方案;第6节给出实验结果及分析;第7节为本文结论.
1 相关研究
监控视频事件检测,主要关注的对象是其中的行人的行为,因而行人检测与跟踪技术就成为能否有效实现事件检测的关键基础.
尽管在一些公开库上行人检测已经取得了很好的成果[4-5],例如,HOG[6]、DPM[7]等,充分利用了人体的轮廓信息,取得了很不错的检测效果,但遮挡等因素对行人的轮廓信息存在较大干扰,进而降低了这类方法的检测性能.深度学习技术,例如卷积神经网络(Convolutional neural networks,CNNs)[8-11]能够自动学习行人检测中具有鉴别力的特征,在非拥挤的场景下,对存在部分遮挡的行人检测,比人工设计特征更具鲁棒性;但拥挤场景下的实际监控视频,行人遮挡严重(例如人体2/3被遮挡),行人检测方法的性能仍然是亟待提高的.
近年来,受益于行人检测技术的不断发展,基于检测的跟踪方法逐渐成为对象跟踪的主流方法,文献[12]提出的分层多目标跟踪算法,对跟踪问题的模型描述和优化求解都给出了很好的解决方案;文献[13]在此基础上,增加了非线性运动模式及对象外观模型在线学习的策略,在复杂的SED数据集上取得了较好的跟踪效果.视频事件分析,涉及对象的动作、行为识别.目前,在一些视频动作识别公开库中,如UCF-101[14]、HMDB-51[15]等,研究者们已经取得了比较好的成果.例如,文献[16]将多个连续帧送入CNN网络,逐层融合以提取时域信息,将UCF-101上的识别准确率从43.9%提高到了63.3%;文献[17]通过将时域的光流信息和空域的姿态信息融合,将HMDB-51上的准确率从57.2%提高到了59.4%.然而,由于SED数据集行人密度大、遮挡严重,使用这些方法也难取得好的检测结果.
TRECVID评测[18]的SED任务,包含7个事件检测,分别是指(Pointing)、拥抱(Embrace)、放东西(ObjectPut)、跑(PersonRuns)、打电话(Cell-ToEar)、人员分离(PeopleSplitUp)及人员聚集(PeopleMeet).根据事件涉及人数,我们将前5个事件归类为个体事件1尽管拥抱(Embrace)是多人事件,但是它和其他单体事件一样具有很明显的关键姿态.同时,在事件发生时,拥抱的行人也可以作为一个整体来考虑,而且拥抱与分离、聚合等其他群体事件具有较明显差异,为行文方便,将其分在个体事件检测一类.,后两个事件归类为群体事件.在TRECVID-SED2015评测中,我们提交了除CellToEar之外的其余6个事件的检测结果,所以本文的方案也只涉及这6种事件的检测.
TRECVID-SED评测,自举办以来,已吸引若干国际国内知名研究机构和院校参加,其中评测结果排名一直比较靠前的是卡耐基梅隆大学的参赛队(CMU)[19],2014年IBM也提交了不错的结果[20].CMU采用方法的框架结构是对标注的训练视频,按照滑动窗口,提取窗口视频段的描述特征,例如STIP[21]、MoSIFT[22]等,并对特征进行编码(Fisher vector);用编码后的特征训练SVM分类模型或者随机森林分类模型;测试时也采用滑动窗口的方式截取视频并提取特征,送入分类模型检测相关事件.该结构的优点是,鉴于SED视频的复杂性,按照特征点提取特征描述事件,很好地回避了拥挤人群无法进行精细人员检测与跟踪的困境.其不足之处在于,需要检测的事件是在真实的四维时空内发生的,在采集监控视频时已经丢失了一维空间信息,在此基础上仅提取局部特征点相关特征又继续丢失了大量信息,更何况不易确定这些特征点来自哪个具体对象,例如,也可能来自未参与事件的行人,这就使得所提取特征信息不仅有损,而且被噪声严重干扰,难以准确描述真实四维空间的事件.虽然TRECVID-SED的参加团队,都是在计算机视觉领域有多年研究经验的团队,但SED评测中的事件检测结果还不够好,检测指标尚有很大的提升空间.
我们提出的SED事件检测方案,正是认识到这种基于特征点方法的不足,并认为在尽可能准确检测和跟踪行人的基础上,进行更高层次的分析,才是解决这类复杂视频问题的合理方案;在研究行人检测过程中,因CNN的优异性能,启发我们提出了使用CNN网络检测具有关键姿态的个体事件.本文的主要贡献是:
1)对固定摄像机拍摄的拥挤场景监控视频分析问题,提出了CNN级联网络检测行人头肩部代替检测行人整体的方法,既利用了CNN自动提取鲁棒特征的优势,也较好地解决了遮挡问题,检测速度也较快;
2)提出了用CNN网络检测具有关键姿态的个体事件的方法,充分利用了CNN对二维形状强大的描述能力,将复杂的四维事件检测问题,在二维空间找到解决方法;
3)提出了用轨迹分析检测群体事件的方案,实质上是分层次解决事件检测这一复杂视觉问题;
4)将高斯过程回归引入跟踪轨迹参数方程拟合,使得我们可以描述任意运动形式的轨迹,提高了跟踪算法的准确性,也为轨迹分析提供了更为准确的轨迹数据.
2 行人检测
视频事件的行为主体是场景中的行人对象,所以检测场景中的行人是最重要的基础;基于行人检测的结果,可以进一步检测个体事件和群体事件.
如前所述,在SED数据集上进行行人检测是极富挑战性的,人员拥挤致使行人彼此遮挡严重;当穿过场景时,行人身上的光照变化较大,造成其外观模型随之变化;这些都是行人检测中遭遇的难点.分析SED视频数据集,其摄像机位置固定,且高于人群,这就使得行人遮挡多发生在人体除头肩之下的区域,也即行人头肩被遮挡的概率很小,所以检测行人头肩区域代替检测行人全身对于解决SED数据集中严重的遮挡问题,无疑是一个很好的选择;但由于头肩区域的所包含的行人信息比整个行人区域所包含的信息少,这就可能造成更多的误检,例如,一个上小下大的吊灯,其平面轮廓与人的头肩区域颇为相似,所以如何设计鲁棒的头肩检测子是准确检测行人的关键.
CNN[8-10]是近期计算机视觉领域最热门的研究焦点,其在对象检测与识别[23]、图像分类[24]等方面都显现了极大的潜力;鉴于CNN的良好性能及SED数据集特点,我们尝试在SED数据集上使用CNN检测行人的头肩部,以此实现检测行人的目的.为此,我们提出了一种基于CNN的头肩检测深度级联网络(HsNet).
2.1网络结构
为了得到更好的头肩部表达特征,引入CNN自动提取头肩部特征;而为了提高头肩区域的检测速度,我们提出一种三级的CNN级联结构检测框架,利用第一级CNN去掉大量明显的负样本,利用第三级对比较困难的负样本进行更好的分类鉴别.
头肩检测深度级联网络(HsNet)由三级CNN网络构成,每级的CNN都使用Caffe工具箱实现[25],整个级联网络框架结构如图1所示.框架包含三级,第一级(s1-net)是一个很浅的二分类网络,只包含一个卷积层和Softmax分类器,用于剔除大量明显的负样本,同时保证正样本的通过率.实验设计,在保持99.5%的召回率前提下,第一级能够剔除77%的负样本.
第二级(s2-net)是一个二分类的中间级,目标是进一步剔除负样本.如图1所示,s2-net由两个卷积层以及一个Softmax分类器组成,网络复杂度比第一级略高,更具区分力,在保持99.5%召回率的情况下,能够进一步剔除44%的负样本.
由于绝大多数的负样本已经被前两级很快地剔除了,所以最后一级可以采用一个更复杂的网络.鉴于Cifar-10网络[11]在一般场景中检测行人的良好效果[10],HsNet最后一级(s3-net)我们直接采用Cifar-10网络.
第三级复杂的网络结构,能够更好地鉴别困难的负样本;同时因为前两级已经剔除了大量的简单负样本,与单独使用Cifar-10网络相比,HsNet结构检测头肩框耗时更少.级联CNN使我们获得了更好的检测性能和更快的检测速度.
2.2检测过程
基于HsNet的行人检测过程:1)对检测视频的每一帧图像,用多尺度的滑窗按照预定步长截取一系列的候选小图像块(Patch),形成待识别样本;2)将这些样本送入预先训练好的头肩/非头肩识别模型HsNet(三级CNN级联网络)进行分类,在网络的每一级被分类为负的样本的Patch直接舍弃,其余样本继续进入网络的下一级进行更严格的识别分类,如此经过三级CNN网络进行分类鉴别;3)网络第三级的输出结果用于判断图像Patch是否属于头肩区域,该区域的矩形框被称为头肩框,将头肩框高度扩展为原对应滑动窗口的3倍,得到行人检测的全身框;4)由于采用多尺度的滑动窗口检测头肩区域,对于同一个行人,会形成多个检测框,最后用非极大值抑制策略剔除多余的检测框,每个位置只保留最可能的一个检测框—行人检测结果.
HsNet网络模型对拥挤造成的行人遮挡和光照变化等干扰具有很好的鲁棒性,其级联结构不仅提高了行人检测准确率,也提高了行人检测速度.
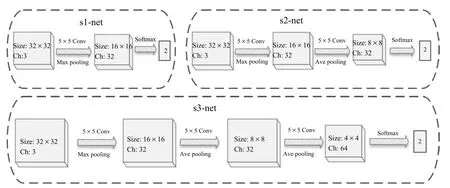
图1 头肩检测的级联深度网络(HsNet)结构[26]Fig.1 The architecture of the CNN cascade for head-shoulder detection[26]
3 行人跟踪
本文提出的事件检测方案分为基于姿态的个体事件检测和基于轨迹分析的群体事件检测,行人跟踪是实现轨迹分析方案的重要环节.鉴于SED数据库的复杂性及文献[12-13]跟踪算法的良好效果,我们基于HsNet的头肩部检测结果,实现了此跟踪算法[27],基于跟踪和轨迹分析,检测SED群体事件.
文献[12]提出了一种基于检测的分层关联多目标跟踪方法,取得了较好的跟踪效果,文献[13]在此基础之上,引入非线性运动模式学习及在线外观模型学习策略,改进了这一分层多目标跟踪算法,其框架结构如图2所示.算法第一层对检测对象进行底层可信关联,形成轨迹片段;第二层利用非线性运动模式在线学习和外观模型多实例学习,对轨迹片段进行有效连接,得到可靠的对象轨迹.
文献[13]使用的行人检测子检测行人整体,而我们为了避免遮挡问题,仅仅检测行人的头肩部分区域代替行人整体;由于头肩区域较小,且采用多尺度滑动窗口的对象检测策略,同一对象的头肩区域在不同帧中位置跳变不可避免,这将影响对象轨迹片段速度的计算,进而影响高层关联中运动关系估计,使同一对象的不同轨迹片段因速度计算误差,导致无法正确关联.为解决此问题,我们将高斯过程回归(Gaussian process regression,GPR)引入跟踪过程,通过GPR,平滑对象轨迹片段,解决不同帧对象头肩部区域位置跳变问题.GPR是采用贝叶斯方法的非线性回归,其训练过程简单,所用的核函数的选择范围较大,因此在机器学习领域倍受重视.
以概率形式描述的GPR预测模型[28]
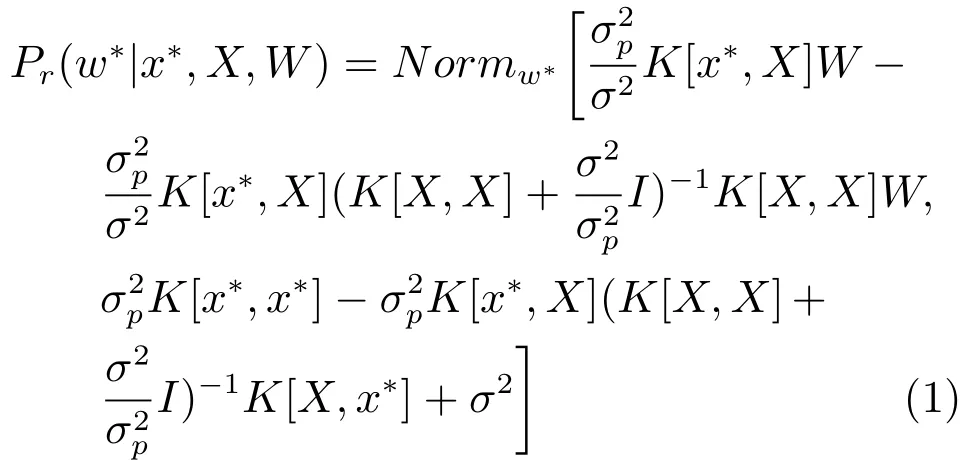
式中,x∗为测试样本特征(D维向量),w∗为测试样本状态(标量);为训练样本特征集,为训练样本状态集;σ2为状态w正态分布模型的方差,训练时采用一维搜索可以得到;为参数先验分布的方差,可以设定为一个较大的值,以弥补先验知识的不足;I为单位矩阵;K[·,·]为核函数,我们选择径向基(Radial basis function,RBF)核函数
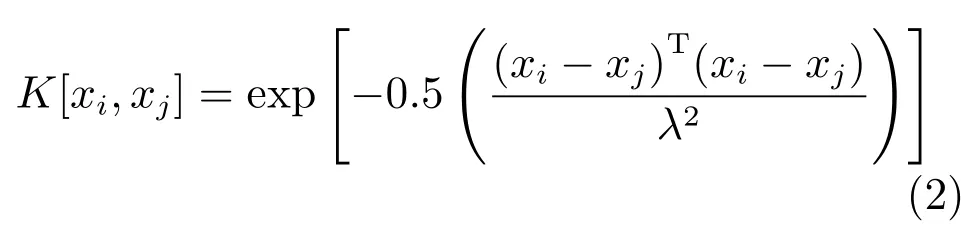
参数λ可以通过最大化边缘似然学习得到
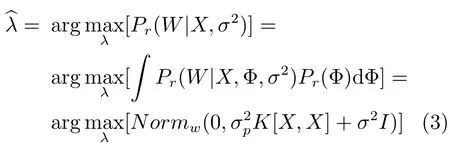
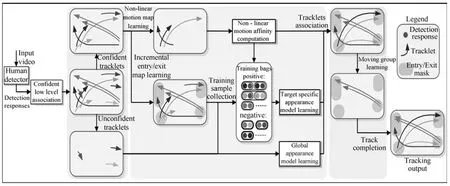
图2 在线学习非线性运动模式及鲁棒外观模型的多目标跟踪算法框图[13]Fig.2 The block diagram of multi-target tracking by online learning of non-linear motion patterns and robust appearance models[13]
式中,Φ=[φ1,φ2,···,φD]T为状态模型梯度参数.测试样本的状态w∗的预测值为式(1)中正态分布的均值.
底层跟踪得到对象轨迹片段,此处我们以底层片段平滑为例,说明高斯过程回归的使用.将对象头肩检测响应记为ri=(xi,yi,wi,hi,t,ci),ri表示第t帧的第i个检测响应,(xi,yi)、wi和hi分别表示该检测框的中心位置、宽度和高度,t为视频帧号,ci为检测框的置信度.
在对象底层跟踪过程中,为使同一对象在不同帧中的位置(xi,yi)平滑变化,我们采用GPR预测检测框位置.位置坐标间关系可以表示为
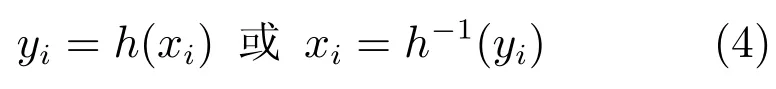
式中,函数h(·)即为需要使用GPR拟合的函数,h-1(·)为其反函数.由于像素点坐标的离散性,若直接拟合xi与yi的关系,需要区分对象运动方向分段拟合h(xi)或h-1(yi)函数,而在进行检测响应关联时,对象运动方向是未知的,为此,我们提出将(xi,yi)用参数方程进行拟合.
将xi和yi写成帧号t的参数方程,则有
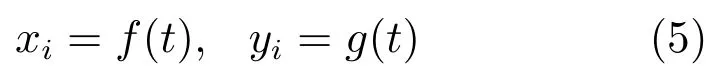
式中,f(t)和g(t)为待拟合的函数.
底层跟踪时,考虑从时刻t+1到t+N共N帧内对象i的检测响应的拟合问题,将两组数据作为GPR方法的训练样本(tn,xin,yin分别表示第t+n帧、第i个对象在第t+n个检测响应的x及y坐标),可以得到式(5)中函数f和g的参数;基于此拟合函数,计算得到对象i在N帧中平滑的运动轨迹片段.
平滑的轨迹片段,可以较准确地计算对象运动的速度,为高层对象关联奠定基础.将检测框位置(xi,yi)按照参数方程进行GPR拟合,不需要已知对象运动方向,这也是本文的一个独到之处.
我们从如下几点将GPR用于改进文献[13]算法:1)底层关联时用GPR拟合头肩检测响应,以得到平滑的轨迹片段;2)高层关联时,用GPR拟合非线性运动模式,比原方法中使用二次函数表示非线性运动模式更合理,因为对象运动轨迹在二维图像上的曲线不一定符合二次函数型,GPR对需要拟合的运动模式没有任何限制;3)对最终融合后的轨迹进行高斯过程拟合,得到完整光滑的行人运动轨迹,为后续基于轨迹分析检测群体事件奠定基础.
4 基于姿态的事件检测
在监控视频中,有很大一类事件具有明显的区别于其他事件的动作或者姿态,我们称为关键姿态(Key-pose),如图3和图4所示的Pointing、Embrace、ObjectPut和PersonRuns事件样本示例.我们将这类事件的检测转化为对图像帧中关键姿态的检测.下面以SED评测中几个具有关键姿态的事件为例说明基于姿态的事件检测过程.

图3 Pointing和Embrace事件样本截图Fig.3 Samples of Pointing and Embrace

图4 ObjectPut和PersonRuns事件样本截图Fig.4 Samples of ObjectPut and PersonRuns
4.1Pointing和Embrace事件
Pointing事件检测,是在视频中检测发生“指”这一动作的视频片段;而Embrace事件检测则是要检测出发生“拥抱”动作的视频片段.观察发现,当这样的事件发生时,图像帧中都对应着很明显的关键姿态(Key-pose),如图3所示的样本示例,所以我们将这两类事件的检测转化为对图像帧中关键姿态的检测.类似地,我们采用与HsNet相同的网络架构来训练这两类关键姿态检测的CNN模型.
在检测这两种事件时,为了节省时间,不再用逐帧滑窗的检测方式,而是直接将前述行人检测结果的头肩框扩展1.5倍之后截取候选图像块,分别输入两种关键姿态检测CNN模型,由模型进行鉴别分类,识别关键姿态.对每一种关键姿态检测结果,根据位置和时间相关性进行平滑滤波,得到相应事件发生的视频片段.
4.2ObjectPut和PersonRuns事件
ObjectPut事件检测,是在视频中检测“放东西过程”的视频片段;而PersonRuns事件检测,是检测行人在场景内跑步的视频片段;这两种事件样本的截图如图4所示,图4(a)是放东西事件样本,图4(b)为跑步事件样本.从人的整体观测,ObjectPut 和PersonRuns事件也具有区别于其他行人姿态的关键姿态,我们同样采取CNN来捕捉这样的关键信息.与Pointing和Embrace事件不同,这两个事件的全身的姿态信息都是非常重要的,而且这些人的头肩部分或者因为弯腰引起了比较大的形变和遮挡,或者因为跑步速度过快导致的成像模糊,都使得基于行人检测结果的再分类并不适合.因此,我们分别为这两个事件训练关键姿态检测CNN模型,并采用滑动窗口的检测方式.
1)模型设计.研究发现Cifar-10网络[11]在行人检测、Pointing事件以及Embrace事件检测上均有良好表现,我们也采用该网络分别训练了Object-Put姿态识别和PersonRuns姿态识别的CNN模型,其结构如图5所示.为了充分利用整人全身信息,我们将样本归一化到64像素×64像素,而不是Cifar-10网络原始的32像素×32像素.

图5 ObjectPut和PersonRuns事件关键姿态检测的网络结构Fig.5 The architecture of CNN for ObjectPut and PersonRuns key-pose detection
2)事件检测过程.这两种事件的检测,因为不能利用行人检测的结果,所以我们依然采用多尺度的滑动窗口截取候选图像区域(Patch),并将Patch作为相应事件CNN模型的输入,根据模型输出的置信分数鉴别图像区域是否属于关键姿态.
4.3事件融合
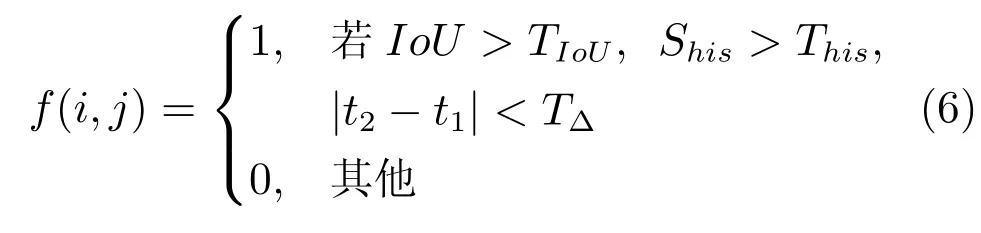
一般说来,事件发生将会持续一段时间,而非瞬间结束.所以,为提高事件检测的鲁棒性,需要对事件进行融合—将这些连续检测到的关键姿态帧融合成为一个完整的事件.融合策略采用最近邻匹配方式,分别考虑空间、外观及时间上的相关性.设t1时刻检测到事件i,时刻t2检测到事件j,则两事件融合规则为式中,f(i,j)为融合函数,1表示可以融合,0表示不能融合;为两个事件检测框重合度,第i个事件检测框,第j个检测框;TIOU=0.5为重合度阈值;Shis为两个检测框内直方图匹配分数;This=35为直方图匹配阈值;TΔ=25为两事件时间差阈值,同一个事件的关键姿态帧在时间上应该是相邻的,考虑到关键姿态帧的检测可能存在遗漏,所以该阈值选为25.
特别地,对于PersonRuns这样持续时间较长且容易漏掉关键姿态帧的事件,我们同时使用卡尔曼滤波器(Kalman filter)预测事件的起始帧和结束帧.
以上介绍了我们提出的基于关键姿态的事件检测方案,与以文献[19]为代表的方法相比较,基于姿态的事件检测方法准确地抓住了事件的关键点,极大地降低了检测难度;而且,检测关键姿态不需要大量提取局部特征点,有效地降低了被其他无关特征点噪声干扰的可能性.
5 基于轨迹分析的事件检测
基于轨迹分析的方案用于检测群体事件.群体事件不仅具有相关人员(人数≥2)自身的行为动作,还蕴含了人员之间的相互关系,相对于个体事件,群体事件的检测显得更为复杂.考虑到一般群体事件很难抽象出关键姿态,解决问题的关键在于如何描述人员之间的相互关系,所以我们首先需要检测并跟踪到行人,也即得到行人的运动轨迹;然后分析行人轨迹之间的关系,进而推理出是否发生所关注的群体事件.正是基于这样的分析,我们提出了基于行人检测与跟踪的轨迹分析方案来识别群体事件.其中,基于行人检测和跟踪是实现轨迹分析方案的重要基础.图6为所提出的群体事件检测方案框图,我们依然基于前文所述HsNet的行人头肩部对象检测结果,进行行人跟踪得到行人轨迹,通过轨迹分析检测群体事件.
群体事件,特别是在人员拥挤的场景中,从场景正面看(正视图),我们的观测将受到遮挡等因素的影响.考虑监控场景的固定摄像头都是悬挂在高出人群的地方,也即可以从一定角度俯视场景,这种俯视观察比正视观察受人员相互遮挡影响就少许多.仅仅检测头肩部区域(避免被遮挡),并采用目标轨迹分析群体事件的解决方案类似这种“俯视观察”.从空中看人,人可以抽象成一个“点”;而运动中人的轨迹,即为一个点的运动轨迹.这样,通过“空中俯视”检测群体事件,即是通过提取这些运动轨迹之间的关系来识别相关事件.

图6 群体事件检测框图Fig.6 The block diagram of group event detection
轨迹分析,从对象的运动轨迹中提取基本的参数(速度、方向、距离等)作为特征,对单个特征进行分析或者将多个特征相结合组成更高级的语义来描述事件,进而判断事件是否发生.相对于传统的特征—分类器相结合的方法,轨迹分析方法更注重对象整体行为以及对象间行为关系,轨迹分析更符合人眼对行为的认知.
我们以SED中的人员聚集(PeopleMeet)与分离(PeopleSplitUp)事件为例,具体阐述如何用轨迹分析方法来检测事件.
TRECVID评测中定义人员聚集指的是一人或多人走向另一人群(人数≥1),并停下谈话交流;人员分离指的是人群(人数≥2)中有一个或多个人离开了人群.
根据定义我们可以把“聚集”事件抽象成三种状态的顺序组合:走近、速度减慢、停留,“分离”事件也抽象成三种状态的顺序组合:停留、速度加快、远离.这两种事件的检测都可以从检测“停留”状态开始,我们以“分离”事件为例叙述通过轨迹分析检测群体事件的过程.完整的算法流程见算法1.
算法1.基于轨迹分析的分离事件检测算法
1.遍历轨迹集合ST
1.1找出每一条轨迹中速度趋近于0(vp≤vT1)的位置,即停留点
2.1.2当前轨迹Tn在Δt1内速度小于阈值vT2.
2.1.3Tn在Δt1内的位置P∆t1与停留点的距离小于阈值DT;将满足条件的轨迹ID添加到以为基准的候选事件Ek,迭代修正Δt1、增加Ek中的轨迹数目Nk.
3.遍历候选事件集SEC,找出分离事件集SE
3.1若候选事件Ek中轨迹数目Nk≥2.
3.1.1求Nk条轨迹的时间交集
3.1.2遍历Nk条轨迹,计算每一条轨迹距离停留点Pk的最远距离Dmax,若Dmax>DT,远离轨迹数目Mk增加1.
3.1.2.1若Mk<Nk,判断有分离事件发生,即Mk个行人与Nk-Mk个行人分离,分离的起始时间为Δt1的tks,分离的结束时间为Δt2的t′ke.
3.1.2.2若Mk=Nk,计算各轨迹运动方向之差,只要存在一个夹角αi>AT,判断有分离事件发生,分离的起始时间为Δt1的tks,分离的结束时间为Δt2的t′ke;否则,行人同向而行,无分离.
3.2若Nk<2,判断无分离事件发生.
4.结束
算法1由停留状态检测、候选事件集检测、分离事件鉴别三个阶段构成.
1)停留状态检测阶段,遍历从视频中检测到的所有轨迹,找出每条轨迹的“停留”状态(速度趋于0),即vp≤vT1,vp为当前轨迹考察点p的速度,vT1表示筛选出停留点的最大速度.由于停留状态是一段时间,因此一条轨迹上会检测出时间连续的停留点(xi,yi),聚类这些停留点
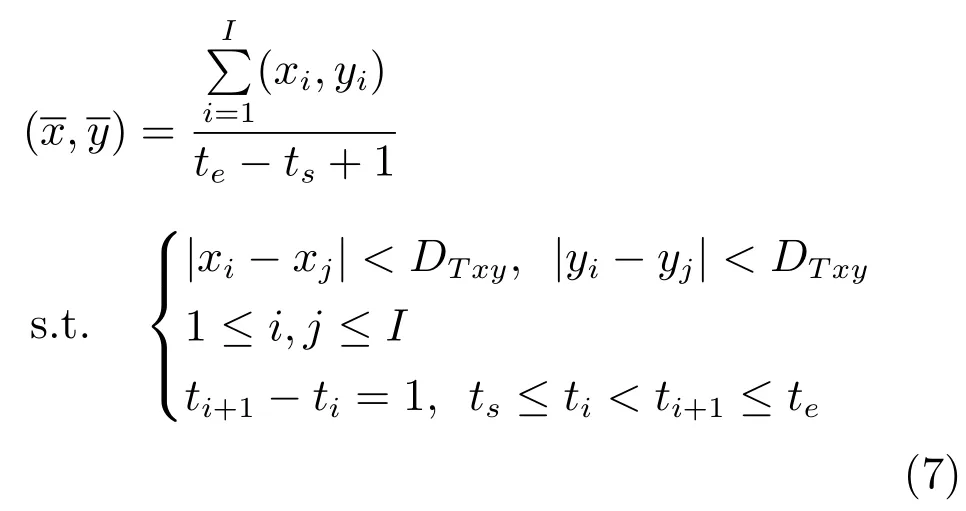

此阶段,算法将检测出所有的停留状态,找出所有候选停留聚类中心集,分离事件有可能从这些聚类中心发生.
3)分离事件鉴别阶段,遍历候选事件集SEC,鉴别可能的分离事件,得到分离事件检测输出结果SE.对于每个候选事件Ek,Nk条轨迹的时间交集为
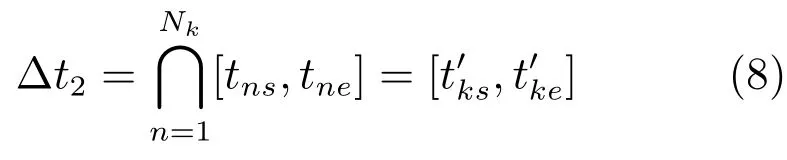
计算每条轨迹在tstart之后距离停留点中心最远的距离Dmax,分离事件判别函数为
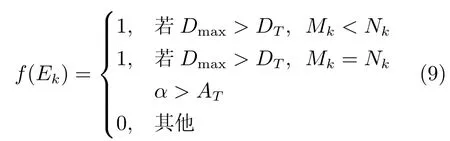
6 实验方法及结果
6.1行人检测
为更好地研究实际监控视频行人检测算法,基于TRECVID-SED的数据集,我们建立了规模较大的监控视频行人检测标注库[29].TRECVID-SED的训练集包含50个视频,我们从其中9个视频,选择标注了45000帧图像中的行人头肩框,得到了404563个头肩区域作为正确标注(Ground truth).
6.1.1模型训练
我们将所有Ground truth作为正样本,加上随机产生的7087336个负样本组成训练集[26],图7为所截取的正负样本示例,图7(a)为正样本,图7(b)为负样本.

图7 头肩区域训练样本示例Fig.7 Samples of head-shoulder
训练HsNet第一级网络时,将所有的训练数据全部送入网络中;训练完成后,根据正样本置信分设定阈值τ,使99.5%的正样本得分高于τ,将得分高于阈值τ的样本组成训练集再送入下一级网络.以此类推,其余两级的训练过程相同.
网络训练过程中,我们使用随机梯度下降算法(Stochastic gradient descent,SGD)及反向传播算法(Back-propagation,BP)优化级联网络的参数.在每一次SGD迭代中,均匀采样32个正样本和96个负样本构成一个批处理单元.由于正样本数量远小于负样本数量,所以采样更偏向正样本.级联网络各层参数初始值均使用标准差σ=0.01的高斯分布初始化,学习率η设为0.01,每经过5000次迭代,学习率η均衰减0.1,动量(Momentum)设置为0.9,最大迭代次数为60000次.
6.1.2实验结果
基于上述训练集,我们将提出的行人检测方案与当前最先进的一些检测方法如DPM+LSVM[7]、JointDeep[8]、CifarNet[10]进行了对比实验.如图8所示,由于人工设计的特征的局限性,DPM的性能是最差的(73.9%).尽管JointDeep[8]和CifarNet[10]均利用了深度网络的长处,但是依然无法处理高度拥挤的行人的情况.所以各自取得了58.5%和57.4%的漏检率.相反,本文的模型因为忽略掉了躯干及以下部分,有效地降低了因为遮挡而导致的噪声干扰.在图9所示的场景中,本文的方法在拥挤的情况下依然检测到了绝大多数的行人,
式中,DT为Dmax的阈值,仅当Dmax大于此值时,认为该轨迹有远离倾向;Mk为远离的轨迹数目;α 为Nk条轨迹中任意两条轨迹运动矢量(从轨迹的始端到末端的连线作为轨迹运动矢量)的夹角,用以衡量对象间相对运动方向,AT为阈值;f(Ek)为1表示分离事件发生,候选事件Ek并入分离事件检测输出结果SE,其结束时间为Δt2中的t′ke,即(t′s,t′e)= (tstart,t′ke).
聚集事件与分离事件是相反的过程,分析与其类似,不再赘述.从行人轨迹分析多人的群体事件,是用分层的思想分析视频(底层—检测跟踪得到轨迹,高层—轨迹分析鉴别事件发生与否),更能捕获真实世界中对象之间的相互关系,从而准确检测出我们关注的事件;当然,轨迹分析的结果,与对象检测和跟踪算法的性能密切相关,基于HsNet的头肩部检测结果与鲁棒的多目标跟踪算法,对轨迹分析方案的实施奠定了重要的基础.并且保持极低的虚检率.
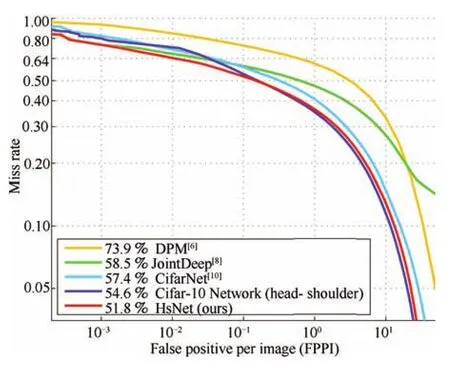
图8 与当前最先进的检测方法在SED-PD上的对比[26](用平均对数漏检率排列,越小越好)Fig.8 Comparison of our results with several state-of-the-art methods on SED-PD[26](The legends are ordered by log-average miss-rate,the lower the better.)

图9 在SED-PD上的部分检测结果[26](红框表示正确检测,蓝框表示虚检,绿框表示漏检)Fig.9 Detection results on SED-PD[26](red:correct detection,blue:false alarm,green:missed detection)
6.2行人跟踪
由于SED仅评测事件检测结果,NIST并不提供行人跟踪的Ground truth;因此我们无法给出GPR改进跟踪算法的定量结果,同时考虑本文的篇幅较长,仅以图10的一组对比图,从轨迹的平滑性、是否断裂以及完整性来体现改进效果.如图10所示,图10(a)为直接关联检测响应得到轨迹片段,轨迹平滑性较差;图10(b)为对图10(a)的轨迹片段通过GPR得到的光滑轨迹;图10(c)是底层关联时没有加入GPR,轨迹速度计算误差较大,影响了高层片段的正确关联,导致轨迹不完整;图10(d)是在底层、高层及最终轨迹中都使用了GPR,修正了检测位置,使得片段正确关联,得到完整、平滑的轨迹,可用于后续轨迹分析和事件检测.
6.3事件检测
6.3.1参数设计
Pointing和Embrace事件,我们采用与HsNet相同的网络架构来训练这两类关键姿态检测的CNN模型.超参数设置也与HsNet一致,即在每一次SGD迭代中,均匀采样32个正样本和96个负样本构成一个批处理单元.级联网络各层参数初始值均使用标准差σ=0.01的高斯分布初始化,学习率η设为0.01,每经过5000次迭代,学习率η均衰减0.1,动量(Momentum)设置为0.9,最大迭代次数为60000次.
ObjectPut和 PersonRuns事件,我们采用Cifar-10[11]网络结构.网络的每一层参数使用标准差σ=0.01的高斯分布初始化,学习率η固定为0.001,动量设置为0.9,最大迭代次数为50000次.
PeopleSplitUp和PeopleMeet事件检测中,针对SED视频场景的特点,轨迹分析方法的参数设置如下:筛选停留点的最大速度vT1=5(pixel);聚类停留点的空间坐标之差小于阈值DTxy=50 (pixel);候选轨迹在Δt1时段速度小于阈值vT2= 10(pixel);距离停留点中心的距离小于阈值DT= 50(pixel);轨迹具有远离倾向的距离阈值DT=100 (pixel);两条轨迹相对运动方向大于阈值AT=45◦.

图10 高斯过程回归改进效果Fig.10 The improved results of Gaussian process regression
6.3.2实验结果
从TRECVID SED2015评测结果,可以体现我们所提事件检测框架的效果.文献[30]详细描述了评测方法,采用实际归一化检测错误率(Actual normalized detection cost rate,ADCR)作为主要的评测指标,值越小说明系统效果越好.
表1为所有事件的评测结果.表1中#Targ是主办方给出的事件总数 (即 Ground truth),#CorDet为正确检测数,#FA为虚检数,#Miss为漏检数.由表1可知,本文所述基于CNN的复杂视频事件检测方法取得了非常优秀的结果,在参与评测的6个项目中,取得了3个第一、2个第二和1个第四的好成绩.这些都得益于CNN能够自动学习更有区分力的特征,在关键姿态的检测上优势明显.同时,基于CNN的行人检测也为后续行人跟踪进而完成基于轨迹分析的群体事件检测奠定了坚实的基础.
7 结语
基于对TRECVID-SED评测中复杂监控视频中事件检测任务的研究,我们提出了:1)基于CNN级联网络检测行人头肩部代替检测行人整体的方法,来检测拥挤场景遮挡严重条件下的行人,实现了可与当前最先进的行人检测方法相比的检测效果;2)基于 CNN网络检测具有关键姿态的个体事件的方法,使得复杂的4D空间的事件检测在2D空间实现检测;3)基于轨迹分析检测群体事件的方案,体现分层次解决高维的事件分析问题的合理性;4)将高斯过程回归引入跟踪轨迹参数方程拟合,使得跟踪算法不必受限于轨迹需要满足线性或二次函数的假设,更适合描述目标的实际运动情况.所提出的事件检测方案,在TRECVID-SED2015国际评测中,取得了很好的排名,证实了方案的有效性.当然,SED数据集事件检测性能还有很大的提升空间,与实际使用还有很大距离,需要研究者付出更多的努力.
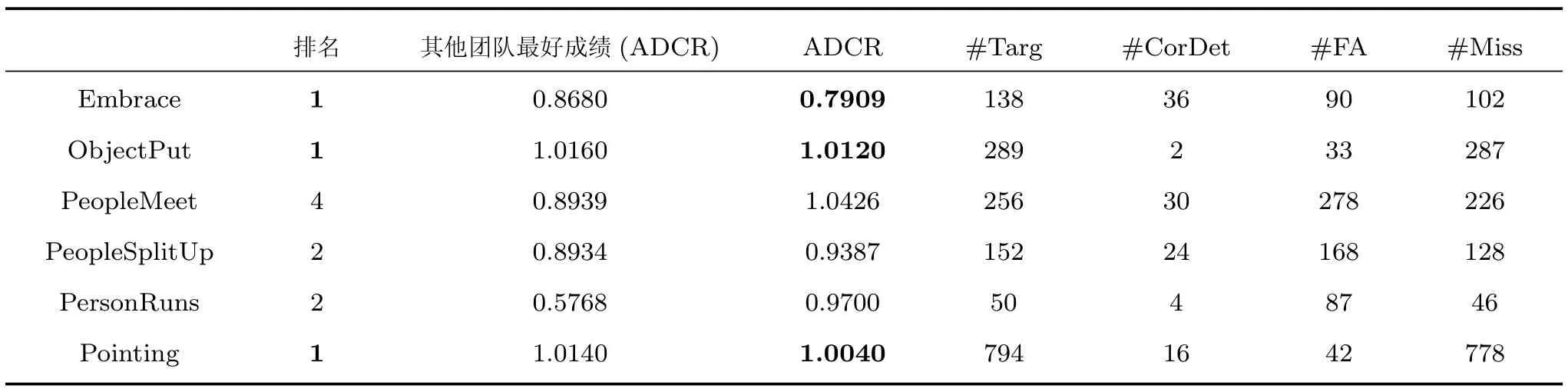
表1 2015年TRECVID-SED评测结果Table 1 Evaluation Results of TRECVID-SED 2015
References
1 Text Retrieval Conference(TREC)[Online],available:http://trec.nist.gov/,April 5,2016
2 National Institute of Standards and Technology(NIST)[Online],available:http://www.nist.gov/index.html,April 5,2016
3 TREC Video Retrieval Evaluation(TRECVID)[Online],available:http://www-nlpir.nist.gov/projects/trecvid/,April 5,2016
4 Dollar P,Wojek C,Schiele B,Perona P.Pedestrian detection:an evaluation of the state of the art.IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(4):743-761
5 Benenson R,Omran M,Hosang J,Schiele B.Ten years of pedestrian detection,what have we learned?In:Proceedings of the 12th European Conference on Computer Vision. Zurich,Switzerland:Springer,2014.613-627
6 Dalal N,Triggs B.Histograms of oriented gradients for human detection.In:Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.San Diego,USA:IEEE,2005.886-893
7 Felzenszwalb P,McAllester D,Ramanan D.A discriminatively trained,multiscale,deformable part model.In:Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition.Anchorage,Alaska,USA:IEEE,2008.1-8
8 Ouyang W,Wang X.Joint deep learning for pedestrian detection.In:Proceedings of the 2013 IEEE International Conference on Computer Vision.Sydney,Australia:IEEE,2013.2056-2063
9 Luo P,Tian Y,Wang X,Tang X.Switchable deep network for pedestrian detection.In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus,Ohio,USA:IEEE,2014.899-906
10 Hosang J,Omran M,Benenson R,Schiele B.Taking a deeper look at pedestrians.In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition.Boston,USA:IEEE,2015.4073-4082
11 Cuda-convnet.High-performance C++/CUDA implementation of convolutional neural networks[Online],available:https://code.google.com/p/cuda-convnet/,April 5,2016
12 Huang C,Wu B,Nevatia R.Robust object tracking by hierarchical association of detection responses.In:Proceedings of the 10th European Conference on Computer Vision.Marseille,France:Springer,2008.788-801
13 Yang B,Nevatia R.Multi-target tracking by online learning of non-linear motion patterns and robust appearance models.In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition.Providence,USA:IEEE,2012.1918-1925
14 Soomro K,Zamir A R,Shah M.UCF101:A Dataset of 101 Human Actions Classes from Videos in the Wild,Technical Report CRCV-TR-12-01,Center for Research in Computer Vision,University of Central Florida,USA,2012.
15 Kuehne H,Jhuang H,Garrote E,Poggio T,Serre T.HMDB:a large video database for human motion recognition.In:Proceedings of the 2011 IEEE International Conference on Computer Vision.Barcelona,Spain:IEEE,2011.2556-2563
16 Karpathy A,Toderici G,Shetty S,Leung T,Sukthankar R,Li F F.Large-scale video classification with convolutional neural networks.In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus,Ohio,USA:IEEE,2014.1725-1732
17 Simonyan K,Zisserman A.Two-stream convolutional networks for action recognition in videos.In:Proceedings of the 2014 Conference and Workshop on Neural Information Processing Systems.Montreal,Canada,2014.568-576
18 Over P,Awad G,Fiscus J,Michel M,Smeaton A F,Kraaij W.TRECVID 2009-goals,tasks,data,evaluation mechanisms and metrics.In:TRECVid Workshop 2009.Gaithersburg,MD,USA:NIST,2010.1-42
19 Du X Z,Cai Y,Zhao Y C,Li H,Yang Y,Hauptmann A.Informedia@trecvid 2014:surveillance event detection. TRECVid video retrieval evaluation workshop[Online],available:http://www-nlpir.nist.gov/projects/tvpubs/tv14. papers/cmu.pdf,April 5,2016
20 Cheng Y,Brown L,Fan Q F,Liu J J,Feris R,Choudhary A,Pankanti S.IBM-Northwestern@TRECVID 2014:Surveillance Event Detection.TRECVid video retrieval evaluation workshop[Online],available:http://www-nlpir.nist.gov/ projects/tvpubs/tv14.papers/ibm.pdf,April 5,2016
21 Laptev I.On space-time interest points.International Journal of Computer Vision,2005,64(2-3):107-123
22 Chen M Y,Hauptmann A.MoSIFT:Recognizing Human Actions in Surveillance Videos,Technical Report CMU-CS-09-161,Department of Computer Science,Mellon University,USA,2009.
23 Lawrence S,Giles C L,Tsoi A C,Back A D.Face recognition:a convolutional neural-network approach.IEEE Transactions on Neural Networks,1997,8(1):98-113
24 Krizhevsky A,Sutskever I,Hinton G E.ImageNet classification with deep convolutional neural networks.In:Proceedings of the 2012 Advances in Neural Information Processing Systems.Lake Tahoe,Nevada,USA:Curran Associates,Inc.,2012.1097-1105
25 Jia Y Q,Shelhamer E,Donahue J,Karayev S,Long J,Girshick R,Guadarrama S,Darrell T.Caffe:convolutional architecture for fast feature embedding.In:Proceedings of the 22nd ACM International Conference on Multimedia.Orlando,USA:ACM,2014.675-678
26 Chen Q,Jiang W H,Zhao Y Y,Su F.Part-based deep network for pedestrian detection in surveillance videos.In:Proceedings of the 2015 IEEE International Conference on Visual Communications and Image Processing.Singapore:IEEE,2015.1-4
27 Li Lan-Bo.Currency Recognition and Multi-Target Tracking Algorithm [Master dissertation],Beijing University of Posts and Communications,China,2015.(李澜博.纸币面值识别及监控视频跟踪算法[硕士学位论文],北京邮电大学,中国,2015.)
28 Prince S J D.Computer Vision:Models,Learning,and Inference.Cambridge:Cambridge University Press,2012.
29 SED Pedestrian Dataset(SED-PD)[Online],available:http://www.bupt-mcprl.net/datadownload.php,April5,2016
30 TRECVID Surveillance Event Detection(SED)Evaluation Plan[Online],available: ftp://jaguar.ncsl.nist.gov/pub/ SED15-EvaluationPlan.pdf,April 5,2016

王梦来北京邮电大学信息与通信工程学院硕士研究生.主要研究方向为计算机视觉和深度学习.本文通信作者.
E-mail:wangmenglai@bupt.edu.cn
(WANG Meng-LaiMaster student at the School of Information and Communication Engineering,Beijing University of Posts and Telecommunications.His research interest covers computer vision and deep learning.Corresponding author of this paper.)

李 想北京邮电大学信息与通信工程学院硕士研究生.主要研究方向为计算机视觉与模式识别.
E-mail:lixiang92130@163.com
(LI XiangMaster student at the School of Information and Communication Engineering,Beijing University of Posts and Telecommunications.His research interest covers computer vision and pattern recognition.)

陈 奇北京邮电大学信息与通信工程学院硕士研究生.主要研究方向为计算机视觉与模式识别.
E-mail:chen-qi1990@163.com
(CHEN QiMaster student at the School of Information and Communication Engineering,Beijing University of Posts and Telecommunications.His research interest covers computer vision and pattern recognition.)

李澜博北京邮电大学信息与通信工程学院硕士研究生.主要研究方向为计算机视觉和大规模深度学习.
E-mail:llb-34@126.com
(LI Lan-BoMaster student at the School of Information and Communication Engineering,Beijing University of Posts and Telecommunications.His research interest covers computer vision and large scale deep learning.)

赵衍运北京邮电大学信息与通信工程学院副教授.主要研究方向为计算机视觉与模式识别.
E-mail:zyy@bupt.edu.cn
(ZHAO Yan-YunAssociate professor at the School of Information and CommunicationEngineering, Beijing University of Posts and Telecommunications.Her research interest covers computer vision and pattern recognition.)
Surveillance Event Detection Based on CNN
WANG Meng-Lai1LI Xiang1CHEN Qi1LI Lan-Bo1ZHAO Yan-Yun1
It is well-known that event detection in real-world surveillance videos is a challenging task.The corpus of TRECVID-SED evaluation is acquired from the surveillance video of London Gatwick International Airport and it is well known for its high difficulties.We propose a comprehensive event detection framework based on an effective part-based deep network cascade— head-shoulder networks(HsNet)and trajectory analysis.On the one hand,the deep network detects pedestrians very precisely,laying a foundation for tracking pedestrians.On the other hand,convolutional neural networks(CNNs)are good at detecting key-pose-based single events.Trajectory analysis is introduced for group events. In TRECVID-SED15 evaluation,our approach outperformed others in 3 out of 6 events,demonstrating the power of our proposal.
Convolutional neural network(CNN),event detection,pedestrian detection,target tracking,trajectory analysis
10.16383/j.aas.2016.c150729
Wang Meng-Lai,Li Xiang,Chen Qi,Li Lan-Bo,Zhao Yan-Yun.Surveillance event detection based on CNN. Acta Automatica Sinica,2016,42(6):892-903
2015-11-03录用日期2016-04-01
Manuscript received November 3,2015;accepted April 1,2016
本文责任编委柯登峰
Recommended by Associate Editor KE Deng-Feng
1.北京邮电大学信息与通信工程学院多媒体通信与模式识别实验室北京100876
1.Multimedia Communication and Pattern Recognition Laboratory,School of Information and Communication Engineering,Beijing University of Posts and Telecommunications,Beijing 100876
猜你喜欢
意林(2021年5期)2021-04-18
学生天地(2020年3期)2020-08-25
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
扬子江(2019年1期)2019-03-08
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
小天使·一年级语数英综合(2017年6期)2017-06-07
