
基于KMV模型的在线社交网络异常用户检测
2016-05-14 22:34黄树斌王彤
网络空间安全 2016年4期
黄树斌 王彤
【 摘 要 】 在线社交网络中,异常用户是始终存在的。现代的手持移动终端设备在提升普通用户便携性的同时,也降低了异常用户在社交网络中的行为成本。KMV模型是美国KMV公司于1993年建立,用来估计借款企业违约概率的方案,是应用最广泛的信任度量模型之一。论文尝试使用KMV模型来映射计算社交网络中异常用户的预期违约率,在保证KMV模型高效、精确的前提下,保证了异常用户的识别率,能够运用在实际社交网络环境中。
【 关键词 】 在线社交网络;异常用户;预期违约率;KMV
【 Abstract 】 Abnormal user will exist permanently in Online Social Network(OSNs). Modern mobile device as well as improve the portability of ordinary users also reduces the cost of malicious behaviors in OSNs. KMV model was posted by KMV Corporation in 1993 to focus on estimating the Expected Default Frequency(EDF) of the enterprise, KMV is the one of the most widely used credit monitor model. This paper use KMV to modeling the EDF of abnormal users in OSNs, has a high recognition rate of abnormal users in guarantee the efficiency and accuracy of KMV. It can be used in actual OSNs.
【 Keywords 】 osns; abnoraml user; edf; kmv
1 引言
随着移动手持设备的发展和社交网络的进一步演化,越来越多的人能够低成本的使用社交网络。由于移动手持设备的功能的逐渐增加,社交网络的终端设备已经逐渐由PC端转移到移动端。移动端手持设备具有使用时间片分散、使用成本低、用户忍耐度低等属性,这些属性,给社交网络带来了一些新的特征。同时,也造成了异常用户的行为成本降低,增大了异常用户的数量。
在以往的研究中,对于异常用户的检测使用的方案大致有基于行为特征、基于内容、基于图、无监督学习等方向。使用如上方案,能够在一定程度上达到检测异常用户的目的,不过仍有一些局限性,具体表现在两方面。
第一,无法发现并检测新的攻击方式:由于社交网络中异常用户是始终存在的,因此,社交网络中会不断出现各种新的攻击方式。异常用户由不同的目的,会根据社交网络的用户监督系统设置,不断调整自己的攻击方式。唯一能识别新的攻击特征的无监督学习方案,由于方案本身的一些局限性,仍然需要有运营人员时刻关注社交网络的发展。
第二,处理数据量过大,无法达到异常用户检测所需的实时性:基于推荐的一些解决方案,包括基于内容的方案,能够达到较高的准确性,但是由于解决方案本身需要分析大量数据,因此实时性无法保证,一般用于离线数据分析等场景中。无法在恶意用户的使用过程中及时的发现并采取相应措施。
本文将经济学领域中的KMV模型应用于社交网络中,通过相应的概念映射,能够利用KMV模型中的思想,得到相应的用户节点的预期违约率。从而判断在选定时间周期内,用户的违约概率,以此来相应的选择应对方案,减少异常用户对正常用户以及社交网络本身造成更大的信息干扰。
2 KMV模型基础思想
KMV模型是美国KMV公司于1997年建立的用来估计借款企业违约概率的方案,是应用最广泛的信任度量模型之一。该模型认为,贷款的信用风险是在给定负债的情况下,由债务人的资产市场价值决定的。结合Black-scholes期权定价公式,估算出企业资产的市场价值、资产价值的波动性。根据公司的负债计算出公司的违约实施点,计算相应的违约距离。再根据违约距离计算出预期违约率(EDF)。
KMV模型的主要优势在于,使用了资本市场的信息而不是历史账面资料进行预测,很好的将市场信息加入了预测逻辑中,更够反应企业当前的信用状况。在一定的时间积累内,KMV模型可以预测得到违约区间。因此,本文将KMV模型引入社交网络中,尝试达到相对实时、运算资源消耗较少的目的。
3 KMV模型在社交网络中的映射
在本部分中,我们将KMV模型中的理论,映射到社交网络中,尝试解决社交网络中异常用户检测的问题。
首先,KMV模型的主要思想:贷款的信用风险是在给定负债的情况下由债务人的资产市场价值决定的。映射在社交网络中,可以表述为:观察用户点的异常行为风险,是在已记录的行为情况下,由观察用户点的总体信任值决定的。也就是说,被观察的用户点,产生异常行为的可能性,和用户点的前期行为有关,也和用户点的当前未清算的行为(债务)有关。
社交网络中概念和KMV模型中的概念对应起来。
(1)用户信任值:在社交网络中,用户的信任值表示用户的一个评分值。与KMV模型中企业股权的市场价值相对应。(2)用户行为:本文将社交网络中用户的行为分为正向行为、负向行为、中性行为。正向行为对信任值有益,负向行为对信任值有害,中性行为不对信任值本身产生影响。(3)单次使用时长:在社交网络中,存在一个平均单次使用时长的数值,表示一个用户平均一次使用社交网络的时长。本文使用该时长作为一个时间段,在一个时间段内,所有的正向行为、负向行为,加权得到用户的具体信任值增减。(4)使用天为单位,将一个单位时间内的信任值增加作为债务和收益,下一个有效单位时间内才计算入总体信任值。
4 算法实施
4.1 数据说明
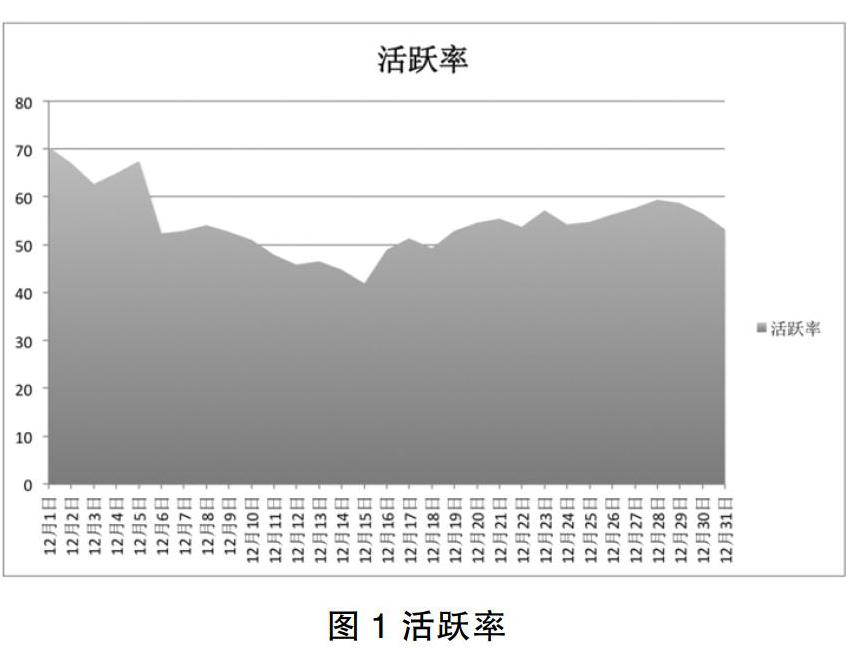
实验数据集使用的是目标应用:Feeling 大学聊天交友社交APP。目前为止,该应用累计用户在20万人左右,作为研究目标,可以代表一般的社交网络应用。从应用中随机选取用户100人,其中包含目标用户点10人,参照用户点90人,终端类型为 iOS,注册时长在一周以上,活跃时间超过1天,均为产生用户行为数据在10以上的用户。以一个月为分析时间段,一天为一个变化周期,单次使用时长为计算周期。根据移动互联网的特性,去除掉不存在操作的时间段,得到用户的活动次数频次图1所示。
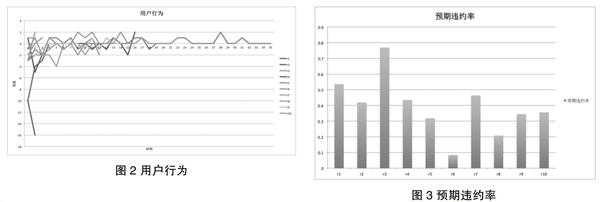
从图1可以看出,作为分析对象的100名用户,在12月中的活跃率在40%-70%之间。在所有记录的用户行为中,选择能够产生数据的行为,加权后如图2所示。
4.2 算法描述
根据以上思想,KMV模型算法描述如下:
用户的当前信任值VA
输入:一个月内观察点的加权行为数据
输出:观察点的信任值历史波动率αA
输入:观察点的当前时间段债务与收入
输出:违约点DP= LS+LS违约距离DD=
最终得到观察点的预期违约率:EDF=N[-DD]
4.3 实验结果
得到的最终预期违约率如图3所示。
作为观察点的10名用户中,经过人工分析后得出的结论表1所示用户标记。
从表1中可以发现,人工分析后,用户标记大致和预期违约率走势相吻合。对于特殊点r6,由于有效数据过少,算法与人工分析都暂时无法判断用户属性。
5 结束语
将经济学领域中模型映射到社交网络中,用作用户分析,是一个比较有趣的问题。作为经济学分析对象的上市公司,有很多行为都和用户在社交网络中产生的行为非常类似。使用的模型,能够很好地对分析对象行为进行预测,在实时性和准确性上都达到了一个较满意的效果。但是,由于分析对象本质的不同,需要对模型进行修正,也需要对分析的用户做一些筛选。
最终结果中,KMV模型虽然对目标用户上下限的分析预测较为准确,但仍然还存在部分中间用户无法较好的判断。
因此,在后续研究中,将研究KMV模型中违约点的设定方式,同时搜集更多的用户有效行为数据,进一步提升算法对于异常用户判断的准确性。
参考文献
[1] 张玉清,吕少卿,范丹.在线社交网络中异常账号检测方法研究[J].计算机学报,2015(10).
[2] 孙小丽.基于KMV模型的商业银行信用风险测算研究[J].北京邮电大学,2013年.
[3] 马若微,张微,白宇坤.我国上市公司动态违约概率KMV模型改进[J].系统工程,2014(11).
作者简介:
黄树斌(1991-),男,江西宜春人,毕业于重庆大学,在读研究生,硕士;主要研究方向和关注领域:社交网络、隐私保护。
王彤(1990-),男,四川南充人,毕业于重庆大学,在读研究生,硕士;主要研究方向和关注领域:推荐系统、隐私保护。
