
基于OPAQ的城市空气质量预报系统研究
2016-06-09 08:53:57王淑莹尹翠芳BinoMaiheuStijnJanssenLisaBlyth
中国环境监测 2016年3期
王淑莹, 许 荣, 尹翠芳, Bino Maiheu, Stijn Janssen, Lisa Blyth
1.北京立博威拓环境技术有限公司, 北京 100083 2.中国环境监测总站, 国家环境保护环境监测质量控制重点实验室, 北京 100012 3.比利时法兰德斯技术研究院, 摩尔 BE-2400
基于OPAQ的城市空气质量预报系统研究
王淑莹1, 许 荣2, 尹翠芳1, Bino Maiheu3, Stijn Janssen3, Lisa Blyth3
1.北京立博威拓环境技术有限公司, 北京 100083 2.中国环境监测总站, 国家环境保护环境监测质量控制重点实验室, 北京 100012 3.比利时法兰德斯技术研究院, 摩尔 BE-2400
空气质量预测在国内的关注度日益提高,传统的空气质量预测系统通常运用数值化学传输模型,利用物理方程来计算污染物的扩散、沉降和化学反应。而化学传输模型的预测准确性很大程度上需要依赖详细的污染源排放信息和气象模型的输出结果。基于统计模型的OPAQ空气质量预报业务系统,采用人工神经网络算法,可预测各污染物的日均值或日最大值。并对北京空气质量预报的结果进行了评价,OPAQ空气质量预报业务系统对空气质量预测的准确性较高,能够利用较低的计算资源得到较为准确的预测结果。与数值预报相比,OPAQ空气质量预报业务系统不需要大量的基础数据作为输入,可弥补数值预报的不足,并成为数值预报的有力补充。
空气质量预报;统计模型;OPAQ
空气质量与人类健康之间的关系已经引起了广泛关注,有不少学者对此做了大量研究[1]。因此,空气质量预报在污染事件发生前对公众的预警和制定减灾计划方面尤为重要。例如,在比利时,如果PM10的日均浓度值连续2 d超过70 μg/m3,就会实行高速路限速的措施,且这种措施行之有效[2];或者,在高污染事件发生的城市实行车辆单双号限行措施。
当前常用的空气质量预报方法主要有:数值预报、统计预报2种方法。数值预报方法可以模拟从全球到街区等多种尺度。另外,数值预报需要大量的基础数据作为输入,除气象预报数据外,还需要较为准确的污染源排放数据、详细的地理环境数据、边界条件数据等,并且需要做大量的计算机数值计算,需要投入较高的人力、物力和技术装备。同时,由于污染源的污染物排放动态变化较大,难以获得精确的污染源数据,因此数值预报目前的预报效果往往难以达到理想的效果。而统计预报方法则避免了上述数值预报方法的弊端,该方法只需气象数据、污染物监测浓度数据即可进行预报。但传统的统计预报方法只是针对单个站点进行模拟,不能实现整个区域的预报。本研究中,在统计模型的基础上集成了插值模型,可以进行整个模拟区域的预报。并在应用统计模型过程中,对污染物浓度监测值与不同气象参数之间的相关性进行了对比。另外,还探讨了本研究中所用的空气质量预报系统与数值预报系统在应用中的互补性。
另一方面,模型评价对模型预测性能也有重要意义。例如,目前,在欧洲空气质量模型论坛上,有一批专业技术人员在协调制定预测模型的评价标准[3]。尤其是在不同的欧洲成员国分别使用多种不同的空气质量预测模型的背景下,制定统一的标准非常重要。本研究中也制定了相应的评价方法对模型的预测结果进行了评价。
1 OPAQ空气质量预报业务系统
法兰德斯技术研究院(VITO)与比利时环保署合作,并由其资助开发了两款统计模型用以替代化学传输模型,分别是OVL模型,利用人工神经网络算法预测站点污染物浓度[4];RIO模型,利用地理统计插值技术来绘制污染物浓度分布图[5]。两款模型将长期作为比利时官方空气质量预报业务系统中的一部分,并已在插值绘图和高污染事件预测方面表现出比化学传输模型更为优越的性能[6]。在欧盟环境治理项目中的AirINFORM项目资助下,将OVL模型与RIO模型结合使用,称之为OPAQ空气质量预报业务系统(以下简称“OPAQ”)。
1.1 OPAQ所采用的预测模型介绍
OPAQ中的OVL模型采用人工神经网络算法中的多层感知方法,其中一个隐含层代表一个输出层。预测的结果是污染物的日均值或日最大值。假如模型在当天早上运行,则当天00:00 至模型开始运行最近时刻的监测数据以及未来几天的气象数据作为OVL的输入数据。对每个监测站点配置几个不同的模型进行训练,不同模型的区别在于所采用的输入参数不同。所预测当天早上的监测数据及行星边界层高度(BLH)作为预测未来第N天的重要输入参数。行星边界层高度可认为是理查德系数(Ri)超过0.5时的高度[7]。其中Ri是浮力(由垂直温廓线确定)与惯性力(由大气湍流确定)的比率。如果Ri非常小(甚至是负的),湍流非常强烈,并且足以打破稳定的温廓线将颗粒物带至垂直方向,则从底部到行星边界层高度之间,颗粒物可以随湍流在此之间扩散。研究表明行星边界层高度在基于人工神经网络算法的空气质量预报系统中有非常重要的作用[8]。另外,还使用了风速与风向、温度、湿度及云量等气象参数提高预测的准确性[9-11]。对每个监测站点都配置几种模型进行训练,最后选择一个最优的模型作为日常预报模型。
空气质量监测值通常符合的正态分布,高浓度值对应的数据量明显小于其他浓度值所对应的数据量。这表明,高浓度事件发生概率较小。尽管如此,依然期望对高浓度事件进行准确预测。对此,研究中将人工神经网络算法的训练样品进行重采样,使其呈均匀分布,这样可以给高浓度事件赋予和其他浓度相同的权重值,从而提高高浓度事件预测的准确性。
相对于原始的神经网络输出而言,OPAQ具有动态偏差修正功能。将日常预测值及实际监测值存储在临时数据库中,通过该数据库,可以将过去的预测误差统计出来,再通过不同的方法,如计算过去预测误差的均值或加权平均,计算得到当天的预测误差。然后将预测误差应用到原始的模型输出结果上,这就是所谓的实时修正。同时,对于每个站点、每个预测时间采用何种修正方法都需要进行优化。
1.2 OPAQ预测模型与数值模型的互补性
OPAQ的机器自学习和统计特性可认为是复杂的数值模型预报系统的补充。这2种方法都有各自的优点,但也也都存在一些不足。有学者曾经做过统计模型和数值模型的比较[12],数值化学传输模型通过扩散和化学反应方程很好地描述了污染物的物理化学过程,并且充分利用了三维气象模型的输出结果。因此,也可以模拟污染物的长距离传输,而这对于污染事件起因的研究是非常重要的。由于化学传输模型需要使用污染物排放数据,且输出结果会随着排放数据的变化而发生相应的变化。因此,化学传输模型可以用于情景分析。然而,如果没有准确的排放数据将会影响空气质量预报的准确性。很多化学传输模型进行评价、预测时都需要进行校正或数据同化,对比空气质量模拟结果和实际监测值来提高模型的性能。此外,化学传输模型对计算机的计算能力也有较高要求,尤其是在设置较高空间分辨率的情况下。因此,通常运行化学传输模型需要较昂贵的硬件设备。另外,要运行基于数值模型的空气质量预报系统以及解释其输出结果也需要在大气科学方面有较深背景的专业人员。
与之相反,OPAQ在安装和部署方面相对简单易学。首先,与数值模型预报系统相比对硬件和人员的要求相对较低。其次,它只需要空气质量监测数据,无需污染物的排放数据。OPAQ或其他统计预报方法同样也有一些不足之处,例如,统计模型不能很好地模拟过去没有发生过的情景,统计方法的特性也决定了其不能很好地解释污染的过程。尽管如此,当训练神经网络模型时,为避免过度拟合化,须将统计模型的性能进行一般化处理。相对于复杂的化学传输模型预报方法,统计预报方法的预测准确性与其相当,甚至要优于前者,对于高污染事件的预测性能也是如此[12-13]。
当空气质量预测用于预警或是否采取消减措施(比如机动车限速或其他措施)时,就需要评价预测模型是否能够预测超标值。为了量化模型的预测性能,使用了预测成功指数(SI)这个指标。SI基于散布图来计算,见图1。

图1 预测值与监测值的散布图
图1中横坐标为监测值,纵坐标为预测值,单位均为μg/m3,100 μg/m3为超标临界值。利用预测到的超标天数总量与预测到的未超标天数总量分别与总的超标天数及总的未超标天数的比值相加再减去1得到,其中减1是为使指数在-1~1。详见式(1):
(1)
式中:SI为预测成功指数,N3为预测到的超标天数,N4为未预测到的超标天数,N1为预测到的达标天数,N2为未预测到的达标天数。
图2展示了统计与数值两种模型的预测性能对比,以PM10为例,比较了两种模型的预测值与监测值的相关性系数(r)及SI两种预测性能。图中浅灰色方块和灰色三角形分别代表OPAQ中OVL的不同模型的预测结果,深灰色菱形代表化学传输模型CHIMERE的预测结果。参与评价的数据为比利时2008年11月—2009年4月3种模型运行的预测数据[6]。结果表明,统计模型在预测高污染事件的发生方面具有较高的潜力。

图2 统计模型与数值化学传输模型就PM10日均值的预测性能对比
2 OPAQ应用于北京空气质量预报的评价
2.1 模型配置
为北京建立的OPAQ空气质量模型,采用中国环境监测总站发布的北京万寿西宫、定陵、东四、天坛、农展馆、官园、海淀区万柳、顺义新城、怀柔镇、昌平镇、奥体中心及古城12个国控点的小时监测数据,美国国家环境预报中心(NCEP)下载的再分析气象数据(FNL)进行人工神经网络算法训练。FNL数据基于全球预报系统(GFS),与GFS数据相比,FNL数据中使用了更多的实际观测数据。因此,对于统计模型来说,所使用的GFS数据和FNL数据具有一致性,使用FNL数据作为历史数据进行训练,GFS数据作为实时预测数据进行预报,所采用的气象参数有2 m高处空气温度,2 m高处相对湿度,10 m高处纬向和经向风速,BLH(行星边界层高度),1 000 hPa处分别与 975、 950、925、900、850 hPa处的温度差。然而,FNL和GFS数据的空间精度较低,可以使用当地气象模型数据进行改善(见4结语部分)。
首先,对PM2.5、PM10、NO2的日均浓度值和O3的8 h滑动平均最大浓度值与气象数据进行了相关性分析。相关性分析使用污染物浓度的对数值,有些气象数据也使用其对数值,如BLH,见图3。
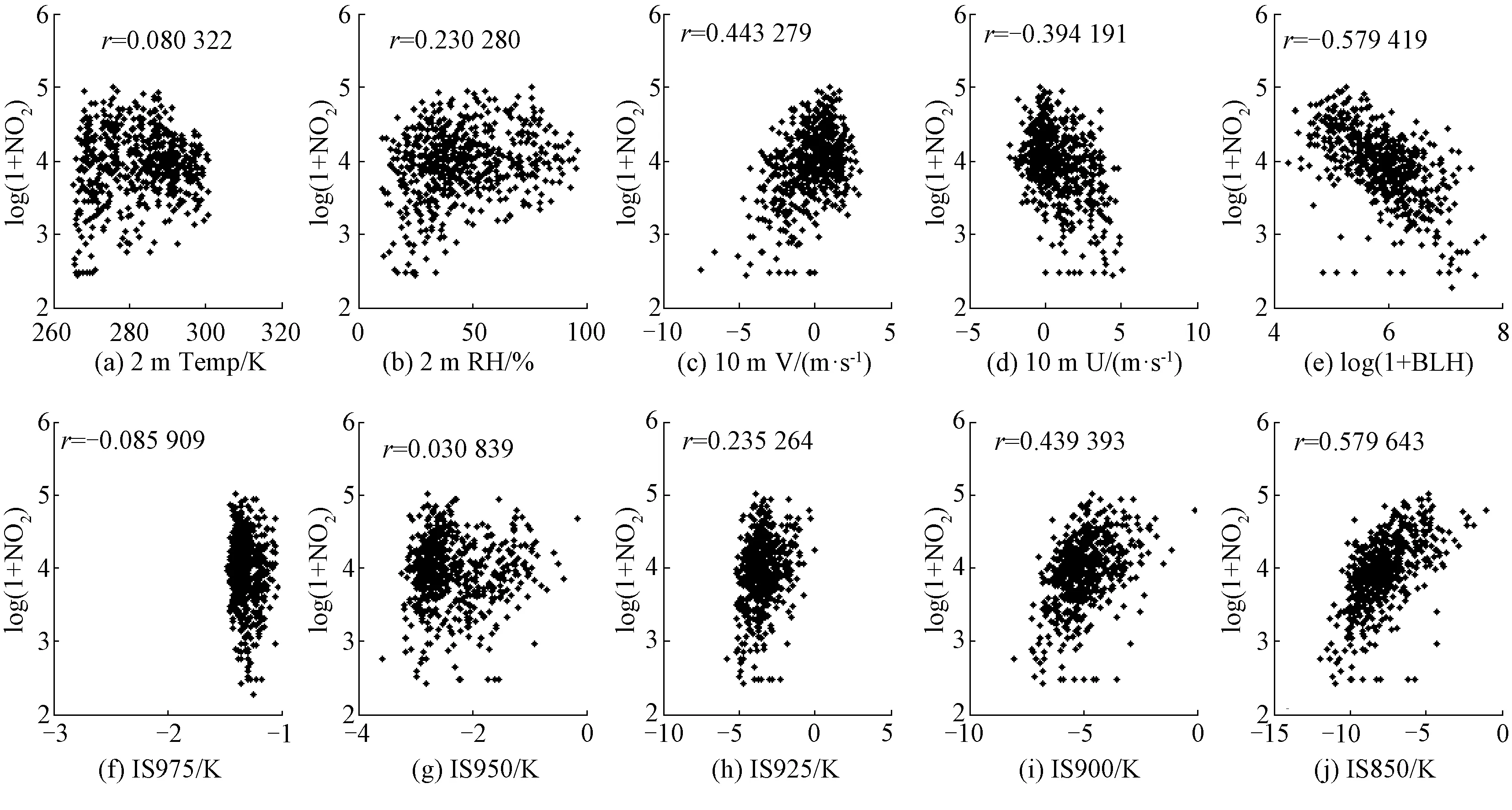
图3 北京东四站点NO2监测值与各气象参数相关性分析
图3中,从上到下,从左至右,分别为NO2日均浓度值的对数值log(1 + NO2)分别与各个气象参数的相关性系数,这些气象参数分别为2 m高处空气温度(2 m Temp),2 m高处相对湿度(2 m RH),10 m高处纬向(10 m V)和经向风速(10 m U),行星边界层高度(BLH),1 000 hPa处分别与 975、950、925、900、850 hPa处的温度差(分别用IS975、IS950、IS925、IS900、IS850表示)。另外,图中还标出了相关性系数值。研究在之前HOOYBERGHS J等[4]所采用参数的基础上,OPAQ所用的OVL模型还增加了反映大气稳定性的垂直温度信息,分别为975~850 hPa高处分别与1 000 hPa高处的温度差,提高了模型性能。
HOOYBERGHS J等研究发现,NO2、PM10、PM2.5与BLH呈显著负相关,O3与BLH呈正相关,这与NO2、NO和O3之间的光化学平衡有关。北京东四站点O3与气象参数的相关性分析结果(图4)与HOOYBERGHS J等的研究结论一致,尤其是O3与2 m处温度日均值相关性显著。
O3浓度在多数站点与1 000 hPa和850、900 hPa处温差相关性显著,而与近地面处的温差相关性较小。目前,对于O3浓度与较高处的温差相关性更显著的原因还不清楚。
另外,分析表明(图3),当风向为北风时,污染物的浓度明显低于风向为南风时(经向风速分别为负和正时)。同样,当风向为西风时污染物浓度较低,而风向为东风时污染物浓度较高。这可能与城市北部、西部多山区和郊区分布有关。
表1列举了各站点污染物监测值与气象参数的相关性系数的均值。气象参数从左至右依次为2 m高处空气温度,2 m高处相对湿度,10 m高处纬向和经向风速,BLH,1 000 hPa处温度分别与 975、950、925、900、850 hPa处温度差。
为每项污染物配置5组模型,计算模拟预测值和监测值的均方根误差(RMSE),然后为每个站点每个预测天(预测当天至未来第5 d)选取最优模型和实时修正方法。相较HOOYBERGHS J等的研究,配置的模型加入了风速、星期属性(是否工作日)、温度、湿度参数后,OPAQ预测结果得到了明显改善。新增的850 hPa高度逆温强度提高了预报结果的准确性,但加入其他高度处逆温强度对模型改善效果不显著。
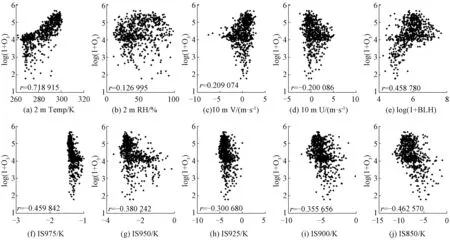
图4 北京东四站点O3监测值与各气象参数相关性分析
表1 北京各站点PM2.5、PM10、NO2浓度日均值和O38 h滑动平均浓度日最大值分别与气象参数日均值相关性系数的平均值

污染物2mTemp2mRH10mV10mUBLHIS975IS950IS925IS900IS850PM100.150.190.42-0.33-0.24-0.21-0.16-0.010.150.32PM2.50.100.380.47-0.44-0.41-0.22-0.17-0.040.160.40NO2-0.060.110.37-0.28-0.480.030.100.230.370.46O30.670.060.18-0.150.46-0.39-0.31-0.26-0.33-0.45
2.2 模型评价
使用2015年以前所有可获得的历史数据对OPAQ预测模型进行训练,并用2015年1月1日—4月30日的数据进行检验。以下重点讨论O3和 PM2.5的预报情况。图5、图6分别为北京东四站点PM2.5和O3的预报与监测值对比时间序列图。图5中监测值表示PM2.5监测日均值,预测值表示OPAQ原始预报值,修正值表示采用实时修正方法的值。图中用黑色虚直线标出超标值(75 μg/m3)。

图5 北京东四站点PM2.5的预报与监测值对比时间序列图

图6 北京东四站点O3的预报与监测值对比时间序列图
图6中监测值表示O3的8 h滑动平均监测浓度最大值,预测值表示OPAQ原始预报值,修正值表示实时修正值。图中用黑色虚直线标出超标值(160 μg/m3)。从上至下分别为当天至未来第5 d的时间序列图。
由图5、图6可见,OPAQ预测模型很好地预测了O3和 PM2.5的浓度。且当监测值和原始预报值差距较大时,采用实时修正方法得到的结果更好。
图7为模拟预测值与实际监测值的相关性系数统计箱型图,横坐标为预报未来天数(用当天至第5 d表示)。预报的每个天数均作了原始预报结果(左侧箱图)和实时修正后结果(右侧箱图)的对比。
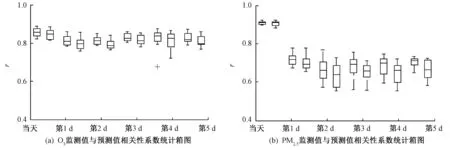
图7 模拟预测值与实际监测值的相关系数统计箱型图

图8 PM2.5其他检验指标的统计箱型图
由图7可见,O3每个预报天的模拟预报结果与实际监测值的相关性系数都约为0.8,说明气象预报结果较好。而对于PM2.5,未来第1 d的相关系数突然下降,约0.6~0.7,未来第2 d以后相关性系数相当。实时修正结果相关性(右侧箱图)和原始人工神经网络算法结果相关性(左侧箱图)略有不同,可能是因为实时修正进行了偏移修正。RMSE的结果也类似,如图8中a图所示,实时修正结果明显低于原始预报结果。
图8还展示了超标天预报的结果统计,设定超标浓度为75 μg/m3。PM2.5的未来第1 d预测成功指数约55~60,实时修正结果(右侧箱图)有明显提高。正确预警指数(FCF)为预报出正确的超标天数除以总超标天数,错误预警指数(FFA)为预报错误的超标天数(实际不超标)除以总超标天数。
由图8可见,FFA约为10%~20%,实时修正结果稍差一些。而FCF统计中,实时修正结果有明显提高,约70%~80%。
3 OPAQ空气质量预报业务系统在国内的应用案例
针对OPAQ在其他几个城市的应用情况,对其预测准确率做了相应的统计,如表2所示。表中的预测准确率是根据中国环境监测总站编写的《环境空气质量预报预警方法技术指南》第二章第六节中关于级别准确分的描述所做的统计,统计了完全准确天数与级别准确天数占所有预报天数的比例,其中完全准确是指预报值±10个点(或±10%)与实况相符;表中的级别准确是指预报不跨级且级别与实况相符。

表2 OPAQ在国内应用案例的预测级别准确率汇总
注:“—”表示无数据。
4 结语
1)通过OPAQ统计预报系统与数值预报系统的对比,探讨了与数值预报系统的互补性。结果表明,OPAQ统计预报系统与数值预报各有优劣,在应用中可以互为补充。
2)用相关性系数及预测成功指数两种指标对统计和数值模型进行预测结果的评价。结果表明,统计模型在预测高污染事件的发生方面具有较高的潜力。
3)与北京监测站预报结果的初步比对表明,OPAQ对空气质量预测的准确性较高。O3每个预报天的模拟预报结果与实际监测值的相关性系数都约为0.8,而对于PM2.5,未来第1 d至第5 d的相关系数在0.6~0.7,而且实时修正后的结果在监测值和原始预报值有差距时更好。
4)OPAQ对污染等级的预测准确性较高,预测未来24 h的级别准确率在56.1%~70%。但是,还有待与数值模型进行预测性能的对比。
5)基于人工神经网络算法的统计预报系统能够利用较低的计算资源来较为准确地预测空气质量。另外,如果使用能够很好地反映当地天气状况的气象模型参数,可以对OPAQ做进一步的改进,并提高其预测准确率。
[1] World Health Organization.Review of evidence on health aspects of air pollution-REVIHAAP Project 309[R].2013.
[2] LEFEBVRE W,FIERENS F,TRIMPENEERS E,et al.Modeling the effects of a speed limit reduction on traffic-related elemental carbon (EC) concentrations and population exposure to EC[J].Atmospheric Environment,2011,45:197-207.
[3] THUNIS P,PEDERZOLI A,PERNIGOTTI D.Perfor-mance criteria to evaluate air quality modeling applic-ations[J].Atmospheric Environment,2012,59:476-482.
[4] HOOYBERGHS J,MENSINK C,DUMONT G,et al.A neural network forecast for daily average PM concentrations in Belgium[J].Atmospheric Environment,2005,39:3 279-3 289.
[5] JANSSEN S,DUMONT G,FIERENS F,et al.Spatial interpolation of air pollution measurements using CORINE land cover data[J].Atmospheric Environment,2008,42:4 884-4 903.
[6] JANSSEN S,DUMONT G,FIERENS F,et al.Land use to characterize spatial representativeness of air quality monitoring stations and its relevance for model validation[J].Atmospheric Environment,2012,59:492-500.
[7] VOGELEZANG D H P,HOLTSLAG A A M.Evaluation and model impacts of alternative boundary-layer height formulations[J].Boundary-Layer Meteorology,1996,81:245-269.
[8] DUTOT A L,RYNKIEWICZ J,STEINER F E,et al.A 24-h forecast of ozone peaks and exceedance levels using neural classifiers and weather predictions[J].Environmental Modelling and Software,2007,22:1 261-1 269.
[9] 程念亮,李云婷,邱启鸿,等.2013年北京市PM2.5重污染日时空分布特征研究[J].中国环境监测,2015,31(3):38-42.
[10] 陈强,梅琨,朱慧敏,等.郑州市PM2.5浓度时空分布特征及预测模型研究[J].中国环境监测,2015,31(3):105-112.
[11] 沈路路,王聿绚,段雷.神经网络模型在O3浓度预测中的应用[J].环境科学,2011,32(8):2 231-2 235.
[12] ZHANG Y,BOCQUET M,MALLET V,et al.Real-time air quality forecasting,part I:History,techniques,and current status[J].Atmospheric Environment,2012,60:632-655.
[13] 张静,李旭祥,许先意,等.大气环境数据分析预测方法对比研究[J].中国环境监测,2010,26(6):66-69.
Study on Urban Air Quality Forecasting with OPAQ
WANG Shuying1,XU Rong2,YIN Cuifang1,BINO Maiheu3,STIJN Janssen3,LISA Blyth3
1.Beijing LIBOVITO Environmental Technology Company, Beijing 100083, China 2.State Enrironmental Protection Key Laboratory of Quality Control in Environmental Monitoring, China National Environmental Monitoring Centre, Beijing 100012, China 3.Flemish Institute for Technological Research, Mol BE-2400, Belgium
Air quality forecast has been and continues to be a growing concern in China. Traditional air quality forecasting systems employ deterministic chemical transport models in which pollutant dispersion, deposition and chemical reactions are computed from the governing physical equations. Detailed pollutant emission information and meteorological model output areneeded to run the chemical transport models. An alternative statistical forecasting system OPAQ is discussed that is based on the BP neural network algorithm. The results of the OPAQ forecast system for a nuhPaer of monitoring stations in Beijing show that forecast accuracy of OPAQ is high and it can take advantage of lower computing resources to predict air quality. Compared with deterministic chemical transport model, it doesn’t need multiple input data and can be a complementary approach of traditional method.
air quality forecasting;statistical model;OPAQ
2015-09-08;
2015-12-31
环保公益性行业专项“京津冀地区大气重污染过程应急方案研究”(201309071)、“京津冀城市大气边界层过程对重污染形成的影响研究”(201409001-03);科技部科技支撑计划环境领域项目“大气复合污染区域联合预测预报关键技术研究”(2014BAC22B04)、“京津冀空气监测预报及防控技术研究与示范”(2014BAC06B04)、中科院先导项目“大气灰霾追因与控制专项数值模式与协同控制方案课题”(XDB05030200)
王淑莹(1982-),女,山西霍州人,硕士,工程师。
许 荣
X830.3
A
1002-6002(2016)03- 0013- 08
10.19316/j.issn.1002-6002.2016.03.02
猜你喜欢
小学生学习指导(低年级)(2023年4期)2023-05-09 11:52:52
今日农业(2021年11期)2021-11-27 10:47:17
中学生数理化·高一版(2021年11期)2021-09-05 14:27:13
环境科学研究(2021年6期)2021-06-23 02:39:54
环境科学研究(2021年4期)2021-04-25 02:42:02
少儿科学周刊·儿童版(2021年23期)2021-03-24 01:00:31
环境保护与循环经济(2017年3期)2017-03-03 20:08:30
汽车与安全(2016年5期)2016-12-01 05:22:14
汽车与安全(2016年5期)2016-12-01 05:22:13
中国环境监察(2016年11期)2016-10-24 05:25:12
