
一种改进的关联规则并行算法*
2016-06-03 09:10:14汪峰坤张婷婷
重庆工商大学学报(自然科学版) 2016年3期
汪峰坤, 张婷婷
(安徽机电职业技术学院 信息工程系,安徽 芜湖 241000)
一种改进的关联规则并行算法*
汪峰坤, 张婷婷
(安徽机电职业技术学院 信息工程系,安徽 芜湖 241000)
摘要:经典的关联规则求解算法(如Apriori算法)是串行算法,当数据量比较大时挖掘效率较低;提出了新的并行BVP算法,BVP算法通过多线程并行读取数据并计算相应的数据特征,然后计算频繁项集和关联规则;实验结果表明:相对于经典Apriori算法,算法执行效率更高。
关键词:数据挖掘;关联规则;并行;频繁项集
作为一种通用的数据挖掘技术,关联规则挖掘已经应用于许多的决策分析系统中。通过对已有数据的关联分析,挖掘出数据集之间有趣的潜在的联系。关联规则挖掘包括两个主要步骤:生成频繁项集和生成关联规则模式[1-2]。其中,生成频繁项集更复杂,消耗更多的时间。
近年来,随着数据量成指数级的增长,针对大数据的关联规则挖掘速度和效率成为数据挖掘新的研究焦点。通过并行算法充分利用计算机的CPU和内存,将大数据分成多个部分进行并行挖掘,是针对大数据挖掘的有效方法。关联规则的并行挖掘算法研究,成为目前数据挖掘领域中的主流研究分支之一。
Agrawal R和Shafer J于1996年提出了Count分布算法(CD算法)[3],CD算法是最早出现的并行关联规则挖掘算法,其它大部分并行算法都是在CD算法基础上修改的。算法将数据集分布到各个单独的处理器中,每个单独的处理器计算局部支持数,生成局部频繁集。然后根据所有的局部频繁集生成全局频繁集。优点是各处理器间通信量比较低。缺点是内存利用率低。CCPD算法是基于Apriori算法的内存共享并行算法[4]。算法思路是将数据集分成若干逻辑分区,各处理器并行生成候选项集,构造共享的Hash树。算法缺点是对共享生成的Hash树进行并行修改时,会造成访问冲突,必须要将并行操作串行化,性能会下降。
提出了BVP算法,是一种基于位串的并行关联规则挖掘算法。算法通过多线程访问数据集,各子线程将读取的数据生成基于列的数据特征(整数)。然后将生成的数据特征传递给主线程,主线程根据所有的数据特征生成频繁项目集。算法具有可并行处理数据集,子线程提取数据特征的算法简单,线程之间通信量少等优点。仿真实验结果表明,对于较大数据集算法提高了运算效率。
1基本概念和理论
涉及的定义、概念和理论如下[1-8]:
定义1设事务数据库DB,由每个事务T组成。设项I={I1,I2,…,Im}。满足T⊆I。X是I的子集,如果X⊆I,则称T包含X;如果X的元素个数为k,则可以称X为k-项集(k-ItemSet)。
定义2如何荐集X在事务数据库D中出现的比例大于给定最小支持度阈值min_Sup,称X为频繁项集。频繁k项集的集合记为项集Lk。
定义3事务数据库属性值集TVS,指事务数据库中所有属性值的集合。
定义4事务项的位串表示:BS(I)=BS(i1,i2,…,in)=(b1,b2,…,bn),其中{bm=1|im∈TVS},{bm=0|im∉TVS}。
定义5位串的数据特征,即位串的值BV,表示位串的二进制串对应的十进制数。例如:BV(1001)=9。
定义6事务项长度TL,指事务项对应的位串中1的个数。
定义7定义十进制数对应的二进制数中1的个数的操作VL。例如:VL(9)=2。
定义8位串的“与(&)操作”:指两个位串进行按位与操作。
性质1频繁项集的所有非空子集都是频繁的。
性质2非频繁项集的所有超集都是非频繁项集。
性质3BVi和BVj是某两条等长事务的位串,设VL(BVi&BVj)=k,则说明两条事务中有k项的值是相同的。
证明:设BVi=(bi1,bi2,…,bim),BVj=(bj1,bj2,…,bjm)。根据定义8中“与”操作,则表达式BVi&BVj中取1的位只可能同时对应的位置都是1。显然,两位串相同属性值的个数,就是“与”操作后1的个数。
推论1BV1,BV2,…,BVm是某m条等长事务的位串,设VL(BV1&BV2&…&BVm)=k,则说明此m条事务中有k项的值是相同的。
证明:利用数学归纳法和性质3即可证。
2BVP算法
2.1算法的基本数据结构
BVP算法中有多条并行运行的子线程和一个主线程,子线程从数据集中分块读取数据,对读取的数据进行转化和统计,计算出相应的数据特征。子线程将计算的数据特征数组传递给主线程中共享的数据特征集合,由主线程计算全局的频繁项集和关联规则项。
设事务数据库DB中有N条数据,属性值共有X种,每条事务数据没有重复的属性取值,每个子线程每次处理M条数据。
子线程的数据结构主要有:事务数据位矩阵BT和数据特征数组pArray。BT是一个M×X的矩阵,每行对应一条转换为位串的事务,每列对应某属性值的出现情况。pArray数组长度与属性值个数相同为X,每个元素取值是相应下标对应的属性值的BV值,即每一列位串对应的整数值。
主线程的数据结构主要有:数据特征集合pSet和频繁项集(FrequentItemsets)。pSet是所有子线程共享的数据特征集合,集合长度为X,对应的是事务数据库中的X种属性值。集合的每个元素是一个长度为「N/M⎤(对应的线程总数)的数组,数组的取值是每个线程计算的相应的属性值的数据特征。数据结构FI用于保存各阶的频繁项集,例如FIk表示保存的是k价频繁项集。
2.2算法流程
子线程算法流程:
生成M行(每个子线程处理M条记录)X列(属性值个数)的事务数据空位矩阵BT;扫描事务数据库,每读取一条记录,根据定义4,在矩阵BT中生成一条位串,直到M条记录处理完成;根据定义4,按列生成X个属性值的位串;根据定义5,计算出X个属性值的位串的数据特征整数值,放到数组pArray中;将pArray的值传递给主线程的数据特征集合pSet,结束线程。
主线程算法流程:

(2) 如果nk/N≥min_sup,则将相应的属性值放入一阶频繁集FI1;
(3) 计算一阶频繁集FI1元素自连接,根据推论1计算每个频繁候选集自连接的支持度。如果支持度大于最小支持度min_sup,将频繁候选集存入二阶频繁集FI2;
(4) 重复第(3)步,直到当前频繁集个数为1,或者没有下一阶频繁项为止。
(5) 集合FI中的元素就是求解的关联规则。
相对于经典的并行算法,算法的优点主要有:算法中的运算主要是位操作运算,计算的速度快;子线程向主线程传递的是数据特征,数据量较少,通信代价低;算法实现简单。
3BVP算法实验与分析
3.1算法流程实验
某事务数据库DB中有6条事务数据,DB={T1,T2,T3,T4,T5,T6},属性值个数X=6。每条事务的取值如下:T1(a,b,e,f),T2(c,d,e,f),T3(a,b,c,f),T4(a,c,d,f),T5(b,c,d,e),T6(c,d,f)。假设最小支持度60%,即最小支持数为:minSupNum=60%*|DB|≈4。设使用两个子线程并行挖掘,则每个线程处理3条数据。
假设线程1处理T1,T2和T3,步骤如下:
(1) 生成3行6列(属性值个数)的事务数据空位矩阵BT。
(2) 扫描事务数据库,根据定义4,在矩阵BT中生成3条位串。如表1所示。

表1 线程1的数据位矩阵BT
(3) 根据定义4,按列生成X个属性值的位串。
BS(a)=101,BS(b)=101,BS(c)=011,BS(d)=010,BS(e)=110,BS(f)=111。
(4) 根据定义5,计算出X个属性值的位串的数据特征整数值,放到数组pArray中。计算可得:pArray={BV(101),BV(101),BV(011),BV(010),BV(110),BV(111)}={5,5,3,2,6,2}。
(5) 将pArray的值传递给主线程的数据特征集合pSet,结束线程。
同理,线程2计算的pArray的值:{4,2,7,7,2,5}。
此时,主线程中数据特征集合pSet的值:{{5,5,3,2,6,2},{4,2,7,7,2,5}}。
主线程算法过程如下:
遍历数据特征集合pSet的每个元素,根据定义7计算属性值出现次数,属性值a出现次数:na=VL(5)+VL(4)=3,VL(5)指数字5对应的二进制数中1的个数,可以通过循环移位与1按位与获得。同理可得:nb=3,nc=5,nd=4,ne=3,nf=5。
如果属性值个数大于等于4(minSupNum),则将相应的属性值放入一阶频繁集FI1,则例中FI1={c,d,f}。
根据FI1元素自连接,得到二阶频繁候选集{cd,df,cf}。根据推论1计算每个频繁候选集组合的支持度。其中cd一起出现的次数:ncd=VL(3&2+7&7)=4,同理ndf=3,ncf=4。则二阶频繁项集FI2={cd,cf}。
由二阶频繁项集FI2自连接,得到三阶频繁候选集{cdf},根据推论1计算三阶频繁候选集的频繁度:ncdf=VL(3&2&7+7&7&5)=3。则三阶频繁项集FI3={cdf}。因为三阶频繁项集中只有一个元素,程序结束。
3.2算法性能比较
以生成频繁项集的时间开销,对经典的串行Aprior算法和提出的BVP算法进行性能比较。
测试数据由IBM数据生成器生成,数据集是单维26属性。数据量由1万条增加到30万条,最小支持度30%,2个子线程和1个主线程。性能比较如图1所示。

图1 运行时间和数据量关系Fig.1 The relationship of running time and datas
由图1中可见,相同数据量时,BVP算法相对于Apriori算法运行时间更短。在双线程的情况下,大约减少了35%的运行时间。
图2是数据量固定为20万条,不同的子线程个数,BVP算法的性能表现:
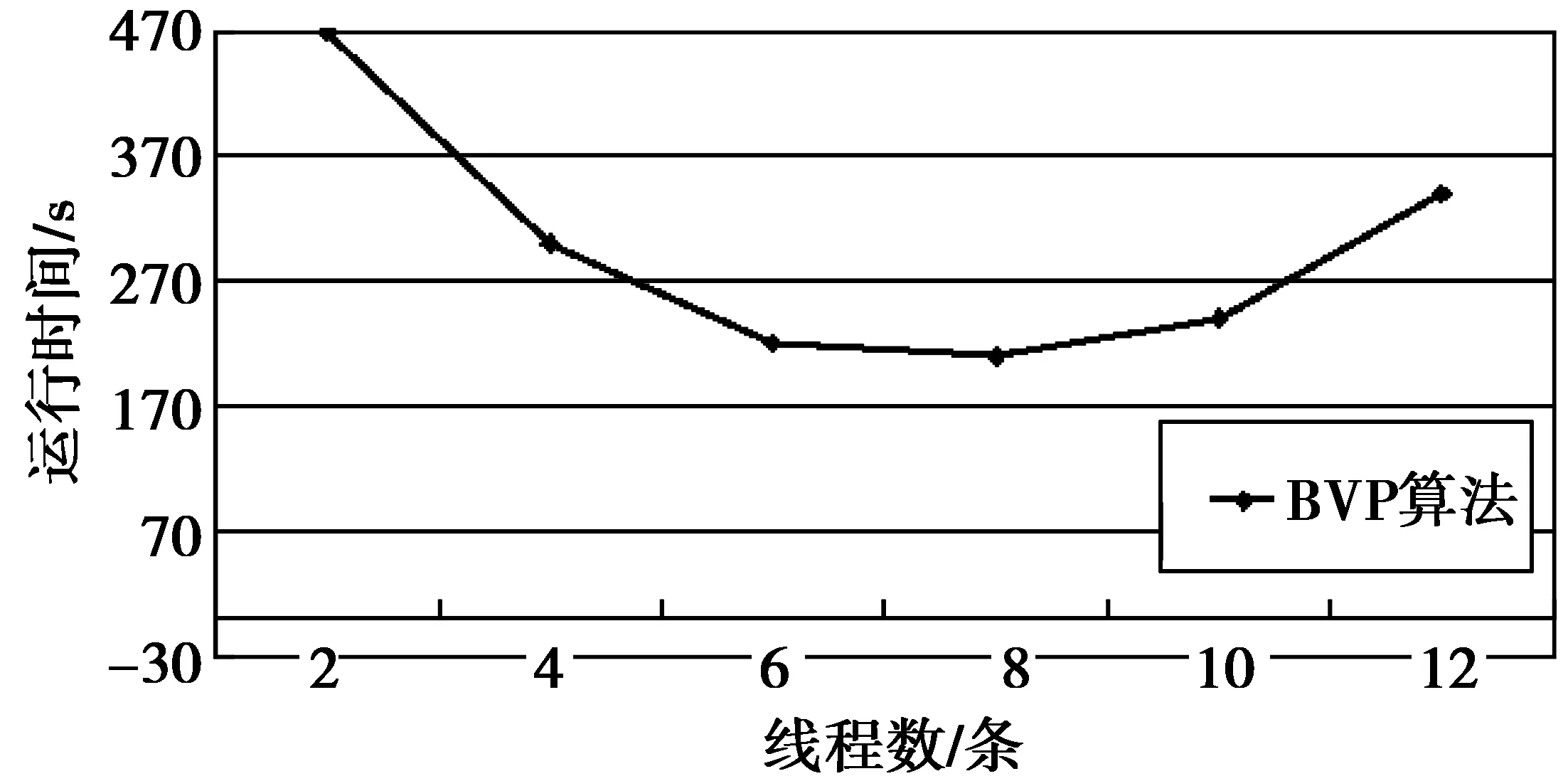
图2 算法运行时间和线程关系Fig.2 Algorithm running time and threads relationship
从图2中可见,适当的增加线程可以减少运行时间。但并不是线程越多,运行时间越短,因为线程切换也是需要时间的。可见,根据实际情况选择合理的线程数是非常重要的。
4结语
提出了基于位串的关联规则并行算法,通过多线程的方式将事务数据分成多个部分,并行的计算数据特征。最后将数据特征传递给主线程统计频繁项目集和关联规则。通过并行算法提高了关联规则求解的效率,并且算法实现简单。通过仿真,算法总体性能优于Apriori算法。
参考文献(References):
[1] PANG N,T.Introduction to Data Mining[M].北京:人民邮电出版社,2015.201-293
[2] AGRAWAL R,IMIELINSKI T,SWAMI A.Mining Associ-ation Rules Between Sets of Items in Large Databases[J].
Acm Sigmod Record,1993,22(2): 207-216
[3] AGRAWAL R,SHAFER J.Parallel Mining of Association Rules[J].IEEE Trans Knowledge and Data Eng,1996,8(6):962-969
[4] ZAKI M J.Paralled Data Mining for Association Rules on Shared-Memory Multi-Processors[M].Proceedings of Sup-ercomputing,Los Alamitos:IEEE Computer soc.Press,1996
[5] LIU L,LI E,ZHANG Y,et al.Optimization of frequent item-set mining on multiple-core processors[G]∥Procee-dings of 33rd International Con-ference on Very Large Data Bases,2007[6] 王智钢,王池社,马青霞.分布式并行关联规则挖掘算法研究[J].计算机应用与软件,2013,30(10): 113-115
WANG Z G,WANG C S,MA Q X.Research on Distributed Parallel Association Rule Mining[J].Computer Appli-cations and Software,2013,30(10):113-115
[7] JING S,LEI X H.Mining Frequent Closed Itemsets Over Data Stream Based On Bitvector and Digraph[J].2010 2nd International Conference on Future Computer and Commun-ication,2010,2(1): 241-246
[8] 石杰.一种快速频繁模式挖掘算法[J].烟台大学学报(自然与工程版),2015,28(2):113-119
SHI J.A Fast Algorithm for Mining Frequent Patterns.Journal of Yantai University(Natural Science and Engin-eering Edition),2015,28(2):113-119
[9] 陈丽芳.基于Apriori 算法的购物篮分析[J].重庆工商大学(自然科学版),2014,31(5):84-89
CHEN L F.Analysis of Shopping Basket Based on Apriori Algorithm[J].Journal of Chongqing Technology and Busi-ness University(Naturnal Science Edition),2014,31(5):84-89
责任编辑:田静
An Improved Rule Association Parallel Mining Algorithm
WANG Feng-kun,ZHANG Ting-ting
(Department of Information Engineering, Anhui Technical College of Mechanical and Electrical Engineering, AnHui WuHu 241000, China)
Abstract:The classical algorithm of association rules (such as Apriori algorithm) is a serial algorithm, when the data volume is relatively large, mining efficiency is low. A new parallel BVP algorithm is proposed. The BVP algorithm reads data from multiple threads and calculates the corresponding data. Then, the frequent itemsets and association rules are computed. Experimental results show that the algorithm is more efficient than the classical Apriori algorithm.
Key words:data mining;association rules; parallel; frequent itemsets
中图分类号:TP301.6
文献标志码:A
文章编号:1672-058X(2016)03-0047-04
作者简介:汪峰坤(1978-),男,安徽六安人,讲师,硕士,从事计算机软件、数据挖掘和大数据处理研究.
*基金项目:安徽高校省级自然科学基金重点项目(KJ2014A038).
收稿日期:2015-10-05;修回日期:2015-12-02.
doi:10.16055/j.issn.1672-058X.2016.0003.010
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
电力与能源(2017年6期)2017-05-14 06:19:37
电子技术与软件工程(2016年22期)2016-12-26 12:55:09
移动通信(2016年20期)2016-12-10 09:09:04
中学课程辅导·教师教育(上、下)(2016年19期)2016-12-07 21:09:42
新教育时代·教师版(2016年33期)2016-12-02 11:43:33
中国中医药信息杂志(2016年7期)2016-12-01 06:07:55
中国市场(2016年36期)2016-10-19 04:10:44
电脑知识与技术(2016年21期)2016-10-18 21:49:16
信息通信技术(2015年6期)2015-12-26 01:16:46
