
基于全文检索的文本相似度算法应用研究*
2016-08-11 06:59王格吴钊李向
计算机与数字工程 2016年4期
王 格 吴 钊 李 向
(1.湖北文理学院数学与计算机科学学院 襄阳 441053)(2.中国地质大学(武汉)计算机学院 武汉 430074)
基于全文检索的文本相似度算法应用研究*
王格1,2吴钊1李向2
(1.湖北文理学院数学与计算机科学学院襄阳441053)(2.中国地质大学(武汉)计算机学院武汉430074)
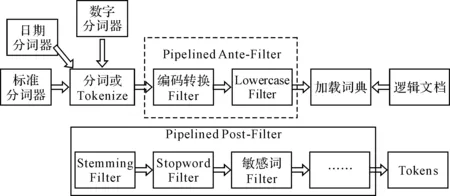
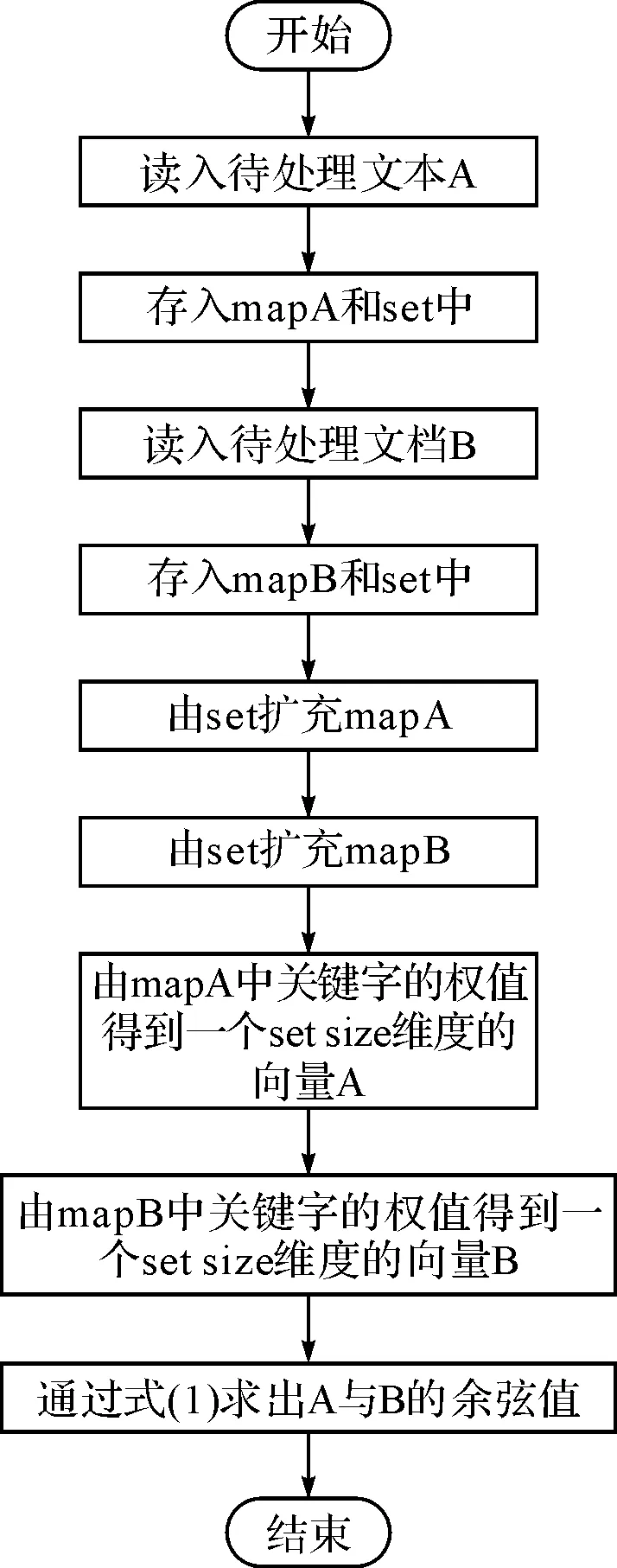
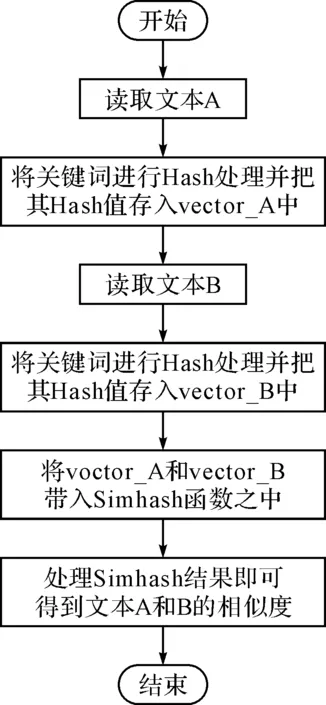
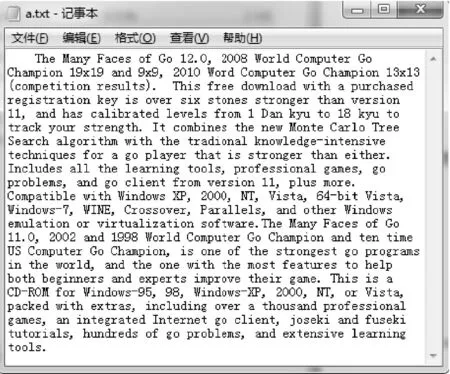
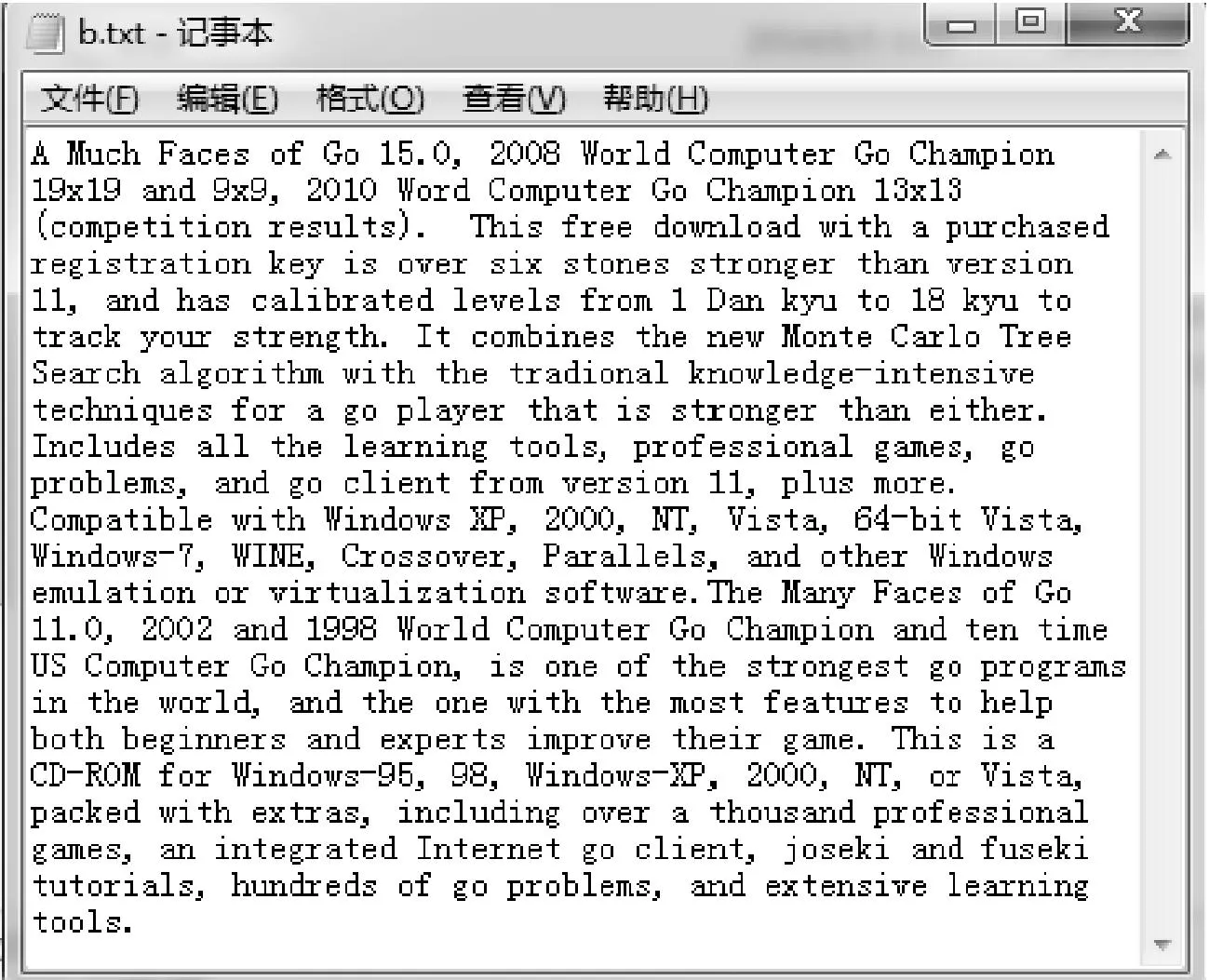
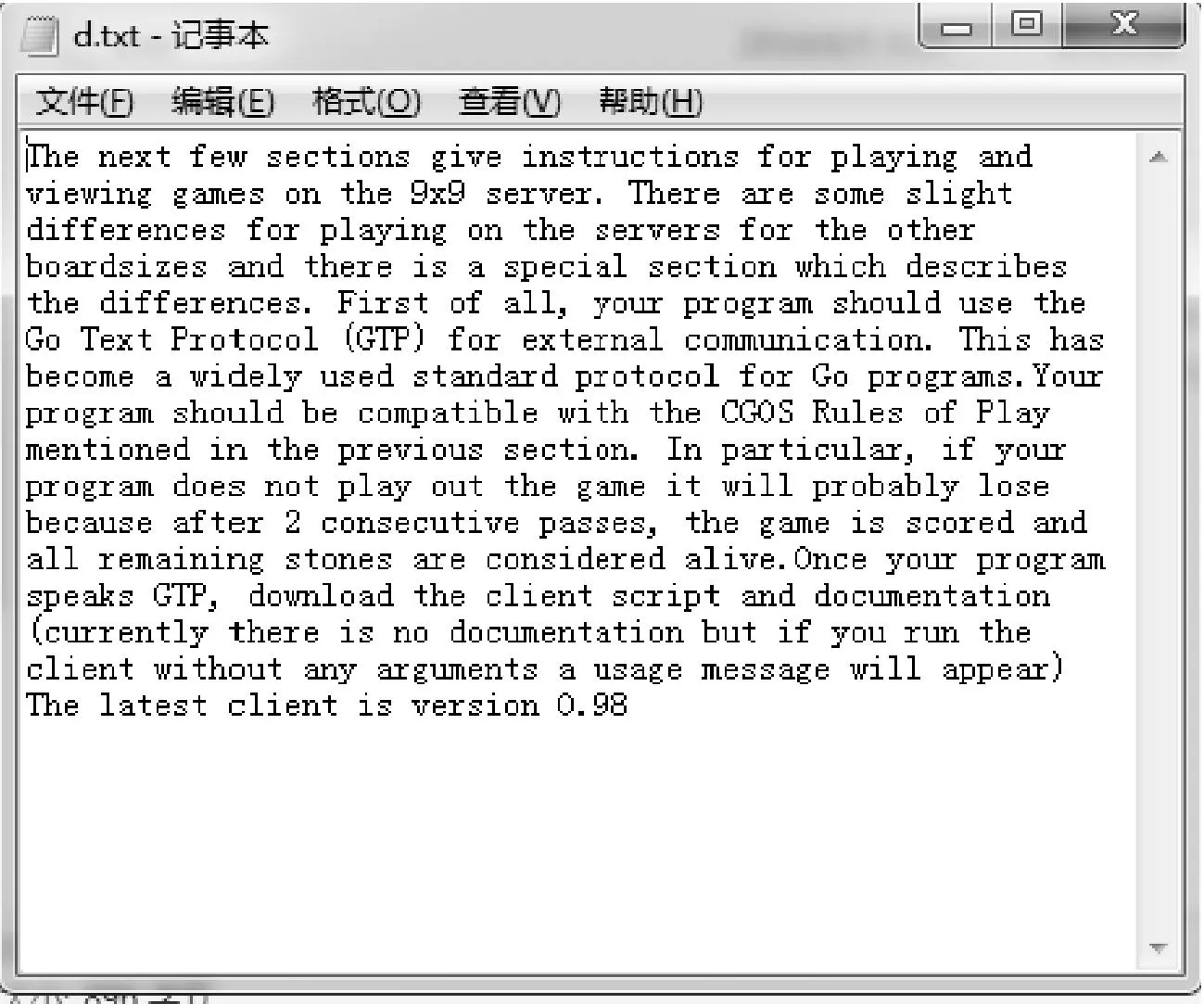
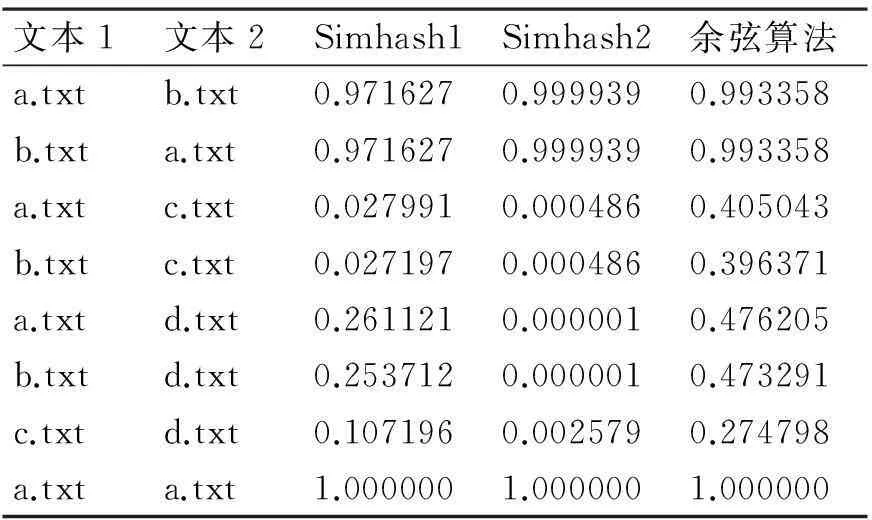
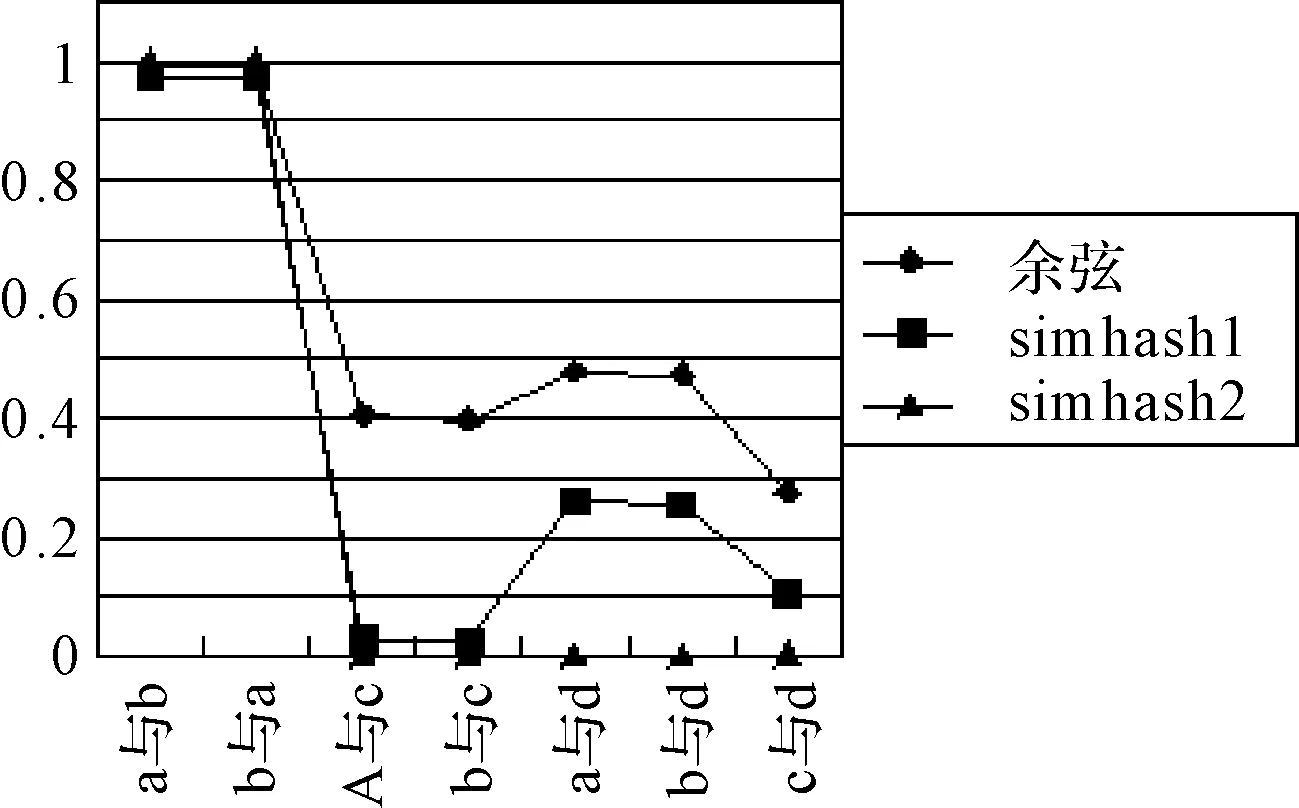
摘要在大量的文本数据中,针对不能快速有效地提取或查找有用信息及知识这个问题,以文本相似度计算为基础的文本数据挖掘成为数据挖掘研究领域里的一个重要的课题。论文主要研究两种不同的方法VSM余弦算法和Simhash来实现文本相似度的计算,首先采用传统的VSM余弦算法和Simhash算法,按照余弦公式通过内积最终计算出文本间的相似度大小n(0 关键词文本相似度; 余弦VSM; Simhash Class NumberTP301.6 文本相似度计算[1]是自然语言处理的一部分,可以计算一个文本中不同词条的相似度,可以计算两个文本间的相似度,也可以进行批处理,对多个文本之间进行两两计算,并输出文本相似度的最后结果。在机器翻译中,相似度可看作是用于衡量文本中词语的可替换程度的参数;在信息检索中,又可理解为文本内容与用户想要搜索的资料的符合程度[2]等。 随着科技的进步,计算机的普及以及Internet的飞速发展,文本信息的大量增长,文本相似度计算在信息检索的效率提高方面,对于发表的文章中抄袭的检测,对于文章相似信息进行压缩存储以便节省存储空间的方面都起到了很大的作用。然而对于英文的文本相似度计算的时候,英文单词本身是有空格分开的,这样以单词来处理一个英文文本进行比较就很简单。 但是中文是没有分隔的,需要加入很多词义,中文是使用多个连续的字如双字、四字成语来表达一个意思,并且在中文的前后语境的不同,一个词语的意思也是不同的,并且有时候中文还会产生歧义,目前对文本的处理方式如图1所示。 图1 文本分词处理方法 长久以来,国内外的很多学者一直在研究文本相似度的计算问题,对于文本相似度计算提出了一些解决的方案。著名的VSM向量空间模型(Vector Space Model)是由Gerard Salton等[3]在1969年首先提出的,文本映射成为N维空间向量,通过向量降维处理,词频统计和比较向量间的关系来计算相似度。在传统的空间向量模型中,所使用的词语向量之间是没有任何语义联系的,仅仅只是不同的词语代表的向量就是不同。为此广义向量空间模型(Generalized Vector Space Model,GVSM)[4]则使用了语义之间的联系,使用文本代替词语来表达文本之间的关系。Deerwester[5]等提出的隐性语义索引(Latent Semantic Indexing)也是文本相似度计算的有效方法,Oleshchuk等[6]在文本相似度计算中引入了本体论,提出了基于Ontology out的文本相似度比较方法,这个方法可以通过语义计算文本词语的相似度。2002年由Google的Charikar[7]提出一种Simhash算法,将一篇文档转化为n位的签名,通过比较签名的相似度来计算原文档的相似度。 国内学者中2001年,张焕炯、王国胜等提出了汉明码的概念[8],利用汉明距离来计算文本相似度,较好地提高了相似度计算速度。2004年晋耀红[9]提出了语境框架的新语义模型,实现了文本间语义相似度的量化,取得了较好的计算效果。2008年,曹恬、周丽、张国煊[10]等提出了基于词共现的文本相似度计算方法。2013王振振[11]等提出了一种基于LDA主题模型的文本相似度计算方法,挖掘隐藏在文本内的不同主题与词之间的关系,能够明显提高文本相似度计算的准确率。 本文对现有的两种文本相似度计算方法VSM和Simhash进行研究,目的是为了对这两种方法的优劣进行更深入的了解,以提高文本相似度计算的精度和有效性,用以对相关的应用起到引导以及参考作用。 文本在向量空间模型中代表的是各种电脑可以识别的数据,该数据使用Document表示,文本的关键字Key是指在该数据中出现而且可以代表该文章不同于其他文章或者代表文章中观点的基本单位,关键字可以用文章之中特定的词语表示,可以用关键字集表示文本为D(K1,K2,…,Kn),其中Ki是关键字,1≤i≤n。 文本之中有a,b,c,d这几个关键字,那么这篇文本就可以用D(a,b,c,d)表示。对含有n个关键字的文本而言,通常会给每个关键字K的出现次数作为其代表的权重W来表示该关键字对文本的重要程度。D=D(K1,W1,K2,W2,…,Kn,Wn),简记为D=D(W1,W2,…,Wn),这种方式叫做该文本D的向量代表方法。 其中Wi是Ki的权重,1≤i≤n。该文本之中,其关键字a,b,c,d的权重分别设置为30,20,20,10,就可以将该文本表示为D(30,20,20,10)。在VSM的向量空间之中,要计算的文本D1和D2的文本相似程度Sim(D1,D2)就可以使用文本之间的计算所得的文本向量余弦值大小表示: (1) 式中,W1i,W2i表示文本D1和D2第i个关键字的权值,1≤i≤n。 在搜索文本的时候就可以计算待搜索文本和数据库中文本的相似度进行余弦计算,其算法的流程图如图2所示。 例如待搜索文本Di的关键字为a,b,c,d,关键字权值分别为30,20,20,10,数据库待核实文本C1的关键字为a,c,d,e,关键字权值分别为40,30,20,10,则D1的向量代表方法为D1(30,20,20,10,0),C1的向量代表方法为C1(40,0,30,20,10),根据式(1)计算待搜索文本D1与数据库中待核实文本C1文本相似度是0.86。 图2 VSM算法流程 文本相似度0.86的计算方法如下。 它的模: (2) 两个向量的点积: (3) (4) (5) 物理意义就是两个向量的空间夹角的余弦数值,下面是代入公式的过程: =2000 (6) (7) (8) (9) 图3 Simhash算法流程图 Simhash算法是由Charikar[6]于2002年提出新的算法,这个算法也是目前被认同为最好、最有效的网页相似内容去重算法,Simhash算法实质上是一种可传统的Hash算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上相当于伪随机数产生算法。而Simhash算法则是基于概率的文本相似度计算方法,对于一篇文章,提取出其中关键词,然后将这些关键词Hash一次,得到n位长度的Hash值,Hash值为1的,特征向量就为1,当Hash值为0,特征向量就为-1,如果要考虑权重,就在特征向量基础上乘以权重,就是这个词的向量值,一篇文档的所有词的向量累加,这个向量为全文主向量,大于或等于零的分量,映射为1,小于0的,映射为0,这相关得出全文的Simhash值,这个叫文本的签名。通过比较不同文本之间签名则可直接得到文本相似度,该算法的流程图如图3所示。 Simhash算法的步骤: 1) 先将文本定义为一个n维的向量D,将D的所有维度均置为0;再定义一个n位的二进制数x作为该文本的特征数并将其初始化为0; 2) 对文本之中每一个关键字:对该关键字使用传统的Hash算法计算得到一个n位的二进制数y; 3) 对于i∈(0,n)进行循环操作: 如果二进制数y的第i位为1,则D的第i个维度的元素值加上该关键字的权重; 如果其为0,D的第i个维度的元素值减去该关键字的权重。 4) 再观察D中的元素值,如果D的第i个元素值大于0,则二进制x的第i位设置为1,否则设置为0,并输出文本的特征数x。 首先将所需要进行文本相似度计算的多个文章进行一个映射,不管这个映射是怎样进行的,只需要得到该文本与其它文本完全不相似的映射,因为Hash算法就是对于不同的数据得到的Hash值是完全不相同的,于是对于每个关键字进行Hash处理,所得到的Hash值是均匀的随机分布,且唯一的。如果一个关键字的Hash结果对应的二进制x的值为101010…0001,则其在算法中对应的向量大小为(k,-k,k,-k,k,-k,…,-k,-k,-k,k)T,其中k为当前关键字的权重,也就是说当其二进制数值为0是当前向量位置就为负值的权重,为1则为权重值大小。然后,将该文本所有的关键字的n维向量进行求和计算,此时会得到一个n位的1,0串,该串就表示该文档的特征数。 为了得到这个n位的1,0串,进行求和计算的时候,如果第i位的数字大于等于1则将x该位的数据置为1,如果小于等于0,则将x该位的数据置为0。 3.1随机超平面Hash算法 Simhash在数学运算中的方法具有可行性,但是,在2个文本相似较高的时候它们的特征数x是否会比较相似,在Google发布的Simhash的方法之中并没有给出Google所使用的具体的Simhash算法和证明,本来在对其进行了试验之后得到了下面的这些想法。 Simhash的算法思路是使用了Sandom hyperplane hash算法,其算法思路为对于一个n维的向量D: 1) 先定义k个n维的向量r1,r2,…,rk; 2) 对每一个向量ri(0 算法之中将每一维的向量都视做一个特定的hyperplane,在D在该hyperplane的投影值大于1则修改x在当前的元素值为1,否则就置其为0。对于2个不同的n维向量A,B来说,它们之间有一个夹角θ,对于任意一个hyperplane来说,能将2个向量分开的概率为θ/π,所以它们的特征数x在某一位的元素值不同的概率也是θ/π。所以可以使用hamming distance来计算2个n维向量之间的特征数所有元素值不同的数值总和来表示不同向量之间的差异程度。 3.2Simhash算法与随机超平面Hash算法的比较 Simhash的算法之中使用Random Hyperplane Hash算法,Simhash并未使用Hyperplane的向量,而是使用关键字在某一位的数值如果为1则不变,为0则置其值为-1,这样便有n位的特征值x得到了n维的空间随机向量。对应了n维的Hyperplane。 下面是一个特殊的例子,首先使用5个关键字来代表某个特定的文本,并且得到一个4位的特征数,所以假设5个关键字的4位特征数分别为x1=1010,x2=1100,x3=1110,x4=1000,x5=0001;则对应的向量为(1,-1,1,-1),(1,1,-1,-1),(1,1,1,-1)(1,-1,-1,-1),(-1,-1,-1,1);再由算法中的第三步可以进行相同位数间的求和运算,得到的结果为(3,-1,-1,-3),由算法中的第四步可以得到文本的特征数x为1001。而对于Random Hyperplane Hash算法来说进行4个5维的向量(1,1,1,1,-1),(-1,1,1,-1,-1),(1,-1,1,-1,-1),(-1,-1,-1,-1,1)按照Random Hyperplane Hash算法可以得到向量D与4个5维向量的乘积结果为(3,-1,-1,3),所求得的文本的特征数也是1001。由两种不同的算法所求得的文本特征数的结果都是1001,可以看出Simhash算法和Random Hyperplane Hash算法的思路是相同的,通过计算Simhash所得的特征数的Hamming distance,可以计算出两个文本之间的相似程度。 由于本文使用的是C++的来进行Simhash的算法设计,由于C++中最大的数据只能使用long long类型来定义的2进制数只有最大2的63次方,在进行Simhash算法的时候还需进行乘法运算,经过测试使用50位的2进制串是比较合适的,但是由于2进制串的位数较少,算法精度不够精准,本文又使用了Python进行编码,再使用C++进行Python的调用,这样就使2进制数的特征数达到了128位,对比2个Simhash的计算数值,也可以看出精度不同的区别。 4.1实验数据 本文处理的文本是由网上找寻的一篇论文之中的几段话,作为实验中的原数据,来进行它们之间的文本相似度计算。 文本a.txt和文本b.txt中的文本数据是比较相似的如图4和图5中所示,用来做一组对照。而c.txt和d.txt中数据之间没有任何的相似度,和a.txt与b.txt也没有任何的相似程度如图6和7中所示。 4.2实验结果与对比分析 系统采用C++MFC界面并在Visual Studio 2010中实现,分别为浏览需要进行比较的文本并显示其访问路径,然后对文本进行Simhash1(C++),Simhash2(Python),余弦算法的计算。 图4 实验数据a.txt 图5 实验数据b.txt 图6 实验数据c.txt 图7 实验数据d.txt 4.2.1实验结果 将实验数据a.txt,b.txt,c.txt,d.txt,进行比较,其中b.txt和a.txt的正反比较以及a.txt和a.txt的比较为对照比较。 表1 实验结果 将实验结果对照的结果用表1和图8表示出来。 图8 实验结果折线图 4.2.2实验结果分析 Simhash算法,对于一篇文章,用分词的方式将它分出词来,然后将这些词Hash一次,得到n位长度的Hash值,Hash值为1的,特征向量就为1,当Hash值为0,特征向量就为-1,如果要考虑权重,就在特征向量基础上乘以权重,就是这个词的向量值,一篇文档的所有词的向量累加,这个向量为全文主向量,大于或等于零的分量,映射为1,小于0的,映射为0,这相关得出全文的Hash值,这个叫全文的签名。 对于文本a.txt和b.txt,它们本身只有几个单词的细微差别,对于整个文本而言是很少的Simhash1计算结果为0.971627,该结果准确度较低;Simhash2的计算结果为0.999939,该结果的准确度相当高;余弦算法VSM的计算结果为0.993358,该结果的精确度也是比较高的。对于文本a.txt和c.txt因为它们之间的联系度非常之低,可以进行结果比较三种算法的准确度。Simhash1的计算结果为0.027991,虽然由于精度的原因该结果还是比较准确度;Simhash2的计算结果为0.000486,该结果是非常准确的;余弦算法VSM的结果为0.405043,该结果就非常不准确了。如数据所示,Simhash1与Simhash2相比较而言,由于C++中long long的数据限制使2进制10串的长度低于Python中128位的2进制10串,所以导致计算结果的不稳定,而余弦算 法,因为其算法本身的原因,其算法的准确度和Simhash1与Simhash2就相差很远。 因此可以得出结论,余弦算法VSM由于其局限性已经不适合进行文本的相似度计算。而Simhash算法不管是因为C++的精度问题还是直接Python进行的128高精度计算都可以看出该基于概率的算法的高准确度具备可行性。 本文对现有的两种文本相似度计算方法VSM和Simhash进行研究,通过对文本进行Simhash1(C++),Simhash2(Python),余弦算法的计算,得出这两种方法的优劣性,余弦算法VSM不适合进行文本的相似度计算,而Simhash算法基于概率的高准确度具有可行性,可以借此来给相关的应用提供参考,提高文本相似度计算的精度和有效性。 参 考 文 献 [1] 宋玲,马军,连莉,等.文档相似度综合计算研究[J].计算机工程与应用,2006,30:160-163. SONG Ling, MA Jun, LIAN Li, et al. The comprehensive computing research on document similarity[J]. Computer Engineering and Applications,2006,30:160-163. [2] 刘丽珍,宋瀚涛.文本分类中的特征选取[J].计算机工程,2004,30(4):14-15. LIU Lizhen, SONG Hantao. The feature selection oftext classification[J]. Computer Engineering,2004,30(4):14-15. [3] Salton G, Wong A, Yang C S. A vector space model for automatic indexing[J]. Communications of the ACM,1975,18(11):613-620. [4] Wong S K M, Ziarko W, Wong P C N. Generalized vector spaces model in information retrieval[C]//Proceedings of the 8th annual international ACM SIGIR conference on Research and development in information retrieval. ACM,1985:18-25. [5] Deerwester S C, Dumais S T, Landauer T K, et al. Indexing by latent semantic analysis[J]. JAsIs,1990,41(6):391-407. [6] Oleshchuk V, Pedersen A. Ontology based semantic similarity comparison ofdocuments[C]//Proceedings of the 14th International Workshop on Database and Expert Systems Applications. IEEE,2003:735-738. [7] Charikar M S. Similarity estimation techniques from rounding algorithms[C]//Proceedings of the thiry-fourth annual ACM symposium on Theory of Computing. ACM,2002:380-388. [8] 张焕炯,王国胜,钟义信.基于汉明距离的文本相度计算[J].计算机工程与应用,2001,21(2):21-22. ZHANG Huanjiong, WANG Guosheng, ZHONG Yixin. The text similarity calculation based on hamming distance[J]. Computer Engineering and Applications,2001,21(2):21-22. [9] 晋耀红.基于语境框架的文本相似度计算[J].计算机工程与应用,2004,16:36-39. JIN Yaohong. The text similarity calculation based on thecontext framework[J]. Computer Engineering and Applications,2004,16:36-39. [10] 曹恬,周丽,张国煊.一种基于词共现的文本似度计算[J].计算机工程与科学,2008,29(3):52-53. CAO Tian, ZHOU Li, ZHANG Guoxuan. A kind of textsimilarity computing based on wordco-occurrence[J]. Computer Engineering and Applications,2008,29(3):52-53. [11] 王振振,何明,杜永萍.基于LDA主题模型的文本相似度计算[J].计算机科学,2013,12:229-232. WANG Zhenzhen, HE Ming, DU Yongping. The text similarity calculation based on the LDA theme model[J]. Computer Science,2013,12:229-232. 收稿日期:2015年10月7日,修回日期:2015年11月23日 基金项目:国家自然科学基金项目“高可靠服务组合快速优化方法研究”(编号:61172084)资助。 作者简介:王格,女,硕士研究生,研究方向:智能计算及应用。吴钊,男,博士研究生,教授,硕士生导师,研究方向:云计算、物联网、大数据处理。李向,男,博士研究生,副教授,硕士生导师,研究方向:智能计算及应用。 中图分类号TP301.6 DOI:10.3969/j.issn.1672-9722.2016.04.001 Application of Text Similar Algorithm Based on Full-text Retrieval WANG Ge1,2WU Zhao1LI Xiang2 (1. School of Mathematics and Computer Science, Hubei University of Arts and Science, Xiangyang441053)(2. School of Computer Science and Technology, China University of Geosciences, Wuhan430074) AbstractIn a large number of text data, due to the problem that it can’t quickly and efficiently find useful information and knowledge, text data mining on the basis of the text similarity calculation becomes an important research topic in the field of data mining. In this paper, Simhash and VSM cosine algorithm are used to realize the text similarity calculation. First, the traditional VSM cosine algorithm and Simhash algorithm are adopted to calculate the degree of similarity between the text size n(0 Key Wordstext similarity, cosine VSM, Simhash1 引言
2 VSM算法
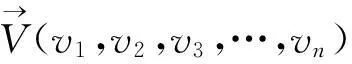


3 Simhash算法
4 实验结果以及结果分析

5 结语
