
基于决策判别树和ASVM的自适应支持向量混合信誉度评价模型研究
2016-05-19 14:21赵福壮
电脑知识与技术 2016年8期
赵福壮

摘要:本文在分析了国内外关于信誉评价的研究现状后,结合我国企业发展的情况,创造性地提出了基于决策分类树与ASVM的混合企业信誉度评价模型。较好地满足了预先设定的要求为我国企业信誉度评价领域增添了一种新的方法。该模型既解决了决策分类树在面对连续属性的缺陷和多分类时出错概率增加的问题,又解决了ASVM无法进行多分类的问题。混合信誉度评价模型中以ASVM作为决策分类树中分支节点的判别模型。并且通过实验发现组合核函数的ASVM模型相对于RBF核函数的ASVM模型在信誉危机判别应用中准确率有一定的提升。最终的混合信誉度评价模型采用了组合核函数的ASVM模型作为分支节点的判别模型。经过最终的实验对比发现,该模型在解决企业信誉多分类问题中具有较高的准确率,具有较高的实用性
关键词:信誉度评价指标;决策分类树;自适应支持向量机;组合核函数;混合模型
中图分类号:TP391 文献标识码:A 文章编号:1009-3044(2016)08-0253-05
Abstract: After analyzing the present situation of the domestic and international credit evaluation research field,and combined with the situation of our country's enterprise development, A hybrid enterprise reputation evaluation model based on decision classification tree and ASVM is proposed.This model meets the requirements of the pre and adds a new credit model for our country. Which not only solves the problem of the increase of the error probability of the decision tree in the face of the defect of the continuous attributes,but also resolves the problem that ASVM cant make a multi classification.In mixed reputation evaluation model,ASVM with combination kernel function is more accurate compared to ASVM with RBF kernel function.So the new the mixed credit evaluation model has a high practicability.
Key words:Index of credit evaluation decision tree ASVM Combined kernel
信用评价是在市场经济环境下针对企业、债券发行单位、金融机构等市场参者未来按期偿还债务的能力及偿还债务的程度进行综合评价的业务行为。在市场经济的大环境下,信用评级起到十分重要的作用。它有利于降低交易风险成本,全面展示企业或债务发行单位的信用风险;有利于降低社会信息获取成本,能够协助政府部门进行市场监管,防范预测金融风险,同时也是经济全球化发展的必然要求。为了进一步发展经济,使中国走向世界,习近平总书记提出了一代一路建设,并在十三五规划中大力提倡中国创造2025计划,从中国制造转向中国创造。企业走出去作为国家的名片,其信誉形象的好坏,更是直接影响着一个国家的总体形象。因此我国政府相关部门也开始重视并加快了信用制度的建设。我国企业征信管理中心借鉴国际先进的征信理念、科学的征信机制、时时海量信用信息等优势,建立了涵盖各级政府职能部门、社会团体、行业协作、媒体、金融机构以及广大消费者评价意见的信用评级标准,对企业进行信誉度评价,建立企业信誉档案,规范企业发展。
然而就实际情况来看,我国征信体系相对于西方发达国家而言起步较晚。西方征信体系已有上百年的历史,并且有很多相关领域学者或机构根据自己国家企业的不同情况进行了针对性研究。总体而言,我国信用评级机构整体来说表现为以下特点[1]:
1)评级机构总量大、规模小、实力相对较弱。
2)信用评级机构的专业性不够强。
3)市场上信用评级机构对企业的信誉评级结果表现出可信度低,利用率低,对社会影响较小特点。
4)企业对信用记录的重视程度还不够,存在造假现象。
由以上四点可以看出一个好的信誉评价机构必须本着公平,公正的原则对受评企业进行信誉评价。只有真实反映出企业的信誉状况,才能取得公众的信任,并为各方所接受。当然准确反映企业信誉状况是以一套科学的企业信誉评价体为前提的。信誉评价领域的相关研究人员对此也做了大量研究。就目前来看,一个良好的信誉评价体系需要做一下两方面的工作[3]:1)评价指标体系的选取问题;2)信誉评价模型的构建问题。
1信誉评价指标的体系的选取
在分析了国内外企业信誉度评级因素的内容和特点,结合中国上市企业的特征,综合评估我国上市企业信用等级,本文将评级因素划分为 企业文化、盈利能力、偿债能力、经营能力、资本构成、行业前景共6个大类一级因素,每一类因素又包含有若干个二级因素[4]。具体如表1所示。
上述初始拟定的评价指标是通过查阅大量文献,进行全面分析,以详尽和完备的原则建立而成的,其中包含了财务指标和非财务指标两大类[2]。从信誉度评价的本质来讲,评价者只需要找到较为关键的指标即可对企业进行信誉评价,从而也降低了评价成本。如果评价指标体系过大,会相应稀释影响企业信誉对应指标的关键因素的影响力,此外还会大大增加信誉评价模型的复杂性程度。因此需要对上述指标体系进行一定的筛选,剔除影响因子相对较小的指标。在维护评价指标体系全面性的前提下,降低评价模型的复杂程度。
本文采用专家意见法来确定企业信誉评价的指标体系,剔除一些影响力较小的指标。我们知道金融领域的专家,经过多年的实践研究,对企业信誉风险评价有着较为深刻的认知。他们可以利用专业知识,工作经验,从评价指标的实际意义来考虑其在企业信誉评价中的重要性。
通过根据专家的打分统计对信誉评价指标进行排序,剔除得分较低的几个指标。专家们的统一判断,行业前景权重较弱,对公司的信誉级别影响较小,因此对其中的产品销售前景、行业整体发展前景和国家政策支持三个指标进行剔除。虽然剔除了行业前景中的三个指标,但剩余评价指标集合与实际的关键指标集合整体还是保持一致的。根据前人的研究可知,企业遭受信用危机,影响信誉度的关键因素主要为企业的流动比率、资产周转率、利润率,并且这几个指标专家统一给出的分值都比较高,剩余的评价指标集合相对全面地覆盖了影响企业信誉的指标集。最终建立包含X1-X15共15个变量的信誉评价指标体系。
2决策判别树在信誉判别中应用优缺点分析
决策树是一种人们为了对某件事情进行决策而进行的一系列判断过程的树形图,由决策节点、分支和叶子三个部分组成。基本思想是利用训练数据集自动的构造决策树,然后根据建立的决策树对任意实例进行判定,它往往向人们展示的是各因素之间的交互作用。
决策树与其他分类算法相比存在的缺陷是当类别很多时,它的分类错误率就可能增大。而且对于连续的属性字段比较困难做出准确的预测。判别节点通常是根据一个属性来进行分类的。上述缺点,判别树在企业信誉判别中也是存在的。
1)企业信誉级别判别属于多分类问题,企业信誉级别通常分为多个层次,面对这种情况,判别树错分的几率将会大大增加。信誉危机判别或贷款决策中通常是二分类问题,即企业是否出现危机或是否给申请贷款对象贷款,运用判别树则比较合适。
2)企业信誉度判别指标体系中,占很大一部分指标比例都是连续的字段。判别树在面对连续属性时,往往也表现出其中的不足,很难做出准确的预测,解决的方法通常是数据预处理期间对数据进行分段处理。
3)判别树在判别分类时属于以此递进的过程,每个判别节点只用一个基本属性字段进行最大限度分类。然而在现实分类情况中不一定存在这种递进式的分类关系。
需要综合所有指标才能进行分类。在企业信誉多等级评价时也会出现这种情况。
通过以上决策树在企业信誉度评价中的应用缺陷总结,能否找到一种新的判别模型用作判别树中分支节点的判别模型,消除上述3点的不利影响有待研究。
3ASVM在信誉判别中的应用及优缺点分析
3.1 ASVM原理介绍[5][6]
首先引入分类错误率、决策损失函数、样本偏斜度的概念并进行说明:
1)分类错误率
在公式(7)中,[λ]作为平衡因子来平衡决策损失最小化和分类间隔最大化目标。此外在模型中加入了决策损失函数来同步决策评价与学习过程,使得学习过程与风险偏好一致。[mj]用来反应样本的偏斜程度,使模型对样本偏斜度有自适应能力,[Cj]分类错误代价反应了决策者的风险偏好,决策者通过这一参数的调节,对分类器结构进行干预,使模型具有交互能力。此外[mj],[Cj]还具有调整最优分类超平面的作用。上述自适应支持向量机自动的赋予了两类分类错误不同的惩罚参数值,某类的分类错误比率越大或该类的样本总数越小,对应的惩罚参数越大。分类器将向着该分类错误的方向变化。不同的偏斜情况和分类错误对应着不同的分类器,使得分类器具备了动态特征。因此,该模型具有数据不平衡特性和决策风险偏好适应性,称之为自适应支持向量机模型。
关于自适应支持向量机的求解中,由于该模型在分类方法中加入了分类错误最小化目标函数,可以看出(7)问题为NP完全问题。通过凸规划方法和二次规划方法是无法求解的。在上述模型中,采用的是样本点到分类边界距离的(0-1)阶梯函数来判断产生分类错误与否。由于阶梯函数的不可导性。可采用公式(8)。
3.2核函数的选择问题
核函数的选择对SVM的性能起到至关重要的作用,寻找一个适合的核函数是SVM算法的核心,但是截至目前,相关研究领域还没有给出合适的理论依据去选择优质的核函数。
目前学术界把支持向量机的核函数分为两类:全局性的核函数和局部性的核函数。可以通过在matlab中运用方阵核函数曲线了解对应的核函数是局部的还是全局的。局部核函数仅对测试点附近的小范围数据有影响,而全局核函数能提取样本全局特征,插值能力比较弱。对测试点近距离数据和远距离数据都有一定影响。
经过实验验证采用高斯核函数的ASVM模型较普通SVM模型在准确率上有一定的提升。但考虑到企业信誉度评价样本集的广泛性,及样本记录属性的多样性,本文提出采用组合核函数的ASVM模型进行信誉风险评估与预测。通过分析全局核函数和局部核函数的优缺点以及核函数的性质,构造组合核函数如公式(10)
3.3实验对比分析
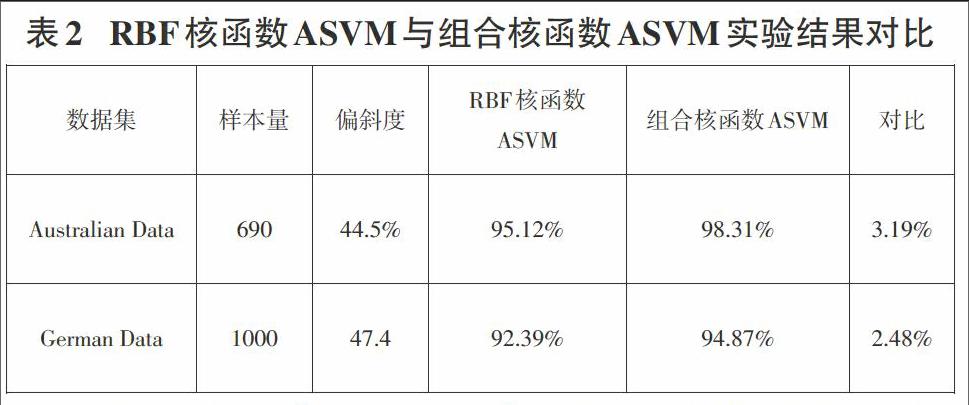
为保证实验的可对比性,本文实验参数设置与陈思凤、Lin等人的设置是一致的。实验数据采用机器学习网站UCI提供的澳大利亚信用支持Statlog(Australian)Data 数据集和德国Statlog(German)Data数据。其中澳大利亚信用数据集,总共包含690条数据,记录中包含14条属性。Y=1的记录包含307条记录,Y=-1的记录包含383条。分别占比44.5%和55.5%。德国信用数据总共包含1000条记录,记录中包含20条属性,一类记录包含474条,二类记录包含526条,分表分别占比47.4%和52.6%。
陈思风的实验表明运用粒子群优化参数的自适应支持向量机能获得更适合的SVM参数。本文对RBF核函数的ASVM和采用(10)式的组合核函数的ASVM分别在上述两个数据集上进行了实验对比。由于只考虑样本不平衡的情况,不考虑决策损失问题,所以此实验的分类错误代价[C1=C2],下表给出了两种核函数的实验结果的准确率。
由表2可以看出,采用粒子群算法进行参数选择的ASVM在上述两个数据集样本偏斜的情况下都达到了较高的分类准确率。采用组合核函数的ASVM与采用RBF高斯核函数的ASVM相比,在准确率上有相应的提高。主要原因在于RBF核函数属于局部核函数,而新提出的组合核函数考虑到了信誉风险预测样本集的广泛性与样本记录中属性的多样性,结合了局部核函数与全局核函数的优缺点。所以组合核函数ASVM更适合用来进行信誉评级。
4 混合企业信誉度评价模型
本文采用国际通用标准,将信用评估等级划分为AAA、AA、A、BBB、BB、B、CCC、CC、C、D四等10级。其中A类信用等级又分为AAA、AA、A三类档次,分别代表AAA级优秀信用企业、AA级优良信用企业和A级良好信用企业;B类信用等级同样划分为BBB、BB、B三类档次,信誉分数逐级递减,代表一般信誉企业;C类信誉等级包含CCC、CC、C三类档次,代表信誉较差企业;D类信誉不再进行细分,直接代表信誉极差企业。
4.1建立信誉判树
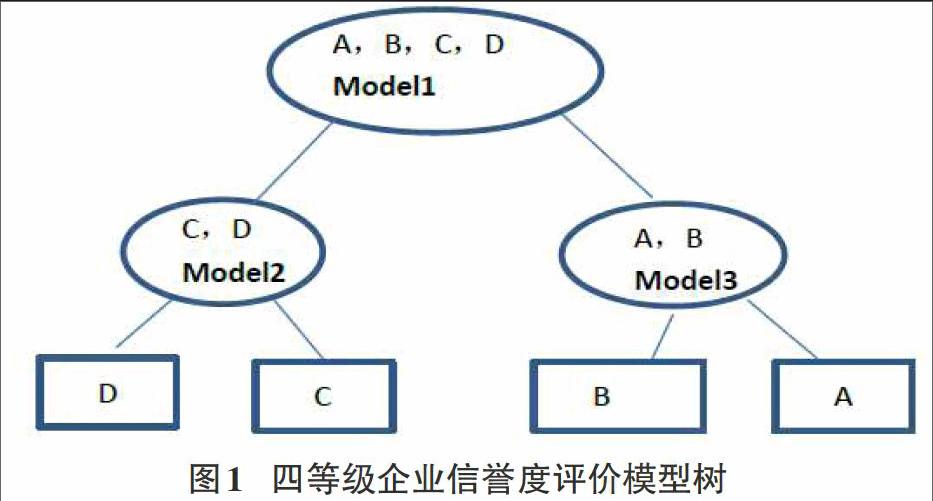
在二叉判定树中,成功的二分查找出走一条从根节点到被查找到节点的路径。不成功的查找则走了一条从根节点到叶子节点的路径。本文提出的信誉决策分类树不满足上述规则。利用建好的信誉决策分类树模型进行企业信誉判定时,走的必须从根节点到叶子节点的一条路径,不会出现中途结束的情况。图1给出一个简单的四分类混合信誉度评价模型树。
树中的每一个判别节点都的判别模型为本文第三部分提到的组合核函数ASVM。
各个判别节点判别模型的训练过程具体如下:
1)选定支持向量机的训练集合[Vn],[n]代表有[n]条记录即:[X1,X2,X3...Xn],集合中每个等级信誉度的企业都要包含一定的量。这样训练出来的超平面才更具代表性。[Xi=(xi1,xi2,xi3...Xim,y)],每条记录有m个变量。[y]代表该条记录在某一个判定节点上的值,[y=1-1]。标签划分根据判别节点的左右孩子节点进行划分。父节点集合[Sf]与左右孩子集合[Sl,Sr]满足关系[Sf=Sl?Sr,Sl?Sr=Φ]。在某一个节点上进行模型训练时,需要对样本标签[y]进行赋值。[Sf]中样本分配到左分支集合[Sl]时该样本标签[y=-1],否则样本被分配到右分支孩子节点集合[Sr],该样本标签为[y=1]。标签赋值确定之后即可运用支持向量机方法进行训练,并用测试集进行测试。如果样本数量不充足可采用交叉验证法对训练出的模型进行测试验证。
2)根据(1)中的说明,初始训练集[Vn],从根节点开始依据左右分支划分的集合给记录中的y进行赋值,左分支集合y=-1,属于又分支的集合y=1。
3)利用训练集合进行训练得到[F(x)=i=1mwiφi(x)+b=wTφi(x)+b=0]一个超平面,记录该判定节点的ASVM模型Model,对模型进行测试验证。
4)根据(3)中分割的两个子集合,递归继续重复(2)(3)两步骤,直到样本记录落在叶子节点集合里结束。训练出全部判别节点的判别模型,混合企业信誉判别模型建立完成,产生一个二叉信誉决策分类树。
按照此方式建立了四等十级混合企业信誉度评价判别树模型如图2所示。
图2中包含9个圆节点和10个方形节点。9个圆型判别节点,每个节点都对应一个判ASVM决策模型。10个方形节点,即10个细分信誉级别。每个圆形节点中包含了相应的集合,意思是,从根节点开始到达该节点经过多次二分类ASVM判别剩下的集合。样本企业所属级别就包含在该集合里。直到从根节点到方形节点,一条路径走完,样本企业落到具体的信誉级别下结束。不再采用根据信誉评价因素进行综合打分的方式来评定企业信誉级别。
4.2实验对比分析
本文数据主要来自于国泰君安官方网站上提供的上市企业2014年度相关数据。根据第1节中本文建立的信誉评价指标体系进行数据规整和预处理。把预处理后的数据作为模型的输入,最后把第3节中的组合核函数ASVM和RBF核函数ASVM分别作为4.1节企业信誉决策分类树中判别节点的判别模型进行训练实验。并对两种混合信誉度判别模型的结果进行了对比。结果如表3所示。
由表3可以看出本文提出的组合核函数ASVM模型与陈思风提出的RBF核函数ASVM模型相比,建立的企业信誉度判别模型分类正确率上有一定的提高。且两种混合信誉度评价模型都在企业信誉预测时都具有较高的准确率,有很高的实用价值。在运用时,可以根据具体场景的要求选择不同的SVM作为混合模型中信誉决策分类树分支节点的判别模型。且本文作者还进行了相关实验发现在调解ASVM中的错误分类代价[Cj]时,能很好的调节模型,使得结果向决策者的偏好方向移动。通过这种方式可以达到混合信誉度评价模型
5结束语
通常前人的研究都是对影响企业信用的指标进行分别打分,再加权求和,根据最后得分来给企业评分[7]。或者通过建模对企业进行分类判断企业是否存在风险,但只能进行二分类。本文创造性的提出采用决策分类树与ASVM结合的方法构造出混合企业信誉评级模型,较好的满足了预先设定的要求,为我国企业信誉度评价建立了一种新的方法。具体主要做了一下几方面的工作:
1)企业信誉评价变量的选取。为了保证评级指标选取的全面、准确性,本文列出18个因素变量,通过专家权重打分,最终选择15个指标作为信誉评级的输入变量。
2)首先决策分类树的优缺点分析,以及在信誉判别领域中的应用研究,并提出疑问。
3)ASVM在信誉判别中的应用及优缺点分析
4)基于决策分类树和ASVM的混合企业信誉评级模型。该信誉评级模型不采用打分法对企业信誉进行评级,而是根据企业样本数据特征进行评级。经过实验发现该混合信誉评级模型具有较高的准确率。并解决了决策分类树在面对连续属性和多分类问题中的不足。同样避免了SVM在多分类问题上的缺陷。
当然该模型还存在有待改进的地方。例如:企业样本数据是一个动态产生的过程,本文的企业信誉判别采用数据为上市企业年度数据。缺乏动态预测。更全面的方法是根据企业的多阶段历史数据进行信誉预测。例如按时间顺序,获取企业每一季度的相关数据,根据数据的动态变化趋势对企业信誉进行预测,将会更加科学全面。作者也会在后面的工作中进行相关研究。
参考文献:
[1] 诸小丽,梁柱.企业信用等级综合评判评分体系[J].中国科技信息,2005(23):293.
[2] 乔薇.中小企业信用评级模型及其应用[D].河南大学,2008.
[3] 詹世鸿.信用风险模型及信用评级综述[D].吉林大学,2007.
[4] 李万庆,张立宁,孟文清. 企业信用的综合评价[J]. 统计与决策,2005,11:23-24.
[5] 丁子春.基于支持向量机的多领域自适应分类方法研究[D].武汉理工大学,2009.
[6] 陈思凤.基于ASVM的创业板上市企业风险评估研究[D].合肥工业大学,2012.
[7] Leonard K J. A fraud alert model for credit cards during the authorization process[J]. IMA Journal of Mathematics Applied in Business and Industry.19934(5):57-62
