
集成极限学习机在手写体数字识别中的应用
2016-07-21 08:59张新英
河南科技 2016年3期
刘 聪 张新英
(中原工学院信息商务学院,河南 郑州 450007)
集成极限学习机在手写体数字识别中的应用
刘聪张新英
(中原工学院信息商务学院,河南郑州450007)
摘要:本文提出了一种ELM_Adaboost算法:把ELM(Extream leanring machine)作为弱分类器,训练ELM预测样本输出,通过Adaboost算法得到多个ELM弱分类器组成的强分类器。利用MATLAB GUI编写一套手写体数字识别系统,采集大量的学习样本,提取数字样本的“十三点网格特征”,使用ELM_Adaboost建立分类器。结果表明,该算法能够达到98.5%的识别率,为手写体数字识别提供指导性作用。
关键词:极限学习机;集成学习;手写体数字识别
随着国家信息化进程的加速,在邮政编码、统计报表、财务报表、银行票据等处理大量字符信息录入的场合,对手写数字识别系统的应用需求越来越强烈,对于主要都是由阿拉伯数字及少量特殊符号组成的各种编号和统计数据,处理这类信息的核心技术是手写体数字识别。将识别系统用于数字信息自动处理领域,节省人力,提高效率,加快信息流动,可创造巨大的经济效益。因此,手写数字的识别研究有着重大的现实意义。
考虑到传统神经网络(BP、RBF等)在训练过程中易陷入局部最优解,参数调整复杂,最近由新加坡学者提取出的一种新前馈神经网络的训练方法—极限学习机,它随机设置前馈神经网络的初始权值,通过求解输出权值的最小二乘解来完成网络的训练。整个过程不需要迭代,相对BP等算法有极快的速度、良好的泛化性。将极限学习机应用于模式识别领域已经得到很多专家学者的关注。
针对传统神经网络用于模式识别的过程中存在容易陷入局部极小值、收敛速度慢、解决小样本问题效果差等情况,将传统神经网络与Adaboost算法相结合,引入到分类及预测的问题中已经得到许多学者的研究[1]。本文将Adaboost与ELM算法相结合用于手写体数字识别中,进一步增强ELM分类器的泛化性,提高手写体数字的识别率。
1 极限学习机
极限学习机是Huang等提出的一种单隐层前馈神经网络的新学习算法。它随机给定输入权值矩阵和隐含层偏差,输出权值矩阵利用最小二乘解计算得到。
假设给定N个训练样本集(xi,ti),其中 xi=[xi1,xi2,……,xin]T∈Rn,ti=[ti1,ti2,……,tim]T∈Rm,ELM网络的激活函数g(x),隐含层节点数目为L,则ELM算法的训练步骤如下所示:①随机给定网络的隐含层连接权值(ai,……,bi),i=1,……,L;②隐含层激励函数为g(x)的前馈神经网络的输出可以表示为βi∈Rm。该式可以简化为:Hβ=Y。
2 集成极限学习机
Adaboost算法是一种自适应提升迭代算法,核心思想是将多个弱分类器的输出结果合成一个新的结果而产生有效分类。给定原始样本集D(x,y),从中选取m组数据作为训练样本,将m组数据初始权重都设置为1/m。用弱分类器训练T次,根据得到的结果更新训练数据权重。分类结果越好的分类器权重越大,经过T次迭代,可得到一个强分类器,即是由若干弱分类器加权得到。ELM_Adaboost模型即把ELM神经网络作为弱分类器,反复训练ELM神经网络预测样本输出,通过Adaboost算法得到多个ELM神经网络弱分类器组成的强分类器。编程实现方法如下。
2.1样本选择和网络初始化
从网络入侵数据库中选择m组训练数据,初始化测试数据的分布权值Dl(i)=1/m,根据样本输入输出维数确定ELM网络的隐含层节点数目,初始化ELM网络权值与阈值。
2.2弱分类器训练
训练第t个弱分类器时,用训练数据训练ELM网络并且预测训练数据输出,得到预测序列g(t)的预测误差和et,误差和et的计算公式为:

式中,g(t)为预测分类结果,y为期望分类结果。
2.3计算预测序列权重
根据预测序列g(t)的预测误差et计算序列的权重at,权重计算公式为:

2.4测试数据权重调整
根据预测序列权重at调整下一轮训练样本的权重,调整公式为:

式中,Bt是归一化因子,目的是权重比例不变的情况下使分布权值和为1。
2.5强分类器函数
训练T轮后得到T组弱分类函数f(gt,at),由T组弱分类函数f(gt,at)组合得到了强分类函数h(x):

3 样本采集及预处理
3.1样本采集
为了获取手写体数字样本,本文利用MATLAB GUI编写了一套手写体数字样本采集系统,利用getframe函数保存手写体数字图片。考虑到不同人的书写习惯问题,本文采集了10个人手写从0~9的数字图片,每张图片数量为50个,则样本数量为5 000个。
3.2图片预处理
由于MATLAB的采样时间跟不上鼠标的滑行速度,会造成断点,影响最终的识别率。因此,需要对采集到的图像进行预处理。为了方便特征提取,本文采取的图像预处理步骤为灰度化→腐蚀膨胀→取反→二值化→缩小字符范围。
4 特征提取
网格特征已经被广泛应用于数字识别的特征提取中,并已经被证明具有很好的效果。本文提取的“十三点网格特征”内容如下:①把字符水平分成4份,垂直分成2份,分别统计这8个区域的白像素的个数,得到8个特征,如图a所示;②水平和垂直各划两条线把水平和垂直分割成3份,统计这4条线穿过的白像素个数,得到4个特征,如图b所示;③字符图像全部白像素数目作为1个特征,如图c所示。综合①②③中的特征,一共得到一个13维的特征。
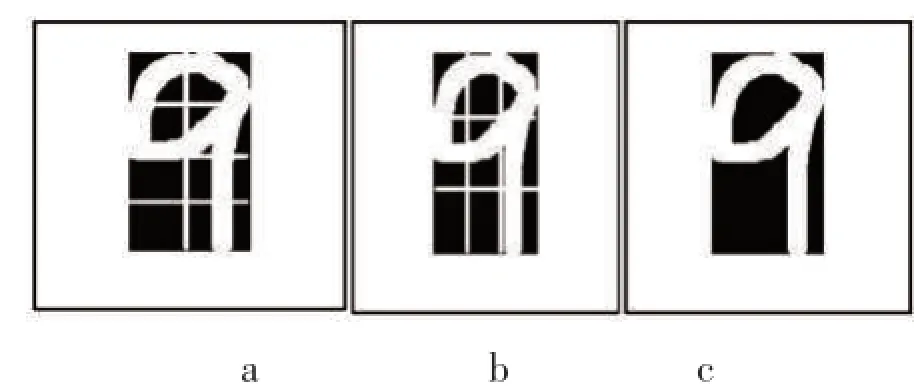
图1 数字识别的特征提取
5 结论
本文针对手写体数字识别,建立了一套样本采集库并提取了数字样本的网格特征。本文同时提出了一种ELM_Adaboost算法,进一步增强了ELM分类器的泛化性。与传统分类器进行比较,将该算法其应用于手写体数字识别中,提高了识别率。
参考文献:
[1]张威,魏冬生.基于Adaboost与支持向量机的人脸特征提取[J].微电子学与计算机,2007(5):69-72.
中图分类号:TP391.41
文献标识码:A
文章编号:1003-5168(2016)02-0027-02
收稿日期:2016-01-26
作者简介:刘聪(1988-),女,硕士,研究方向:控制工程与模式识别。
Integration Extream Leanring Machine Used in Handwritten Numeral Recognition
Liu CongZhang Xinying
(College of Information and Business,Zhongyuan University of Technology,Zhengzhou Henan 450007)
Abstract:An algorithm called ELM_Adaboost was proposed in this paper.Firstly,taking ELM(extream leanring machine)as a weak classifier,and then training ELM algorithm and predictting the output of sam⁃ples;Finally,obtaining a strong classifiers by the plurality of the ELM weak classifiers through the ada⁃boost algorithm.A set of handwritten numeral recognition system was composed by MATLAB GUI,and a large number of learning samples were collected,the Thirteen point grid feature of the digital sample was extracted,ELM_Adaboost was used to build the classifier.The results showed that the algorithm could achieve a recognition rate of 98.5%,which provides a guiding role for handwritten numeral recognition.
Keywords:extream leanring machine;ensemble learning;handwritten numeral recognition
