
云环境MMM数据库集群双主多从架构模型构建*
2016-08-11 06:59胡景光黄天天
计算机与数字工程 2016年4期
刘 波 胡景光 黄天天
(1.湖南农业大学信息科学技术学院 长沙 410128)(2.邵阳学院湘西南农村信息化服务湖南省重点实验室 邵阳 422000)(3.湖南省农村农业信息化工程技术研究中心 长沙 410128)
云环境MMM数据库集群双主多从架构模型构建*
刘波1,2,3胡景光1黄天天1
(1.湖南农业大学信息科学技术学院长沙410128)(2.邵阳学院湘西南农村信息化服务湖南省重点实验室邵阳422000)(3.湖南省农村农业信息化工程技术研究中心长沙410128)
摘要随着湖南国家农村农业信息化示范省综合服务平台与农村物联网基础平台的运行,对农业大数据的操作与安全提出了新的要求。为了适应这一要求,针对RedHat与MySQL系统,提出一个基于Linux系统可扩展的MySQL数据库集群双主多从架构优化模型。该模型主要由三个设计模块组成,即前端代理层实现主备热切换与读写分离;数据服务层对服务节点进行整合、监控与单一镜像;数据共享层实现远程数据同步备份容灾。测试证明在不提高服务器硬件性能的条件下,仅通过增加服务器数量就能解决整个数据库集群的性能瓶颈问题,而且能够在大批量读写数据的环境下进行有效的服务,加强云平台下农业数据的安全性、健壮性及可靠性。
关键词双主多从架构; 数据库集群; 读写分离; 负载均衡; 地址漂移
Class NumberTP392
1 引言
为了农业科技创新适应市场发展规律,满足湖南省农村地区对农业信息化的渴求,2011年~2014年国家科技部开展了农村农业信息化关键技术集成与示范(2011BAD21B00)与农村物联网综合信息服务科技工程(2012BAD35B00)课题研究,湖南省科技厅联合湖南农业大学等单位进行了湖南国家农村农业信息化综合服务平台[1]与农村物联网基础平台[2]的应用研究,并成功搭建了湖南农业信息化云平台,每天不停收集农业知识条目、呼叫中心信息与物联网终端数据,面对如此庞大的数据信息,如何保护这些数据安全,对农业云平台提出了新的要求。
当前为了适应云计算与大数据时代越来越严苛的数据存取要求,主要采取了如下措施:
1) 架构一种能够承受高并发、高负载和高可用的数据库应对客户端数以千万级的访问请求[3],而数据库集群在硬件性能无法再显著提升情况下,可以通过增加服务器数量获得通信性能的倍数级增加,同时具有可扩展性及可容灾性[4~5]。
2) 针对数据库集群访问频繁、并发访问等问题,服务器大多使用了负载均衡与复制技术[6~7],但访问量随着时间成几何倍数的增长,响应单个请求的速度越来越慢,若数据文件较大,写操作还会出现锁表时间过长等影响访问效率的问题。
3) 在硬件设备不变情况下,通过优化SQL语句和索引等方式[8~9],仍然不能满足数据存取要求,则建立数据库集群[10]。既然瓶颈是由于单台服务器的访问负载过重引起的,就通过增加数据库服务器的数量,将前端大量的数据连接进行负载均衡,分发到数据库集群的各个节点上面,让单台的服务器负载降低,从而初步解决数据瓶颈问题。
2 湖南农业信息云建设
2012年,湖南农业大学根据湖南国家农村农业信息化综合服务平台的建设进展,实施了湖南农大服务器虚拟化一期系统实施方案,一次性投入600多万元购买了9台华为服务器,3台S5600T与2台S2600T数据存储,划分了50台虚拟服务器,并初步搭建了2台数据库集群,同时将整个网络中的所有节点构成一个逻辑上统一的整体,实现用户可以对数据库节点进行透明存取。然而随着访问量的增大与数据流量的增多,相应的数据瓶颈也逐步显现,主要表现如下:
1) 节点间通信成为制约集群系统性能的严重瓶颈[11].虽然当前以太网技术已比较成熟,实现起来难度不大,而且网线接插方便,便于扩展和更换设备,然而集群系统中的一些先天弱点,导致了集群系统中节点间的数据传输效率不高。
2) 数据集群实现并行处理技术所需层次较多,配置复杂,影响正常性能。对于数据库软件,数据还要再经过一层应用的解析才能被数据库管理软件使用,每经过一层,数据处理都要消耗CPU资源,极大地影响了系统的性能。
3 MMM数据库集群优化模型
为了克服平台数据交互瓶颈问题,尝试建立更多数据库集群,根据MySQL数据库的特点,选择搭建MySQL数据库集群,虽然MySQL数据库构建集群的方式有多种,如簇集群模型、主从复制集群模型等,然而MMM数据库集群优化模型提供了MySQL主主复制配置的监控、故障转移和管理的一套可伸缩的脚本套件。在MMM集群模型中,典型的应用就是双主多从架构,通过MySQL复制技术可以实现两台服务器互为主从,且在存储时只有一个节点可以写入,避免多点写入的数据冲突。同时当可写的主节点故障时,MMM套件立刻监控到,然后将服务自动切换到另一个主节点,继续提供服务,从而实现MySQL的高可用。该模型的架构图如图1所示。

图1 MMM架构模型
针对湖南信息化综合服务平台的特点,结合MySQL的MMM数据库集群配置进行优化,以MMM集群为模型,配合使用Amoeba数据库代理服务以及高可用软件(Keepalived)和分布式块设备(Distributed Replication Block Device,DRBD)复制技术完成MySQL高可用和高可扩展的集群。
· 高可用集群组件Keepalived
Keepalived是Linux下一个轻量级的高可用解决方案,可以实现服务或者网络的高可用。Keepalived的部署简单快捷,所有配置只需一个配置文件即可完成。Keepalived专门用来监控集群系统中各个服务器节点的状态,它根据TCP/IP参考模型的第三、第四和第五层交换机检测每个服务节点的状态,若某个服务器节点出现异常,或工作出现故障,Keepalived将检测到,并将出现故障的服务点从集群中剔除,而在故障点恢复正常后,Keepalived又自动将此服务节点重新加入服务器集群中,况且这些工作全部自动完成,无需人工干预,需要人工完成的只是修复出现故障的服务节点。Keepalived后来又加入了虚拟路由冗余协议(Virtual Router Redundancy Protocol,VRRP)的功能,通过VRRP可以不间断稳定的运行,因此Keepalived一方面具有服务状态检测和故障隔离功能,另一方面具有HA Cluster功能。
· 数据同步组件DRBD
分布式块设备复制(Distributed Replication Block Device,DRBD)是一种基于网络的块复制存储解决方案,主要用于对服务器之间的磁盘、分区、逻辑卷进行数据镜像。当用户将数据写入本地磁盘时,同时将数据发送到网络中另一台主机的磁盘上,这样本地主机(主节点)与远程主机(备节点)的数据就可以保证实时同步,当本地主机出现问题,远程主机还保留着一份相同的数据,可以继续使用,保证了数据的安全。
DRBD是Linux内核存储层中的一个分布式存储系统,具体来说由两部分构成,一部分是内核模块,主要用于虚拟一个块设备;一部分是用户空间管理程序,主要用于和DRBD内核模块通信,以管理DRBD资源。在DRBD中,资源主要包含DRBD设备、磁盘配置、网络配置等。DRBD的结构图如图2所示。
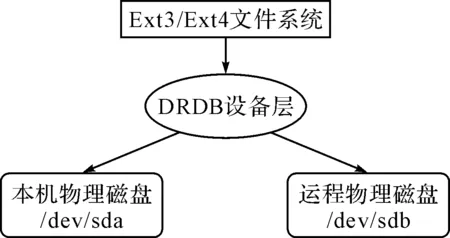
图2 DRBD结构图
DRBD设备在整个DRBD系统中位于物理块设备之上,文件系统之下,在文件系统和物理磁盘之间形成了一个中间层,当用户在主用节点的文件系统中写入数据时,数据被正式写入磁盘前或被DRBD系统截获,同时,DRBD在捕捉到有磁盘写入的操作时,就会通知用户空间管理程序把这些数据复制一份,写入远程主机的DRBD镜像,然后存入DRBD镜像所映射的远程主机磁盘。
· 数据库连接代理组件Amoeba
Amoeba是一个MySQL协议接口的连接代理软件,根据用户事先设置的规则,将SQL请求发送到特定的数据库上执行,基于此可以实现负载均衡、读写分离、高可用性等需求。
同时Amoeba具有承担SQL请求的路由器功能,实现负载均衡、读写分离、高可用提供机制,用户只需结合使用MySQL的Replication等机制即可实现主从同步等功能。
· MMM数据库集群管理套件
MMM管理套件是MySQL主主复制管理器,提供了MySQL主主复制配置的监控,故障转移和管理的一套可伸缩的脚本套件。附带的工具套件可以实现多个Slaves的read负载均衡,因此使用这个套件不仅可以移除一组服务器中复制延迟较高的服务器的虚拟IP,还可以备份数据、调整两节点之间再同步等。
MMM管理套件功能主要通过mmm_mond、mmm_agentd、mmm_control三个脚本完成。
因此由上述软件一起组成了MMM数据库集群优化模型,如图3所示。
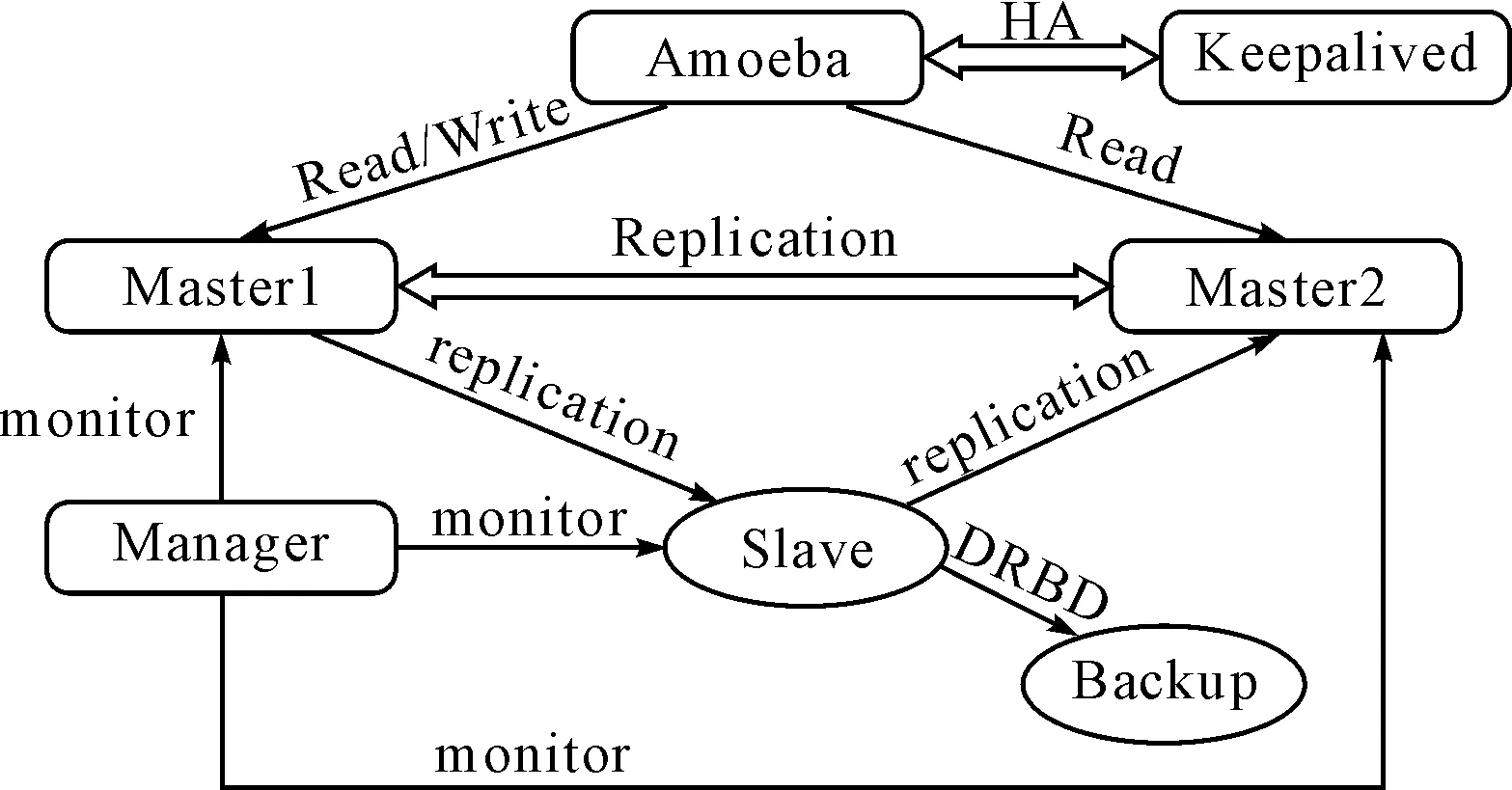
图3 MMM集群优化架构
4 优化模型实现
本次数据库集群的搭建使用六台服务器,服务器的系统环境为RedHat6.4企业版本和64位处理器架构,IP地址的分配网段为10.9.9.0/24,MySQL数据库为mysql-5.5.22.tar.gz和mysql-cluster-gpl-7.2.8.tar.gz。
· Amoeba与Keepalived配置
使用Amoeba作为客户端数据库查询的代理服务,然后配合使用Keepalived实现Amoeba主备服务器之间的高可用,提高系统的稳定性和安全性。前端代理集群使用两台服务器,使用的IP地址为10.9.9.31、10.9.9.32,VIP(虚拟IP地址)为10.9.9.33。具体的IP分配如表1所示。

表1 IP地址分配表
然后在主从两台服务器上分别安装JDK环境和Amoeba、Keepalived软件,其中Amoeba的配置文件主要分为dbServer.xml、amoeba.xml两个文件,dbServer.xml主要完成后端服务器集群的配置,amoeba.xml主要完成对前端代理和用户访问控制的配置;Keepalived通过配置软件安装的依赖包及配置编译参数,实现对Amoeba服务的健康检查和监控,如果Amoeba停止服务,Keepalived会将出故障的主机剔除,并进行主从切换以解决单点故障问题。
启动Amoeba和Keepalived进行测试,在Amoeba出现故障时,VIP自动切换到备份主机,符合预期目标。如图4所示为通过客户端使用VIP访问测试数据库,并停止Amoeba主服务器,系统自动切换到从服务器,并继续连接数据库的情形。

图4 测试数据库并停止Amoeba主服务器
· 构建MMM集群管理系统
数据库集群节点和管理节点的服务器台数为四台,分别安装5.5版本的MySQL数据库和MMM管理套件。具体的节点IP分配如表2所示。

表2 集群节点IP地址分配
由于有三台数据库节点服务器,所有要分配四个读写漂浮IP地址,表3是漂浮IP对应的数据库节点的映射表。
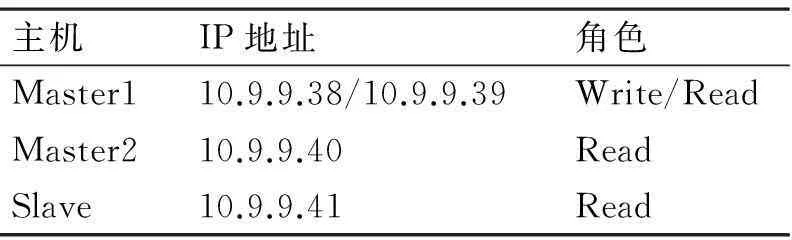
表3 读写IP主机映射
在Master1、Master2、Slave主机上完成MySQL的安装后,需要建立如表4所示的数据库账号,这些账号分别为主从复制账号、MMM代理程序agentd登陆账号、MMM管理服务mond登录账号。
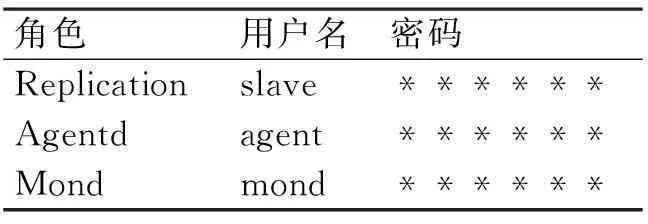
表4 MySQL数据库账号分配
然后登录Master1、Master2、Slave上的MySQL数据库,配置MySQL Replication主从复制,然后启动MySQL-mmm和MySQL数据库,再登陆集群的每个数据库节点执行命令。
至此数据库集群与前端Amoeba的整合完毕,整个集群模型基本实现,再进行数据测试,依次测试应用程序对数据库集群的访问、Amoeba实现的读写分离,实现读操作均衡分布于集群的各个读服务器节点,最后配置DRBD数据同步,实现数据的安全性。
· DRBD数据同步
当整个集群初步搭建完成后,使用集群中的Slave主机作为DRBD数据同步的Master主机,然后加入一台远程备份主机Backup1作为DRBD的Slave,Backup1的IP地址配置为10.9.9.42,在两台主机上分别配置一个100G的磁盘sdb1,作为数据同步的物理设备。在Slave主机上和Backup1上分别源码编译安装DRBD软件,再重新启动MySQL数据库服务,至此,数据库文件迁移完成,整个集群架构搭建完成。其测试效果如图5所示。
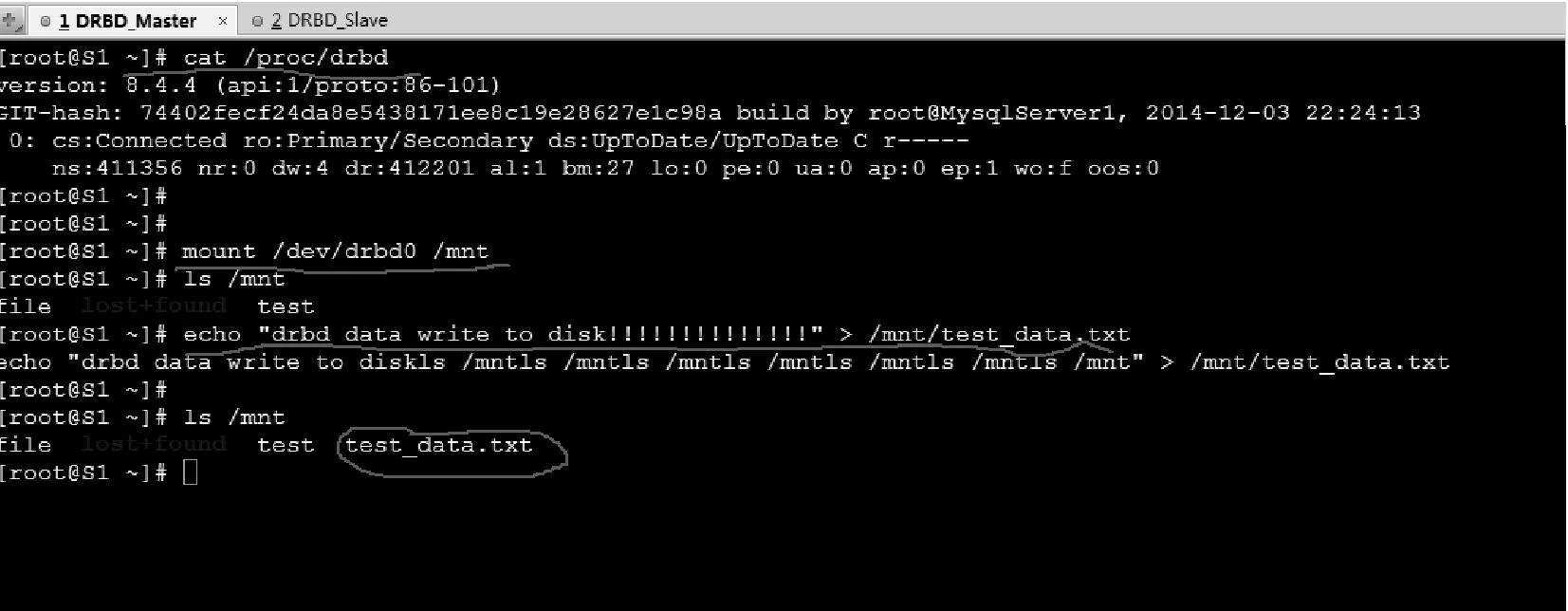
图5 DRBD主服务器测试图
5 结语
本文根据湖南国家农村农业信息化综合服务平台与农村物联网基础平台的运行情况,提出一个基于Linux系统可扩展的MySQL数据库集群双主多从架构MMM优化模型,主要利用Amoeba实现数据库查询的读写分离和负载均衡,通过Keepalived实现Amoeba主从之间单点故障转移,通过MMM数据库集群套件将数据库集群整合,实现对外单一映像的关键问题,使用漂浮IP的方法,将读写IP均分给集群中的各个节点,在集群节点出现故障时,对IP地址进行转移实现集群的高可用,最后通过整合DRBD对数据库文件进行远程同步,有效地提高了整个数据库集群的安全性和稳定性。
参 考 文 献
[1] 黄天天,刘波.湖南农业信息化综合服务平台测试方法分析[J].软件.2013,34(12):172-177.
HUANG Tiantian, LIU Bo. The Testing Methods Based on Hunan Agricultural Information Service Platform[J]. Information Science and Technology,2013,34(12):172-177.
[2] 刘波,沈岳,郭平,等.湖南农业云物联网建设对策分析[J].物联网技术,2013,3(6):76-79.
LIU Bo, GUO Ping, SHEN Yue, et al. The countermeasure analysis of Hunan cloud agriculture IOT construction[J]. Internet of Things Technologies,2013,3(6):76-79.
[3] 刘健,张军伟,邵冰清,等.支持EB级存储的元数据服务器集群系统[J].中国科学:信息科学,2015,45(6):721-738.
LIU Jian, ZHANG Junwei, SHAO Bingqing, et al. Metadata server clustering system for EB-scale storage[J]. Science China Press: Information Science,2015,45(6):721-738.
[4] Ramesh Dharavath, Author Vitae, Chiranjeev Kumar. A scalable generic transaction model scenario for distributed NoSQL databases[J]. Journal of Systems and Software,2015,101(3):43-58

[6] 王学瑞.mysql集群及负载均衡技术及应用[J].信息与电脑,2013,(2):131-132.
WANG Xuerui. The Application and Load Balancing Technologu of MySql Cluster[J]. China Computer & Communication,2013,(2):131-132.
[7] 韦一鸣.基于MySQL复制技术的数据库集群研究[D].杭州:杭州电子科技大学,2014:1-46.
WEI Yiming. Study on Database Cluster Based on MySQL Replication[D]. Hangzhou: Hangzhou Dianzi University,2014:1-46.
[8] 周玉科,马廷,周成虎,等.MySQL集群与MPI的并行空间分析系统设计与实验[J].地球信息科学学报,2012,14(4):448-493.
ZHOU Yuke, MA Ting, ZHOU Chenghu, et al. Design and Implement of Parallel Spatial Analysis System Based on MySql & MPI[J]. Journal of Geo-information Science,2012,14(4):448-493.
[9] M. Smit, B. Simmons, M. Litoiu. Distributed, application-level monitoring for heterogeneous clouds using stream processing[J]. Future Generation Computer Systems,2013,29(8):2103-2114.
[10] 魏斌.高性能MySQL集群部署[J].河南科技,2014(7):6-9.
WEI Bing. The Cluster Deployment of High Performance Based on MySQL[J]. Journal of Henan Science and Technology,2014(7):6-9.
[11] 冯弢.基于云计算下的通信架构模型建立与实现[J].信息通信,2015(5):210-212.
FENG Tao. The Establishment and Implement of a Communication Architecture Model Based on Cloud Computing[J]. Information & Communications,2015(5):210-212.
[12] 金瑛浩.基于MySQ L集群的矢量路径数据库设计研究[J].黑龙江科技信息,2014(8):166-166.
JIN Yinghao. The Design Research of Vector Path Database Based on MySQ L clusters[J]. Heilongjiang Science and Technology Information,2014(8):166-166.
收稿日期:2015年10月9日,修回日期:2015年11月25日
基金项目:国家科技部科技支撑计划课题(编号:2012BAD35B05,2012BAD35B07);湘西南农村信息化服务湖南省重点实验室开放基金课题(编号:XAI20150326);2014湖南省教育厅科研一般项目(编号:14C0542);2015年度湖南农业大学“大学生创新性实验计划项目(编号:XCX14063);2015年湖南农业大学团委科技创新立项项目(编号:制作发明类201502)资助。
作者简介:刘波,男,博士,副教授,硕士生导师,研究方向:软件工程、数据库技术、物联网技术、农业信息化。胡景光,男,研究方向:计算机网络。黄天天,女,硕士研究生,研究方向:计算机应用、农业物联网。
中图分类号TP392
DOI:10.3969/j.issn.1672-9722.2016.04.028
Model Design of Double-Master and Multi-slave Architecture for Database Cluster of Master-Master Replication Manager for MySQL Based on Clouds
LIU Bo1,2,3HU Jingguang1HUANG Tiantian1
(1. Information Science and Technology College of Hunan Agricultural University, Changsha410128)(2. Hunan Provincial Key Laboratory of Information Service in Rural of Southwestern Hunan, Shaoyang422000)(3. Hunan Engineering Technology Research Center of Agricultural & Rural Information, Changsha410128)
AbstractAs the running of Hunan rural integrated services platform of national rural and agricultural information demonstration province and the fundamental platform of the Hunan agriculture IOT, new requirements are proposed by big data operation and safety for agriculture. For the requirement, an optimization model is proposed of master-master replication manager for MySQL on Linux cluster for RedHat and MySQL. Three design models are mainly components of the model, including, the front layer to realize the main switch from MySQL-Proxy, the data service layer to integrate the service node, monitoring and single image, the share data layer to realize remote data synchronization, backup and disaster recovery. The tests have proved that not only the problem of the performance bottleneck of the whole database cluster can be solved by increasing servers by the way, but also the effective service can be achieved through a large of reading and writing under not increasing server hardware performance. The model can enhance the agricultural data security, robustness and reliability under the cloud.
Key Wordsmaster-master replication manager for MySQL, database cluster, MySQL-Proxy, load balance, address drift
猜你喜欢
疯狂英语·新读写(2022年7期)2022-11-22
装备制造技术(2020年3期)2020-12-25
山东陶瓷(2020年5期)2020-03-19
军事运筹与系统工程(2019年4期)2019-09-11
湘潮(上半月)(2019年6期)2019-05-22
音乐教育与创作(2019年9期)2019-05-16
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
中国照明(2016年5期)2016-06-15
