
基于DFI的HTTP流归并方法*
2016-08-11 06:59殷红花
计算机与数字工程 2016年4期
殷红花 桑 静
(扬州市职业大学 扬州 225009)
基于DFI的HTTP流归并方法*
殷红花桑静
(扬州市职业大学扬州225009)
摘要目前的流量分类算法只能对不同类型的HTTP流量进行分类,无法将HTTP流量以各自所属的网页进行聚类,因此无法满足后向收费等新兴应用,论文提出一种基于DFI的HTTP流归并算法,能将一次网页访问所产生的所有HTTP流进行归并。该方法是一种基于流量行为的应用识别技术,通过分析不同HTTP流在会话连接或数据流上状态的不同,从而对HTTP流以网页为单位进行归并。实验结果表明该方法可以有效地解决大规模网络流量的HTTP流归并问题。
关键词HTTP流; 归并; DFI; 流量行为
Class NumberTP393
1 引言
现阶段绝大多数ISP还在提供流量计费的网络服务,因此当前ICP(Internet Content Provider)可以替用户向ISP支付访问Web服务所产生的流量费用来吸引更多客户。如阿里巴巴已经宣布淘宝、聚划算、支付宝等手机客户端用户可以申领每月2G定向免费流量。本文提出的HTTP流归并算法可以对浏览器访问不同Web所产生的流量进行精确分类,从而统计用户访问不同网页各自所产生的流量。此外,ISP还可以根据不同收费,对不同的ICP提供区分服务,对于支付较高费用的ICP,ISP可以提高它的流量通过路由的优先级,在网络负载较高的情况下提高用户访问该网站的体验效果,从而在保留当前用户的基础上吸引更多的潜在用户。但是目前还没有能对单个页面中HTTP流量进行有效归并的高效算法。虽然已经存在大量关于流量分类和识别的文献,尤其是基于应用层的流量分类[1~4],还有针对Web最新技术例如Ajax的测量研究[5~6],但是它们只能对不同的网络流量进行分类。
针对不同的应用环境,本文提出基于DFI的HTTP流归并算法,该算法对每一个HTTP请求的头部进行解析,提取头部字段GET、Referer以Host,通过将GET和Host拼接而成的URL与Referer进行匹配从而完成流之间的归并,再通过不同流之间时间等特征对主流与辅流进行识别,从而完成对一次网页请求所产生的所有流进行归并,适用于对精度要求较高但是流量较小的网络。另外,基于DFI的HTTP流归并算法从流量行为的角度分析主流与辅流在会话连接与数据流上状态的细微差别,总结出规律,从而完成主流与辅流的识别与归并,适用于大流量下对效率要求较高的网络环境。
2 相关研究
目前针对HTTP流归并的相关研究工作较少,尤其是专门针对HTTP流归并问题的研究。HTTP流归并方法主要分为三大类: 1) 基于IP与Think times的HTTP流归并算法; 2) 基于Referer与Think times的HTTP流归并算法; 3) 主动HTTP流归并。
2.1基于IP与Think times的HTTP流归并算法
早期Web网站规模相对较小、使用静态文档,而且一个网页中所有资源均来自同一个台服务器,因此可以通过IP对HTTP流量进行初步聚类。Think times是Mah[7]首次提出的概念,具体指两条不同HTTP流之间的时间间隔。Mah认为用户浏览网页并选择点击一个超链接的Think times与浏览器发送内嵌对象的Think times会存在明显的区别。Mah在对HTTP流进行归并时主要考虑IP和Think times,通过IP将路由器中抓取的所有HTTP流进行分类,客户机端与服务器端IP均相同的HTTP流量属于同一个集合,之后再通过基于Think times的分类算法识别出访问每一个网页所产生的HTTP流量。Barford[8]与Smith[9]提出的关于Web流量归并算法从本质上来说也是基于Mah的模型。Choi与Limb[10]在Mah模型的基础上通过对HTTP报文头部进行分析,利用HTTP请求所访问资源类型协助区分主请求与访问内嵌对象请求。
2.2基于Referer与Think times的Web流量归并算法
随着HTTP协议不断发展以及CDN等网络加速技术广泛应用,仅通过IP与Think times已经无法对Web服务产生的流量进行有效归并。当前所提出的HTTP流归并算法通过对Referer值与完整URL进行匹配,找出每一个HTTP请求所属源端页面的HTTP请求,从而确定不同请求之间的归并关系,并在这个基础通过Think times识别出主流与辅流。Ihm[11]提出的StreamStructure算法通过Referer与Thinks times对HTTP流量以各自所属的页面进行归并,计算每个HTTP请求与最近出现的相关HTTP请求对应的响应报文时间间隔,Ihm认为主请求对应的时间间隔应超过设定的Think times阈值,而用于访问内嵌对象的HTTP请求对应的时间间隔应小于Think times阈值。Khandelwal设计的CobWeb[12]系统则是通过HTTP请求头部的Referer字段对HTTP流量以各自所属的网站进行归并,该系统的主要特点是可以对在线流量进行实时处理。
2.3主动HTTP流归并
主动HTTP流归并方法是一种基于浏览器的主动网页归并测量,通过浏览器插件精确地记录本地所有网页加载事件,再根据日志信息得出HTTP流的归并结果。Butkiewicz[13]在对网页复杂性分析的研究中提出了基于浏览器的测量框架,用于研究用户使用浏览器上网的行为。采用扩展Net:Export的Firebug和Firestarter,将渲染网页时所产生的所有HTTP请求与响应自动导出到日志中。基于Referer与Think times的HTTP流归并算法则通过解析HTTP请求的内容完成对HTTP流的归并,优点是不需要像主动流量归并那样需要浏览器插件提供其它参考数据,但具有需解析报文载荷与主流识别精度不高等缺点。主动HTTP流归并需要浏览器插件的支持,具有精度高的优点,可以通过它对其它HTTP流归并算法进行评价。
3 基于DFI的HTTP流归并算法
3.1HTTP流量归并树
HTTP流归并算法通过分析HTTP报文,还原HTTP流量的归并关系,从而完成对HTTP流的归并。例如访问www.sina.com/并通过点击超链接打开edu.sina.com.cn/与www.xdf.cn/产生的HTTP流量所构建的归并关系树,如图1所示。
3.2基于DFI的HTTP流归并识别规则
基于DFI的HTTP流归并算法从流的角度,分析主流与辅流之间的差异并提炼出规则,从而识别主流与辅流并在此基础上完成辅流与主流的归并。本文针对主流在传输HTTP请求时是否复用TCP连接提出两种不同场景的识别方法。
3.2.1基于多事务场景的主流识别
当一条HTTP流满足基于多事务场景的主流识别规则时,便可以认为它是主流,规则具体定义如下: 1) 主流宿IP为新IP; 2) 主流中主响应包含的TCP报文段数应介于4~150之间,且一条主流中至少有两个HTTP请求; 3) 主流从收到主响应首个TCP报文段后20ms开始,到完整响应下载结束的950ms以内至少有三个相关HTTP请求被加载,且这些HTTP请求对应的宿IP是新IP或与主流具有同样的宿IP; 4) 若一条流中第一个HTTP请求对应的响应只通过一个TCP报文段传输,而第二个HTTP请求与响应满足上述3个条件,也可以认为该流是主流; 5) 若当前主流宿IP与前一个主流宿IP前24位相同时,那么必须保证它们IP后8位也相同;6)主流中第一个HTTP请求与离它最近的十个HTTP请求平均时间间隔应大于1s,当前主流与上一个主流的时间间隔应大于5s。

图1 HTTP流量归并树示例图
3.2.2基于单事务场景的主流识别
在实际网络环境中,部分主流中只包含单个HTTP请求,且该主流宿IP所对应的所有辅流也只包含一个HTTP请求。基于单事务场景的主流识别规则定义如下: 1) 主流宿IP为新IP; 2) 在一定的时间区间内(2s),一条IP相关的3个TCP连接中HTTP请求均只有1个,且该IP对应的第一条流中响应所包含的TCP报文段数应介于4~150之间,主流为该IP对应的第一条流; 3) 主流从收到主响应首个TCP报文段后20ms开始,到完整响应下载结束的950ms以内至少有3个相关HTTP请求被加载,且这些HTTP请求对应的宿IP是新IP或与主流具有同样的宿IP; 4) 若当前主流宿IP与前一个主流宿IP前24位相同时,那么必须保证它们IP后8位也相同; 5) 主流中第一个HTTP请求与离它最近的十个HTTP请求平均时间间隔应大于1s,当前主流与上一个主流的时间间隔应大于5s。
3.3辅流归并算法
辅流与主流归并通过主流识别算法完成主流与辅流的识别后再通过辅流归并算法将辅流归并到它所属的主流上。对于一个主流之后32s内出现的每一个辅流,若满足规则1且不满足规则2时,则将它归并到离它最近的主流上,否则将该辅流与离它第二近的主流相归并,且辅流与该第二近主流时间间隔小于32s,归并过程如图2所示。
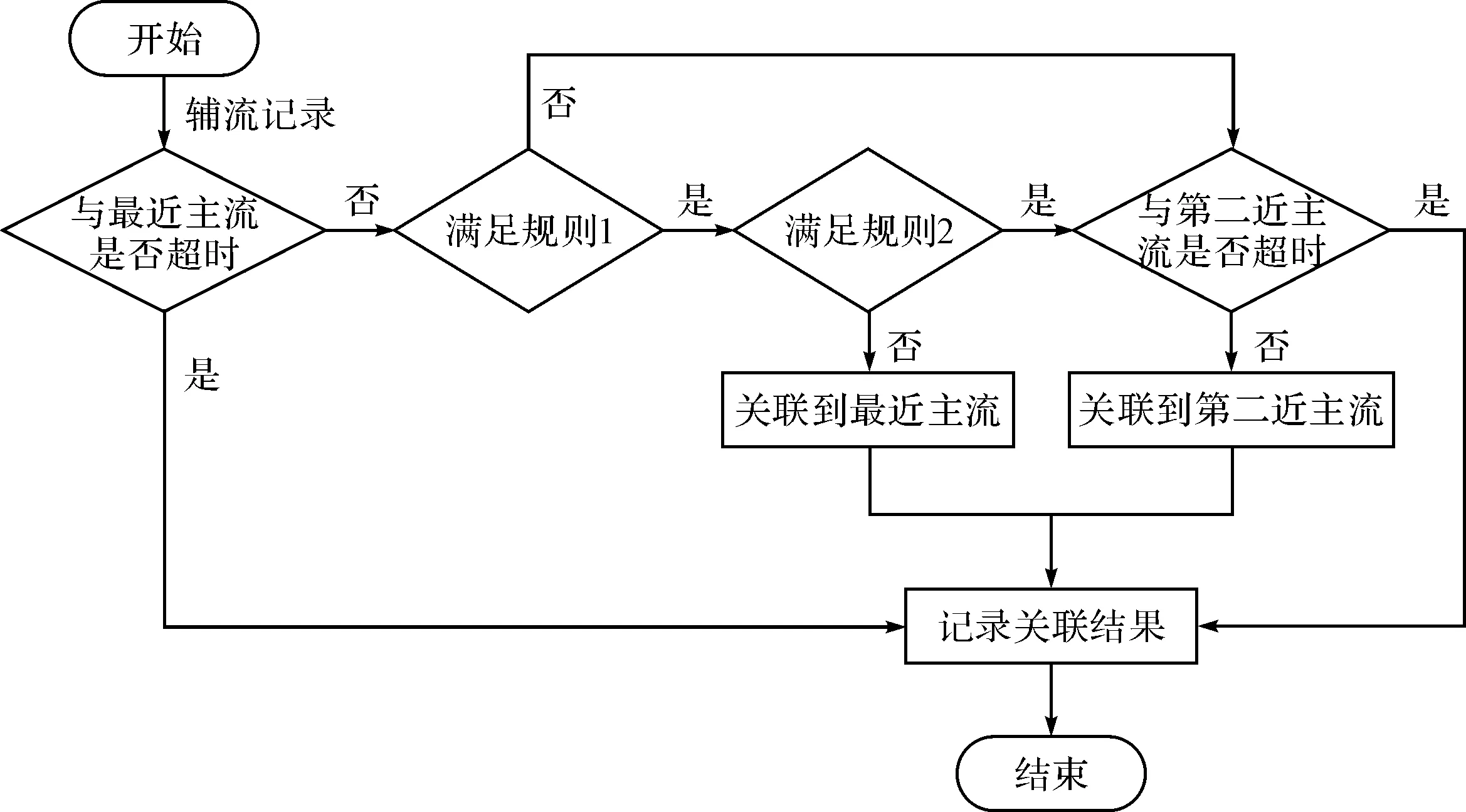
图2 归并算法流程图
规则1:辅流宿IP为新IP或与主流具有相同IP,且辅流中首个HTTP请求时戳大于主流中第一个响应的开始时戳加上浏览器处理时间(20ms);
规则2:辅流宿IP对应的DNS查询报文时戳介于前一个主流主响应开始时戳加上浏览器处理时间(20ms)与当前主流主响应开始时戳加上20ms之间,且该宿IP对应的其它辅流未在当前主流与前一个主流之间出现。
4 实验结果与分析
4.1实验数据与评价指标
实验数据通过基于Selenium自动化框架的数据采集系统在本地计算机上所采集来自访问40个在alex排名较高的网站产生的流量,数据大小约为21G,包含40个数据子集,每个数据子集为访问同一域名网页所产生的流量,同时记录所访问页面的URL,对主流进行手动标记。
4.2分类性能
为了评价基于DFI的HTTP流归并算法的性能,选用四种评价指标,包括查准率和查全率,归并字节比率和加载时间比率。归并字节比率定义为算法归并结果中每个网页的总字节数与对应网页实际字节数的比值。加载时间比率定义为归并结果中每个网页的加载时间与对应网页实际加载时间的比值。查准率和查全率体现算法针对主流识别的效果,归并字节比率与加载时间比率则体现辅流与主流归并上的准确率。图3和图4分别给出了基于HTTP请求方法与基于DFI方法的查全率和查准率。

图3 主流识别查全率
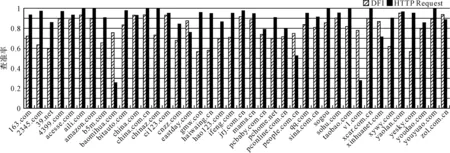
图4 主流识别查准率
从图3可以看出基于HTTP请求方法的平均查全率为86.5%,而基于DFI方法的平均查全率为72.6%。由于基于HTTP请求方法通过解析报文应用层内容比DFI方法获得更多相关信息,因此在查全率上前者要高于后者。图4可以看出基于HTTP请求方法的平均查准率为88.6%,而基于DFI的HTTP方法的平均查准率为79.63%。由于前者解析应用层内容,查准率高于后者。部分域名下基于HTTP请求方法的查准率不如基于DFI的方法,因为前者将部分非广告内嵌对象也识别成主流,导致查准率降低,而这些内嵌对象却不满足DFI方法对主流的定义,因而不会被错误地识别为主流。图5给出了基于DFI方法与基于HTTP请求方法对网页归并字节数统计结果的比值。纵坐标表示同一个数据子集中不同页面归并字节比率均值。
图5可以看出40个数据子集的归并字节比率均值为95.2%,而且每个子集的归并字节比率也均接近1,说明算法在辅流与主流的归并上能获得较好的性能。图6给出的是基于DFI方法与基于HTTP请求方法对页面加载时间统计结果的比值。纵坐标代表同一个数据子集中不同页面加载时间比率均值。
图6中40个数据子集的加载时间比率均值为102.4%。部分数据子集的加载时间比率要远高于1,导致这种情况是因为加载时间是由主流以及被归并辅流的最晚结束时间所决定,错误归并一条辅流对某个页面统计加载时间所产生的影响要远超过对该页面字节数统计。与基于HTTP请求方法相比,基于DFI方法只需要TCP层以下的信息而不必解析报文应用层载荷,流归并效率高,同时可以用于HTTPS等加密流量。

图5 页面归并字节比率

图6 页面加载时间比率
5 结语
针对网络后向收费以及路由加速应用,本文提出基于DFI的HTTP流归并算法。基于DPI的HTTP流归并算法通过解析HTTP请求的内容对一次网页请求产生的所有流量进行归并,无法用于加密流量,而基于DFI的HTTP流归并算法不需要解析数据包,通过总结不同HTTP流在会话连接或数据流上状态的规律,对HTTP流进行归并。实验结果表明基于DFI的流归并方法可以有效地解决大规模网络流量的HTTP流归并问题。下一步工作将优化归并策略进一步提高基于DFI算法归并精度。
参 考 文 献
[1] Karagiannis T, Papagiannaki K, Faloutsos M. BLINC: multilevel traffic classification in the dark[C]//ACM SIGCOMM Computer Communication Review. ACM,2005,35(4):229-240.
[2] Ma J, Levchenko K, Kreibich C, et al. Unexpected means of protocol inference[C]//Proceedings of the 6th ACM SIGCOMM conference on Internet measurement. ACM,2006:313-326.
[3] Roughan M, Sen S, Spatscheck O, et al. Class-of-service mapping for QoS: a statistical signature-based approach to IP traffic classification[C]//Proceedings of the 4th ACM SIGCOMM conference on Internet measurement. ACM,2004:135-148.
[4] Butkiewicz M, Madhyastha H V, Sekar V. Understanding website complexity: measurements, metrics, and implications[C]//Proceedings of the 2011 ACM SIGCOMM conference on Internet measurement conference. ACM,2011:313-328.
[5] Kiciman E, Livshits B. AjaxScope: a platform for remotely monitoring the client-side behavior of Web 2.0 applications[C]//ACM SIGOPS Operating Systems Review. ACM,2007,41(6):17-30.
[6] Schneider F, Agarwal S, Alpcan T, et al. The new web: Characterizing ajax traffic[M]//Passive and Active Network Measurement. Springer Berlin Heidelberg,2008:31-40.
[7] Mah B A. An empirical model of HTTP network traffic[C]//INFOCOM’97. Sixteenth Annual Joint Conference of the IEEE Computer and Communications Societies. Driving the Information Revolution., Proceedings IEEE. IEEE,1997,2:592-600.
[8] Barford P, Crovella M. Generating representative web workloads for network and server performance evaluation[C]//ACM SIGMETRICS Performance Evaluation Review. ACM,1998,26(1):151-160.
[9] Smith F D, Campos F H, Jeffay K, et al. What TCP/IP protocol headers can tell us about the web[C]//ACM SIGMETRICS Performance Evaluation Review. ACM,2001,29(1):245-256.
[10] Choi H K, Limb J O. A behavioral model of web traffic[C]//Network Protocols, 1999. (ICNP’99) Proceedings. Seventh International Conference on. IEEE,1999:327-334.
[11] Ihm S, Pai V S. Towards understanding modern web traffic[C]//Proceedings of the 2011 ACM SIGCOMM conference on Internet measurement conference. ACM,2011:295-312.
[12] Khandelwal H, Hao F, Mukherjee S, et al. CobWeb: In-network cobbling of web traffic[C]//IFIP Networking Conference, 2013. IEEE,2013:1-9.
[13] Butkiewicz M, Madhyastha H V, Sekar V. Understanding website complexity: measurements, metrics, and implications[C]//Proceedings of the 2011 ACM SIGCOMM conference on Internet measurement conference. ACM,2011:313-328.
收稿日期:2015年10月5日,修回日期:2015年11月27日
基金项目:江苏省现代教育技术研究重点课题:基于用户满意度的高职院校网络建设研究(编号:2015-R-44970)资助。
作者简介:殷红花,女,硕士,讲师,研究方向:计算机网络。桑静,女,硕士,副教授,研究方向:计算机网络。
中图分类号TP393
DOI:10.3969/j.issn.1672-9722.2016.04.031
HTTP Flow Cobbling Method Based on DFI
YIN HonghuaSANG Jing
(Yangzhou Polytechnic College, Yangzhou225009)
AbstractCurrently, the flow classification algorithm can only classify HTTP traffic with different application types, therefore it is unable to meet the emerging services such as reverse billing. A HTTP flow cobbling is proposed based on DFI, which can cobble all HTTP traffic generated by web service. This method is based on the application of the flow behavior recognition technology, by analyzing the difference of HTTP streaming in different sessions or different states, thus HTTP stream can be merged by web page as a unit. Experimental results show that the proposed method can solve the problem of HTTP flow cobbling in large scale traffic effectively.
Key WordsHTTP flow, cobbling, DFI, traffic behavior
