
关键词抽取策略研究
2016-06-18 08:51郝晓燕张兴忠陈耀文
太原理工大学学报 2016年2期
胡 琪,郝晓燕,张兴忠,陈耀文
(太原理工大学 计算机科学与技术学院,太原 030024)
关键词抽取策略研究
胡琪,郝晓燕,张兴忠,陈耀文
(太原理工大学 计算机科学与技术学院,太原 030024)
摘要:针对传统关键词抽取方法统计特征单一,常用位置特征对文本写作结构有局限性的问题,提出了一种新的关键词抽取方法。该方法根据关键词在文中出现位置的分布特性,计算并提取出新的间距特征,更加适用于当下网络文本随意多变的写作方式,同时考虑影响关键词识别的各个因素,通过多个特征的提取与结合,改善了一般位置特征和传统统计方法的不足之处。最终和传统TF-IDF方法的对比实验结果中,文中所提出的方法各方面性能都有所提高,表明该方法是有效可行的。
关键词:关键词抽取;词频;间距;词性;重要度
随着现在信息技术和互联网的不断发展,信息文本的数量正呈爆炸式增长,人们如果想快速地从这些海量信息资源中查找出自己所感兴趣的内容,就需要抽取出其中的关键词,来代表文档的主要内容,方便人们查询。关键词自动抽取是利用计算机从文献中提取出反映主题信息的词语,是信息检索、文本分类、文本聚类以及自动文摘生成等技术的基础。LUHN在20世纪50年代首次开展关于关键词自动抽取的实验后,相关领域内的研究就一直没有间断过,同时也不断出现新的方法来提高关键词抽取的准确率。目前,国内外相继提出许多关键词自动抽取的方法,主要可分为3类:基于统计的方法、基于机器学习的方法和基于语言学的方法。
1) 基于统计的方法。基于统计的方法是利用文本特征的统计信息进行关键词抽取,如词频[1]、TF-IDF(Term Frequency Inverse Document Frequency)[2]、词共现[3]、N-Gram[4]、复杂网络特征[5]等,该类方法是最早被提出的,不需要像机器学习那样进行复杂的训练,可以对文本直接进行关键词的提取,因此是目前应用最多,并且效果较好的关键词抽取方法之一。
2) 基于机器学习的方法。基于机器学习的方法是把关键词抽取问题看成二元分类问题,该类方法需要先对大规模语料库进行学习,然后对训练集进行训练,训练的同时提取出抽取关键词的特征,来构造关键词抽取的分类模型,最后再利用该模型标注词语,判断是否为关键词,常用的方法有:FRANK et al的贝叶斯算法[6]、决策树、最大熵模型等,该类方法不能直接对文本进行关键词的抽取,过程较为复杂,使用起来不是很方便。并且只要训练集不同,构造的分类模型也会有所差异,最终也会影响关键词抽取的准确性,因此该类方法在应用方面不是很广泛。
3) 基于语言学的方法。基于语言学的方法是从人类语言学的角度出发,通常需要对中文文本从词、句、语义、篇章等层级进行分析,如基于词汇链的方法[7]。这类方法比较人性化,更加贴近人类对文章的理解过程,但如何根据文章的结构,准确地对它进行语言学方面的划分,目前还没有十分准确的解决方法,但是在近几年,此类方法受到了该领域研究者的广泛关注。
基于机器学习的方法和基于语言学的方法,虽然在性能方面可能会略好,但是其过程相对复杂,从实用性来说没有基于统计的方法使用广泛。而传统的统计词频的方法,由于其特征单一,考虑方面不全,很容易受到一些高频非关键词的干扰,此外,一般的位置特征仅是对文章结构进行划分,对文本写作方式有一定的局限性。针对上述问题,以统计方法为基础,提出了新的间距特征,排除了常用位置特征的不足,同时从多个方面进行考虑,结合词频、词性、重要度多个特征进行关键词抽取。从实验结果来看,与传统方法相比,本文提出的方法在准确率、召回率等各方面性能均有所提高。
1关键词抽取策略
1.1文本预处理
中文不像英文那样在书写方面词语之间就有天然的分隔符,而且由于中文语义的多样性,切分不同就会产生不同的意思。所以在实验之前,先对数据集进行简单的分词处理,把文本中的词语用空格隔开,分成若干个词条。
去除文本中的标点符号及停用词,如逗号、句号之类的标点和“的”、“了”、“吗”之类的虚词,因为这些标点符号和停用词对文章的主题表达并没有实际的意义,只会对关键词的抽取带来影响和干扰。然后再去除文本中多余的格式、表格等内容,并保留词语所在的原来位置。对于处理后的文本,人工进行关键词标注,作为实验参考结果。
1.2候选词汇的特征统计
虽然传统的词频统计方法来抽取关键词过程简单,使用起来方便,但它一方面容易将一些高频常用词误判为关键词,另一方面又很可能无法识别出那些出现次数较少,但关键度较高的词语。因此最终降低关键词抽取的准确率。
本方法考虑到影响关键词识别的各个因素,经过对比分析,统计出词频、间距、词性、重要度作为关键词抽取的特征。
1.2.1词频
关键词要想准确的表达文本的主题信息,就必然会在文中多次出现。因此,词语在文本中出现的次数越多,作为关键词的可能性也就越大。FRANK[6]早在他提出的KEA算法中,就将词频作为实验研究的一个特征项,并且取得很好的结果。TURNEY之后也用实验证明了关键词词频是与其所属领域是相关的。而后续的研究者又发现,即使不使用领域信息,关键词词频仍然能够有效工作。所以,本文选取词频作为关键词抽取的一个重要特征。具体计算公式如下。
(1)
式中:ti表示提取的词频特征;f表示该词在文章中出现的次数。
对于词频特征项的计算,本文选取的是非线性函数的计算方法。由式(1)可以看出,词在文中出现的次数越多,即词频越高,公式的值也就越趋向于1,该词成为关键词的可能性也就越大。同时,词频若高到一定程度,它的波动范围又很小,因此也一定程度上排除了那些高频的常用词对关键词抽取的干扰,符合人类写作的实际情况。
1.2.2间距
在关键词的位置特征研究中,杨颖[8]、谢晋[9]、张瑾[10]等多位研究者,在他们各自的实验中都将文章分为标题、摘要、首尾段、正文等多个部分,并根据关键词在文中的出现位置,为它们分配不同的参数值作为关键词识别的一个特征项。但是对于网络文本或新闻报道,很多都没有摘要或标题,有时也只用一个段落进行叙述,此时这样的位置分析并不合适。
此后杨震等[11]在关键词的排序研究中,认为关键词在文中的分布,具有小的内间距和大的外间距的特点。作为主题关键词,为了表达作者叙述的完整性,在局部小话题或小段落中出现次数会比较多,而局部范围较小,相邻出现位置之间就会产生较小的间距;同时作为整个文本的关键词,又必定贯穿于全文,会在文中多个段落或话题中出现,而此时整个文本范围较大,所以相邻出现位置之间也产生较大的间距。本文就使用关键词的这种分布特征,提取关键词识别的间距特征项,具体计算公式如下:
(2)
式中:di表示词语在文本中相邻出现位置之间的间距,若词语在文中出现位置分别t1,t2,…,ti,ti+1,则相邻位置之间的间距就为d1=t2-t1,d2=t3-t2,…,di=ti+1-ti;i表示间距个数;u表示i个间距总和的平均值。
(3)
(4)
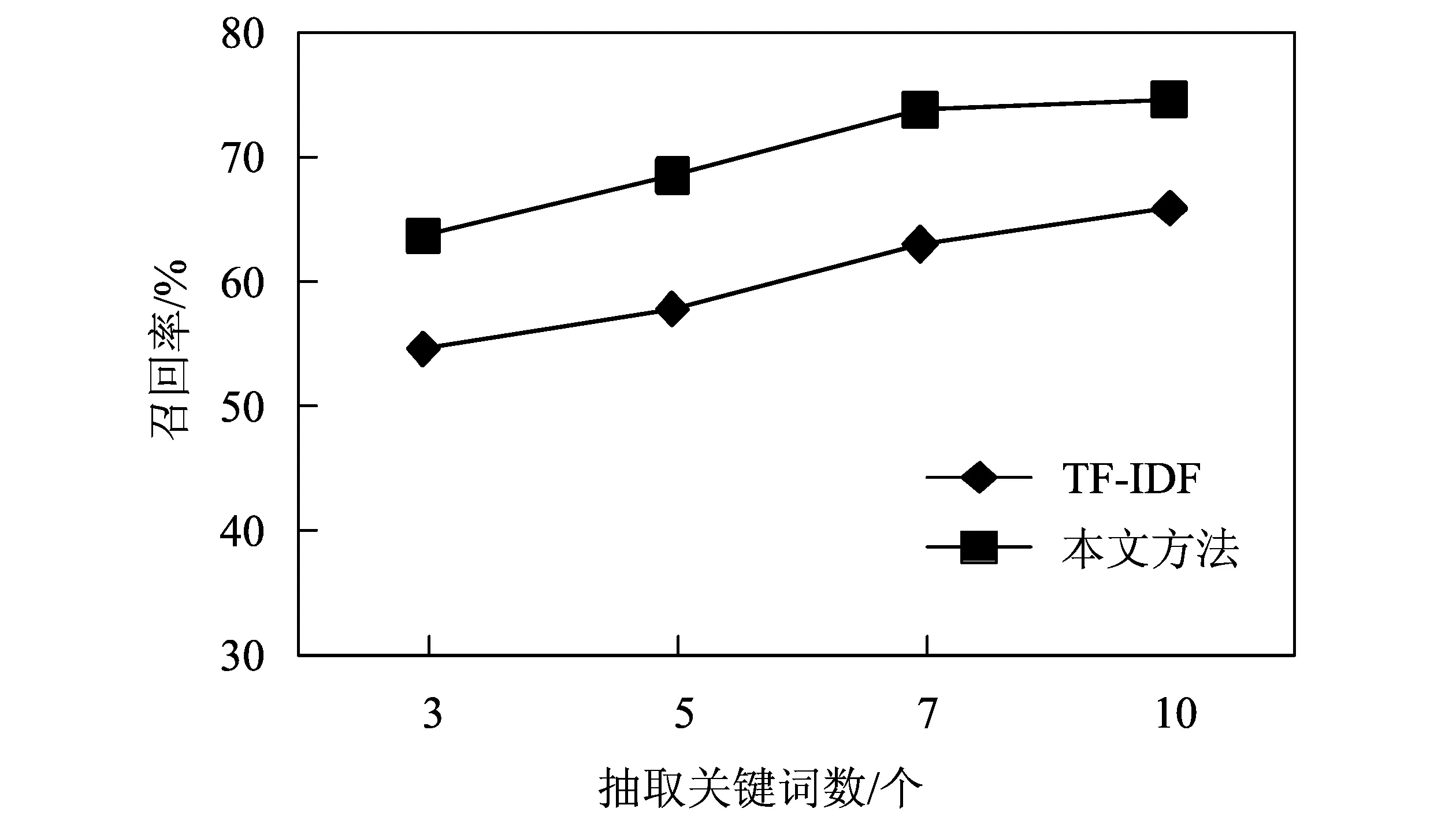
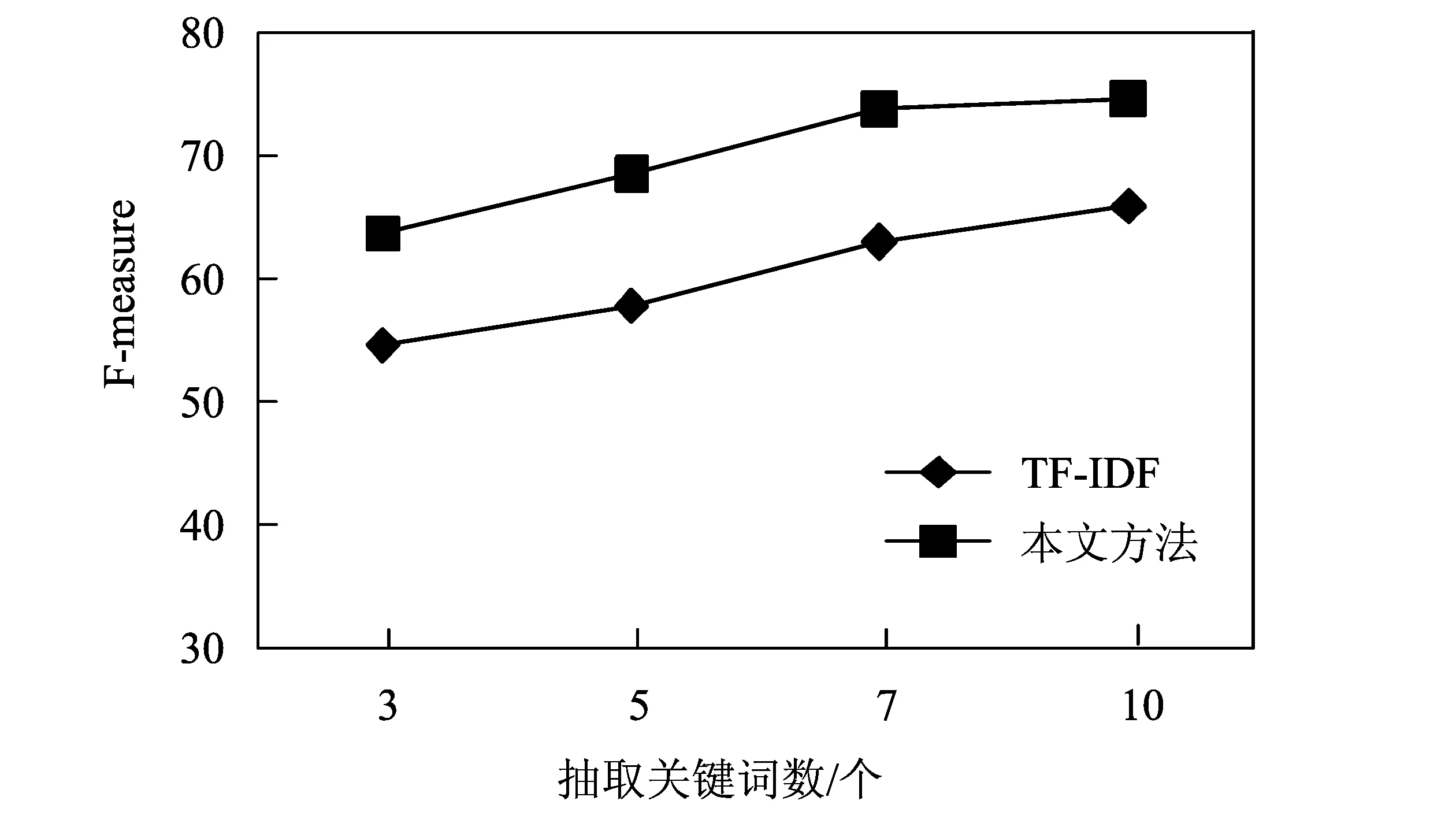
将小于平均值的间距(di (5) (6) 将大于平均值的间距(di≥u)划分到外间距当中,并计算所有属于外间距的间距和db,然后计算出外间距和的平均值m(db)。 (7) 在实际文本中,如果产生的内间距越小,说明这个词在话题中出现频繁,对这个话题的表述就越重要,关键度会越高;而如果产生的外间距越大,说明词在的话题在文本中出现范围很广,与全文的主题思想关联度越高,那么这个词作为全文关键词的可能性也就越大。 用式(7)中外间距与内间距平均值的比值大小的计算结果作为内外间距特征项,即它们的比值越大,内外间距的平均值相差越大,我们就认为该词语的关键度也就越高。 1.2.3词性 词性是根据词的特点来进行划分的,也是一种浅层语言学的表示。杨颖等[7]就在实验中对关键词的词性分布进行了统计分析,结果很直观地看出名词和动名词在关键词总数中所占比例较大,而形容词、副词等其他词性所占比例较小,同时在很多其他研究者的实验中,也证实了这一特征的有效性,由此我们将词性作为关键词抽取的一个特征项。本文采用文献[12]中的方法,对不同词性赋予不同的权重。具体计算如式(8)所示。 (8) 1.2.4重要度 一个词语如果要作为整个文本的关键词,必然会在文中多个段落中出现,因此,词语在文中出现的段落数,往往也能体现该词对文章的重要程度[12]。另一方面,我们将词频作为特征项进行统计的同时,仅在一个段落或话题中出现多次的局部关键词,很可能会因为其高频优势被误判为整个文本的关键词,从而影响我们关键词抽取的准确率,而该特征项在一定程度上可以改善这一不足。因此,我们将词在全文中的重要度作为另一个选取关键词的特征,具体计算如式(9)所示。 (9) 式中:s表示关键词在文中出现的段落数;r表示整个文档的段落数。词语在文中出现的段落数越多,与全文段落数的比值越大,我们就认为该词的重要度也就越大。 1.3关键词权重计算 提取出词语的4个特征项后,再通过公式将提取的各个特征结合到一起,计算出词语的权重wi,并根据每个词的权重大小对词语进行排序,最后选取出前n个词语作为所要抽取的关键词。具体计算见式(10)。 (10) 式中:ti表示提取的词频特征;li表示提取的间距特征;pi表示提取的词性特征;ki表示提取的重要度特征。 2实验设置与结果 2.1实验平台 所有实验均在操作系统为windows 7的计算机上进行。分词系统采用中国科学院计算技术研究所研制的汉语词法分析系统ICTCLAS (Institute of computing Technology,Chinese Lexical Analysis system),实验过程通过java语言编程实现。 2.2实验数据 本实验所使用的数据为ACE2005语料库,其中包含CBS(哥伦比亚广播电台),CNR(中央人民广播电台),CTV(中国电视公司),XIN(新华社)等国内外10个频道的新闻报道。去除其中一些字数较少的文本后,最终选取出600篇新闻文本,作为实验用的数据集。 2.3评价标准 由于在关键词抽取领域,没有统一的实验数据和评价标准,所以本文采用常用的准确率(Precision)、召回率(Recall)和F-measure值来衡量关键词抽取效果。 1) 准确率(Precision)。实验中提取正确的关键词数与实际提取出的关键词总数的比值,它衡量的是抽取的准确程度。表达式如式(11)所示, (11) 2) 召回率(Recall)。实验中提取的正确的关键词与人工标注的关键词总数的比值,它衡量的是算法的查全率和实验的完备性。表达式如式(12)所示, (12) 准确率和召回率分别反映了实验性能的两个不同方面,而F-measure评价指标,是它们两个的综合,计算公式如式(13)所示, (13) 2.4实验结果 为了验证本文所提出方法的有效性,进行了与近年来使用最多并且效果较好的TF-IDF算法的实验比较,并且分别抽取不同的关键词数,来进一步验证本方法的抽取效果。实验结果如图1—图3所示。 图1 准确率实验结果对比Fig.1 The precision comparison of experimental results 图2 召回率实验结果对比Fig.2 The recall comparison of experimental results 图3 F-measure实验结果对比Fig.3 The F-measure comparison of experimental results 从实验结果中可以得出,本文所提出的方法总体的准确率、召回率和F-measure值都有所提高,整体性能都高于TF-IDF方法,说明本文所提出的方法是很有效的。同时也可以看出,随着抽取关键词数的增加,准确率提高幅度变慢,当抽取关键词个数为7时,准确率最高,到10时开始下降,这是因为文本中的词数有限,而抽取的关键词数越多,越容易产生权重相近或相同的词语,从而影响最终的抽取效果。 3结论 在对关键词出现位置进一步分析的基础上,提取出了新的间距特征,相比于以往的位置特征更加适用于现在网络文本灵活多变的写作结构。同时融合词频、词性和词语重要度等特征,根据最终计算出的权重大小来选取出文本的关键词。最后通过和传统方法的实验结果对比,可以看出本文提出的方法各方面性能都有所提高,说明了本方法的有效性。 由于时间和实验条件有限,本方法也存在很多不足,比如本文中实验所用语料数量不够多,文本类型不够全面;在提取间距特征时,还可以选取更符合关键词实际分布情况的计算方法;最终计算关键词权重时,还可以根据特征不同的影响力,给它们设定不同的参数,进一步提高准确率等。此外,在中文关键词抽取领域没有统一现成的数据标准,经常都需要人们进行人工标注,也会带来一些主观因素的影响。这些都是我们在今后的工作中要继续研究和改进的问题。 参考文献: [1]LUHN H P.A statistical approach to mechanized encoding and searching of literary information[J].IBM Journal of Research & Development,1957,1(4):309-317. [2]WU H C,LUK R W P,WONG K F,et al.Interpreting TF-IDF term weights as making relevance decisions[J]. ACM Transactions on Information Systems,2008,26(3):55-59. [3]WARTENA C,BRUSSEE R,SLAKHORST W.Keyword extraction using word co-occurrence[C]∥IEEE.2010 Workshops on Database and Expert Systems Applications.Piscataway:IEEE Computer Society,2010:54-58. [4]JIAO H,LIU Q,JIA H.Chinese keyword extraction based on N-Gram and word Co-occurrence[C]∥IEEE.International Conference on Computational Intelligence and Security Workshops.Washington DC:IEEE,2007:152-155. [5]赵鹏,蔡庆生,王清毅,等.一种基于复杂网络特征的中文文档关键词抽取算法[J].模式识别与人工智能,2007,20(6):827-831. [6]FRANK E,PAYNTER G W,WITTEN I H,et al.Domain-specific keyphrase extraction[C]∥IEEE Computer Society.Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence.San Francisco:Morgan Kaufmann Publishers Inc.,1999:668-673. [7]胡学钢,李星华,谢飞,等.基于词汇链的中文新闻网页关键词抽取方法[J].模式识别与人工智能,2010,23(1):45-51. [8]杨颖,戴彬.基于多特征的中文关键词抽取方法[J].计算机应用与软件,2014,31(11):109-112. [9]谢晋.基于词跨度的中文文本关键词自动提取方法[J].现代物业:中旬刊,2012,11(4):108-111. [10]张瑾.基于改进TF-IDF 算法的情报关键词提取方法[J].情报杂志,2014,33(4):153-155. [11]YANG Z, LEI J J,FAN K F,et al.Keyword extraction by entropy difference between the intrinsic and extrinsic mode[J].Physica A:Statistical Mechanics and its Applications,2013(923):4523-4531. [12]黄轩,李伟.基于多特征的中文关键词抽取方法[J].计算机与现代化,2013(4):15-17. (编辑:朱倩) Research on the Strategy of Keyword Extraction HU Qi,HAO Xiaoyan,ZHANG Xingzhong,CHEN Yaowen (DepartmentofComputerScienceandTechnology,TaiyuanUniversityofTechnology,Taiyuan030024,China) Abstract:In the statistical method of keyword extraction, statistical aspects are insufficient,and general location features have limitations to the writing structure of the text. To resolve these problems, a new keyword extraction method is proposed,which,according to the location of the key words in the text,extracts the new features of word spacing,and is more suitable for the network text at random and changeable writing style. In addition, the method considers all factors affecting key word recognition,improves the shortcomings of traditional statistical methods by extracting word frequency, word spacing, part of speech and importance of words. Finally, in comparison with the traditional TF-IDF method,the proposed method is improved in all aspects, which shows that the method is effective and feasible. Key words:extraction;word frequency;word spacing;part of speech;importance of words 文章编号:1007-9432(2016)02-0228-05 *收稿日期:2015-05-27 基金项目:山西省自然科学基金资助项目:基于框架语义标注的中文篇章指代消解策略研究(2012011011-2) 作者简介:胡琪(1990-)女,山西定襄人,硕士生,主要从事计算语言学,自然语言处理方向的研究,(E-mail)314176086@qq.com通讯作者:郝晓燕,副教授,主要从事计算语言学、自然语言处理方向的研究,(E-mail) haoxiaoyan@tyut.edu.cn 中图分类号:TP391 文献标识码:A DOI:10.16355/j.cnki.issn1007-9432tyut.2016.02.020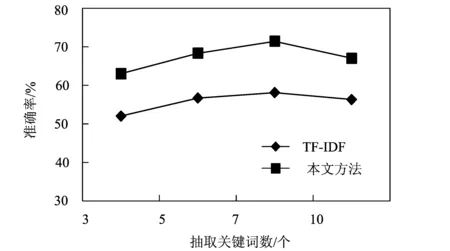
猜你喜欢
读者(2022年13期)2022-06-20
内江科技(2021年8期)2021-09-13
中国交通信息化(2019年4期)2019-07-13
亚太教育(2018年5期)2018-12-01
长江丛刊(2017年27期)2017-12-01
中国修辞(2017年0期)2017-01-31
小学生导刊(低年级)(2016年5期)2016-05-27
海军航空大学学报(2015年3期)2015-11-11
中国煤层气(2015年6期)2015-08-22
读者·校园版(2015年7期)2015-05-14
