
稀疏降噪自编码算法用于近红外光谱鉴别真假药的研究
2016-07-12 12:58杨辉华雒志超蒋淑洁张学博尹利辉
光谱学与光谱分析 2016年9期
杨辉华,雒志超,蒋淑洁,张学博,尹利辉
1.桂林电子科技大学电子工程与自动化学院,广西 桂林 541004 2.北京邮电大学自动化学院,北京 100876 3.中国食品药品检定研究院,北京 100050
稀疏降噪自编码算法用于近红外光谱鉴别真假药的研究
杨辉华1, 2,雒志超1,蒋淑洁1,张学博3,尹利辉3
1.桂林电子科技大学电子工程与自动化学院,广西 桂林 541004 2.北京邮电大学自动化学院,北京 100876 3.中国食品药品检定研究院,北京 100050
近红外光谱分析技术作为一种快速、无损检测技术十分适用于真假药品现场鉴别。自编码网络作为当前机器学习领域研究的热点受到广泛关注,自编码网络是一种典型的深度学习网络模型,它比传统的潜层学习方法具有更强的模型表示能力。自编码网络使用贪婪逐层预训练算法,通过最小化各层网络的重构误差,依次训练网络的每一层,进而训练整个网络。通过对数据进行白化预处理并使用无监督算法对输入数据进行逐层重构,使网络更有效的学习到数据的内部结构特征。之后使用带标签数据通过监督学习算法对整个网络进行调优。首先对真假琥乙红霉素片的近红外光谱数据进行预处理以及白化预处理,通过白化处理降低数据特征之间的相关性,使数据各特征具有相同的方差。数据处理之后利用稀疏降噪自编码网络针对真假药品光谱数据建立分类模型,并将稀疏降噪自编码网络模型与BP神经网络以及SVM算法在分类准确率及算法稳定性方面进行对比。结果表明对光谱数据进行白化预处理能有效提升稀疏降噪自编码网络的分类准确率。并且自编码网络分类准确率在不同训练样本数量下均高于BP神经网络,SVM算法在少量训练样本的情况下更有优势,但在训练数据集样本数达到一定数量后,自编码网络的分类准确率将优于SVM算法。在算法稳定性方面,自编码网络较之BP神经网络和SVM算法也更稳定。使用稀疏降噪自编码网络对真假药品近红外光谱数据进行建模,能对真假药品进行有效的鉴别。
近红外光谱;真假药鉴别;自编码网络;白化
引 言
药物与人们的生活息息相关,但是市场上充斥着大量的假冒伪劣药品。假如不慎服用假药不但不能起到治疗疾病的效果,反而会对人体产生危害。因此真假药的鉴别有重要意义。近红外光谱分析技术以其分析速度快、不破坏样本、不污染环境等特点,广泛应用于农业产品的质量检测、食品工业、石油化工等领域[1]。同样在药物鉴别分析方面也有着广泛应用,Storme-Paris等[2]使用簇类独立软模式法(soft independent modeling of class analogy,SIMCA)算法对通过添加不同的赋形剂来达到相同药物活性成分的药品样本建立药品鉴别模型,实验表明使用近红外光谱技术能检测出药品构成中的微小差异,是鉴别真假药品的一种有效的手段。Deconinck等[3]利用决策树(classification trees)分别对Viagra和Cialis真假药品近红外光谱数据进行鉴别,其分类准确率分别达到83.3%和100%。Michel J Anzanello等[4]使用主成分分析(principal components analysis,PCA)结合K邻近算法(K-nearest neighbour,KNN)和支持向量机算法(support vector machine,SVM)对Viagra和Cialis真假药品进行鉴别。实验表明,SVM算法相对于KNN算法具有更高的分类准确率。Peinder等[5]、Floyd E Dowell等[6]使用偏最小二乘判别分析法(partial least squares discriminant analysis,PLS-DA)分别对Lipitor和抗疟疾药进行鉴别,验证了PLS-DA模型在光谱药品鉴别上的有效性。国内方面,冯艳春等[7]使用一致性检验、相关系数法、反相关系数法以及使用特征谱段的相关系数法快速鉴别真假药品。虞科等[8]使用最小二乘支持向量机(least squares support veotor machine,LSSVM)建立分类模型,对中药丹参粉末样品的真伪进行判别,相对于传统的SVM算法,LSSVM在训练速度上更有优势。
自编码网络自Hinton等[9]在2006年首次在Science上提出,便引起了学术界广泛的关注。自编码网络可以充分的利用未标签数据通过逐层的预训练(pre-train)得到各层网络的初始化权值,从而使网络能更有效的提取数据的特征。稀疏自编码(sparse autoencoder,SAE)在自编码的基础上加入稀疏惩罚项,限制被激活的隐层节点数。降噪自编码(denoising autoencoder,DAE)[10]在输入的信号中加入随机噪声,通过噪声数据重构原始信号使得学习到的特征更具有鲁棒性。
鉴于自编码网络具有优秀的模型表达能力,不但被广泛应用于海量数据建模,并且具有从少数样本集中学习到数据的本质特征的能力,针对琥乙红霉素真假药数据集,首先通过光谱预处理及白化处理消除光谱特征维度之间的相关性,然后利用稀疏降噪自编码网络对琥乙红霉素真假药数据集建立真假药鉴别模型。并与传统的BP神经网络以及SVM算法进行比较,结果表明稀疏降噪自编码网络在分类准确度和分类稳定性方面均优于BP神经网络和SVM算法。
1 算法描述
1.1 数据白化
在对数据建模的过程中,使建模数据的协方差矩阵转变为单位矩阵,将对建模的准确性产生积极的影响。将数据的协方差矩阵转变为单位矩阵的过程称为白化(whitening)或球化(sphering)。当数据具有统一的协方差,数据的特征之间是相互独立的,并且每个数据特征都具有相同的方差。
之所以要使数据的特征之间相互独立,因为在多维数据的概率模型中,各个维度的联合概率分布非常复杂,难以描述。当特征维度之间相互独立,联合概率分布就可以分解为多个简单的分布。每个数据特征方差单位化也是非常有必要的。相同的方差意味着特征之间有着相同的重要程度。数据白化的步骤如下:
(1) 对x零均值化,构造它的协方差矩阵,
Σ=E(xxT)
(1)
当数据变量之间是相关的,那么他的协方差矩Σ将不是对角矩阵。
(2) 为了解除数据之间的相关性,我们需要将协方差矩阵转变为对角矩阵。对角矩阵可以通过求解矩阵的特征值和特征向量来得到,
ΣΦ=ΦΛ
(2)
Λ是对角化矩阵,其对角元素就是Σ的特征值。矩阵Φ的列向量是协方差矩阵Σ的特征向量。对角化公式可以写作
ΦTΣΦ=Λ
(3)
对x做如下变换,
y=ΦTx
(4)
y即为解除相关后的数据,其协方差矩阵E(yyT)是一个对角化矩阵。
(3) 上面的Λ矩阵的对角元素可能是不相同的(特征值不同),白化的过程就是使Λ矩阵的对角元素单位化。已知
Λ-1/2ΛΛ-1/2=I
(5)
代入式(3)后得,
Λ-1/2ΦTΣΦΛ-1/2=I
(6)
因此我们将y乘上缩放因子Λ-1/2就得到白化后的数据w
w=Λ-1/2y=Λ-1/2ΦTx
(7)
得到的w不仅协方差是对角矩阵,而且是单位矩阵Ε(wwT)=Ι。
1.2 稀疏自编码网络
自编码网络是一种无监督的特征学习算法,通过逐层的预训练来获得网络的初始化权值。自编码网络通过构造一种使输入层与输出层具有相同节点数的神经网络,使用反向传播算法来训练。使输入数据与输出数据尽可能相等,从而学习到数据的内部特征。
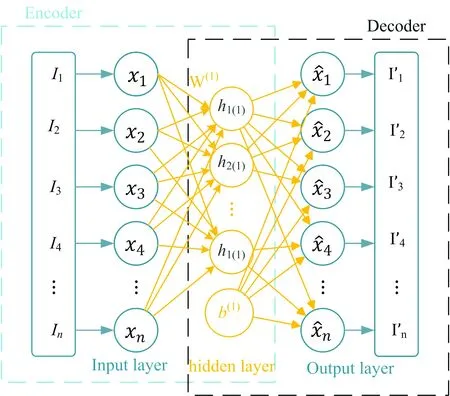
图1 单层自编码
如图1所示,一个单层的自编码网络只有一个隐层,输入和输出层有相同数量的神经元。自编码网络可分为编码层和解码层。第一阶段为编码过程,设x∈Rn。
h(x)=f(W1x+b1)
(8)
f(z)=1/(1+exp(-z))是非线性激活函数,h(x)∈Rm是隐层节点的激活值,W1∈m×n是连接权值矩阵。b1∈Rm是偏置值。自编码网络的输出为解码过程,
(9)
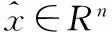
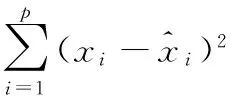
进一步限制隐层单元的激活值的稀疏性[11],损失函数添加惩罚因子,惩罚不符合稀疏期望的情况,使隐层节点的平均激活值保持在一个较低的比例ρ。所以优化问题就变为
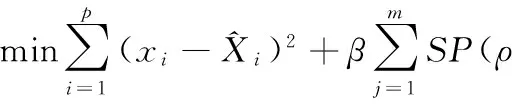
(10)
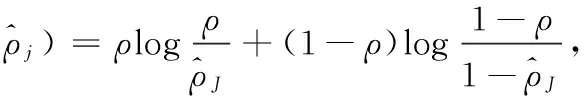
1.3 降噪自编码
Vincent等认为如果学习到的是一个好的特征表示,那么即便是数据有所缺失也应该能很好的重构出原始数据,为此提出了降噪自编码算法[7]。如图2所示。
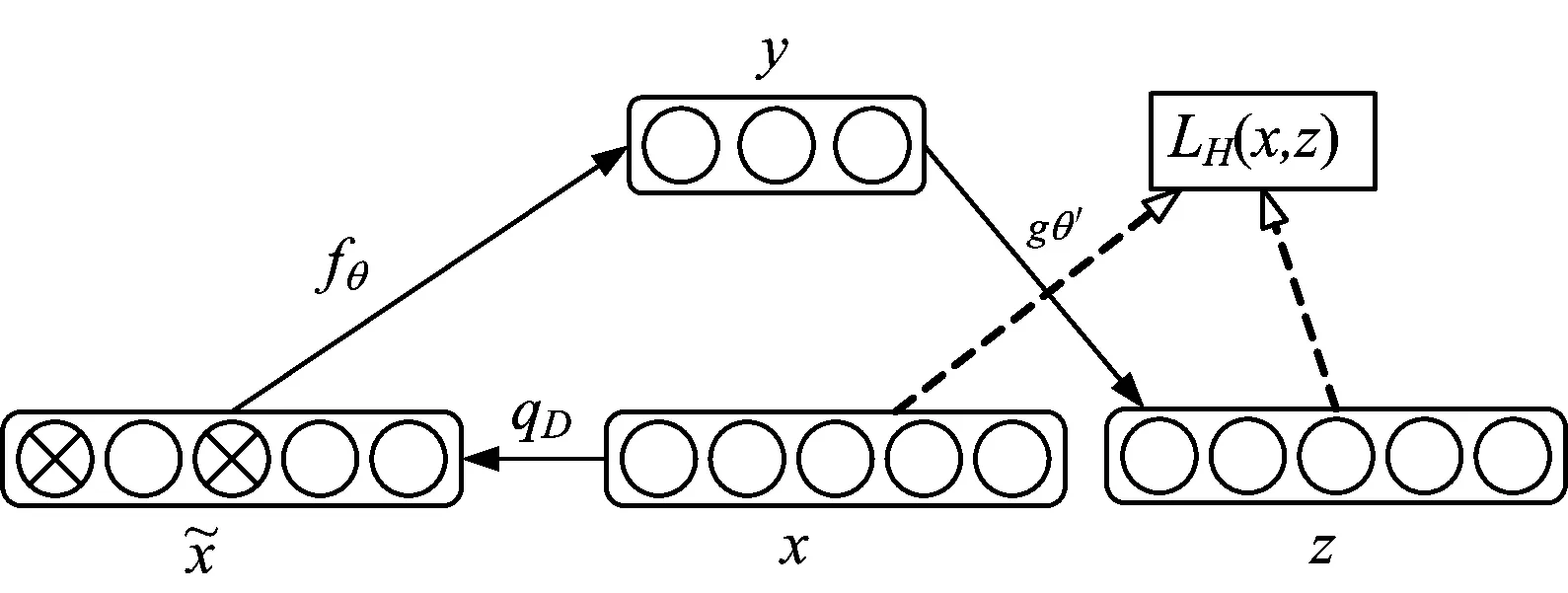
图2 降噪自编码
2 实验部分
2.1 数据
实验数据为西安利君厂生产的琥乙红霉素片以及其他药品, 采用铝塑包装透过塑料泡罩来测定光谱、以及打开铝塑包装对药片接触测定光谱,共2套光谱,涉及了不同批次、不同仪器、不同厂家和不同品种。分析过程中,将不同批次和不同仪器的测定光谱作为自身光谱,把不同厂家和不同品种的光谱作为假劣药品对照光谱。共包含负类样本(真药)171个,正类样本(假药)78个。其中每个光谱数据有1 247维。数据组成如表1所示。

表1 药品样本统计
2.2 数据处理
2.2.1 光谱数据预处理
将光谱数据进行一阶导数化(13个点平滑)消除基线和其他背景干扰,并通过矢量归一化预处理来校正由微小光程差异引起的光谱变化。处理后的光谱如图3所示。
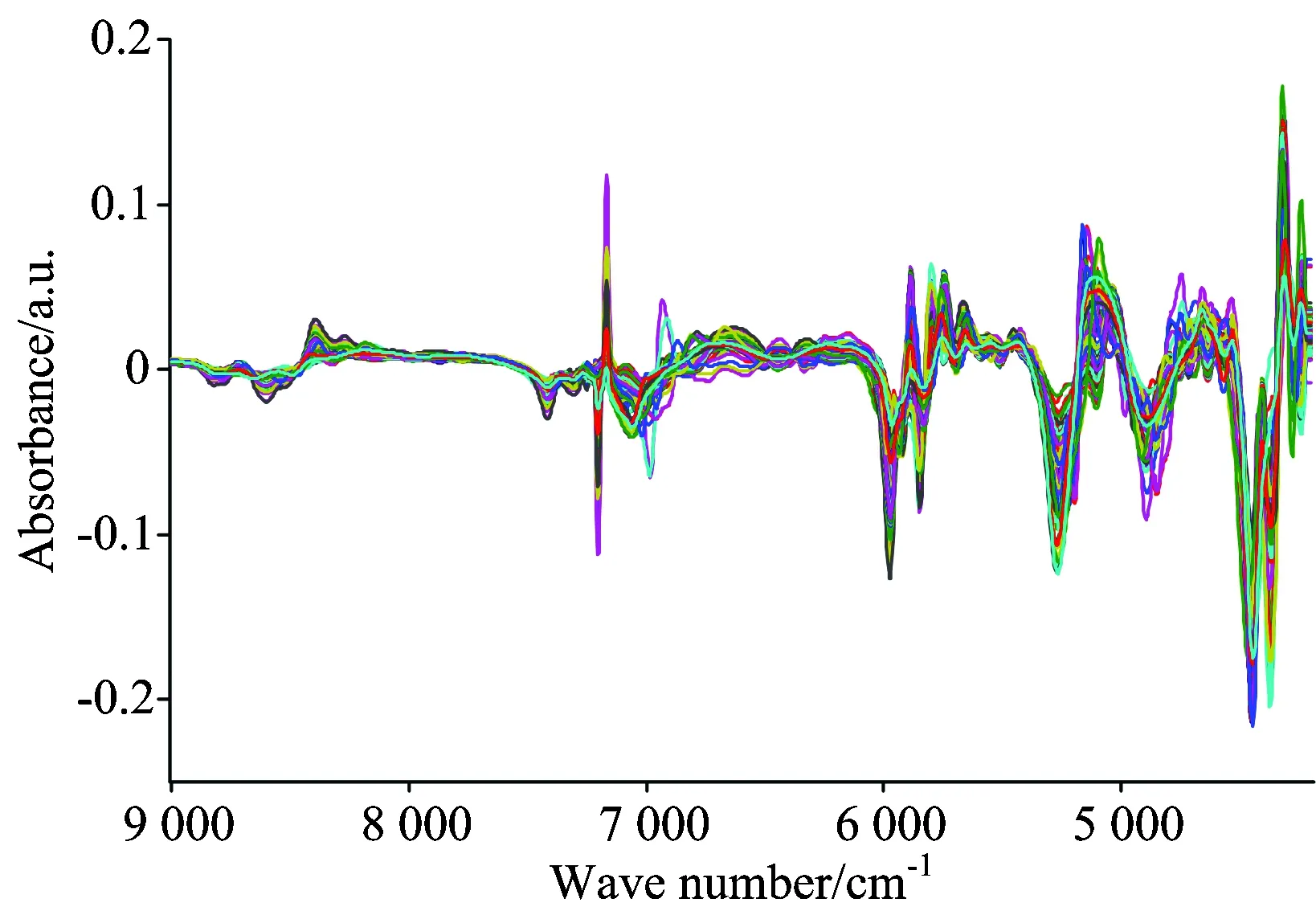
图3 药品样本近红外光谱
2.2.2 光谱数据白化处理
对光谱数据预处理后,将光谱数据各维的协方差矩阵转换为单位矩阵,并使各维的方差归一化。进行数据白化后消除了光谱维度之间的相关性,对建模有积极意义。
2.3 建立分类模型
MATLAB R2012b作为编码工具,选用DeepLearnToolbox中自编码工具箱(https://github.com/rasmusbergpalm/DeepLearnToolbox)。通过实验设定网络结构为1 247-200-100-1,如图4所示,网络中间两层通过自编码算法来初始化权值W,最后一层使用logistic回归对正负样本进行分类。
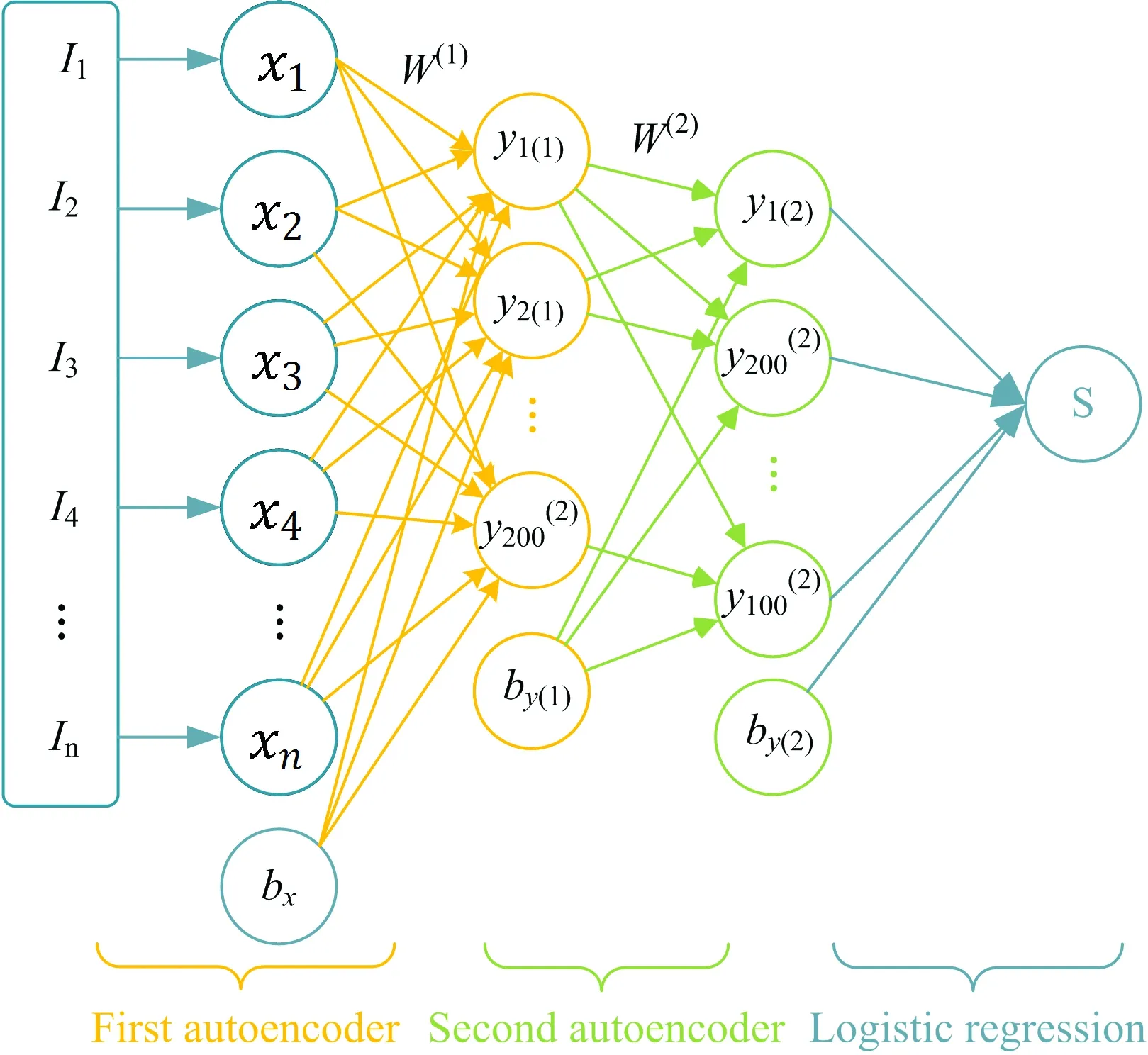
图4 两层自编码网络结构
将白化后的光谱数据(1 247维)作为稀疏降噪自编码网络的输入数据。在自编码网络预训练阶段无需样本标签参与训练,用训练集逐层训练自编码网络。共两层,其网络结构分别为1 247-200-1 247和200-100-200。其中稀疏参数ρ设为0.09,图5给出了稀疏参数ρ与第一层自编码网络重构误差的关系,可以看出选择0.09的稀疏参数使得自编码网络的重构误差最小。加入方差为0.001的高斯噪声,随机高斯噪声的加入使得学习到的特征更具有鲁棒性。学习率为0.001,神经元激活函数为sigmoid,使用BP算法训练网络,使用随机梯度下降法,每一层迭代200次。分别得到自编码网络权重W1和W2。预训练后,构造网络结构为1 247-200-100-1的神经网络。用预训练得到的权值W1和W2初始化神经网络的前两层连接权值。用带标签的训练数据集来训练整个网络。
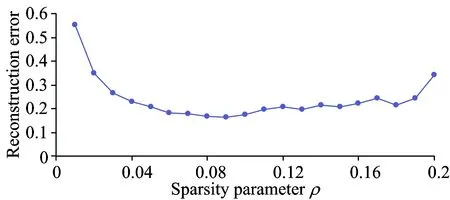
图5 不同稀疏参数下的自编码网络重构误差
选用常用的BP神经网络和SVM算法作为对比实验。其中神经网络选用MATLAB中的神经网络工具箱,网络结构分别选用单层网(1 247-200-1)以及与自编码网络具有相同结构的网络(1 247-200-100-1)。SVM算法选用台湾大学林智仁等开发的Libsvm工具箱。选用线性核函数以及高斯核函数作为对比,通过工具箱中的网格寻参函数交叉验证来确定SVM高斯核参数,其中参数c=1,g=0.32。
3 结果与讨论
实验设计按表2所示,根据训练集与测试集之间不同的比例,随机从各个类别的数据集中选取相应比例的数据组成训练集与测试集进行测试对比,取10次测试结果的平均值。测试结果如图6所示。
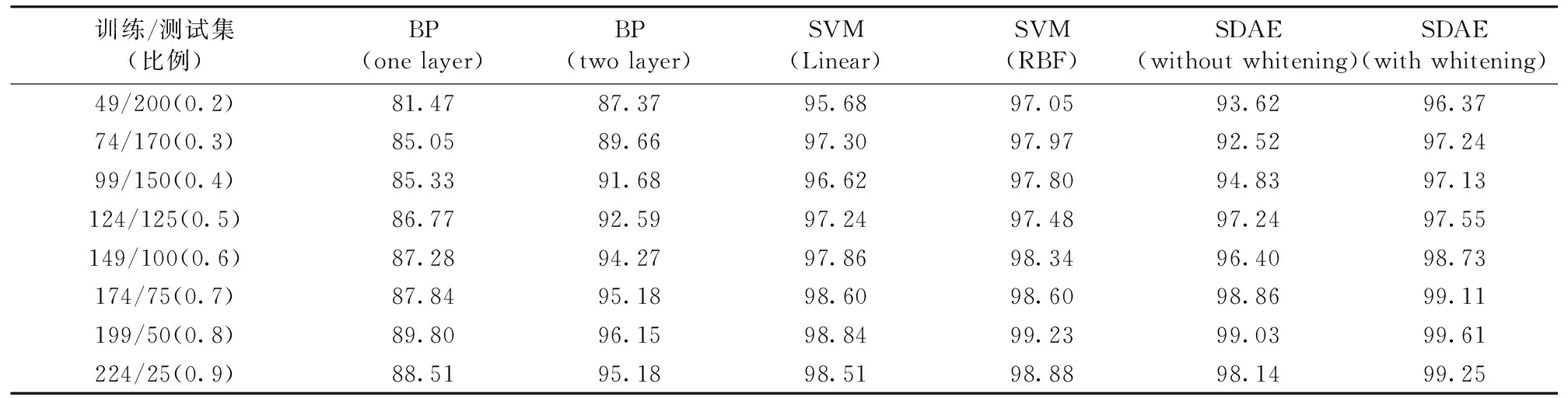
表2 不同比例训练集与测试集的各算法分类准确率
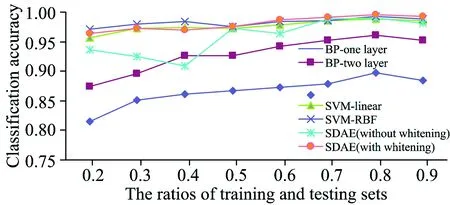
图6 各药品鉴别模型分类准确率
实验结果显示用经过白化处理后的数据训练自编码网络的准确率均高于未经白化处理数据训练的自编码网络。因此,数据白化处理能有效的提升分类模型准确率。传统的BP神经网络缺少了自编码网络的预训练过程,容易陷入局部极小值,所以BP神经网络算法的准确率不及自编码网络。在训练数据集数量较小的情况下,自编码能充分利用训练数据进行预训练,弥补训练数据集不足导致的欠学习。少量的训练数据集情况下,相对于传统BP神经网络有较大提高,但SVM在小训练数据集上的表现更优秀。随着训练集数量的增加自编码能的准确率也随之提升,并最终达到甚至优于SVM算法的分类准确率。
同时针对算法稳定性方面进行比较,分别计算各算法10次分类结果的平均绝对误差(mean absolute difference,MAE)。如图7所示,自编码网络的算法稳定性均优于传统的BP神经网络算法。自编码算法结合数据白化处理,使自编码算法的稳定性进一步提高。在少量训练数据集的情况下,自编码网络算法也依然能保持稳定性,随着训练数据集数量的增加,自编码网络算法的稳定性普遍优于SVM算法。
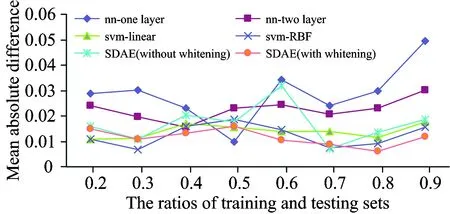
图7 各分类器的平均绝对误差
4 结 论
将真假药品光谱数据首先进行预处理以及白化处理,去除光谱特征之间的相关性。预处理后的光谱数据通过稀疏降噪自编码网络逐层预训练,学习得到光谱数据的内部结构特征。使用各层预训练得到的网络权重作为稀疏降噪自编码网络各层的初始值。预训练能避免神经网络训练中陷入局部最小值,同时提升神经网络收敛速度。之后使用带标签训练数据集对整个自编码网络进行调优,得到稀疏降噪自编码网络模型。使用该模型对琥乙红霉素片真假药品进行鉴别,其鉴别准确率高于BP神经网络,虽然在少量训练数据的情况下不及SVM,但是随着训练数据增加,自编码网络的准确性会优于SVM,因此自编码网络在大数据情况下更具有优势。在算法稳定性方面,稀疏降噪自编码网络也有很好的表现。其分类结果的平均绝对误差(MAE)整体优于BP神经网络和SVM算法。但是由于自编码首先需要逐层的预训练,再训练整个网络,其训练时间要长于BP神经网络和SVM算法。但已有研究通过并行计算或分布式计算来提升自编码网络算法执行效率。随着技术的不断成熟、以及数据规模的不断扩大,自编码网络在近红外药品鉴别领域会有更好地表现。
[1] CHU Xiao-li, LU Wan-zhen(褚小立, 陆婉珍).Spectroscopy and Spectral Analysis(光谱学与光谱分析), 2014, 34(10): 2595.
[2] Storme-Paris I, Rebiere H, Matoga M, et al.Analytica Chimica Acta, 2010, 658(2): 163.
[3] Deconinck E, Sacré P, Coomans D, et al.Journal of Pharmaceutical and Biomedical Analysis, 2012, 57: 68.
[4] Anzanello M J, Ortiz R S, Limberger R, et al.Forensic Science International, 2014, 235: 1.
[5] De Peinder P, Vredenbregt M J, Visser T, et al.Journal of Pharmaceutical and Biomedical Analysis, 2008, 47(4): 688.
[6] Dowell F E, Maghirang E B, Fernandez F M, et al.Journal of Pharmaceutical and Biomedical Analysis, 2008, 48(3): 1011.
[7] Feng Y C, Yang X L, Yang Z H, et al.Journal of Chinese Pharmaceutical Sciences, 2011, 20(3): 290.
[8] YU Ke, CHENG Yi-yu(虞 科,程翼宇).Chinese Journal of Analytical Chemistry(分析化学), 2006, 34(4): 561.
[9] Hinton G E, Salakhutdinov R R.Science, 2006, 313(5786): 504.
[10] Vincent P, Larochelle H, Bengio Y, et al.Proceedings of the 25th International Conference on Machine Learning, 2008: 1096.
[11] Lee H, Ekanadham C, Ng A Y.Proc.Conference on Advances in Neural Information Processing Systems (NIPS), 2008.873.
(Received Mar.18, 2015; accepted Jul.24, 2015)
Sparse Denoising Autoencoder Application in Identification of Counterfeit Pharmaceutical
YANG Hui-hua1, 2, LUO Zhi-chao1, JIANG Shu-jie1, ZHANG Xue-bo3, YIN Li-hui3
1.College of Electronic Engineering and Automation, Guilin University of Electronic Technology, Guilin 541004, China 2.College of Automation, Beijing University of Posts & Telecommunications, Beijing 100876, China 3.National Institute for Food and Drug Control, Beijing 100050, China
Near-infrared(NIR)As a fast and non-destructive testing technology, spectroscopy techniques is very suitable for pharmaceutical discrimination.Autoencoder network, as a hot research topic, has drawn widespread attention in machine learning research in recent years.Compared with traditional surface learning algorithm models, Autoencoder network has more powerful modeling capability as a typical deep networks model.Based on the unsupervised greedy layer-wise pre-training, autoencoder trains the network layer by layer while minimizing the error in reconstructing.Each layer is pre-trained with an unsupervised learning algorithm, learning a nonlinear transformation of the input of each layer which is the output of the previous layer.Pre-whitening process could get the inner structural features of the data more effectively.The supervised fine-tuning is followed with the unsupervised pre-training which sets the stage for a final training phase.The deep architecture is fine-tuned with respect to a supervised training criterion with gradient-based optimization.In this paper, firstly, the preprocessing step and pre-whitening transformation were used to treat near-infrared spectroscopy data of erythromycin ethylsuccinate, The pre-whitening transformation would reduce the correlation of the features, which gave each feature the same variance.Experimental results showed that the pre-whitening process had improved the classification accuracy of Sparse Denoising Autoencoder (SDAE) effectively.The SDAE with two hidden layers combined with pre-whitening was used to build the classification model for the identification of counterfeit pharmaceutical.The BP neural networks was compared with SVM algorithm for the classification accuracy and mean absolute difference (MAD).SDAE algorithm had higher classification accuracy than BP neural networks which had the same network structure with the SDAE networks, and SDAE algorithm also performed better than the SVM algorithm when the train datasets achieved a certain amount.As to the generalization performances, SDAE algorithm had less mean absolute difference of classification accuracy than SVM and BP Neural Networks.This result showed that SDAE algorithm could be effectively used to discriminate the counterfeit pharmaceutical.
Near-infrared spectroscopy;Pharmaceutical discrimination;Autoencoder;Whitening
2015-03-18,
2015-07-24
国家自然科学基金项目(21365008,61105004),广西自然科学基金项目(2012GXNSFAA053230,2013GXNSFBA019279),广西信息科学实验中心重点基金项目(2012-02),广西高等学校优秀人才资助计划项目(桂教人[2011]40号),桂林电子科技大学研究生教育创新计划项目(GDYCSZ201478)资助
杨辉华,1972年生,北京邮电大学自动化学院教授 e-mail: 13718680586@139.com
TP391
A
10.3964/j.issn.1000-0593(2016)09-2774-06
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(神奇星球)(2022年5期)2022-08-15
小哥白尼(神奇星球)(2022年4期)2022-06-06
小哥白尼(神奇星球)(2022年3期)2022-06-06
空间科学学报(2021年1期)2021-05-22
热带农业科学(2020年7期)2020-08-31
环境与生活(2020年4期)2020-02-19
快乐语文(2018年25期)2018-10-24
茶叶(2015年3期)2015-12-13
中国光学(2015年5期)2015-12-09

- 光谱学与光谱分析的其它文章
- 基于高光谱的环首都地区数字高程模型与可吸入颗粒物的空间相关性研究
- 大豆硒蛋白构象的光谱法研究
- Synthesis of La-Co-O Mixed Oxides via Polyethylene Glycol-Assisted Co-Precipitation Method for Total Oxidation of Benzene
- Mercury in Sclerotia of WolfiporiaExtensa (Peck) Ginns Fungus Collected Across of the Yunnan Land
- 可拓神经网络模式识别对成品油的鉴别与测量
- Spectroscopic Analysis of Organophosphorus Pesticides Using Colorimetric Reactions