
见物见人
——时空大数据支持下的存量规划方法论
2016-07-22 02:22段冰若郝新华蔡玉蘅
上海城市规划 2016年3期
段冰若 王 鹏 郝新华 蔡玉蘅 石 淼
见物见人
——时空大数据支持下的存量规划方法论
段冰若 王 鹏 郝新华 蔡玉蘅 石 淼
相比于传统的增量规划,存量规划中主要在产权本质、时间逻辑和空间处理尺度上有着本质的不同。因此,存量规划对现有用地现状和性质的精准刻画提出了更高的要求。作为当前传统的用地现状分析图在存量规划中存在着地块特征刻画精度有限与用地分类维度过低等不足。对用地类型的混合、同种用地类型的规模、同一地块的时间属性等用地特征,传统的现状分析图也难以进行描述。随着互联网LBS(Location-Based Service)服务的发展,越来越多LBS时空数据因其巨大的用户基数和完善的时空地理信息,受到规划师的关注。这些新的时空地理数据使得对用地功能和人口活动特征的详细刻画成为可能。使用互联网某LBS平台人口分时活动密度数据,叠加百度POI(Place of Interest),通过非监督分类和非负矩阵分解的方法,分别对北京市六环内的地块尺度、500 m网格尺度和25 m点阵尺度进行用地功能的识别与分类。通过多维度分类结果的叠加,对研究区域的用地功能、人口时空活动特征进行深入刻画,探讨通过大数据进一步辅助存量规划的用地功能研究方法。
AbstractCompared to the traditional incremental planning in China, inventory planning is different in the perspective of property, time and space. Thus, a higher demand for the depiction of existing space is needed in the inventory planning process. However, the depiction method used in incremental planning such as land use analysis map cannot fulfill this demand. With the prevalence of internet LBS (Location-Based Service) data, planners see a new opportunity to make a more detailed depiction of the existing space. This paper intends to use an LBS data of population density by hour, together with POI (Place of Interest) from Baidu. With the help of unsupervised learning algorithm, a detailed depiction of land use and population activity pattern will be presented, showing more opportunities for big data analysis in the current urban planning research.
存量规划 | 机器学习 | 用地分类 | LBS数据
KeywordsInventory planning | Machine learning | Land use clustering | LBS data
0 引言
(1)存量规划转型与挑战
随着城市的不断扩张与发展,城市中,尤其是城市中心区的用地功能混合度随之增高。在传统的用地分类中,城市的用地功能依照居住、商业、公共服务设施等,共分为2大类、9中类、14小类。然而传统的用地分类方式已经难以描述功能日益复杂的城市用地。旧城区自下而上在地块功能上的自然生长,通勤交通方式的变化等,向传统的用地分类提出了诸多挑战。在这一过程中,传统用地难以实现对混合类用地功能的描述、同种用地类型规模的描述,以及对同一地块时间属性的描述。
另一方面,随着越来越多的国内一线城市,由于其自身人口、交通、环境和资源的压力,纷纷开始在其下一阶段的城市规划工作中融入了控制城市规模和外向扩张的内容,存量规划和规划转型逐渐成为了国内城市发展所关注的焦点。2007年深圳市提出将城市总体规划的战略由增量规划转变为存量规划,成为第一个将存量规划作为其规划思想的城市。最新一轮的上海市城市总体规划中,也提出了“严守用地底线,实现建设用地零增长甚至负增长”的目标。类似的,北京市也在新一轮总规中提出“简单规划、瘦身健体”的规划指导思想。相比于传统的增量规划,存量规划对用地现状和性质的精准刻画提出了更高的要求和挑战。存量规划主要有以下3个不同点。第一,产权本质不同:在存量规划中,涉及的权利关系更加复杂。这对现场及周边环境的深入解读提出了更高的要求。第二,时间逻辑不同:增量规划是预期性的,着眼的是未来的利益分配,可以花费数月时间调研,并可伴随规划实施的过程逐步调整。而存量规划的频次将会显著高于增量规划,需要实时精确地了解现实矛盾,以及对受损方的影响。因此一旦对用地现状理解出现偏差,就可能出现较大的负面影响。第三,空间处理尺度不同:存量规划代表着由大规划到小微规划的转变。由长远的空间构想转变为微处理、微设计、微更新。结构调整更加趋向精细化,在空间结构格局变化不大的情况下,通过用地结构的调整来改善城市的功能结构,为城市提供更好的发展环境[1]。由以上3点不同可以得出,当前存量规划的主要任务之一即对用地现状进行快速精准的描述与深入的刻画。
由于传统用地分类描述方法的局限性,互联网大数据成为了另一种解决问题的途径。随着智能终端的大范围普及和互联网LBS (Location-Based Service)服务的日益完善,越来越多的LBS时空数据因其覆盖用户广、时空信息完善,走进了城市研究者的视野。其分布颗粒度细、覆盖时间广、可按需抓取的特点,使得使用该类分时人口时空地理数据刻画用地功能、反映人口活动特征成为可能。
本文拟使用互联网某LBS平台人口分时活动密度数据,叠加百度POI(Place of Interest)数据,通过非监督分类和非负矩阵分解的方法,分别对北京市六环内的地块尺度、500 m网格尺度和25 m点阵尺度进行用地功能识别与分类。通过多维度的分类结果叠加,对研究区域的用地功能、人口时空活动特征进行深入刻画,探讨可以进一步辅助存量规划的用地功能研究方法。本章第二部分将对使用分时人口数据进行的研究进行总结回顾。第一章将对研究方法进行具体介绍,包括对数据、方法论和研究尺度进行详细解释。第二章将对研究结果进行分层分析。第三章将对全文进行总结,并对下一步研究做出展望。
(2)研究现状
目前应用较多的用地识别方式是从地理学角度通过卫星遥感测定判定用地性质。Halder等人就通过蚁群算法对卫星照片中的建设用地与非建设用地进行了识别[2]。随着识别方法的改进,通过卫星照片也能对生态用地以及工业用地进行较为精准的识别[3]。近年来基于地图服务产生的大数据POI(Point of Interests)也逐渐被应用于用地的识别。王芳等人就通过POI数据对由城市路网划分的功能单位进行识别,通过聚类分析将传统意义上的商业区细化为饮食文化型商业区、专营型商业区等5个功能类型[4]。该类数据本身自带的地点用途分类能够辅助分析人员对用地本身功能的多样性及复合性进行精细化的描述。然而不论是卫星遥感还是POI识别都只能测定出城市的物理空间属性,而随着存量规划的兴起,规划师正逐渐关注用地的复合属性。实体尺度的建筑空间的规模、用途、性质以及社会活动尺度上的就业、住房、通勤等都是在进行用地描述时需要关注的重点。在深圳存量规划的城市发展评估指标体系中既加入了传统规划中土地利用、市政、交通、公服设施等指标,又引入了用于描述社会属性的人口、就业、住房等指标。从存量规划的角度来看,用地本身的属性其实是实体物理空间与社会活动空间相互作用的产物。
分时人口数据,一般指带有时间信息的人口统计数据,在与地理坐标结合时能够用于描述用地的社会空间活动。常用的分时人口数据来源有手机信令数据[5],出租车OD数据[6],公交刷卡数据[7],社交媒体签到数据等。相比于规划常用的统计公报、普查或年鉴数据,分时数据的统计口径能够通过数据处理细化到城市地块的规模或者汇总为一个单一的城市指标。由于分时数据多为实时采集的数据,所以也具备了实时进行地块属性评判的潜在能力。裘炜毅等人就利用手机信令数据对上海市张江高科技园区及莘庄工业区的职住分布进行了研究[8]。虽然两用地周边都有居住用地的布局配置,但是通过手机信令数据生成出行链并对用户OD点的识别能够判断出张江高科技园区的职住比略低于莘庄工业区的职住比,显示高科技园区周边的居住用地从社会属性上并未较好地为园区职工提供住房。
本研究中采用的分时人口数据相较于目前使用的手机信令、社交媒体数据、出租车、公交刷卡数据而言的优势在于直接同需要分析的地块人口密度变化挂钩。不需要通过繁琐的处理,通过生成轨迹链等方式进行二次统计。这保证了数据在未来用于实时评估用地状况的运算中能够大幅缩减运算时间。在数据精度方面,手机信令对基站的依赖程度巨大,平均精度在500 m×500 m左右。出租车、公交刷卡等数据更是受到了道路尺度的大幅限制。而主要依靠GPS提供定位的分时人口密度数据能够提供精度达到25 m×25 m网格的细度数据,基本达到了建筑的分析尺度。此外该数据本身的获取门槛较低,通过互联网抓取技术就能持续获取数据。综上可知,新的数据环境和分析方法降低了数据获取的难度和数据分析的技术门槛,因此,如何对当前环境下的数据加以运用,使规划制订与实施更能满足城市运行的需要及市民生活的需求,则需要规划师在提高自身数据研究技术的同时,对当前的数据环境进行进一步的思考。当前研究中,龙瀛等已对数据在规划应用中的角色进行了系统的思考与梳理,提出了数据增强设计的概念。本文将从数据增强设计的概念出发,对人口密度数据进行深入挖掘,辅助存量规划的进行[9]。
1 研究方法
1.1研究对象及研究数据
本次研究范围为北京六环内区域。所采用的主数据源为互联网某LBS产品的分时人口活动热度数据。该数据的主要来源是该互联网产品的桌面端和移动端APP的用户使用过程中产生的过程数据。该服务通过采集桌面端的IP地址和移动端用户主动产生的定位信息,计算每一位置每个时刻的人口统计。原始的数据包含3个字段,分别为数据采集点的坐标、日期和该小时的人口密度。其中,人口密度值已经过服务后台预处理,与实际人口数量存在正相关的转换关系。数据采集点的网格密度为25 m,点呈均匀点阵分布。目前笔者通过网络爬虫,采集了2015年7月30日至8月2日北京六环以内的数据,数据量在每小时230万个点左右(图1)。因抓取频次的限制,个别郊区区块存在数据缺失,但是并不影响对功能复杂的城市中心城区的分析。
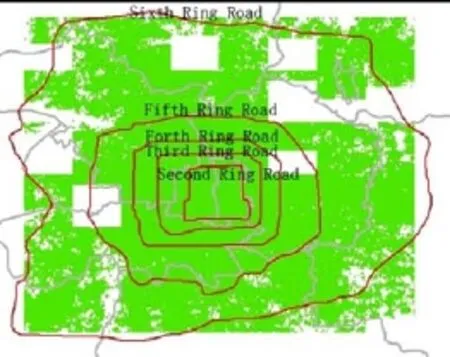
图1 原始数据点范围
为保证该分时人口数据能够较好地对不同类型的城市功能,尤其是混合功能进行深入解读,在正式研究前,笔者对几处熟知的特征地块进行了预试研究。首先,笔者对同一主导功能的不同地块的人口活动进行了横向对比。笔者分别选择了3种用地功能与人口活动特征截然不同的地块,通过将地块内的点数据匹配到地块中,计算出每个地块的分时人口热度曲线。其中S代表周末,W代表工作日,后面的数字代表整点时间。
这3个地块分别为市级活动中心西单大悦城、市级商业办公中心金融街和市级绿地奥林匹克森林公园(图2)。其中,西单大悦城的人口活动热度在工作日和周末都较高,且一般于下午14至16点左右达到高峰。金融街则呈现出明显的办公特征,即工作日的人口活动热度显著高于休息日。而奥林匹克森林公园则相反,在周末吸引着更多的人前来活动。
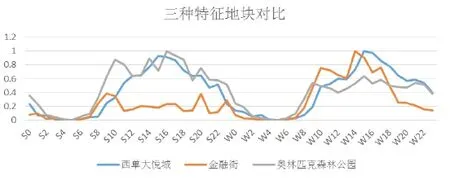
图2 3种特征地块对比
通过观察尺度较大、地块特征较为明显的若干地块后可以看出该分时人口密度在地块上所表达的特征与趋势已经能够满足用于机器学习的识别需求。为了进一步对数据质量与其所能反映的特征进行评估,笔者选取了一栋建筑中点层面的数据进行对比(图3)。所选择的是办公建筑“百度大厦”。在研究中对大厦中不同区域的分时人口活动变化规律进行对比。从图3可以看出,在百度大厦中,除1号点外,其余3点有着相似的曲线特征,即典型的办公活动特征。由此可知,在同一建筑中的不同区域,因其空间使用功能的不同,所反映出的人口活动变化规律也大相径庭。因此这些数据所反映的用地功能特征及精细程度,是传统用地分析方法无法比拟的。
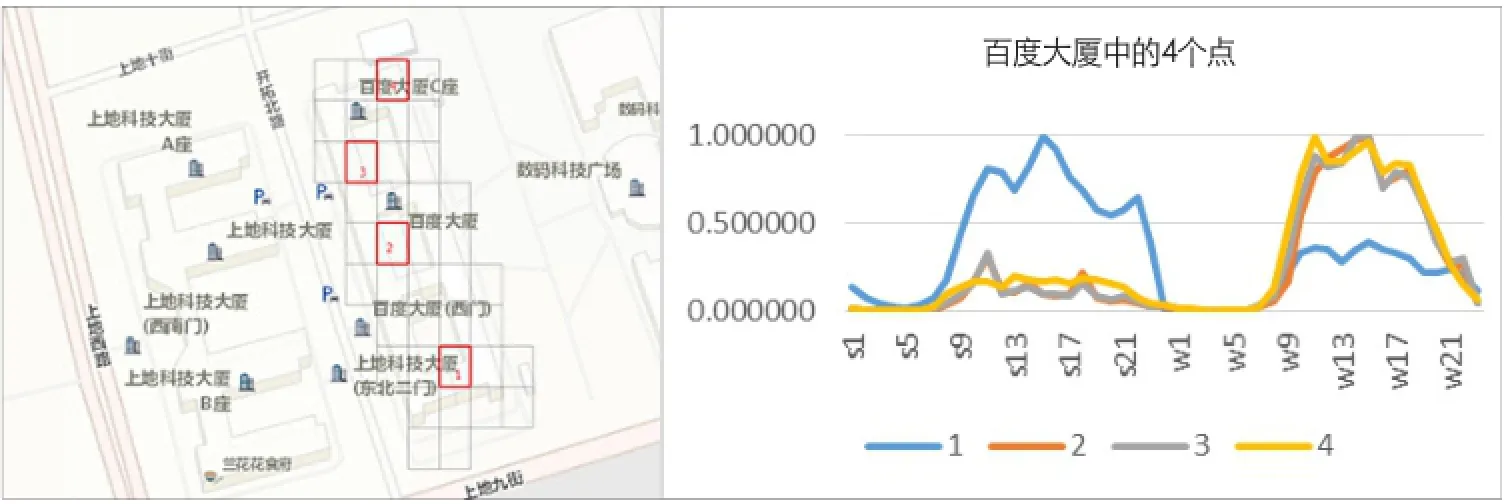
图3 建筑内数据点对比
另外,为了更好地配合分时人口数据,对用地功能进行深入解读,笔者使用了百度POI作为辅助数据源。通过百度地图提供的API (Application Programming Interface,应用程序编程接口),笔者采集了2015年初北京市域范围内的5大类、20小类约20万个POI,涵盖居住、商业、娱乐、公共服务设施、交通、绿地等内容。每个POI点包括唯一编号、POI名称、坐标、一级分类、二级分类、用户评价等字段(图4)。
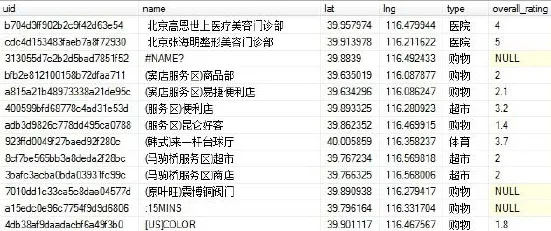
图4 POI数据样例
1.23层研究空间尺度匹配体系
观察数据特征可知,在不同空间尺度中,分时人口数据所反映出的用地特征也有不同的侧重。在传统的地块尺度中,数据能够较好地体现出该地的人口活动规律,但是面对地块内部的大型建筑,尤其是重要建筑节点时,地块尺度则显示了其自身分析尺度过大的缺陷。这时,更为精细的点阵尺度数据则可以对地块内部的混合功能进行全方位的立体描述。与此同时,在郊区存在许多自身面积较大的地块,此时再使用地块尺度进行分析,则会因其包含太多数据而使分析结果过于笼统,难以满足精细刻画的需求。因此,将较大的地块划分为若干空间尺度较小的研究单元,可以对这些大尺度的地块进行进一步的精细刻画。
结合以上空间研究单元需求,笔者将整个研究单元分为3层空间尺度,分别进行数据匹配。3层空间尺度体系分别为原始地块尺度(由路网分割)、500×500 m网格尺度,及25×25 m原始数据点阵尺度(图5)。其中,原始地块尺度对于多数空间单元能够做到较好的描述,但是对于极大的郊区地块和极小的内城地块,其描述结果并不能很好地体现该空间所在的本身特征。因此,我们使用均分额500 m网格,对地块尺度的描述进行补充说明。在点阵尺度,研究结果则会更多地倾向于对建筑尺度的对比,包括建筑内部的时空特征,以及建筑与地块的时空关联等。通过3层空间尺度体系的分门别类与描述,笔者对同一研究对象进行基于地块、网格和内部点的多维立体描述,为存量规划所需的深度精细刻画提供理论支持。
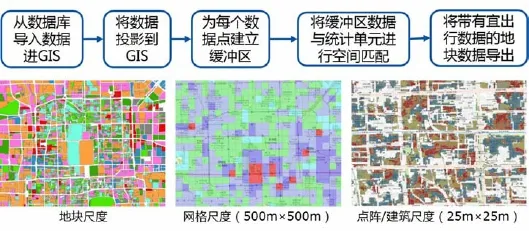
图5 空间匹配流程与结果
1.3非监督分类与矩阵分解在研究中的使用
由观察数据可知,分时人口密度数据作为曲线类数据,其自身特点非常适合使用机器学习的方法进行非监督分类。笔者将数据整理为休息日的24小时分时人口数据与工作日的24小时分时人口数据,共48个时刻,结合20种不同类型POI的数量,对3层空间尺度的研究单元进行k-means聚类分析(图6)。
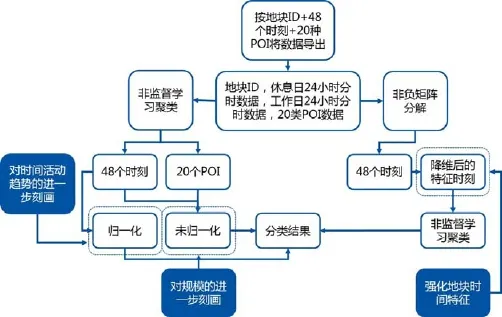
图6 机器学习流程
为了能够确定k-means中k的取值,笔者在每组数据进行k-means分类之前均进行了silhouette检验,寻找每组合适的k值,保证在分类过程中,既不会出现因为k值过小而忽略某些特征,也不会出现因为k值过大使得多组分类结果高度重合的情况。
在使用k-means进行聚类时,为了分别对时间活动的趋势规律和地块人口活动规模进行进一步区分,笔者分别使用了归一化的48个时刻数据和未归一化的数据进行非监督学习,使分类结果更加详细。在进行48个时刻的非监督分类同时,笔者也尝试了使用非负矩阵分解(NMF)的方法,将每个研究单元48个时刻中的特征提取出来,在放大特征的基础上进行非监督分类。
2 研究结果
2.1地块尺度研究结果
考虑到48个变量仍是一个很高的维度,而k-means聚类对高维度的聚类仍力度不足,为进一步降低数据的维度,本部分采用了非负矩阵分解(NMF)的方法,以归一化之后的48个变量作为输入,最终将变量降为4维,然后以降维之后的5个变量作为k-means聚类的输入,经过实验证明,降维之后再聚类的方法比直接聚类的方法所得精度更好。因此,地块尺度的分类方法是,采用非负矩阵分解(NMF)的方法先对归一化后的48个变量进行降维(降成5维),然后采用k-means聚类的方法对降维之后的5个变量进行聚类。多次试验,进行silhouette检验,发现当分类类别数为9时,silhouette检验的得分最高,意味着k=9时,分类精度最高,因此,选择k=9类作为最终的分类结果。
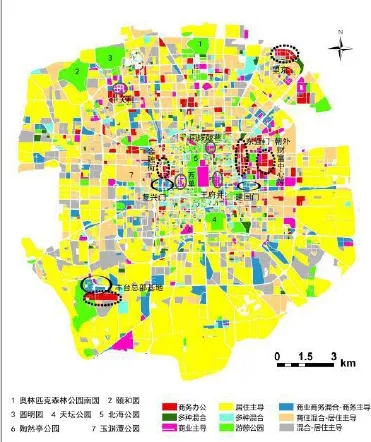
图7 地块尺度分类结果
图7展示了地块尺度分类的结果,地块的类别根据各类别的曲线特征确定,同时抽样选取已知功能的典型地块。从地块尺度分类结果图可以看出,该方法对商务办公、商业商务混合、商业识别度最高。能够很好地识别出这3类对应的典型区域,如东二环的东直门—朝外一带,财富中心,望京的商务楼集中区,丰台总部基地,金融街及中关村办公楼集中区等商务办公区;南锣鼓巷,王府井,西单,中关村购物中心等典型商业主导区域;复兴门、建国门等商业商务混合区。此外,对游憩—公园、居住主导、商住混合—居住为主等功能的地块也有较好的识别度。例如,奥林匹克森林公园、颐和园、圆明园、天坛公园、北海公园等公园均能分到一类(公园游憩类),但同时陶然亭公园、玉渊潭公园等则没有能够正确识别。居住主导类和商住混合—居住为主类别在空间分布上的明显区别是居住主导类更具外围性,且分布更多在南边,而商住混合—居住为主类则更多分布在北边,这与北京北部较南部发达的特征一致。而混合—居住主导,及其他两类混合类则无法准确判断类别,而实际上,这3类在五环内的地块中所占比例非常小,可以说,总体上,本部分基于地块尺度的地块分类方法具有较高的精度。
除对典型的功能区能有较高的识别度之外,该分类对非典型功能区中精细地块也能有较好的识别。以奥林匹克森林公园所在区域为例(图8),这块区域包括了居住、商业、办公、游憩公园等多种类型,随机抽取几个地块,观察所识别的精度,结果如图8所示。图中,地块1经过机器学习识别出来的结果是游憩公园类型,其所表现的曲线特征为周末人多、平时人少、高峰在下午14—17点的特征,与人们游憩娱乐的行为习惯一致,进一步对比百度地图的结果,发现该地块为奥林匹克森林公园南园所在地,为绿地类型用地;地块2经过机器学习识别出来的结果是商务主导的用地,曲线特征为明显的周末几乎无人、平时人多、10—18点长高峰的特征,与人们工作的行为习惯一致,而在百度地图中显示该地块为京东总部未搬迁之前的办公所在地,为商务办公用地类型;地块3识别的结果是商业主导的用地类型,曲线表现为周末、平时略突出的双高峰的特征,由于该购物中心为片区级购物中心,主要服务周边居住、办公的人群,因此商业特征相较商业中心不太明显,但仍表现为商业主导的特征,而百度地图上显示该地块为漂亮阳光广场,为商业服务业用地类型,曲线、以及地图上的实景展示均验证了本部分所用分类方法在精细地块尺度上具有较高的识别度。
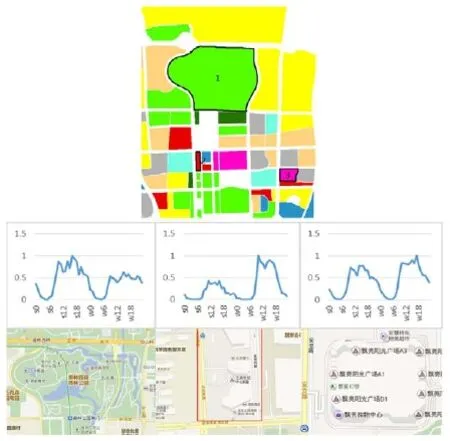
图8 奥林匹克森林公园区域地块识别功能、对应曲线、实际功能
虽然在典型功能及精细地块尺度上都能有较好的分类结果,但仍存在部分识别效果的比例,如前文所述陶然亭公园、玉渊潭公园等无法与其他公园分为一类,故宫、景山公园等被分成了商业主导类型等,这些均属于不恰当的类别划分。说明单一从人类活动的特征推测用地功能在功能更加混合的用地上区分度不够,且小地块的人类活动数量会对异常事件有敏感的反应,导致分类结果的误差,后续还得结合POI数据和人类活动的数据,共同判断地块的用地功能。值得一提的是,本部分所谈商业主导、居住主导、商务主导等各用地功能,均是指承载更多人类活动的功能,而不单纯是从地块中的占地面积来判断。要掌握用地的运行状况,人的活动实际是一个更合理的角度。此外,地块的数据去除了道路、广场,而这两者本身也承载人类重要活动,是一类重要的用地类型,而基于地块的用地功能无法进行识别,也是遗憾之一。
2.2网格尺度研究结果
为了更好地体现500 m网格的特点,弥补郊区大地块中分类精度的不足,网格尺度分别对POI数据、归一化后的48个小时的分时人口曲线数据和原始曲线数据进行了空间匹配。通过POI的分类结果辅助判断用地的主导功能。归一化曲线的分类结果对时间活动特征进行强化描述。原始曲线分类结果则侧重描述各网格内的人口活动规模。通过3类数据分类结果的叠加,可以对单一网格进行更为立体的解读。
在使用k-means进行分类前,通过Silhouette检验,得知3组数据潜在的理想k值,即分组组数均为5组。在非监督分类后,通过观察每组数据的不同分组的统计学特征,研究可以结合网格对应的实际地块对分组结果进行合理解释。
在POI分组中(图9),分组依据主要为不同种类POI的比重。5类分组结果分别为商业商务综合地块、交通服务富集地块、商业混合地块、市级活动中心,及居住企业学校地块。从分组结果可以得知,POI的分组结果更偏重对商业的描述,而对居住及公共服务功能的描述则略有不足。而这也是由POI自身为商业导航的性质所决定的。因此,使用分时人口数据分类结果进行叠加在这里显得更有必要。
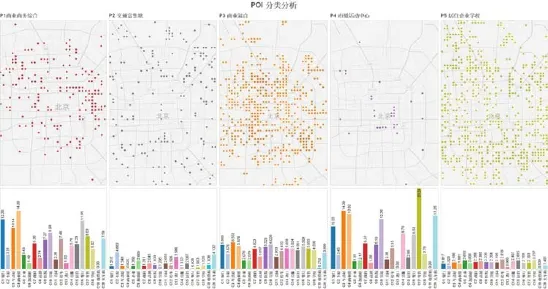
图9 POI分类内结果分析
在未归一化的原始曲线的分类结果中,分类依据主要是人口活动规模。人口活动规模由低到高共分为5类。对于归一化的曲线,其分类结果主要体现了地块的职住特性与工作日和休息日的特征差异。分类结果的职住性质分别从纯工作场所类到职住平衡类再到居住娱乐类共分5类。而在此分类方法中无法完好区分的居住和娱乐则可由POI的分类结果进行很好的弥补(图10)。
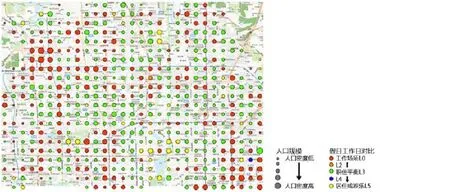
图10 分时人口密度分类结果
通过将3种分类方法的分类结果进行叠加,排除不存在及特征重复的组合,共得到11类用地功能分类。通过与已知特征的地块进行比对,可以发现该用地功能分类的结果能够较好地对研究范围内的500 m网格进行功能区分,并且区分结果可以进行较好的解释。以笔者较为熟悉的五道口地区为例(图11),在该区域内,用地功能混合度较高、类型较为多样化。既有以商业办公为主的华联,以教学为主的各大高校,也有类似华清嘉园这类混合度较高、功能较为多样化的住宅区。从分类结果上,笔者发现该尺度分类方法对学校的识别效果较好,区域内的北大、清华、北语等学校均可以被较好地识别。华清嘉园等小区则被识别为商务中心类型,与其小区内数量众多的小公司及周边繁华的餐饮零售业的现状相契合。各研究院所及清华科技园所在地块在该分类方法中也可以被较好地识别出来,呈现出与学校和零售商业截然不同的分类结果。
2.3点阵尺度研究结果
点阵尺度的研究目的是为了通过将原始点阵数据的48小时分时曲线数据进行聚类分析,对地块内部的人口活动热点及特征进行精细区分与刻画,对地块内部的地块性质主导因素进行识别,发现地块热点。
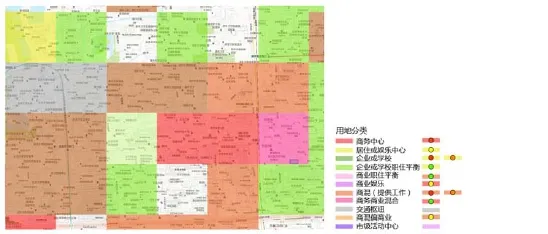
图11 叠加结果分析
在Silhouette检验后,k-means分类中的k取值确定为15。不同于地块尺度与网格尺度,点阵尺度的分类结果所主要表达的是根据曲线的特征及规模反映出地块中建筑的外轮廓和建筑中的不同功能。以西二旗为例(图12),点阵尺度的分类结果很好地体现了西二旗地铁站及百度大厦区域的高人口活动热度。高人口活动热度的点均落入建筑内部,25 m的点阵精度也保证了其可以对建筑外轮廓进行较好的勾勒与反映。与此同时,也可以通过对比分类结果的方法,对不同建筑的人口规模及活动特征进行区分。
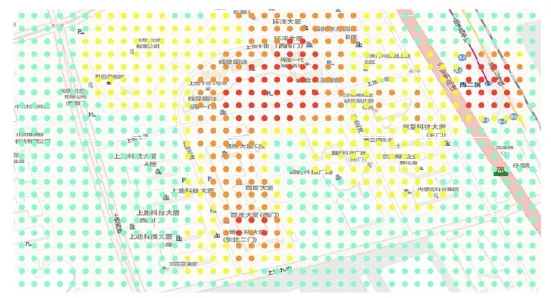
图12 点阵分类结果局部
另一方面,通过对分时人口数进行叠加,可以在点阵尺度对以人口密度为基础的三维空间进行进一步刻画与可视化表达(图13)。由此图可以判断,百度大厦是该地区人口活动的绝对热点,其规模甚至远大于西二旗地铁站。同时,百度大厦北侧的联想研究院则是该地块另一人口活动热度较高的区域。
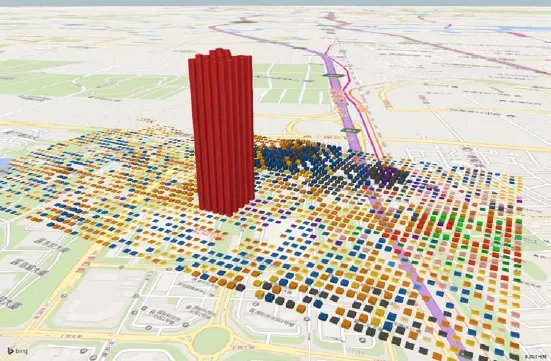
图13 点阵分类三维刻画
3 总结
分时人口密度数据为城市定量研究数据源选择提供了全新的视角。其自身特征决定了在刻画城市用地功能上,有着其他数据无法取代的优势。同时,在结合POI等其他辅助数据源配合时,分时人口密度数据可以对城市中的混合功能进行较好的辨认与区分,帮助研究者与规划人员发现传统研究方法所无法发现的城市特征。在3层空间尺度下,该数据也能够对不同尺度的城市功能特征进行诠释,对同一研究对象进行多维立体描述,保证分类结果的精准和有效性。
总体而言,分时人口密度数据解决了在规模、规律和功能3个方面的认知过程中产生的问题。首先,在规模识别上,该数据可以对分时人口规模进行深度刻画,达到对同种功能不同级别的识别,解决传统分析方法中对不同规模的居住区、商业区分类过程中遇到的困难。第二,在活动规律识别上,分时人口密度打破了传统分析方法中单一结果、缺乏时间维度的构造,对同一地块不同时间段的特征进行了有效的反映,对地块人口活动规律的单日内变化、工作日与周末的差异进行了突出表达。第三,在城市功能认知上,结合POI的约束,分时人口数据可以发现传统用地分类中无法刻画的隐藏属性,如小区里的公司。
但是在城市定量研究中,分时人口密度也有着其自身的不足与局限性。该数据最大的局限性在于,由于数据是经过点阵进行采集的,点阵的数据中并不包括单一用户的行为信息。这也意味着,对于用户的时空轨迹,使用此种数据无法进行分析。在大规模迁徙和行为路线选择研究方面,该数据无法提供有效支持与帮助。
本研究通过使用非监督分类的方法对城市用地进行人口活动特征与功能上的重新划分,其主要贡献包括3点。第一,为建成环境使用后评价提供了新的途径与思路,超越传统评估方法中访谈、问卷的小样本与局限性,为调研提供更为多元化的视角。第二,为研究城市功能历史转变提供了可能。传统调研方法对于历史数据的获取和反馈能力相对有限。而本方法可以通过个性化抓取,选择需要的时间与地理范围,对研究对象进行分类描述与刻画。第三,研究尺度更为精细,在小微尺度上的数据分析为更多的小尺度空间研究提供了可能,也满足了存量规划的自身需求。在人流拥堵点识别、建筑与地块的微观联系上,都有着可供挖掘的潜力。
通过此次研究,笔者了解到该数据与方法在存量规划中的应用潜力。在下一研究阶段中,通过完善该方法,可以对更为宏观和热点的规划问题进行挖掘与分析。例如研发可供非首都核心功能疏解评估的人口规模监测模式、京津冀协同发展中重点对接单位和区块的用地人口特征变化分析等。课题组也将对分析方法进行进一步完善,通过该方法对城市的运行状况进行常态化监测,在发现规划问题的同时,对规划进行精确辅助。
References
[1]邹兵. 增量规划,存量规划与政策规划[J]. 城市规[9]划,2013(2):35-37. ZOU Bing. Increment planning, inventory planning and policy planning[J]. Urban Planning, 2013(2): 35-37.
[2]Halder A, Ghosh A, Ghosh S. Supervised and unsupervised land-use map generation from remotely sensed images using ant based systems[J]. Applied Soft Computing Journal, 2011, 11(8): 5770-5781.
[3]梁松. 城市规划动态监管卫星遥感关键技术研究[D]. 北京:中国矿业大学博士学位论文,2010. LIANG Song. Study on the key technology of satellite remote sensing for urban planning dynamic supervising[D]. Beijing: The Dessertation for Doctoral Degree of China University of Mining and Technology, 2010.
[4]王芳,高晓路,许泽宁. 基于街区尺度的城市商业区识别与分类及其空间分布格局——以北京为例[J]. 地理研究,2015,34(6):1125-1134. WANG Fang, GAO Xiaolu, XU Zening. Identification and classification of urban commercial districts at Block Scale[J]. Geographical Research, 2015,34(6): 1125-1134.
[5]王德,王灿,谢栋灿,等. 基于手机信令数据的上海市不同等级商业中心商圈的比较——以南京东路、五角场、鞍山路为例[J]. 城市规划学刊,2015(3):50-60. WANG De, WANG Can, XIE Dongcan, et al. Comparison of retail trade areas of retail centers with different hierarchical levels: a case study of East Nanjing Road, Wujiaochang, Anshan Road in Shanghai[J]. Urban Planning Forum, 2015(3): 50-60.
[6]张晓亮,陈智宏,刘冬梅,等. 一种基于多源数据的出租车分布预测方法研究[J]. 道路交通与安全,2015(1):47-51. ZHANG Xiaoliang, CHEN Zhihong, LIU Dongmei, et al. A taxi travel forecasting method based on multi-source data[J]. Road Traffic and Safety, 2015(1): 47-51.
[7]龙瀛,张宇,崔承印. 利用公交刷卡数据分析北京职住关系和通勤出行[J]. 地理学报,2012,67 (10):1339-1352. LONG Ying, ZHANG Yu, CUI Chengyin. Identifying commuting pattern of Beijing using bus smart card data[J]. Acta Geographica Sinica, 2012, 67(10): 1339-1352.
[8]裘炜毅,刘杰. 手机大数据视角下的工业区职住平衡分析方法[C]//中国城市规划年会论文集:城市规划新技术应用. 北京:中国建筑工业出版社,2015. QIU Weiyi, LIU Jie. Industrial job-housing balance in the perspective of mobile phone big data[C]// China Annual Urban Planning Forum Proceedings. Beijing: China Architecture & Building Press, 2015.龙瀛,沈尧. 数据增强设计——新数据环境下的规划设计回应与改变[J]. 上海城市规划,2015 (2):81-87. LONG Ying, SHEN Yao. Data augmented design: urban planning and design in the new data environment[J]. Shanghai Urban Planning Review, 2015(2): 81-87.
City Sensing: An Inventory Planning Tool Based on Spatial-temporal Big Data
1673-8985(2016)03-0009-08 中图分类号TU981 文献标识码A
段冰若
北京清华同衡规划设计研究院有限公司技术创新中心
规划师,硕士
王 鹏
北京清华同衡规划设计研究院有限公司技术创新中心
副主任,高级工程师,硕士
郝新华
北京清华同衡规划设计研究院有限公司技术创新中心
规划师,硕士
蔡玉蘅
北京清华同衡规划设计研究院有限公司技术创新中心
规划师,硕士
石 淼
北京清华同衡规划设计研究院有限公司技术创新中心
数据分析师,硕士
猜你喜欢
青春期健康(2022年13期)2022-07-18
英语文摘(2022年4期)2022-06-05
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
自然资源情报(2018年4期)2018-12-28
小天使·一年级语数英综合(2018年3期)2018-06-22
领导决策信息(2018年10期)2018-05-22
中国工程咨询(2017年8期)2017-01-31
太空探索(2016年5期)2016-07-12
中国工程咨询(2016年2期)2016-02-14
中国工程咨询(2016年3期)2016-02-13
