
基于优先级动态二进制翻译寄存器分配算法
2016-08-04 06:18卢帅兵
浙江大学学报(工学版) 2016年7期
戴 涛,单 征,卢帅兵,石 强,潭 捷
(解放军信息工程大学 数学工程与先进计算国家重点实验室,河南 郑州 450002)
基于优先级动态二进制翻译寄存器分配算法
戴涛,单征,卢帅兵,石强,潭捷
(解放军信息工程大学 数学工程与先进计算国家重点实验室,河南 郑州 450002)
摘要:针对动态二进制翻译系统QEMU寄存器分配不考虑基本块之间对寄存器需求的差异性,造成不必要寄存器溢出而导致重复访存开销的问题,提出高效的基于优先级线性扫描寄存器分配算法.该算法基于中间表示与源平台寄存器之间的映射关系,获取每一次生成基本块中间指令预分配寄存器次数并统计排序确定寄存器的优先级,寄存器分配时动态调整寄存器分配顺序,减少寄存器溢出次数,降低生成本地代码指令数量.QEMU动态翻译x86、mips及arm平台的nbench测试集实验结果表明,该算法基于中间代码改进具有很好的跨平台性,有效减少了生成本地代码指令数目,比QEMU优化前翻译性能分别提升了6.7%、6.8%、4.7%.
关键词:动态二进制翻译;寄存器分配;QEMU;中间指令
二进制翻译是一种即时的编译技术,将一种体系结构的指令集转换成另外一种指令集并可执行的技术[1].翻译的过程分成前端解码器、中端优化器以及后端编码器[2].前端解码依据源机器指令的特点,将机器指令翻译成成汇编指令,分离出每条机器指令完成类似反汇编的功能.中端优化器的主要工作是变换生成的中间代码[3-4],通过分析基本块内中间代码组织关系简化中间代码,如常量传播[5]、变量活性分析[6]、标志位优化[7]等方法剔除冗余指令[8].后端编码器的作用是将中间代码转换生成本地可执行的指令流.
与传统编译器不同的是动态二进制翻译的寄存器分配是在程序运行的过程中,即后端编码过程,传统编译器高效的寄存器图着色法[9-10]无法在动态二进制翻译中使用,动态二进制翻译系统中常采用基于线性扫描方法的寄存器分配方法[11-12].Alei等[13]对QEMU寄存器的管理及分配机制进行详细的描述,但未给出一种有效的改进方法.吴浩[14]基于在X86平台翻译ARM程序,采用直接映射寄存器分配策略,通过大量对比实验验证中间表示的存在降低了二进制翻译的性能,但是需要大幅度的修改QEMU的翻译机制.文延华等[15]在Alpha平台翻译PowerPC程序时,对PowerPC的特殊寄存器的二进制翻译中模拟,提出分段映射和特殊寄存器裁剪相结合的方法并获得一定的优化效果,但由于寄存器裁剪函数的复杂性,可被优化的程序比较少.廖银等[16]在MIPS平台模拟X86平台寄存器时采用直接映射的策略,利用本地平台通用寄存器数量多的特点,直接将X86的8个通用寄存器分配到MIPS的通用寄存器上,一一映射,简化指令翻译的规则,降低了代码膨胀率.该方法需求特定平台硬件基础,不具有很好的通用性,移植性较差.Cai等[17]在cross-bit系统中提出简化的寄存器图着色法,使用3个链表收集变量定值引用信息,将使用到的变量构造成一个图,此后在每次发生一次溢出时重新构造冲突图,该方法因为寄存器溢出需要每次进行图的构造大大增大了翻译的开销,整体的效率提升有限.Liang等[18]基于QEMU的中间表示分析变量的定值与引用,使用链表存储变量的生命周期和使用,减少中间表示指令数目,由于需要多次遍历采集基本块内变量的定值与引用信息,算法的复杂度较高且不具有良好的移植性.
本文重点阐述QEMU翻译原理、中间表示的临时变量与寄存器分配之间的关系以及寄存器分配机制,基于中间代码与平台无关的特点,提出改进的基于优先级线性扫描寄存器分配方法.通过统计基本块内中间表示每条指令预分配寄存器数量,对寄存器预分配次数排序确定各个寄存器在基本块内分配的优先顺序,减少因寄存器溢出导致冗余访存指令,提高程序的执行效率.
1相关工作
QEMU[19]是一个广泛使用的多源到多目标动态二进制翻译系统,可以支持用户级和系统级二进制翻译.采用一种与平台无关(Tinycodegeneration,TCG)微指令的中间表示,不同源平台程序只需要变换前端解码器而不需要改动后端编码器,即可实现多源到多目标平台的动态翻译,具有很好的跨平台特性.QEMU动态翻译的基本原理是利用指令变换时的语义等价,将源体系程序的指令翻译成一条或者多条TCG中间语言表示,然后将TCG中间表示指令变换成目标平台的一条或者多条指令,保证上述两者转换过程中指令语义的一致,实现不同平台上指令的等价.
基本块是QEMU翻译和执行的基本单位,拥有单个入口和单个出口,以跳转指令结尾若干条指令序列.基本块的执行流程可以分为以下两种.
一种是块链执行,块链的形成是在执行多个基本块指令时可能发生,指的是将翻译好的几个tb(translationblock)直接通过jmp指令连接起来,执行完一个tb时,不再需要跳转到翻译流程去查找下个要被执行的tb,直接通过jmp指令跳转到已翻译好的tb,直到无法确定跳转目标地址或者发生异常才返回翻译流程.基本思路是基于在直接跳转的情况下,跳转目标是确定的且不发生变化,翻译时在该分支插入一条原地跳转指令,待前驱翻译确定跳转地址后,将原地跳转指令的地址改成真实的地址,下一次执行该分支时,直接跳转到指定的基本块中,省去上下文切换和重复翻译开销.如图1(b)所示为经过块链后程序的执行流程.
另外一种是基本块交替执行,即翻译和执行交叉进行,如图1(a)所示为未进行块链程序执行的过程.翻译后主体代码由三部分实体组成:Prologue、Epilogue及一个或多个基本块.Prologue代码用于保存目标平台上状态,包括通用寄存器、堆栈等信息;然后利用jmp指令跳转入基本块的入口地址,完成目标平台到虚拟机状态的转换.基本块指令流执行完后,都需要执行exit_tb指令,表明虚拟机的指令流已执行完成,下一步执行翻译流程,跳转Epilogue代码入口地址,进行本地寄存器恢复,退出虚拟机,执行本机指令.以上即为动态二进制翻译系统QEMU翻译和执行两个状态切换流程.

图1 多个基本块执行过程Fig.1 Multiple basic blocks execution process
1.1TCG微指令
TCG指令格式定义为DEF(name,oargs,iargs,cargs,flags),所有微指令包含在tcg/tcg-opc.h中.在结构体TCGOpDef中对每一个成员变量有详细的说明,其中name为微指令的名字,oargs为指令输出参数个数,iargs为指令输入参数个数,cargs为指令常数个数,flags标志指令是否影响内存内容.此外,还有args_ct与sorted表示参数约束属性,该参数与结构体系的寄存器紧密相关.TCG指令类似于一种精简指令,和普通处理器一样,拥有数据传送、算术运算、逻辑运算、程序控制指令及其他指令[20].
TCG指令的操作数称为临时变量,构成TCG中间表示基础,通过使用临时变量作为源机器指令操作数到目标机器指令数据存储、传送与计算.根据临时变量生命周期的不同划分,TCG定义了4种变量类型:普通变量(temp)、普通本地变量(temp_local)、全局变量(globaltemp)和全局寄存器变量(globalregtemp).TCG变量统一用结构体TCGTemp进行描述,默认可分配TCGTemp个数为512.若超过该数目,则异常中止程序翻译.变量类型依靠结构体TCGTemp的标志位进行区分.此外,4种类型临时变量作用域各不相同,程序处理机制也不同.其中全局变量和全局寄存器变量生命周期存在于整个程序的翻译过程,只有程序退出时才被回收.全局寄存器变量一般是固定分配宿主机某一个寄存器值,用来保存源机器CPUState结构体的指针,实现源机器状态数据的快速读取,加快程序执行速度.普通变量生命周期范围为一个基本块,基本块执行结束变量被标注为“释放”状态,备下一条指令使用.普通本地变量的生命周期为一个函数范围内,与普通变量不同的是在某些基本块末尾处需要程序保存执行时的数据流信息以供下一个基本块使用,需要将基本块的执行信息进行回写.
1.2临时变量
临时变量内容均存储在TCG上下文的512个TCGTemp的static_temps静态数组中.其中全局变量和全局寄存器变量采取一次性分配策略建立运行时环境,在以后翻译的过程中不会再进行分配,生命周期贯穿程序始终.全局变量源机器平台运行环境ENV一般用全局寄存器变量表示,而源机器平台如标志寄存器用全局内存变量表示,存储分布在静态数组static_temps空间的起始处;普通变量和普通本地变量依据源机器指令进行动态的分配存储在数组后面部分,每分配出一个,则将该空间打上标记进行标识.临时变量的存储空间布局如图2所示.
TCG分成4种不同类型的临时变量,各种变量空间分配机制不尽相同,释放机制也各不相同,TCG采用不同的函数接口进行释放.为了管理临时变量内存释放空间,TCG在上下文结构体TCGContext用4个first_free_temp整型静态数组存储记录static_temps数组中32位普通变量、32位普通本地变量、64位普通变量和64位普通本地变量类型释放空间位置.该数组存储值表示static_temps数组中的已被释放索引,每释放出一个空间先将该空间的分配标识清除,其次将first_free_temp存储的索引赋值给下一个释放出空间,即TCGTemp->next_free_temp=TCGContext->first_free_temp,同时修改TCGContext->first_free_temp的值,于是TCGContext->first_free_temp实际上是一个拥有4个释放空间的链表数组,TCGContext->first_free_temp存储的永远是该链表的头,如图3所示.
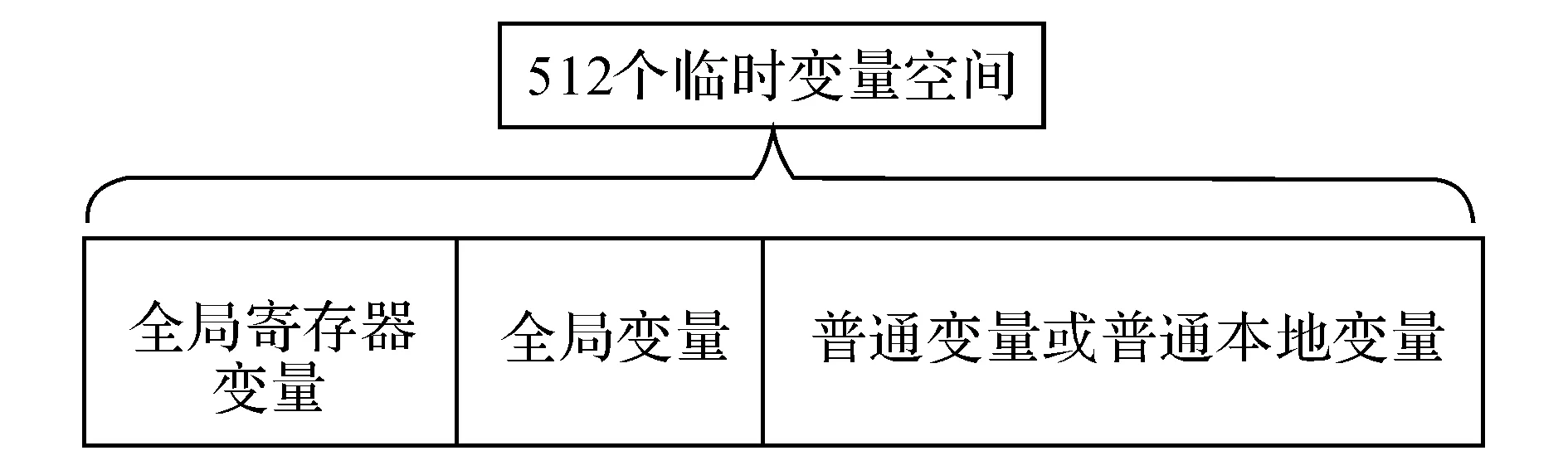
图2 临时变量内存布局Fig.2 Temporary variable memory format
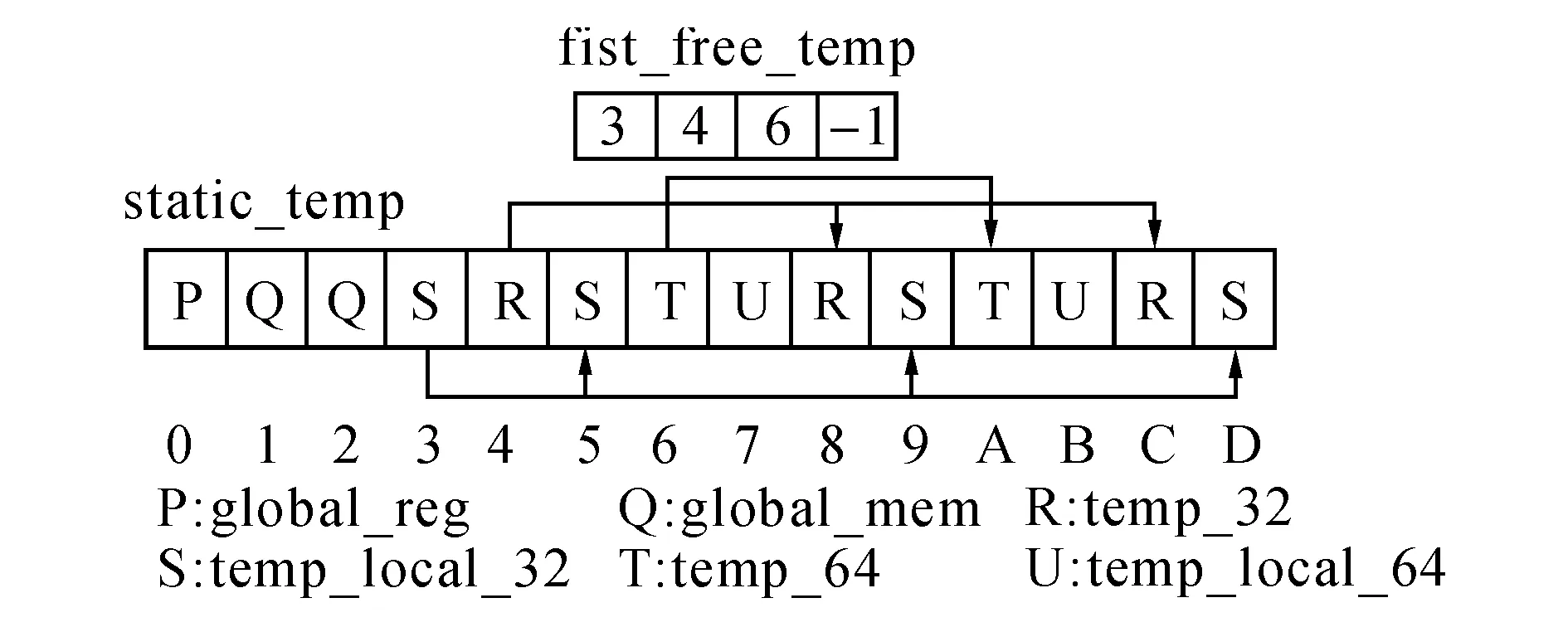
图3 释放的空闲空间链表组织方式Fig.3 Free space linked list organization
图3中,P为全局寄存器变量,Q为全局变量,R为32位普通变量,S为32位普通本地变量,T为64位普通变量,U为64位普通本地变量.static_temps索引序号3, 4, 5, 6, 8, 9,a,c,d均为释放空间,索引序号0, 1, 2, 7,b表示已分配空间,3→5→9→d是32位普通局部变量释放的空闲空间链表,4→8→c为32位普通变量已释放的空闲空间链表,6→a为64位普通变量释放的空闲空间链表.first_free_temp存放的是释放空间链表头在临时变量static_temps存储空间的索引,图中共有3个链表,头索引号分别为3、4、6,所以数组first_free_temp的前3个字节存储3个链表的头索引值,由于临时变量存储空间中没有释放出64位普通本地变量已分配的空间,在静态数组first_free_temp第4个字节用-1表示.
2TCG寄存器分配策略
寄存器作为CPU体系最重要的信息存储部件,它的取值与存储速度远比内存快很多,是CPU的宝贵资源.它的利用效率直接影响程序的执行速度.动态二进制翻译系统的机制是将源体系的可执行代码翻译成中间代码,然后将中间代码转换成本地代码指令的过程.从寄存器映射的角度来看,是从源体系的寄存器直接映射到虚拟机维护的一套内存虚拟寄存器,再由虚拟寄存器映射到目标体系上的寄存器的过程,临时变量是上述寄存器转换的“传输者”.寄存器本地分配的主体包括以下两部分:一部分是内存虚拟寄存器,另外一部分是中间代码使用的变量.传统编译器寄存器分配时是为每个变量分配虚拟寄存器变量,然后在寄存器分配阶段为每个虚拟寄存器分配真实的寄存器.TCG与此相类似,其中的临时变量类似传统编译器中的虚拟寄存器.一套虚拟寄存器是一连续的内存区域,目标体系寄存器与虚拟寄存器一一对应.内存虚拟寄存器相对于通用寄存器而言不存在差异性,为存储中一段内存空间.源体系的寄存器与内存虚拟寄存器的映射思想比较简单,实现两者一对一的映射即可,以翻译x86可执行程序为例,如图4所示.

图4 源体系寄存器与虚拟寄存器之间的映射Fig.4 Mapping between source system register and virtual register
对于内存虚拟寄存器,QEMU采用直接映射方法,分配成固定的寄存器绑定方法,如x86的宿主机用ebp寄存器指向env,利用ebp寄存器偏移即可获取整个虚拟寄存器,实现源体系寄存器到本地寄存器的映射.
2.1临时变量与本地寄存器分配关系
中间代码临时变量进行本地寄存器分配时,思想复杂得多.因中间指令语义各不相同,操作数个数差异或操作数之间的依赖关系等,临时变量寄存器分配与中间指令紧密相关.为了确定每条中间指令可分配的寄存器,在QEMU定义了一结构体TCGTargetOpDef数组,确定了每条中间指令的操作数与目标平台寄存器之间的关系,包括每个操作数可分配本地寄存器范围、操作数之间的依赖关系等.以可供分配的寄存器共有7个的宿主机x86为例,如图5所示.
st8_i32指令的原型声明是st8_i32t0,t1,offsetadd_i32指令的原型声明是add_i32t0,t1,t2.结构体数组的第一行INDEX_op_st8_i32是st8_i32指令索引,后面的字符串数组限定t0、t1操作数可分配寄存器范围,用字符串表示,如图中的“q”,“r”,分别表示t0可分配的寄存器范围为EAX、EDX、ECX、EBX,t1可分配的寄存器范围为EAX、EDX、ECX、EBX、ESI、EDI、EBP、ESP.图5所示的INDEX_op_add_i32为加法add_i32指令的索引,其中第二字符串数组“0”表示指令add_i32的t0操作数和t1操作数之间可能存在依赖关系,即t0和t1为同一个临时变量,既作为输入也作为输出参数,“ri”表示操作数t2可分配4个通用寄存器一个或者是一个立即数.图5所示的INDEX_op_shl_i32为算术移位指令shl_i32的索引,第1个参数和第2个参数寄存器的分配范围与加法指令add_i32的相同,第3个参数只可为立即数或寄存器ECX.
基本块内临时变量寄存器分配采用线性扫描固定寄存器顺序(first-mean-busy,FMB)分配机制,即“最靠前意味着最忙碌”,通过线性扫描目标体系提供的寄存器数组索引进行本地寄存器的分配.分配机制的实现过程如下:当中间变量需要进行本地寄存器分配时, 依据中间指令操作码和中间变量位

图5中间操作码与寄存器之间的约束
Fig.5Constraintsbetweenoperationcodeandregister置,确定临时变量可分配寄存器范围;然后从数组的起点开始遍历,当遇到寄存器索引处于"空闲状态"时,即作为指定分配的寄存器.将该寄存器的状态置成"忙碌",中止遍历,等对应中间变量使用结束后,则释放该寄存器,恢复成”空闲”状态.若遍历完的寄存器数组索引都处于"忙碌"的状态,采用线性遍历寄存器数组从数组中强制“溢出”一个寄存器作为指定分配的寄存器.因溢出的寄存器保存着上一个临时变量的值,在释放寄存器的同时将“溢出”的寄存器保存的值回写入内存中,保证寄存器中的值不丢失.
2.2当前机制存在的缺陷
当前指令间的寄存器分配方法采取简单的线性扫描和溢出,指令内变量的寄存器分配采用优先级的方法.利用操作数可分配寄存器个数划分优先级,避免寄存器分配竞争时导致操作数分配不到寄存器资源,但指令间寄存器分配竞争没有相关的优化算法.若发生资源竞争,进行寄存器溢出的方法处理,显然存在不合理之处.以在x86宿主机翻译aplha可执行程序为例,如图6所示.

图6 中间表示与翻译后的本地指令Fig.6 Intermediate representation and local instruction after translation
图6中,左边为中间代码,右边为经翻译后生成x86本地指令.每条中间指令的序号与翻译生成本地指令序号是一一对应关系,其中④指令将ecx寄存器分配给了tmp0,⑨指令是一条算术移位指令,在2.1节中shl_i32指令第3个操作数只能为立即数或者分配为寄存器ECX,但因ECX寄存器已分配,只能采取寄存器溢出的方法.将寄存器值写回到内存,如图6右边⑨指令地址0xb7f9ff9b将寄存器ECX的值写回到虚拟寄存器.若后续引用该虚拟寄存器,则从虚拟寄存器中读回,如图中指令0xb7f9ffa3处从虚拟寄存器0x6b1c(%ebp)取值并赋值给寄存器ESI.若在处理④指令时将寄存器ESI分配给变量tmp0,显然生成⑨本地指令中虚拟寄存器的读写指令是冗余的.存在上述冗余访存虚拟寄存器指令的原因是因为指令④寄存器分配策略是简单的按照寄存器顺序线性扫描方法分配寄存器,未考虑指令间的寄存器分配竞争会造成冗余的指令产生.
针对上述由于寄存器溢出导致冗余访存的情况,提出基于优先级线性扫描寄存器分配算法(linearscanregisterallocationalgorithmbasedonpriorty,LSRAP),以指令内操作数可分配寄存器个数最少作为优先级的基础.首先在变量活性分析阶段分析基本块内指令,以指令内操作数寄存器分配个数,避免指令间寄存器分配不必要的寄存器溢出,减少生成本地代码指令数目,提高本地代码指令的执行效率.
3LSRAP算法
目前寄存器分配方法存在的问题是对所有的基本块指令间寄存器分配采用统一的固定顺序,但基本块与基本块之间是存在差异性的,基本块内的指令组成各不相同,对寄存器的需求也不一致,固定的寄存器分配顺序与单条指令的最优分配结合没有使整个基本块寄存器分配达到最优.本文提出基于优先级线性扫描寄存器分配算法,线性扫描基本块内有效的中间指令,统计并排序指令操作数预分配寄存器数目,依据寄存器预分配需求数量动态调整寄存器分配顺序.若可分配的寄存器的统计数目越大,则基本块内指令对该寄存器的需求越大,分配该寄存器的优先级越高,最先分配出去,剩余指令寄存器分配时压力越小,反之优先级越低,最慢分配出去,剩余指令分配该寄存器越困难,从而寄存器溢出的可能性变小,使基本块内每条指令寄存器分配达到最优.该算法的流程图如图7所示.

图7 LSRAP算法流程图Fig.7 LSRAP algorithm flowchart
首先,TCG上下文是动态二进制翻译系统前端二进制文件解析与后端代码生成的桥梁,记录了基本块的全局变量个数、tb块链地址及内存池等信息.该算法以该数据结构作为基础,在该结构体中定义一最大可分配寄存器数目大小的数组regAllocatedNum及寄存器分配顺序索引的数组regOrder,分别用于记录基本块内寄存器可被允许分配次数及基本块内寄存器分配时顺序,翻译基本块时初始化数组regOrder为默认的分配顺序,清空数组regAllocatedNum为0.
其次,在变量活性分析阶段线性扫描基本块内的中间指令获取该指令操作数预分配的寄存器,统计寄存器分配数目.对预分配寄存器计数时分成2种情况,因全局变量分配成一个固定的寄存器,翻译成本地指令时,其他变量均不能使用该寄存器,该固定寄存器的计数器采取直接置0的方法,其他寄存器只须将对应序号寄存器的分配计数器regAllocatedNum采取累加的方法,反复迭代完成寄存器分配计数器的统计,算法的伪代码如图8所示.

图8 寄存器分配次数统计伪代码Fig.8 Register allocation count pseudo-code
最后,依据寄存器分配计数器regAllocatedNum进行降序排序,数值越大说明基本块内支持分配该寄存器指令越多,优先级越高,越容易分配出去;反之,数值越小说明只允许基本块内部分指令能分配该寄存器,分配该寄存器越困难,若数值为0,则说明该寄存器只能分配成固定的全局变量,其他变量没权利分配该寄存器.
4实验与分析
该实验采用QEMU模拟器作为动态二进制翻译平台,它的寄存器分配采用默认固定顺序寄存器分配方法.为了验证固定顺序分配法存在的缺陷和该算法的跨平台实际优化效果,通过正确性测试、本地代码指令统计和整体性能测试对提出的算法进行评估,对比不同固定顺序的寄存器分配方法在不同平台上的运行效果.
为了对比说明实验的效果,除QEMU采用固定默认寄存器分配顺序外,手动修改源平台寄存器分配顺序,如表1的寄存器分配模式所示.其中,顺序0是QEMU采用的默认固定寄存器分配顺序.

表1 寄存器分配模式
4.1实验环境
在QEMU上运行nbench-2.2.3benchmarksuite(QEMU官方网站推荐用于评测性能的测试程序)作为实验的测试集.所有的执行速度是5次测试的算术平均值.
实验均是在宿主机Intel(R)Core(TM)2QuadCPUQ8200 @ 2.33GHz平台翻译mips交叉编译器、arm交叉编译器及i386的gcc编译器编译nbench测试集,各编译器的版本如表2所示.

表2 编译器版本
4.2正确性测试
开启nbench-2.2.3benchmarksuite的调试选项,在x86平台上使用arm、mips交叉编译器编译nbench测试集;启动源平台算法改进后的QEMU,传入编译好的测试案例可执行文件,从调试信息获取执行结果,如表3所示.
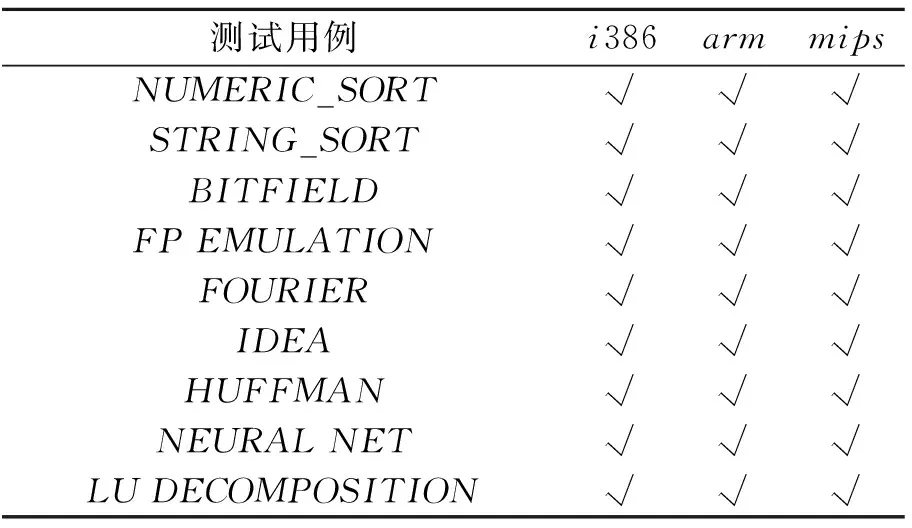
表3 nbench运行正确性测试
实验显示,该算法翻译执行不同目标平台的nbench,且执行的结果与改进前nbench执行的结果是一致的,表明该算法能够进行正确的翻译,具有很高的可信度.
4.3本地代码指令测试
为了对比不同平台nbench下测试案例在算法优化前、后对生成本地代码指令的影响,利用QEMU的日志输出功能,统计了不同平台下采取不同模式寄存器分配方法的本地代码指令数目,如表4所示.
本地代码指令数目反映了运行nbench运行的时间.生成的本地代码指令越少,间接执行本地代码时间越少.从表4的数据结果来看,不同的寄存器分配顺序生成的目标代码指令数目各不相同,表明寄存器分配顺序影响QEMU翻译系统生成本地代码指令;其次通过LSRAP算法改进生成本地代码指令数目比QEMU固定顺序寄存器分配都少,比寄存器默认分配方法少2.2%~3.4%.

表4 不同寄存器分配模式下本地指令数目统计
4.4整体性能评价
为了对比LSRAP算法对QEMU整体性能的影响,采用统计QEMU翻译执行测试程序每秒迭代次数.该测试集的执行结果直接反映该算法对翻译系统的性能影响效果,采取不同目标平台的nbench和不同寄存器分配模式进行实验.记QEMU默认寄存器分配方法每秒迭代次数为IQEMU,QEMU经LSRAP算法优化后每秒迭代次数为IAQEMU,加速比记作nsp=IAQEMU/IQEMU,如表5~7所示.

表5 i386体系nbench测试结果
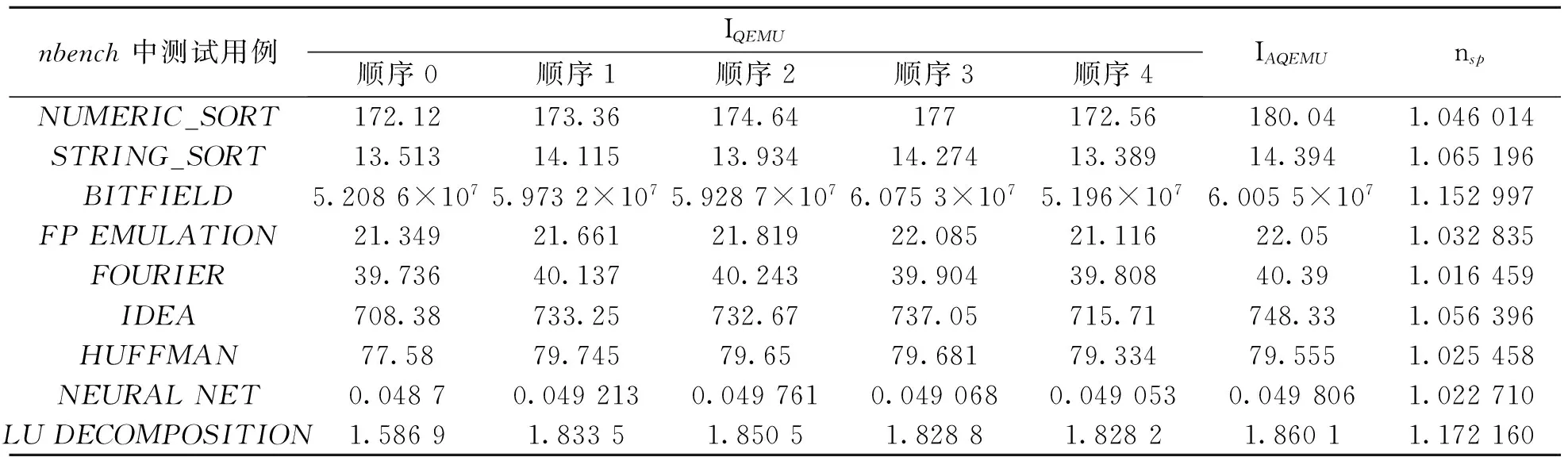
表6 mips体系nbench测试结果

表7 arm体系nbench测试结果
通过不同平台上nbench测试结果可以验证不同寄存器分配顺序程序执行效果表现各不相同,其中默认的寄存器分配顺序测试案例执行效果明显略差于手动修改寄存器分配顺序;其次动态调整寄存器分配顺序每秒迭代次数略大于固定寄存器分配顺序,经算法改进后nbench的测试案例每秒迭代次数arm、mpis、i386平台都有不错的提升效果,性能提升效果与具体测试用例相关,其中STRING_SORT和BITFIELD的测试案例优化提升性能最高.依据表5~7的测试数据可得,动态翻译i386平台下的nbench各个测试案例性能提升1.2%~16.4%,所有测试案例的平均性能提升约为6.7%;动态翻译mips平台下的nbench各个测试案例性能提升1.6%~17.2%,所有测试案例的平均性能提升约为6.8%;动态翻译arm平台下的nbench各个测试案例性能提升1.0%~14.1%,所有测试案例的平均性能提升约为4.7%,说明该算法具有良好的跨平台性.由此可以推断LSRAP算法虽然作为程序执行开销的一部分,但是相对于整体性能的提升而言影响很小.实验结果表明,本文的优化方法是行之有效的.
5结语
本文重点介绍了QEMU的运行原理,分析阐述QEMU的寄存器分配算法机制,举例说明该机制存在的缺点,并提出基于优先级的动态二进制翻译寄存器分配算法.该算法利用中间表示操作码和本地指令指令之间的映射关系统计基本块内预分配寄存器次数,确定寄存器使用分配的优先级顺序.该算法具有很好的跨平台特性,不同目标平台的可执行nbench测试案例执行效果都有一定的提升.实验结果表明,采用该算法可以有效地提高QEMU的执行效率.
参考文献(References):
[1]PENNEMANN,KUDINSKASD,RAWSTHORNEA,etal.EvaluationofdynamicbinarytranslationtechniquesforfullsystemvirtualisationonARMv7-A[J].JournalofSystemsArchitecture, 2016, 65: 30-45.
[2] 马湘宁. 二进制翻译关键技术研究[D]. 北京:中国科学院计算技术研究所, 2004.
MAXiang-ning.Researchonkeytechnologytobinarytranslation[D].Beijing:InstituteofComputingTechnologyChineseAcademyofSciences, 2004.
[3]HAWKINSB,DEMSKYB,BRUENINGD,etal.Optimizingbinarytranslationofdynamicallygeneratedcode[C]∥Proceedingsofthe13thAnnualIEEE/ACMInternationalSymposiumonCodeGenerationandOptimization.IEEE/ACMInternationalSymposiumonCodeGenerationandOptimization, 2015: 68-78.
[4]GSCHWINDM,ALLMANER,SATHAYES.etal.Dynamicandtransparentbinarytranslation[J].IEEEComputer, 2000, 33(3): 54-59.
[5]WEGMANMN,ZADECKFK.Constantpropagationwithconditionalbranches[J].ACMTransactionsonProgrammingLanguagesandSystems(TOPLAS), 1991, 13(2): 181-210.
[6]MUTHR.Registerlivenessanalysisofexecutablecode[EB/OL].[2015-07-07].www.cs.arizona.edu/alto/papers/liveness.ps.
[7] 马湘宁, 武成岗, 唐锋, 等. 二进制翻译中的标志位优化技术 [J]. 计算机研究与发展, 2005, 42(2): 329-337.
MAXiang-ning,WUCheng-gang,TANGFeng,etal.Twoconditioncodeoptimizationapproachesinbinarytranslation[J].JournalofComputerResearchandDevelopment,2005, 42(2): 329-337.
[8]EBCIOGLUK,ALTMANE,GSCHWINDM,etal.Dynamicbinarytranslationandoptimization[J].IEEETransactionsonComputers, 2001, 50(6): 529-548.
[9]CHAITINGJ,AUSLANDERMA,CHANDRAAK,etal.Registerallocationviacoloring[J].ComputerLanguages, 1981, 6(1): 47-57.
[10]CHAITINGJ.Registerallocationandspillingviagraphcoloring[J].ACMSigplanNotices, 1982, 17(6): 98-101.
[11]TRAUBO,HOLLOWAYG,SMITHMD.Qualityandspeedinlinear-scanregisterallocation[J].AcmSigplanNotices, 2010, 33(5):142-151.
[12]POLETTOM,SARKARV.Linearscanregisterallocation[J].ACMTransactionsonProgrammingLanguagesandSystems(TOPLAS), 1999, 21(5): 895-913.
[13]ALEILiang,GUANHai-bing,LIZeng-xing.AresearchonregistermappingstrategiesofQEMU[C]∥Proceedingsofthe2ndInternationalSymposiumonIntelligenceComputationandApplications(ISICA'2007).Wuhan: [s.n.], 2007: 168-172.
[14] 吴浩. 二进制翻译系统QEMU中的优化技术[D]. 上海:上海交通大学, 2007.
WUHao.OptimizationtechnologyofQEMU[D].Shanghai:ShanghaiJiaoTongUniversity, 2007.
[15] 文延华, 唐大国, 漆锋滨. 二进制翻译中的寄存器映射与剪裁的实现 [J]. 软件学报, 2009, 20(2): 1-7.
WENYan-hua,TANGDa-guo,QIFeng-bin.Registermappingandregisterfunctioncuttingoutimplementationinbinarytranslation[J].JournalofSoftware, 2009, 20(2): 1-7.
[16] 廖银, 孙广中, 姜海涛, 等. 动态二进制翻译中全寄存器直接映射方法 [J]. 计算机应用与软件, 2011, 28(11): 21-24.
LIAOYin,SUNGuang-zhong,JIANGHai-tao,etal.Allregistersdirectmappingmethodindynamicbinarytranslation[J].ComputerApplicationsandSoftware, 2011, 28(11): 21-24.
[17]CAIZ,LIANGA,QIZ,etal.Performancecomparisonofregisterallocationalgorithmsindynamicbinarytranslation[C]∥InternationalConferenceonKnowledgeandSystemsEngineering.Hanoi:IEEE, 2009: 113-119.
[18]LIANGY,SHAOY,YANGG,etal.RegisterallocationforQEMUdynamicbinarytranslationsystems[J].InternationalJournalofHybridInformationTechnology, 2015, 8(2): 199-210.
[19]FABRICEB.QEMU,afastandportabledynamictranslator[C]∥Atec05:ConferenceonUsenixTechnicalConference.[S.l.]:Usenix,2005.
[20] 张西超,郭向英,赵雷,等.TCG动态二进制翻译技术研究 [J]. 计算机应用与研究,2013,30(11):34-37.
ZHANGXi-chao,GUOXiang-ying,ZHAOLei,etal.StudyonTCGdynamicbinarytranslationtechnique[J].ComputerApplicationandSoftware, 2013, 30(11): 34-37.
收稿日期:2015-07-07.浙江大学学报(工学版)网址: www.journals.zju.edu.cn/eng
基金项目:国家自然科学基金资助项目(61472447).
作者简介:戴涛(1990-),男,硕士生,从事二进制翻译及软件逆向研究.ORCID:0000-0001-7009-9227.E-mail: daitworld@126.com 通信联系人:单征,男,副教授.ORCID:0000-0001-9618-8551.E-mail: zzzhengming@163.com
DOI:10.3785/j.issn.1008-973X.2016.07.016
中图分类号:TP 314; TN 332
文献标志码:A
文章编号:1008-973X(2016)07-1338-09
Registerallocationalgorithmofdynamicbinarytranslationbasedonpriority
DAITao,SHANZheng,LUShuai-bing,SHIQiang,TANJie
(State Key Laboratory of Mathematical Engineering and Advanced Computing,PLA Information Engineering University, Zhengzhou 450002, China)
Abstract:QEMU uses a simple sequential allocation algorithm to deal with all the basic blocks without considering the difference between the basic block, which causes a lot of register overflow. A more efficient priority-based linear scan register allocation algorithm was presented based on the mapping between intermediate representation and the source platform register, dynamically adjusting register allocation sequence to reduce register spilling times and the number of generated native code instructions by counting and ordering the pre-allocated registers of a basic block. The improved algorithm has a good cross-platform based on intermediate code, effectively reducing the generation of local code instructions. Experimental results show that the algorithm is better than the performance of QEMU before optimization, which respectively upgrades about 6.7%, 6.8%, 4.7% in x86 platform, mips platform and arm platform.
Key words:dynamic binary translation; register allocation; QEMU; intermediate code
