
基于时空视觉显著性特征的行人检测
2016-06-23 08:07曾召华杨新花
电视技术 2016年2期
曾召华,杨新花,赵 谦
(西安科技大学 通信与信息工程学院,陕西 西安 710054)
基于时空视觉显著性特征的行人检测
曾召华,杨新花,赵谦
(西安科技大学 通信与信息工程学院,陕西 西安 710054)
摘要:在分析现有的行人检测算法的基础上,针对前景提取不完整及检测误差较大等不足,提出了一种基于时空视觉显著性特征的行人检测改进算法。在具有代表性的Itti模型的基础上,使用更接近于人类视觉的Lab颜色空间对其颜色空间进行改进,并将运动特征及基于轮廓搜索的内部空洞填充法引入其中,生成总显著图。提取ROI,采用HOG特征结合SVM分类器对ROI进行行人检测。实验结果表明,该算法在一定程度上避免了误检和漏检的发生,相比较HOG算法具有较好的检效果。
关键词:行人检测;视觉显著性特征;空洞填充;HOG特征
行人检测是图像处理与计算机视觉领域中备受关注的研究课题之一,同时也是智能交通和驾驶辅助系统的重要组成部分,快速准确的行人检测机制能够为智能车辆的安全驾驶和自主导航提供关键技术和安全保障。现有的行人检测方法可以分为三类[1]:基于模板、基于模型和基于学习。其中,基于模板的检测,求解人体模板的过程较为复杂;基于模型的检测,虽采用了已建立好的模板进行匹配,但易受光照以及行人姿态变化的影响;基于学习的检测,先提取人体各特征,后利用模式识别的方法进行分类。其中最为常用的是基于梯度方向直方图(Histogram of Oriented Gradient,HOG)特征描述行人的方法,但该方法所提取的特征向量维数较大,使得计算量也较大,严重影响实时性,加上线性SVM作为弱分类器进行级联训练后,虽节省了时间,但却需要在整个图像区域内进行匹配,严重影响实时性与精确性。
在机器视觉领域,研究者们对视觉注意机制的兴趣与日俱增,该机制可以从大量的视觉数据中确定出最相关的部分。Itti[2]等人于1998年,根据早期原始视觉系统的神经网络结构和行为,率先提出了视觉注意机制模型的概念,并在2001年度Nature上对该模型理论作了进一步完善。文献[1]将经典的itti模型引入到行人检测中,在一定程度上能够实现准确的行人检测,该方法克服了HOG行人检测算法加入SVM分类器之后需要对整个区域进行检测的缺陷,但是,采用RGB颜色空间处理图像,处理结果受到了影响。文献[3]将背景差分法与Itti模型有效地结合在一起,实现了对海底弱小目标的检测,相比较常规背景差分,该方法能够更好地检测到不清晰的目标。文献[4]对Lab颜色空间进行了相应的介绍,并将其与其他颜色空间进行了比较,结果表明,Lab空间更接近于人类视觉机制。
针对上述不足之处,本文对Itti模型中的颜色空间进行相应的改进,获得颜色、亮度、方向等空间特征显著图,同时将基于时间的运动特性引入该模型中并对前景图采用基于轮廓搜索的空洞填充法进行处理,得到基于时空特征的总显著图,获得感兴趣区域(Region of Interest,ROI)。然后,在ROI内利用行人分类器进行检测。
1基于HOG与SVM的行人检测
HOG特征是一种局部区域特征描述,通过统计和计算局部区域上的梯度方向直方图来构成特征,且对光照变化和小幅度的偏移不敏感。结合支持向量机(Support Vector Machine,SVM)训练得到的弱分类器可实现人与非人物体的准确判断。
1.1HOG特征计算
在HOG特征提取之前,首先,对图像进行灰度化处理,然后,采用Gamma校正法对输入图像颜色空间进行归一化处理,目的是调节图像的对比度,抑制光照变化、阴影及噪声干扰等所造成的影响。具体步骤如下:
1)在简单梯度算子[-1,0,1]下,计算水平方向梯度值、垂直方向梯度值和梯度方向角。
2)把样本图像划分为若干个像素单元(cells),并对所有像素的梯度幅值进行直方图统计。
3)将几个cells组成一个block,并将block中的所有cells特征描述符串联得到HOG特征描述子。
4)将图像内的所有block内的HOG特征描述子串联得到图像的HOG特征向量。
1.2检测过程
线性的SVM分类器是用来完成数据集分类的最简单常用的方法之一。首先,从训练集中提取HOG特征,将得到的特征向量作为已训练完成的SVM分类器的输入,在整幅图像范围内判断图像中是否有行人。对于与人体样本相似的非人样本,在初始训练中很难分辨,易产生误判,同时由于行人姿态,及外界环境中干扰的存在,即使训练的分类器性能良好也会产生漏检、误检。因此,有研究者提出先对视频图像做背景滤除[3],然后再做检测。本文正是在此基础上引入了Itti的改进模型,并对得到的前景图做了相应的填充。
2视觉显著性的计算
视觉注意模型模仿的是人类的神经系统机制,通过神经网络竞争机制及对各特征的整合得到部分感兴趣区域。其中Itti 模型是该领域较为经典的检测模型之一,因其简单高效等特征而被研究者们普遍采用。该模型采用自底向上的机制来计算视觉显著图,从图像的特征出发,不依赖于任何先验知识。基本思想是:首先,提取图像的颜色、亮度、方向特征,采用金字塔滤波得到各特征的尺度空间表示,然后采用中央强化周边抑制的方法计算不同尺度空间的特征差异,最后进行归一化,合并特征显著图,得到总显著图。
2.1提取颜色显著性
在RGB颜色空间中采用R,G,B三种颜色来描述输入图像,且其亮度和颜色之间存在着一定的关系,因此人们感觉到的并不是颜色而仅仅是亮度。而Lab空间[4]将亮度和颜色分开来表示,L通道没有颜色,a和b通道有颜色。研究表明,Lab空间更接近于人类视觉感知系统,且调节简单,速度快。
从RGB空间转化到Lab空间的方法如下:首先,对输入的彩色图像提取R、G、B三通道值,归一化颜色值到[0,1]区间,如式(1)所示
[R,G,B]=[R,G,B]/255
(1)
令X,Y,Z,为由RGB空间向Lab空间转化的中间变量,具体过程如式(2)~(7)所示
X=0.412 456 4×R+0.357 576 1×G+0.180 437 5×B
(2)
Y=0.212 672 9×R+0.715 752 2×G+0.072 175 0×B
(3)
Z=0.019 333 9×R+0.119 192 0×G+0.950 304 1×B
(4)
L=116.0×fy-16.0
(5)
a=500.0×(fx-fy)
(6)
b=500.0×(fy-fz)
(7)
其中,fx,fy,fz的计算详见文献[4]。
2.2提取亮度和方向显著性
首先,将图像分解为一组特征图,从特征图中分别提取亮度特征I,方向特征O[5]。具体计算如下
I=(R+G+B)/3
(7)
O(θ)=‖IG(θ)‖+‖IGπ/2(θ)‖
(8)
其中,R,G,B分别为彩色图像像素的RGB值;I为通过式(7)求得的亮度值,G(·)表示Gabor滤波;θ表示局部方向;θ∈{0°,45°,90°,135°}。
显著性区域指的是与周围区域相比差异明显的区域,按照中央强化四周弱化的机制对图像的颜色、亮度、方向等特征图进行处理。用不同尺度的图像相减来模拟图像四周与中心的差分,可得到不同尺度下的视觉刺激图[6-9]。不同尺度的图像做差分运算得到相应特征的显著图,如式(9)所示
M(c,s)=∣M(c)ΘM(s)∣
(9)
其中,c∈{1,2,3},s∈{3,4,5}。“Θ”表示差分运算。首先采用插值法对不同尺度的两幅图像做插值得到相同尺度的图像,再逐像素进行减法运算,然后将各特征图归一化。
各个尺度的特征图相加得到相应特征的显著图,如式(10)所示
M=∑∑N((M(c,s))
(10)
最后采用求均值的方法将其融合为一幅图像获得总显著图,如式(11)所示
S=[N(I)+N(C)+N(O)]/3
(11)
图1为采用上述方法得到的各特征分量的视觉显著图。

a 原图 b 亮度显著图 c 颜色显著图

d 方向显著性图 e 总显著图 图1 视觉显著图
3实现结果与分析
为了证明本文算法的有效性,选取了INRIAPerson行人数据库中的部分行人图片及PETS2001中的一段标准视频在MATLAB2010b环境下进行实验,部分仿真结果在VS2010结合Opencv2.4.1环境下完成。静态图片中,行人姿态各异,数量不等,使用传统算法检测,误检较大;而视频中摄像头和行人之间的距离随时间变化,且行人特征包括了正面、侧面以及转身等不同情况,存在一定的检测难度。最后,将本文算法与其他相关算法的结果相比较。 比较结果如图2~图3所示。

a1 原图 a2 HOG检测结果 a3 本文算法a 第一组

b1 原图 b2 HOG检测结果 b3 本文算法b 第二组

c1 原图 c2 HOG检测结果 c3 本文算法c 第三组

d1 原图 d2 HOG检测结果 d3 本文算法d 第四组图2 本文算法在静态图像检测结果
为便于更好地了解算法的性能,行人检测算法通常使用漏检率(false negative rate)和误检率(false positive rate)来评定算法的优劣性。误检率定义如式(12)
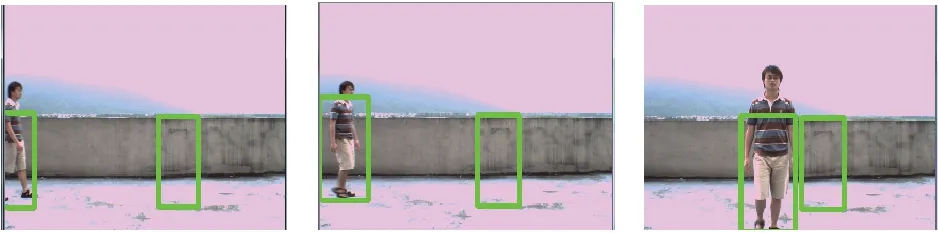
a1 第7帧 a2 第14帧 a3 第60帧

a4 第74帧 a5 第83帧 a6 第114帧a 传统HOG检测结果

b1 第7帧 b2 第14帧 b3 第60帧

b4 第74帧 b5 第83帧 b6 第114帧b 文献[3]算法检测结果

c1 第7帧 c2 第14帧 c3 第60帧

c4 第74帧 c5 第83帧 c6 第114帧c 基于改进的时空视觉注意机制算法检测结果图3 本文算法在视频中的检测结果
FalseNegativeRate=[FalseNegative/
(TruePositives+FalseNegative)]×100%
(12)
误检率定义如下
FalsePositiveRate=[FalsePositive/(TrueNegatives+
FalsePositives)]×100%
(13)
表1给出了本文算法与HOG算法在静态图片中的检测性能比对信息;表2给出了本文算法与其他相关算法在视频中检测性能的比对信息。其中,误检率和漏检率均指所有帧中的最大值。
从表中比对数据可以看出,本文算法在行人数目、姿态以及外界环境发生较大变化的情况下,相比HOG算法具有较高的准确率。
表1静态图片中算法的性能比对
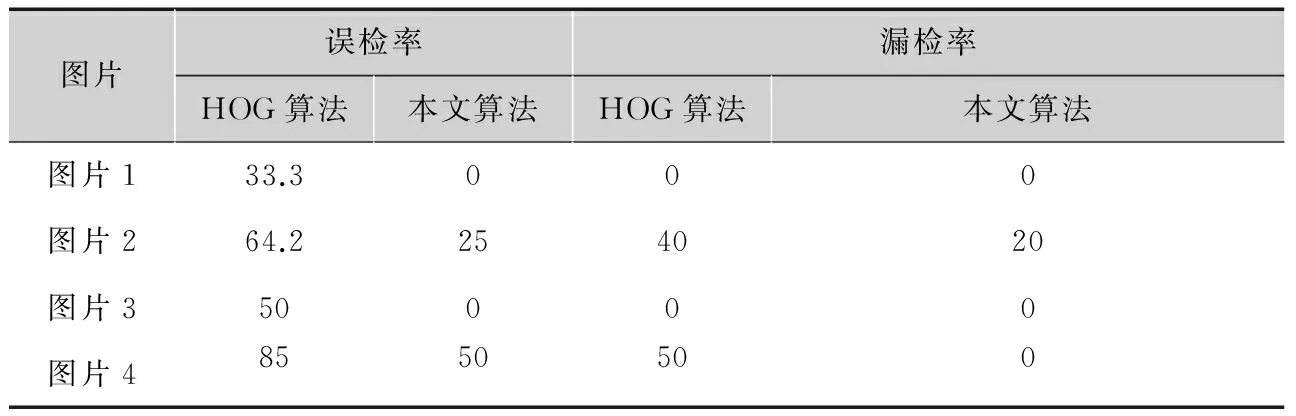
图片误检率漏检率HOG算法本文算法HOG算法本文算法图片133.3000图片264.2254020图片350000图片48550500
表2视频中算法的性能比对
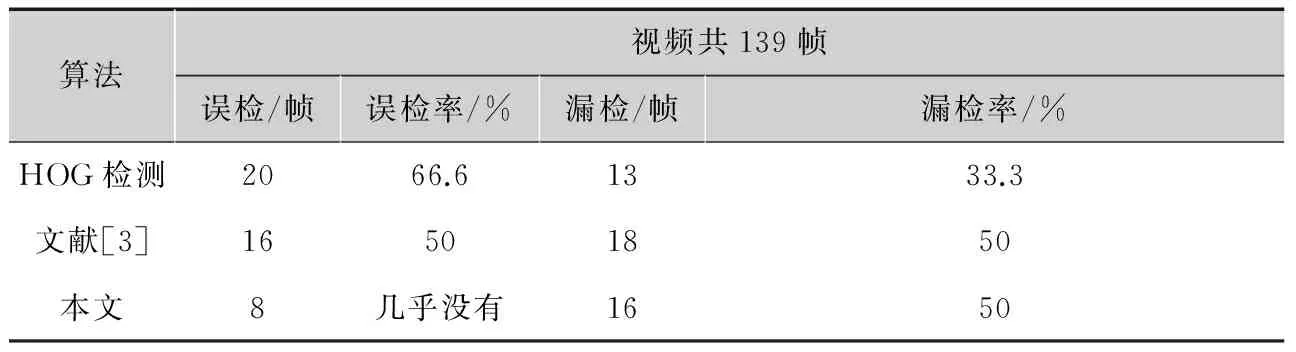
算法视频共139帧误检/帧误检率/%漏检/帧漏检率/%HOG检测2066.61333.3文献[3]16501850本文8几乎没有1650
4结语
文中引入视觉显著性特征,提取视频图像的颜色、亮度、方向等特征,融合后得到总显著图;采用三帧差分法和基于轮廓搜索的空洞填充法对前景目标进行处理,结合总显著图得到ROI;最后,采用基于SVM的HOG检测在ROI内检测行人。实验结果及相关分析表明,本文算法在目标发生旋转、大小变化时相比较其他两种算法具有更高的准确率,但对于漏检现象效果不理想,且随着行人数目的增多,环境的复杂化加剧。今后研究的重点会针对以上不足,结合多种有效的特征提高算法的有效性和准确性。
参考文献:
[1]张艳军,邓永生,田甄. 基于视觉注意机制的行人检测方法[J].科技视野(高校科技),2015(15):98.
[2]ITTI L,KOCH C,NIEBUR E. A model of saliency based visual attention for papid scene analysis[J].IEEE transactions on pattern analysis machine and intelligence,2002,20 (1):1254-1259.
[3]王秀芬,王汇源.基于背景差分法和显著性图的海底目标检测方法[J].山东大学学报(工学版),2011,2(41):12-16.
[4]龚涛,刘怡,黄自力,等. 基于相关配准的帧间差分算法[J]. 电视技术,2014,38(1):195-197.
[5]周文明. 动态场景下基于空时显著性的运动目标检测方法研究[D].上海:上海交通大学,2011.
[6]白晓方,杨卫,陈佩珩. 一种改进的运动目标检测与跟踪方法[J]. 电视技术,2014,38(1):180-182.
[7]DALAL N,TRIGGS B .Histograms of oriented grasients for human detection[C]//IEEE International Conference on Computer Vision and Patten Recognition.[S.l.]:IEEE Press,2015(1):886-893.
[8]曲永宇,刘清,郭建明. 基于HOG和颜色特征的行人检测[J]. 武汉理工大学学报,2011,4(40):134-137.
[9]章春凤,宋加涛,王万良. 行人检测技术研究综述[J]. 电视技术,2014,3(38):157-162.
责任编辑:闫雯雯
Pedestrian detection based on spatio-temporal visual significant feature
ZENG Zhaohua,YANG Xinhua,ZHAO Qian
(SchoolofCommunicationandInformationEngineering,Xi’anUniversityofScienceandTechnology,Xi’an710054,China)
Abstract:Through the analysis of the current pedestrian detection algorithm, for the disadvantage of incompletely extracting foreground and a large number of detecting error, a pedestrian detection algorithm based on spatio-temporal visual significant feature is proposed. On the basis of the typical Itti saliency model, use lab color space which is closer to human vision to improve the model’s color space and introduce into the motion feature and inner cavity filling method based on contour searching, generate saliency map.Extract ROI, then,using HOG feature in comnination with SVM to detect the ROI, in order to detect the pedestrian. The experimental results demonstrate that the approach can aviod some false nagative and false positive to a certain extent, and have better detecting effect compered with HOG detection algorithm.
Key words:pedestrian detection; visual significant feature; cavity filling; HOG feature
中图分类号:TP391.41
文献标志码:A
DOI:10.16280/j.videoe.2016.02.022
基金项目:陕西省科技计划工业科技攻关项目(2014K06-37;2015GY023);西安市科技计划技术转移促进工程(CXY1440(4));西安市碑林区应用技术研发项目(GX1311;GX1310;GX1417);西安科技大学博士启动金(2015QDJ015)
收稿日期:2015-07-22
文献引用格式:曾召华,杨新花,赵谦. 基于时空视觉显著性特征的行人检测[J].电视技术,2016,40(2):115-118.
ZENG Z H,YANG X H,ZHAO Q. Pedestrian detection based on spatio-temporal visual significant feature[J].Video engineering, 2016,40(2):115-118.
