
面向内存云的数据块索引方法
2016-05-14 08:38王跃飞于炯鲁亮
计算机应用 2016年5期
王跃飞 于炯 鲁亮

摘要:内存云(RAMCloud)通常通过移动数据的位置来解决内存利用率低的问题,致使Hash表数据定位失效,查询数据效率低下;另一方面,在数据恢复过程中由于不能快速定位到需要的数据,每台备份服务器返回的数据段不能更好地组织起来。针对以上问题,提出内存云全局键(RGK)及二叉树索引。RGK分为三部分:定位到主服务器、定位到段以及定位到数据块。前两部分构成协调器索引键(CIK),在恢复中借助构造的协调器索引树(CIT)能够定位到段所在的主服务器;后两部分构成主服务器索引键(MIK),数据在内存中位移后也能通过主服务器索引树(MIT)快速获取到数据。与传统内存云集群相比,主服务器获取数据块的时间随数据吞吐量的增大而明显减少;协调器在闲散时间、重组日志时间等方面均有下降。实验结果表明,全局键在构造的二叉索引树的支持下能有效缩短获取数据及快速恢复的时间。
关键词:内存云;日志结构;二叉索引树;数据块定位;快速恢复
中图分类号:TP393.02 文献标志码:A
Abstract:In order to solve the problem of low using rate, RAMCloud would change the positions of objects, which would cause the failure for Hash to localize the object, and the low efficiency of data search. On the other hand, since the needed data could not be positioned rapidly in the recovery process of the data, the returned segments from every single backup could not be organized perfectly. Due to such problems, RAMCloud Global Key (RGK) and binary index tree, as solutions, were proposed. RGK can be divided into three parts: positioned on master, on segment, and on object. The first two parts constituted Coordinator Index Key (CIK), which means in the recovery process, Coordinator Index Tree (CIT) could position the master of segments. The last two parts constituted Master Index Key (MIK), and Master Index Tree (MIT) could obtain objects quickly, even though the data was shifted the position in the memory. Compared with the traditional RAMCloud cluster, the time of obtaining objects can obviously reduce when the data throughput is increasing. Also, the idle time of coordinator and recombined time of log are both declining. The experimental results show that the global key with the support of the binary index tree can reduce the time of obtaining objects and recovering.
Key words:RAMCloud; logstructure; binary index tree; object localization; fast recovery
0 引言
近年来,固态存储器的需求呈指数级增加,无论是搜索引擎还是社交网络,都需要比磁盘更高的随机访问性能[1]。随着应用的发展,这些数据逐渐从磁盘转移到闪存或动态随机访问存储器(Dynamic Random Access Memory,DRAM)中。由于在线数据密集型(On Line Data Intensive,OLDI)应用受到访问延迟、吞吐量等性能参数的制约[2],用户与数据中心的交互难以跨越由类似问题形成的屏障。内存云的出现完美地解决了以上问题:内存云是一个将所有数据存储在内存中的,由服务器集群组成的数据中心,磁盘仅在宕机或断电等意外情况下用于数据的备份[3]。如图1所示,在内存云集群中,每台服务器分为两部分,分别是主服务器(Master),用来存储和计算;以及备份服务器(Backup),用于快速恢复。集群中含有一个类似于Hadoop分布式文件系统[4]中NameNode节点的协调器(Coordinator),用来管理配置信息等工作。主服务器采用日志(log)存储方式,基本单位为段(segment),是组织数据块(object)存储的基本单位。
相对于传统数据中心,内存云提供了良好的可用性、可扩展性以及海量数据读写的低延迟环境。在针对掉电易失性、数据存储效率等问题上,研究人员制定了一系列策略以克服将数据存放在内存带来的短板效应:1)内存数据管理。针对海量数据的管理,内存云无论在内存或是磁盘中均采用日志结构的存储方式,能够实现快速索引、写入、修改等操作[5]。2)掉电易失问题。Stutsman[6]提出快速恢复策略,使主服务器掉电后能在2s内将所有的数据迅速恢复完毕,保证了数据的安全稳定。
以上问题虽然得以解决,却依然存在缺陷:1)在内存数据管理方面,由于数据以碎片形式写入内存中的段,造成段内空隙废弃较多,亟待重组清理。为提高内存利用率, Rumble等[7]提出内存二级清理机制。该策略可将内存整体利用率提高至98%,却使得定位数据的hash函数因数据的挪动致使地址失效,最终数据的查找效率由O(1)降低为O(n)。2)在快速恢复方面,每台备份服务器在恢复过程中主要通过自我查找的方式返回需要的数据。尽管实现了并行查找,但宏观上查找的数据量依然非常大。
与传统数据中心存储介质不同,目前关于内存云在索引数据方面的研究较少。其他支持大数据应用的存储系统,包括Bigtable、LevelDB、Redis和Cassandra[8-11]等在数据的管理上均采用简单的键值对存储,未使用辅助二级索引等其他方式,仅仅通过主键获得数据成为数据操作的瓶颈。华为、Facebook以及Twitter等大型数据中心采用面向列的Hbase分布式存储系统[12],该数据库为解决列与列之间的关联采用二级索引H Index,在降低索引时间等方面取得了显著效果。目前,一些新的观点弱化了索引,转而通过使用网络协议,或两阶段协议等技术确保在一个远程过程调用(Remote Procedure Call, RPC)期间数据获取的稳定性和一致性[13-14]。在海量索引目标方面,典型地如网页的甄别索引,将5000亿个网址(截止至2010年)的信息指纹随机映射到16字节整数空间[15],为处理海量索引目标提出了可供参考的技术方法。
以上方案都为进一步研究内存云下的索引问题提供了宝贵的经验与参考价值,然而并未结合内存云特殊的日志结构,致使内存云在索引数据上存在缺陷。本文在内存云数据块原有的格式上添加了一个特有的内存云全局键(RAMCloud Global Key,RGK)。在构造的二叉树索引的支持下可以实现快速定位数据和主服务器,减少获取数据以及快速恢复的时间。
1 问题描述
1.1 内存云log日志结构
内存云采用日志结构(logstructure)存储数据,每个主服务器内存空间为64GB,日志被分割成多个段,大小默认为8MB。数据块存储在段中。如图2所示,内存云集群中存在多张表(table),表中的基本存储单元为数据块,在表内被唯一标识。每张表可以单独存在于一个主服务器,也可以跨越多台服务器存储。通常情况下,每台主服务器内含多张表的数据块。
为方便增加、删除和查询某个数据块,集群中每个内存云主服务器内含有一张Hash表。定位数据块需要〈TableId,objectkey〉二元组,其中TableId指定了数据块属于哪张表,objectkey是数据块在一张表内唯一受到标识的主键。Hash函数通过TableId和objectkey获得唯一的数据块地址,进而进行操作。
1.2 二级清理机制及存在的问题
由于数据块的存储地址依据Hash表计算得来,内存云中的段在存储数据块时不可避免地浪费了大量的段空间,为解决该问题,内存云使用了二级清理机制:第一级清理(segment compaction),是将任意段中的数据块移动到一个新的段内并紧密排列;第二级清理(combined cleaning),是在备份服务器中进行同样的段合并。
然而在第一级清理后,数据块因为紧密排列导致其地址发生了变化,原先的Hash函数因无法计算地址而失效。这导致最初获取数据块的时间复杂度从O(1)升至O(n),此时只能通过在表内逐一比对objectkey以获取所需的数据块,同时这也激增了快速恢复的时间。如图3所示。
1.3 快速恢复机制及存在的问题
为避免内存数据掉电易失性,备份服务器以段为单位[16],将每个主服务器的数据备份在了备份服务器内。在恢复过程中,协调器首先查看所有的备份服务器内的数据,用于检查日志信息完整性。之后获取需要的段,拼接后重新恢复完毕。
为保证安全,需要恢复的数据分别备份在成百上千个备份服务器内,因此查阅所有的备份服务器并判断日志数据的完整性是一项十分消耗时间和资源的工作。在此阶段中存在以下几点问题:
1)每台备份服务器独立查找本机内所有相关的段。由于主服务器备份系数一般为3(在不同的备份服务器备份3份),因此每台备份服务器内含有的段的数量级约为24000个。尽管研究人员提出了所有备份服务器的查找并行化,节省了时间,但从内存云集群的宏观角度考虑,一次快速恢复的段查找仍维持在千万数量级。
2)当每台备份服务器将自身存储的恢复所需的段地址传递给协调器后,协调器需要分析这些大量的段,之后重新将地址整合成一张恢复表(recovery map)。然而段的重组过程较为耗时,不仅因为返回段的无序性,同样备份服务器在返回段的过程中并行化较低。
3)并不是所有的备份服务器都需要参与恢复过程。有些备份服务器并不含有需要的数据段,但在快速恢复机制中,这些服务器也参与了查找。
通过分析以上在清理机制与快速恢复过程中出现的问题,可以总结出对段和数据块的定位是必要的。目前对数据块的定位仅仅限定于〈TableId,objectkey〉二元组,对段的定位还没有相关讨论。
2 全局键索引策略
2.1 内存云全局键
内存云集群中,数据块是数据组织的最小单位。每个数据块在写入内存时被赋予几个关键值,用于数据块的基本操作。图4展示了数据块在内存云中的存储格式,图中在原有的格式中添加了内存云全局键RGK。
在图4中,64bit Table Identifier用来唯一标识集群中的表;64bit Version记录了数据块修改后的当前版本,防止了数据的脏读;数据块时间戳Timestamp记录了数据的写入时间,区分新老数据块,使清理时更加高效;Checksum用来确认数据块的正确性与完整性;Key Length记录了键长,Key、Value记录了该数据块的键值与数据块内的实际数据。
结合1.2、1.3节讨论的问题,为快速定位内存云中的段与数据块,现提出内存云全局键的概念。
定义1 内存云全局键(RAMcloud Global Key, RGK)。内存云全局键是一串长为64位的二进制码,能够唯一标识内存云集群中的每一台主服务器、每一个段以及最小数据单元数据块。
根据内存云集群、段以及段内数据块的数量,将全局键有效位定为前33位,后31位作为预留或备用,如图5所示。在RGK中,前10位作为集群主服务器的标识,可分别独立标识1024台主服务器。后13位标识每台服务器内的段:内存云每台服务器内存固定64GB,共划分为8192个段,采用13位二进制标识。较小数据块通常在10000B左右,因此最后10位标识每个段内的数据,可记录1024个数据块。
RGK的长度是允许变化的,备用数据位在集群数量扩增等情况下允许被占用。结合1.2、1.3节讨论的问题,为实现数据的快速定位,现将RGK合理划分。
定义2 协调器索引键(Coordinator Index Key, CIK)。协调器索引键是包含在RGK前两部分内的一串长为s位的二进制码,其中m表示RGK中标识主服务器的二进制位数,m至s位表示RGK中标识段的位数。
定义3 主服务器索引键(Master Index Key, MIK)。主服务器索引键是包含在RGK后两部分内的一串长为(o-m)位的二进制码,其中m至s位表示RGK中标识段的位数,s至o位表示RGK中标识数据块的位数。
每台主服务器内建立一棵深度为23的MIT。前十三层定位到一个确定的段,在该节点下的叶子节点均是该段的数据块。与满二叉树不同之处在于,对每个叶子节点赋一条指针,指针指向该节点对应数据块的物理地址,当Key值索引到该叶子节点,读取该节点指针指向的地址。
由于树的深度固定为23,在该循环重复有限次后即能获取到指向数据地址的指针,索引的使用提高了定位某个数据块的性能。而优化前为获取数据,需要调用二元组〈TableId,objectkey〉,再通过校对objectkey获取数据,增加了内存时延。
另一方面,MIT索引属于聚集索引,这是因为数据是以段数据块的形式有规律地组织起来的,索引键值的逻辑顺序映射了物理存储顺序。在磁盘扫描中,检索数据不需要指针跳动,扫描数据避免了多余的不连续磁盘I/O开销。并且于聚集索引的范围扫描执行情况优良,因为聚集索引的叶子节点在物理上是按照组成聚集索引的顺序排列在磁盘上的。
3 实验与分析
3.1 实验环境
实验模拟内存云集群。创建11个节点,其中1个节点为协调器,10个节点为主服务器。每个节点内主服务器内存16GB,备份服务器硬盘100GB。主服务器内段默认8MB,分别备份3份副本随机放置在10个节点中内的磁盘中。
由于实验模拟的集群节点少内存小,实验中RGK设置为25位。其中前4位定位到唯一主服务器,第5~15位确定该服务器内的唯一段,16~25位定位到数据块。主服务器内 10GB用来放置数据,共存放数据段1280个。要说明的是,MIT(即RGK去除前4位)第11层为满节点,其中含有768个空节点,这些空节点的孩子节点也为空,不存在索引问题。
3.2 实验结果与分析
通常在内存中,获取数据的速度与数据传输通道容量、吞吐量、内存时延等因素相关。实验中,获取数据的速度通过公式S/T计算大小。其中S为访问数据量,T为访问时间。
3.2.1 主服务器获取数据块
图9展示了原主服务器(noMIT)与引入MIT两种不同情况下,获取 1GB~10GB的数据共需要的时间。未引入索引树时,随着获取数据的增加,直线的斜率增大。这是因为获取数据的方法是通过逐一比对每张表内的〈TableId,objectkey〉二元组,内存访问延迟较高。当引入MIT时,吞吐量与时间呈线性关系,是因为在索引树叶子节点使用指针指向数据的地址,内存访问延迟很低。
3.2.2 快速恢复时间分析
为模拟快速恢复,采用蒙特卡罗算法随机生成一组1280×3条1~10的数据组成的矩阵,表示某台主服务器内1280个段,每个段随机备份在1~10号节点中的3个节点。每台备份服务器约含3840个段,空间占据30GB。
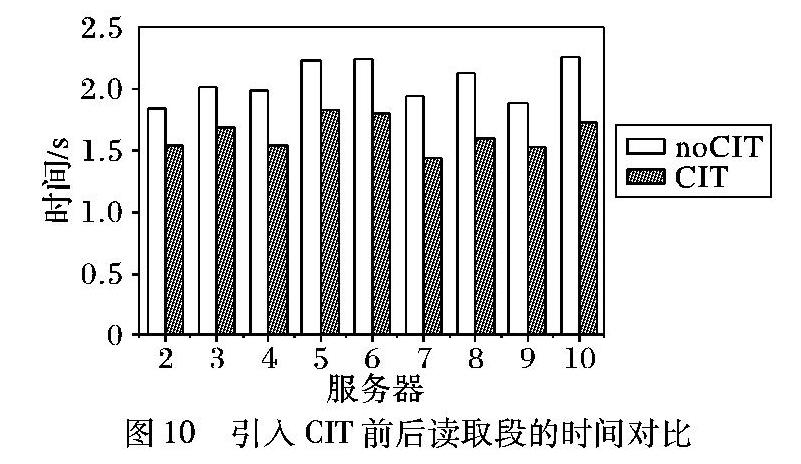
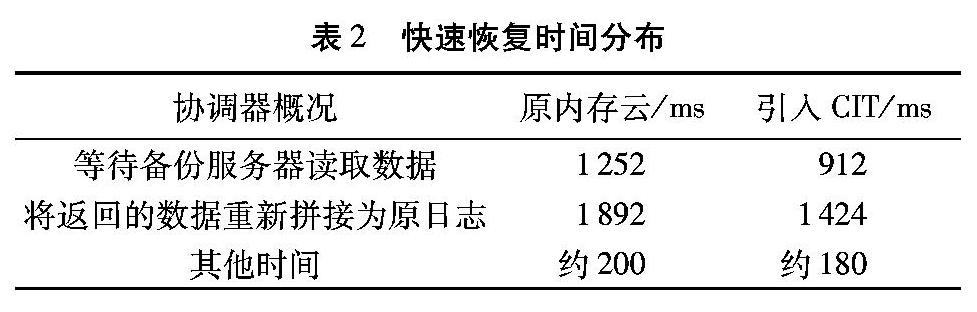
表2展示了恢复阶段协调器的时间概况。恢复过程中协调器节点首先等待从磁盘中返回的数据,随后将数据按崩溃前的顺序重新组织。通过表中的对比可以观察到:1)协调器闲散时间有效减少;2)重组段的时间有效减少。
实验3.2.2节的结果使备份服务器返回数据的时间提前,使协调器更早地获得要恢复的段。重组段时间减少是由于每个段含唯一的RGK,通过比对RGK的大小可以迅速重组崩溃的日志。
由于集群仅含有10个节点,每个节点需恢复的数据量大。一个集群含有节点一般来说在500~1000,数据随机备份在大量节点上恢复的时间也比较少。
4 结语
目前一些数据中心为快速获取数据都会采用在原有的数据格式中添加第二主键的方法,如MongoDB等,但这种方法是将数据的存储方式改为JavaScript对象表示法(JavaScript Object Notation, JSON)格式,加重了数据的负担。本文在内存云日志结构中添加了全局键,为获取、修改数据提供了另一种更高效的聚集索引方法,同时减少了快速恢复的时间。当然,全局索引大小上也存在局限性。当集群服务器超过两千台,或者段内的较小数据块没有经过合并算法合并,都会带来索引树占据内存过大等问题。对于超大内存云集群与其涵盖的海量数据,是否专门使用一组内存服务器搭建索引树则是一个新的需要探索的问题。
下一步将针对内存云架构,对备份服务器的存储方式进行新的探索与改进。通常段的存储是按照内存中的存储方式完全备份在备份服务器内的,按照以空间换取时间的研究思路,可将数据稀疏存储在空间足够充足的硬盘上。如何存放备份服务器的Hash表,如何设置Hash函数,仍然是下一步研究的重点。
参考文献:
[1]FOX A, GRIBBLE S D, CHAWATHE Y, et al. Clusterbased scalable network services[C]// Proceedings of the 16th ACM Symposium on Operating Systems Principles. New York: ACM, 1997: 78-91.
[2]ARMBRUST M, FOX A, GRIFFITH R, et al. A view of cloud computing[J]. Communications of the ACM, 2010, 53(4): 50-58.
[3]OUSTERHOUT J, AGRAWAL P, ERICKSON D, et al. The case for RAMClouds: scalable highperformance storage entirely in DRAM[J]. ACM SIGOPS Operating Systems Review, 2010, 43(4):92-105.
[4]BORTHAKUR D. The hadoop distributed file system: architecture and design[EB/OL].[20150505]. http://hadoop.apache.org/common/docs/r0.18.2/hdfs_design.pdf.
[5]RUMBLE S. Memory and object management in RAMCloud[D]. Stanford: Stanford University, 2014: 17-44.
[6]STUTSMAN R. Durability and crash recovery in distributed inmemory storage systems[D]. Stanford: Stanford University, 2013: 49-53.
[7]RUMBLE S, KEJRIWAL A, OUSTERHOUT J. Logstructed memory for DRAMbased storage[C]// Proceedings of the 12th USENIX Conference on File and Storage Technologies. Berkeley: USENIX, 2014: 1-16.
[8]CHANG F, DEAN J, GHEMAWAT S, et al. Bigtable: a distributed storage system for structured data[J]. ACM Transactions on Computer Systems, 2008, 26(2): 4.
[9]MITCHELL C, GENG Y, LI J. Using onesided RDMA reads to build a fast, CPUefficient keyvalue store[C]// Proceedings of the 2013 USENIX Annual Technical Conference. Berkeley: USENIX, 2013: 103-114
[10]KIM W, CHO I, MIN D, et al. Design of data backup on distributed memory system based on keyvalue store using hot/cold data management[C]// Proceedings of the 2014 Conference on Research in Adaptive and Convergent Systems. New York: ACM, 2014: 359-361.
[11]LAKSHMAN A, MALIK P. Cassandra: a decentralized structured storage system[J]. ACM SIGOPS Operating Systems Review, 2010, 44(2): 35-40.
[12]CHEN H, LU K, SUN M, et al. Enumeration system on HBase for lowlatency[C]// Proceedings of the 2015 15th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing. Piscataway, NJ: IEEE, 2015: 1185-1188.
[13]BAKER J, BOND C, CORBETT J C, et al. Megastore: providing scalable, highly available storage for interactive services[C]// Proceedings of the 5th Biennial Conference on Innovative Data Systems Research. [S.l.]: VLDB, 2011: 223-234.
[14]CORBETT J C, DEAN J, EPSTEIN M, et al. Spanner: Googles globally distributed database[J]. ACM Transactions on Computer Systems, 2013, 31(3): 8.
[15]吴军. 数学之美[M]. 北京:人民邮电出版社, 2012:142-152.(WU J. Beauty of Mathematics[M]. Beijing: Posts & Telecom Press, 2012:142-152.)
[16]ONGARO D, RUMBLE S M, STUTSMAN R, et al. Fast crash recovery in RAMCloud[C]// Proceedings of the 23rd ACM Symposium on Operating Systems Principles. New York: ACM, 2011: 29-41.
