
差分隐私保护下一种改进的协同过滤推荐算法
2016-05-14 11:05王彤黄树斌
网络空间安全 2016年4期
王彤 黄树斌

【 摘 要 】 协同过滤(CF)是推荐系统中最常用的算法,然而传统的构建在协同过滤上的推荐系统很难提供一个严格并有数学证明的隐私保证。近期研究表明,攻击者可以通过观察用户的推荐结果,推测出用户的评分记录,这将对用户的隐私造成极大的威胁。论文在应用差分隐私保护技术的隐私保持协同过滤算法的基础上,对用户与物品进行裁剪,从而大量减少了噪声的引入,在保证隐私的前提下提升了算法准确度。同时,论文提出的算法改进方法具有较广的适用性,能够与已有的研究能够很好的结合。
【 关键词 】 协同过滤(CF);差分隐私保护;安全
【 Abstract 】 Collaborative Filtering (CF) is the most common algorithm in recommender system. However, the traditional approaches can hardly provide a rigid and provable privacy guarantee for recommender system. Recent research revealed that by observing the public output of the CF, the adversary could infer the historical ratings of the particular user, which will cause a great threat to user privacy. This paper address the privacy issue in CF by cutting the data, which is constructed on the basis of the notion of differential privacy. As a result, this method would reduce the large number of noise introduced by differential privacy algorithm, and increase the accuracy of the algorithm with privacy preserving. Furthermore, our method can easily apply in the existing research.
【 Keywords 】 collaborative filtering; differential privacy; security
1 引言
Ramakrishnan等人首次提出在推荐系统中的隐私问题,Narayanan等人通过联合Netflix与IMDB的发布数据集成功的标识出部分户。Calandrino等人通过观察推荐系统一段时间内推荐结果的变化,结合背景知识推断出某用户的历史评分与行为。
差分隐私保护是一种在满足差分隐私的条件下保证发布数据或查询结果的精确性的,有着严格数学证明的理论,能够有效的保护个人隐私。在通常情况下,由于推荐系统中的查询往往具有较高的敏感度,所以应用差分隐私技术会引入大量的噪声,这会导致在保证隐私的同时会有较大的精度损失。
很多学者就差分隐私在推荐系统中的应用提出不同的方法,在隐私保护与推荐的准确性方面均取得了不错的效果,但仍有许多局限性,它们主要表现在两个方面。
(1)差分隐私技术会引入噪声,由于推荐系统中的查询往往具有较高的敏感度,所以应用差分隐私技术会引入大量的噪声,导致数据可用性较差。为了减少大量噪声的引入,现有研究往往采用各自定义的局部敏感度进行计算,但这使得推荐算法仅在特定应用场景有较好的效果。
(2)现有研究的各种隐私保护推荐算法对原有算法进行了大量的改进,但算法的大量修改使得其很难利用传统推荐领域已有研究成果。
本文在应用差分隐私保护技术的隐私保持协同过滤算法的基础上,根据隐私保护程度对用户与物品进行裁剪,从而大量减少了噪声的引入。同时,本文提出的算法改进方法具有较广的适用性,能够与已有的研究能够很好的结合。
2 改进的隐私保持协同过滤推荐算法
在本部分,我们将提出改进的隐私保持协同过滤推荐算法(IPriCF)来解决基于近邻的协同过滤推荐算法中的隐私问题,在后面的部分,我们将首先介绍算法的总体思想,然后对我们的算法进行详细的描述。
2.1 算法思想
差分隐私的基本思想是对原始数据的转换或对统计结果添加噪音来达到隐私保护的效果,即保证给出总体或模糊的信息,但是不泄露个体的信息。推荐系统中的查询往往具有较高的敏感度,所以应用差分隐私技术会引入大量的噪声,导致数据可用性较差。假如我们以余弦相似度(COS)作为协同过滤算法中的相似度度量,一个典型的情况是两个用户仅仅有一个同时评分的物品,最坏的情况下,删除这条记录后他们的余弦相似度从1降低到0。对原数据加入满足Lap(1/ε)分布的噪声后,原数据的可用性将急剧降低。
定义1 (全局敏感度)对于任意一个函数f:D→Rd,函数f的全局敏感度为:
Δf = || f(D) -f(D') ||
由定义1可知,对于函数f每条记录的敏感度是不同的,而直接影响噪声引入数量的全局敏感度Δf 取其中最大的值,所以,我们会对原始数据进行剪裁,裁剪掉那些“特殊”并且敏感度很大的值,降低查询的全局敏感度,从而减少噪声的引入。
2.2 算法描述
根据以上思想,改进的隐私保持协同过滤推荐算法描述如下:
算法1 IPriCF
输入:用户ua对物品ti的真实评分rai ;输出:保证用户隐私的预测评分ai 。
1)数据裁剪:(1)用户评分的数量位于区间[α,β];(2)1.2 物品被评分的次数应不小于γ。
2)隐私邻居选择:(1)添加Laplace噪声,计算相似度度矩阵;(2)选择邻居:根据生成相似度矩阵选择k个邻居。
3)计算预测评分ai 。
本算法中,步骤3为标准的CF操作,我们将重点讨论数据裁剪与隐私邻居选择部分。
数据剪裁分为两个阶段:第一阶段生成用户评分数的直方图统计,在本阶段中我们筛选出评分数量不属于区间[α,β] 的用户,然后在原始数据集中删除与该用户有关的所有评分信息;第二阶段生成物品被评分数的直方图统计,在本阶段中我们筛选出被评分数量小于γ的用户,然后在原始数据集中删除与该物品有关的所有评分信息。
为了使被裁剪的用户依然能得到推荐,同时又要保证其隐私,我们在计算相似度时仅与未被剪裁的用户计算相似度,并加入Laplace噪声;对于被裁剪用户之间,他们的相似度为0。需要注意的是,区别于被裁剪的用户,在计算相似度的过程中,我们将不考虑关于被裁剪物品的评分记录。
邻居选择部分与标准的KNN协同过滤算法类似,我们设置参数k表示参与用户推荐的相似用户个数。
3 实验与评价
3.1 实验数据集
实验数据集采用的是推荐领域中公认的MovieLen数据集,包含943个用户对1682部电影共10万条评分,每个用户的评分数不小于20,评分为1-5。
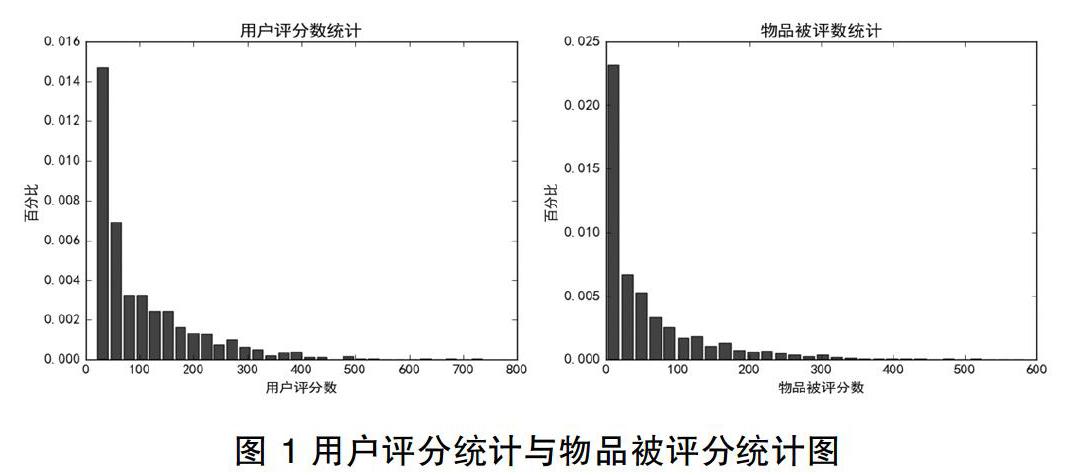
图1为用户评分统计图与物品被评分统计图,从图中可以看出,用户评分次数集中在 [20, 400]这一区间,而大于400次评分的用户仅占1.60%,物品被评分数集中在[1, 300]这一区间,仅被评分过一次的物品占8.38%。
3.2 评价标准
本文采用推荐领域中公认的均方根误差(RMSE)作为评价标准:
RMSE=
其中r是用户ua对物品ti的真实评分,ai是预测评分,T表示训练数据集,|T|表示训练数据集的大小。显然,较低的RMSE值意味着较高的预测准度。
3.3 实验结果与分析
将原始数据集按 80% / 20% 比例随机分为训练数据集与测试数据集,按相同方法分为5组互不相关训练数据与测试数据,我们分别在数据集上应用基于近邻的协同过滤算法,典型的使用差分隐私保护的协同过滤推荐算法与本文提出的算法,实验的结果是在这五组数据集上的结果取均值。
在差分隐私保护中,隐私保护预算是决定隐私保护水平的一个重要指标。越小的代表着越高的隐私保护水平,同时会引入更多的噪声。在实验中,我们将隐私保护预算的范围设置为[0.1,1],将k设置为20,参考上图统计信息,我们设置α=20,β=400,γ=2,在以上参数设置下我们将并计算在不同隐私保护水平下算法的表现。
图 2 为相似度度量分别为余弦相似度(COS)与皮尔森相似度(PCC),基础算法为基于物品的协同过滤算法的表现。从上图2可以看出,随着隐私保护预算的增加,数据的可用性增大。此外,在<0.5时,随着的增加,RMSE值急剧下降,这表明算法要保证一个较高的隐私保护水平将带损失较大的数据可用性,在≥0.5时,算法结果变化趋于平缓,这表明算法在一般的隐私保护需求下能在数据可用性与隐私保护水平中取得一个良好的折衷。
4 结束语
隐私保护是推荐系统中一个非常具有挑战的问题:一方面,为了提供更好的用户体验,需要不断提升推荐的准确度;另一方面,精准的推荐会暴露用户的隐私信息,这会导致用户失去对推荐系统的信任。所以,提升推荐系统的准确度与为用户提供隐私保证同等重要。差分隐私保护技术有着严格的数学证明,能够保证其处理结果的可信度等优点。本文在应用差分隐私保护技术的隐私保持协同过滤算法的基础上,根据隐私保护程度对用户与物品进行裁剪,从而大量减少了噪声的引入。同典型的差分隐私保护下的协同过滤算法相比,该算法在保证用户隐私的前提下提升了推荐的准确度。同类似的改进型研究相比,该算法与已有的研究成果能较好的结合,同时能够很好的利用传统推荐领域的研究成果。
在后续研究中,将研究数据剪裁程度通隐私保护预算与算法推荐准确度之间的关系,以进一步的提升算法的准确度。
参考文献
[1] N.Ramakrishnan, B.J. Keller, B.J. Mirza, A.Y. Grama, G. Karypis,Privacy risks in recommender systems, IEEE Internet Computing 5 (6) (2001) 54-62.
[2] A.Narayanan, V. Shmatikov, How to break anonymity of the netflix prize dataset, CoRR abs/ cs/0610105.
[3] Narayanan, V. Shmatikov, Robust de-anonymization of large sparse datasets, in: Proceedings of the 2008 IEEE Symposium on Security and Privacy, SP08, IEEE Computer Society, Washington, DC, USA, 2008, pp. 111-125.
[4] J.A. Calandrino, A. Kilzer, A. Narayanan, E.W. Felten, V. Shmatikov, ‘‘You might also like: privacy risks of collaborative filtering, in: Proceedings of the 2011 IEEE Symposium on Security and Privacy, SP11, IEEE Computer Society, Washington, DC, USA, 2011, pp. 231-246.
[5] Dwork, Differential privacy, in: ICALP06: Proceedings of the 33rd Inter- national Conference on Automata, Languages and Programming, Springer- Verlag, Berlin, Heidelberg, 2006, pp. 1-12.
[6] G.Adomavicius, A.Tuzhilin, Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions, IEEE Transactions on Knowledge and Data Engineering 17 (6) (2005) 734-749.
作者简介:
王彤(1990-),男,四川南充人,毕业于重庆大学,重庆大学读研,硕士;主要研究方向和关注领域:推荐系统、隐私保护。
黄树斌(1991-),男,江西宜春人,毕业于重庆大学,重庆大学读研,硕士;主要研究方向和关注领域:社交网络、隐私保护。
猜你喜欢
计算机时代(2016年12期)2017-01-14
中国新通信(2016年22期)2017-01-13
软件导刊(2016年11期)2016-12-22
现代情报(2016年11期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年26期)2016-11-24
