
某高校科研社交网络社区结构的研究
2016-08-08 03:45夏欢刘辉张春
常州工学院学报 2016年3期
关键词:爬虫
夏欢,刘辉,张春
(安徽工业大学计算机科学与技术学院,安徽马鞍山243032)
某高校科研社交网络社区结构的研究
夏欢,刘辉,张春
(安徽工业大学计算机科学与技术学院,安徽马鞍山243032)
摘要:对某高校的科研人员而言,其学术论文一经发表,均可被网页检索,通过爬虫从网络上获取论文数据信息,数据处理后可得到作者之间的论文合著关系,再用复杂网络分析软件Pajek构建出科研社交网络,最后在科研社交网络中利用社区发现模型进行社区划分,得到科研社区结构。同时,在科研社区下进行个性化推荐等服务,由于服务的对象更明确,其推荐准确度和效率明显提高。所以,在科研社交网络下,社区结构的研究成果为之后的学术论文推荐等服务提供了支持。
关键词:爬虫;论文合著关系;科研社交网络;科研社区
0引言
图结构或网络结构可以表示现实中的很多复杂系统[1],社交网络可以看作无向图,由用户(节点)和用户之间的关系(边)构成,其可以划分为若干个社区。在一个社区内的成员间联系紧密,不同社区的成员之间联系稀疏。因此,在科研社交网络中发现社区结构,以及每个用户所属的社区,其结果或许能够揭示一些潜在的关系进而对一些现象给出合理解释[2]。
近年来,越来越多的学者开始关注复杂网络中社区结构的研究。最早期的社区发现是Newman等于2004年提出的,是基于模块度的社区挖掘算法[3],之后各种社区发现的研究相继出现,Palla等[4]提出了派系过滤算法,简称CPM算法,可以发现重叠社区结构。Gregory[5]提出了一种重叠社区发现的两阶段策略,首先通过节点介数分割节点,将原始网络转换成一个新的网络,然后在转换后的网络上使用分裂算法对社区进行划分。Chen等[6]提出了一种快速的重叠社区发现算法,算法从只有1个节点的初始社区出发,不断对社区进行扩展。陈端兵等[7]提出了重叠社区发现的两段策略,将社区划分为2个阶段,即初始社区抽取和社区合并,并能有效地挖掘网络中的重叠社区。骆挺等[8]提出了一种新的社区发现算法,是基于完全子图的。
本文主要研究某高校计算机学院科研社交网络的社区结构,主要包括科研社交网络的构建和社区发现两方面。通过爬虫算法获取网络上的论文信息,数据处理后用Pajek构建科研社交网络,再在科研社交网络中利用社区发现模型进行社区结构的研究,为之后的个性化推荐服务提供支持。
1基于科研社交网络的社区发现模型
1.1节点与社区的连接度
对于给定的节点u和社区c,u和c之间的连接度L(u,c)[7]可定义为
(1)
式中:u为当前节点,当节点u与节点v有边相连时,则wuv=1,否则wuv=0;Dn为节点n的度。
如图1,假设社区c包含1~5个节点,则节点3与社区c的连接度L(3,c)=4/5=0.8。
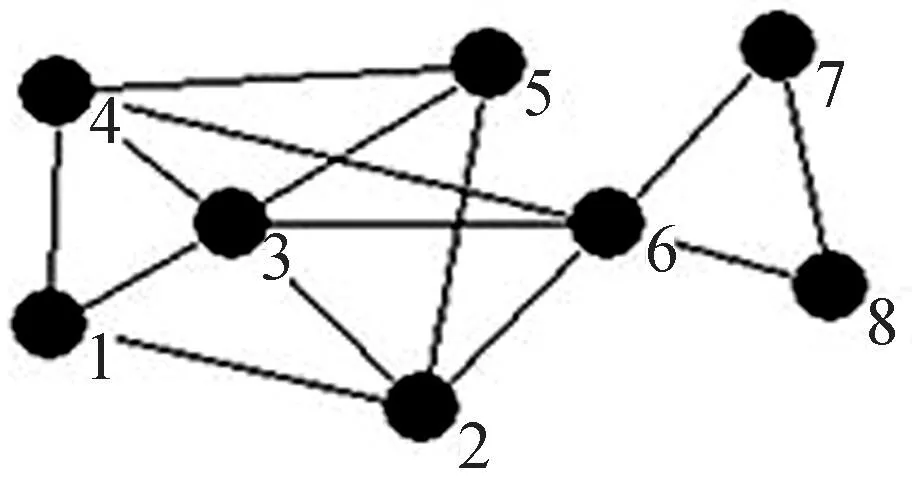
图1 网络示意图
1.2模块度
模块度Q用来衡量社区划分的效果,其概念由Newman和Girvan于2004年最先提出[3]。后来,各种模块度的定义相继产生。本文选用Shen等定义的模块度[9],可适用于重叠社区和非重叠社区的情形,定义方式为
(2)
式中:m是网络的总边数;Aij为网络的邻接矩阵;Oi表示节点i所属的社区个数;ki,kj分别表示节点i和j的度;当节点i,j在同一个社区时,则δ(Ci,Cj)函数值为1,否则为0。
1.3社区发现模型
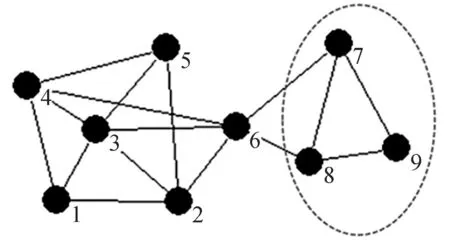
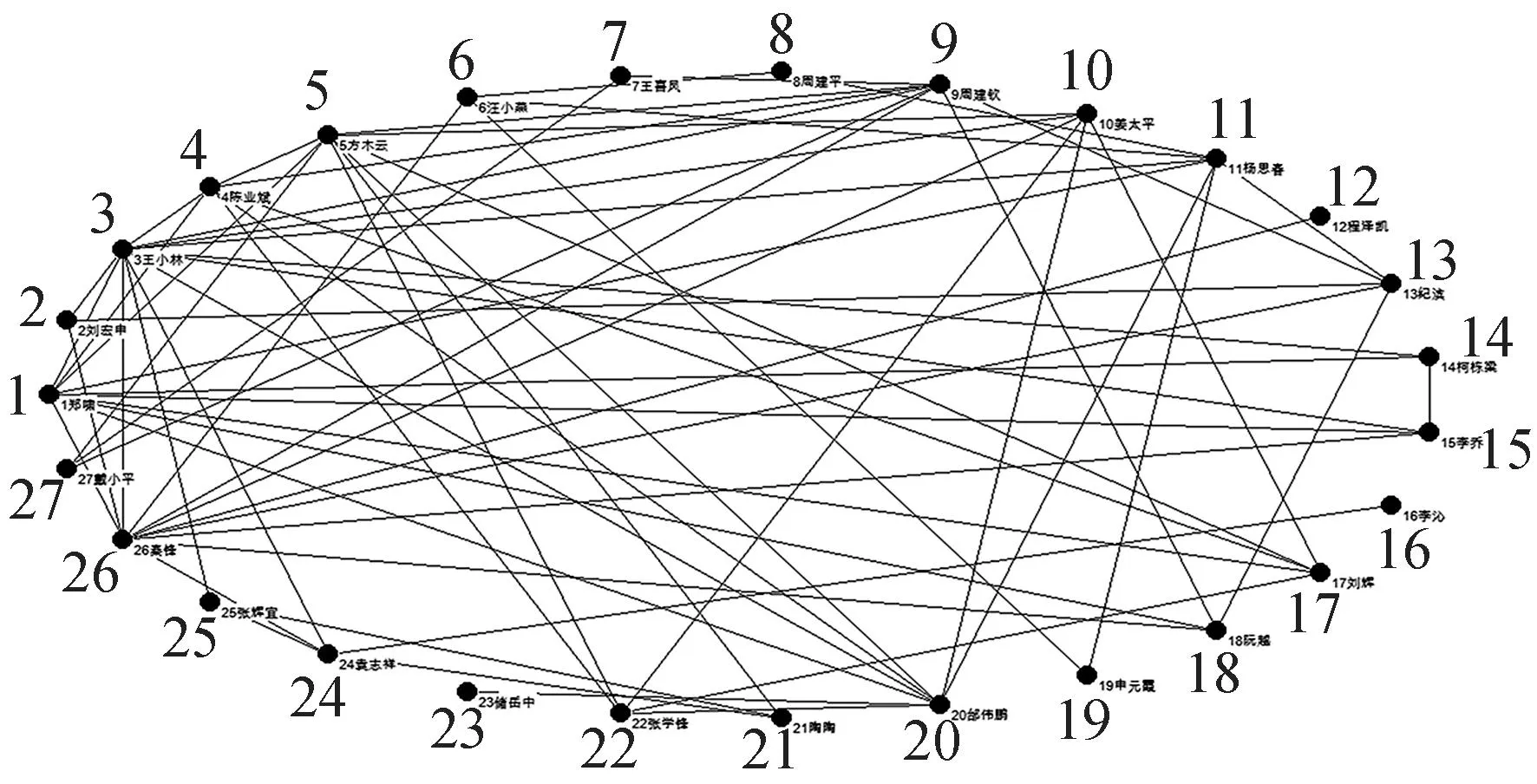
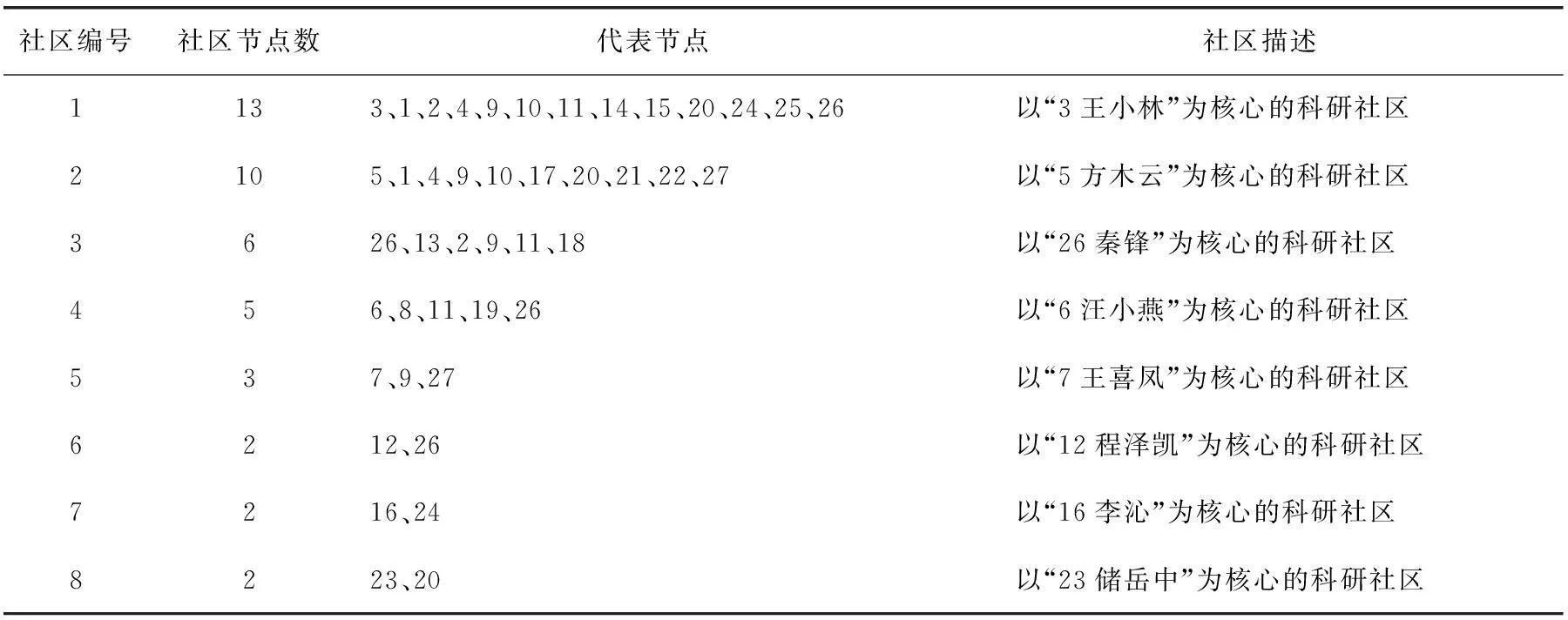
本文的社区发现算法标记科研社交网络中的所有节点为F,当某个节点被划分社区后,则将其标记为T。从标记为F的当前最大度节点开始,将邻居节点加入,形成初始社区,并按式(1)计算当前社区内的每一个节点与社区的连接度,将连接度 图2~3对本文算法进行了说明,标记所有的节点为F。 图2 社区c1划分 图3 社区c2划分 首先,3的度最大,作为社区核心,3的邻居节点1、2、4、5、6加入,3、1、2、4、5、6作为初始社区c1,并分别计算L(1,c1)=L(2,c1)=L(4,c1)=L(5,c1)=1>0.5,L(6,c1)=3/5=0.6>0.5,所以保留所有节点在初始社区中,不移除。其次,判断c1的邻居节点7、8,由于L(7,c1)=L(8,c1)=1/3<0.5,故不加入c1。最终,第1个社区划分为c1。图2中虚线框显示了第1个社区c1的划分,并标记已被划分社区的节点为T。再在剩余的标记为F的节点7、8、9中判断,最大度节点为8,邻居节点6、7、9与8作为1个初始社区c2,但L(6,c2)=2/5=0.4<0.5,故将节点6从c2中移除,初始社区c2变成节点7、8、9,再判断c2的邻居节点6,由于L(6,c2)=2/5=0.4<0.5,故不加入c2,最终第2个社区划分为c2,图3中虚线框显示了第2个社区c2的划分。 算法的主要步骤如下: ①标记网络中所有的节点为F,List为发现的社区,初始为φ; ②当网络中存在标记为F的节点时,选取标记为F且度值最大的节点和其邻居节点,这些节点形成一个初始社区c; ③对于当前社区内的每一个节点v,计算节点与本社区的连接度L(v,c); ④如果L(v,c) ⑤找出社区c的所有邻居节点,记为Nc; ⑥对于Nc中每一个节点v,计算节点与社区的连接度L(v,c); ⑦如果L(v,c)≥LV,则将节点v加入社区c,得到新的社区,仍记为c; ⑧将社区c中的节点标记为T; ⑨重复步骤②~⑧,最终发现所有的社区为List=List∪{c}。 2实验结果与分析 本文用截至2015年12月份前某高校计算机学院研究生导师的论文合著情况作为数据集,进行科研社交网络的构建。先用网络爬虫算法从网络上获取用户的论文发表信息,包括作者和论文题目,存入mysql数据库中,再数据处理成Pajek的数据格式,利用Pajek构建出该高校的科研社交网络,是一个无向无权网络,如图4所示。 图4 科研社交网络图 对于构建出的科研社交网络,用Java语言编程实现本文的社区发现模型。表1是各个不同研究领域的科研人员,根据论文合著关系构建的科研社交网络得到的社区划分结果,并得出模块度Q值较高,为0.495 0,说明社区划分效果良好。 表1 社区划分情况 本文的社区发现模型得到8个社区划分,分别是以 “3王小林”“5方木云”“26秦锋”“6汪小燕”“7王喜凤”“12程泽凯”“16李沁”“23储岳中”为核心的科研社区,同一社区内的科研人员之间在学术科研上有着一定的共性。经过与该高校计算机学院的实际科研团队进行对比,本文的社区划分模型的结果与实际情况基本一致。 由此可知,该社区发现模型对科研社交网络社区结构的划分较精确,为进一步的网络结构分析、功能演化预测以及论文推荐等精确的个性化服务提供了支持。 3结语 本文主要研究某高校科研社交网络的社区结构,分为科研社交网络的构建和社区发现两方面,通过爬虫获取网页上用户的论文发表信息,进行数据处理后构建出科研社交网络,为下一阶段的社区发现奠定基础。在社区发现阶段,通过寻找网络中的最大度节点,加入邻居节点及连接度判断,不断扩充社区,最终发现所有的社区结构。这些社区结构能真实地反映出科研人员之间一种隐匿的学术上的紧密关系,在科研社区下进行个性化推荐服务的研究,减少了传统推荐中对所有用户依次进行判断的开销,提高了推荐的精度和效率,并在一定程度上提高了算法的稳定性和社区发现的质量。 因此,本文提出的模型对科研社交网络后期的功能演化预测提供了帮助,下一步将对更大规模的科研平台进行科研社交网络的构建和社区发现的研究,旨在为后续的个性化推荐服务提供支持。 [参考文献] [1]NEWMAN M E J.The structure and function of complex networks[J].SIAM Review,2003,45(2): 167-256. [2]李春英,汤庸,汤志康,等.面向大规模学术社交网络的社区发现模型[J].计算机应用,2015(9): 2526-2568. [3]NEWMAN M E J,GIRVAN M.Finding and evaluating community structure in networks[J].Physical Review E,2004,69(2): 026113. [4]PALLA G,DERENYI I,FARKAS I,et al.Uncovering the overlapping community structure of complex networks in nature and society[J].Nature,2005,435(7043): 814. [5]GREGORY S.Finding overlapping communities using disjoint community detection algorithms[M]//Complex Networks. Heidelberg:Springer,2009:47-61. [6]CHEN D,SHANG M,LV Z,et al.Detecting overlapping communities of weighted networks via a local algorithm[J].Physica A: Statistical Mechanics and its Applications,2010,389(19): 4177-4187. [7]陈端兵,尚明生,李霞.重叠社区发现的两段策略[J].计算机科学,2013,40(1): 225-228. [8]骆挺,钟才明,陈辉.基于完全子图的社区发现算法[J].计算机工程,2011,37(18): 41-43. [9]SHEN H,CHENG X,CAI K,et al.Detect overlapping and hierarchical community structure in networks[J].Physica A: Statistical Mechanics and its Applications,2009,388(8):1706-1712. 责任编辑:陈亮 doi:10.3969/j.issn.1671-0436.2016.03.013 收稿日期:2016- 03-30 作者简介:夏欢(1992—),女,硕士研究生。 中图分类号:TP301 文献标志码:A 文章编号:1671- 0436(2016)03- 0056- 04 Community Structure of a University on Scientific Research Social Networks XIA Huan,LIU Hui,ZHANG Chun (College of Computer Science and Technology,Anhui University of Technology,Maanshan 243032) Abstract:For the scientific researchers at a university,their academic papers can be searched on website once published.Paper data was acquired by crawler and processed to obtain the paper co-authorship,then the scientific research social networks was built using Pajek,a complex network analyzing software,and finally the structure of scientific research community was obtained after community division by applying a community detection model.Services like personalized recommendations in these communities had improved remarkably with greater accuracy and efficiency because of definite clients and service areas.Results of the community structure study on scientific research social networks provided support for future services like paper recommendation. Key words:crawler;paper co-authorship;scientific research social network;scientific research community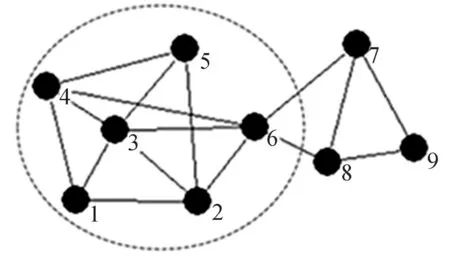
 猜你喜欢
房地产导刊(2022年10期)2022-10-18开封大学学报(2021年1期)2021-07-01现代信息科技(2021年21期)2021-05-07网络安全和信息化(2020年5期)2020-12-29计算机与数字工程(2020年10期)2020-12-07数码设计(2019年5期)2019-12-20智能计算机与应用(2018年5期)2018-10-20计算机与网络(2018年10期)2018-06-14电脑知识与技术·经验技巧(2018年1期)2018-05-30电子制作(2018年2期)2018-04-18
猜你喜欢
房地产导刊(2022年10期)2022-10-18开封大学学报(2021年1期)2021-07-01现代信息科技(2021年21期)2021-05-07网络安全和信息化(2020年5期)2020-12-29计算机与数字工程(2020年10期)2020-12-07数码设计(2019年5期)2019-12-20智能计算机与应用(2018年5期)2018-10-20计算机与网络(2018年10期)2018-06-14电脑知识与技术·经验技巧(2018年1期)2018-05-30电子制作(2018年2期)2018-04-18
