
人的视觉行为识别研究回顾、现状及展望
2016-04-28 08:55单言虎黄凯奇
计算机研究与发展 2016年1期
单言虎 张 彰 黄凯奇
(模式识别国家重点实验室(中国科学院自动化研究所) 北京 100080)
(yanhu.shan@nlpr.ia.ac.cn)
人的视觉行为识别研究回顾、现状及展望
单言虎张彰黄凯奇
(模式识别国家重点实验室(中国科学院自动化研究所)北京100080)
(yanhu.shan@nlpr.ia.ac.cn)
Visual Human Action Recognition: History, Status and Prospects
Shan Yanhu, Zhang Zhang, and Huang Kaiqi
(NationalLaboratoryofPatternRecognition(InstituteofAutomation,ChineseAcademyofSciences),Beijing100080)
AbstractHuman action recognition is an important issue in the field of computer vision. Compared with object recognition in still images, human action recognition has more concerns on the spatio-temporal motion changes of interesting objects in image sequences. The extension of 2D image to 3D spatio-temporal image sequence increases the complexity of action recognition greatly, Meanwhile, it also provides a wide space for various attempts on different solutions and techniques on human action recognition. Recently, many new algorithms and systems on human action recognition have emerged, which indicates that it has become one of the hottest topics in computer vision. In this paper, we propose a taxonomy of human action recognition in chronological order to classify action recognition methods into different periods and put forward general summaries of them. Compared with other surveys, the proposed taxonomy introduces human action recognition methods and summarizes their characteristics by analyzing the action dataset evolution and responding recognition methods. Furthermore, the introduction of action recognition datasets coincides with the trend of big data-driven research idea. Through the summarization on related work, we also give some prospects on future work.
Key wordscomputer vision; action recognition; spatio-temporal motion; dataset evolution; survey
摘要人的行为识别是计算机视觉领域中的重点研究问题之一.相对于静态图像中物体识别研究,行为识别更加关注如何感知感兴趣目标在图像序列中的时空运动变化.视觉行为的存在方式从二维空间到三维时空的扩展大大增加了行为表达及后续识别任务的复杂性,同时也为视觉研究者提供了更广阔的空间以尝试不同的解决思路和技术方法.近年来,人的行为识别相关工作层出不穷,已成为计算机视觉研究中的热点方向.以时间为顺序,对从21世纪初至今约15年中出现的视觉行为识别研究方法进行了梳理、归类和总结.相比其他综述性文章,以不同时期人的行为识别数据库的演化为线索,介绍不同时期行为识别研究所关注的研究重点问题和主要研究思路,能更清晰直观地体现行为识别研究的发展历程.同时,以数据库演化历程为顺序介绍行为识别,能更好地呼应当前视觉领域愈来愈受人关注的大数据驱动的研究思路.通过对相关工作的梳理和总结,还对今后行为识别研究的发展方向做出展望,希望对各位研究者方向把握上提供一些帮助.
关键词计算机视觉;行为识别;时空运动;数据库演化;综述
自古以来,人类就利用自身的智慧,试图让机器代替人类劳动.尤其是第1台电子计算机的出现,使得人类可以有机会利用计算机完成更为复杂的计算任务.随着计算机技术的飞速发展,让计算机代替人类思考已经逐渐从梦想走进现实.如1997年IBM公司研制的深蓝计算机在国际象棋比赛中战胜了人类,在人工智能的发展史上记上了浓墨重彩的一笔.计算机视觉作为人工智能的重要组成部分,在人工智能的发展中起到了重要的作用.研究表明,人类从外界获取的信息中,视觉信息占各种器官获取信息总量的80%.“眼见为实,耳听为虚”、“百闻不如一见”等成语都反映了视觉信息对于了解事物本质的重要性.计算机视觉技术是研究怎样让计算机通过摄像机去获取外界的视觉信息,然后像人类一样知道“看”到的是什么,并且理解“看”到的东西在哪里、在“干”什么.因而,物体识别、目标跟踪和行为识别是计算机视觉研究的重要问题.
行为识别研究的主要内容是分析视频中人的行为.作为计算机视觉领域的重要研究问题,行为识别具有重要的科学意义.
相对于静态图像中物体识别研究[1],行为识别更加关注如何感知感兴趣目标在图像序列中的时空运动变化.视觉行为的存在方式从二维空间到三维时空的扩展大大增加了行为表达及后续识别任务的复杂性,同时也为视觉研究者提供了更广阔的空间以尝试不同的解决思路和技术方法.近年来,人的行为识别相关工作层出不穷,已成为计算机视觉研究中的热点方向.此外,研究人的行为对于研究大脑的视觉认知机理也具有重要的科学意义.很多行为识别方法从大脑认知的角度构建视觉行为的表达与计算模型,这类方法不仅可对大脑认知机理相关研究提供实验证明,还通过实验对认知科学进行反馈和促进.
除了重要理论意义外,行为识别同样具有重要的应用价值.随着硬件技术的发展,监控摄像头已经非常廉价,在物联网技术的推动下,监控摄像头已经无处不在.在广场、银行、学校、公路等公共场所,摄像头记录着人类生活的每个角落.尤其是近几年发生的恐怖事件,如伦敦地铁爆炸案、美国911事件、俄罗斯火车站爆炸案以及波士顿爆炸案,这些重大公共安全事件促使全球各国政府加大设备投入,在公共场所搭建大规模视频监控系统.据2007年英国《每日邮报》报道,约420万个摄像头覆盖在英国的各个角落,每个英国公民平均每天会出现在300个不同的摄像头录像中.传统的视频监控主要是靠人对摄像头捕获的信息进行观测,靠肉眼检测视频中的异常行为.研究表明,人眼在注视监控画面20分钟以后,注意力将严重涣散,画面中95%以上的视觉信息将被人眼“视而不见”.对于当今如此大规模的摄像头网络,人力已经无法胜任视频监控这一工作了.基于此,以计算机视觉技术为基础的智能视频监控系统应运而生.通过行为识别技术,计算机可以实时判断公共区域中行人、车辆等感兴趣目标的状态变化,自动识别其中的异常行为,从而实现对威胁公共安全的行为进行预警和主动防御.在公共安全领域以外,随着人们生活水平的提高,个体家庭中的安全防护问题也日益突出.借助网络的普及和发展,智能监控系统已经走入了千家万户.智能家庭监控系统在降低由一些危险行为(如入侵、盗窃、独居老人跌倒等)带来的生命财产损失的工作中起着关键性作用.
除此之外,基于视频的行为识别也是视频信息检索的关键技术.随着互联网技术的迅速发展,人类已经生活在一个信息化时代.网络传播速度的大幅度提升使得信息实现了全球化共享,如视频数据现在可以较快的速度在网络上传输、大量的国内外视频网站(如YouTube、Hulu、优酷等)纷纷涌现.据统计,用户每分钟通过YouTube网站上传的视频时长超过100 h.如此大规模的视频数据除了为我们带来丰富的信息共享外,也给存储和检索带来了巨大的挑战.由于上传用户对视频的文字描述过于简单,不足以描述视频中所蕴含的丰富内容,如何有效地对视频进行压缩而不损失用户感兴趣的内容、如何在文字描述不充分的情况下找到符合用户要求的视频,这些都是工业界和学术界所共同关注的问题.基于内容的视频压缩和检索技术利用行为识别方法检测视频中用户感兴趣的行为,可有效对视频进行压缩和索引标注.
另外,行为识别在人机交互中也发挥着重要的作用.近几年,随着人机交互技术的发展,人与计算机之间的交互方式已经有了长足的进步.从传统的按键式交互方式(如鼠标、键盘)发展到现在的触摸式交互(如触摸屏).然而这些交互方式都需要人与计算机接触才能达到操作的目的,而在现实生活中,人与人之间直接通过眼神或动作就可以达到简单的交互目的.为了实现人机之间的非接触式交互,人们利用手势和行为识别技术实现了人与计算机之间的信息传递.如微软XBox中结合Kinect深度传感器利用运动姿态识别技术实现了自然的人机交互和体感游戏.除此之外,很多公司也致力于研究眼球运动估计,利用眼球运动追踪实现人与机器(如手机)的交互.
可以看出,人的行为识别具有重大的研究和应用意义.因此,该研究领域受到了越来越多研究者的关注,主要体现在以下4个方面:
1) 大量的知名期刊,如IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI),International Journal for Computer Vision (IJCV),Computer Vision and Image Understanding (CVIU),IEEE Transactions on Circuits and Systems for Video Technology (CSVT),Pattern Recognition Letter (PRL)和Image and Vision Computing (IVC)等都分别开设了行为识别相关专刊,开设时间和题目如表1所示:

Table 1 Special Issues About Action Recognition
2) 近年来很多新的行为识别工作也愈来愈多地出现在计算机视觉和模式识别领域以IEEE国际计算机视觉大会(International Conference on Computer Vision, ICCV)、IEEE国际计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition, CVPR)和欧洲计算机视觉会议(European Conference on Computer Vision, ECCV)三大会议为代表的重要学术会议中.
我们统计了20多年来三大会议中与行为识别相关文章的数目,如图1所示,该图很直观地显示了行为识别相关研究呈明显的逐年上升趋势.
3) 为了让更多研究者了解行为识别,很多组织在一些重要的会议中进行了行为识别专题讲座,这些讲座追根溯源介绍了行为识别的发展以及未来的发展方向,很好地推动了行为识别领域的发展.
4) 为了促进行为识别的发展,该领域也出现了多个行为识别相关的竞赛,如美国国家标准技术研究所(NIST)从2008年起到现在一直开展的TRECVID监控场景下的事件检索[2]、CVPR2010年开展的行为识别竞赛以及由美国中佛罗里达大学(UCF)牵头的THUMOS大数据真实场景下的行为识别竞赛[3]等.这些竞赛不仅吸引了大量研究者对行为识别领域的关注,也极大地促进了该领域的发展.

Fig. 1 Articles about action recognition in the top-3 computer vision conferences (ICCV,CVPR,ECCV).图1 ICCV,CVPR和ECCV三大会议上行为识别相关论文统计

Fig. 2 Typical human action recognition datasets in recent years.图2 各个时期比较有代表性的行为数据库
目前,行为识别的研究者已撰写了一些行为识别相关的综述性文章[4-13],对行为识别领域的发展进行回顾和总结.这些文章对行为识别方法进行了不同角度的方法归类和介绍.一般来说,按照行为的复杂程度来划分,行为由简单到复杂可以分为姿态(gesture)、单人行为(action)、交互行为(interaction)和群行为(group activity).姿态和单人行为主要关注如何为行为主体本身的形态、位置变化建立模型;而交互行为和群行为的研究重点是如何刻画更大时空尺度中行为主体与场景物体或行为主体之间的空间、时间和逻辑关系.本文前2类简单行为相关工作被称为行为识别方法,而后2种复杂的行为识别方法被称为事件分析方法.
本文以时间为顺序,以数据库的发展历程为线索,对不同时期的行为识别方法进行归类.公开的行为识别数据库对行为识别方法的评测起到了关键的作用,也为研究者们提供了一些研究规范.行为识别数据库的更新和发展在行为识别领域起到了方向标的作用.每一个优秀的行为识别数据库被发布,都会伴随着大量的新的行为识别方法的提出.
图2展示了2001—2014年一些引用较高被广泛使用的公开行为识别数据库.
早期的行为数据库(如KTH[14]和WEIZANN[15]等)主要的出发点集中在对一些基本行为识别上.这些行为数据大多都是在可控场景下进行的单人行为,行为类别与样本数量都比较少.很多经典的行为识别方法如文献[16-19]等都在这些数据库中进行了验证.这些简单的行为数据库对于我们从计算机视觉角度去了解行为表达的本质做出了巨大的贡献,这些数据库现在仍然作为行为识别的基线数据被广泛地使用.
随着研究者对行为识别方法认识得不断深入,一些特定问题被提了出来.为解决视角不变问题,法国国家信息与自动化研究所(French Institute for Research in Computer Science and Automation, INRIA)和中国科学院自动化研究所(Institute of Automation, Chinese Academy of Sciences, CASIA)等一些研究机构发布了多视角的行为数据,如IXMAS Actions[20]数据库、CASIA[21]行为数据库.针对此类数据库,有些方法[22-24]通过利用多个视角信息的互补性来提高行为的表达能力;也有些工作[25-26]则是对不同视角之间的行为特征迁移进行学习,以获得一个更为泛化的特征表达.
前面提到的包括多视角在内的行为数据库中,行为类别主要是单人简单行为,场景相对比较简单和单一;但在真实生活的视频里,行为类别是非常丰富的,并且影响行为在视频中表达的因素也非常多,如视角、光照,摄像机运动、环境变化等.对此,网络及多媒体视频由于其更为自然真实,并且具有海量、多样、易获取等特点,成为行为识别数据库的又一重要来源.用户上传的海量视频数据为我们提供了大量真实生活中的行为素材.基于此,在2008年和2009年,有很多真实场景下的行为数据库被发布,如Hollywood[27],UCF Sports[28],UCF YouTube[29]等.
除网络多媒体视频外,还有一些研究者通过模仿真实场景(考虑复杂的运动背景)构建了诸如MSR Action[30]和Collective Activity Data[31]等行为数据库.由于局部特征对于视角和光照等变化具有很好的鲁棒性,基于局部特征点的行为识别方法[14,32-36]在这类真实场景数据库中得到广泛的应用.
自2010年以来,随着计算机视觉的发展,行为识别数据库也呈现出新的特点:
1) 行为识别数据库的规模越来越大.自2009年开始,随着“大数据”在互联网信息行业被推向高潮,计算机视觉领域也出现了以ImageNet[37]图像库为代表的超大规模数据库.虽然当前行为识别数据库的规模还远远不及图像识别数据库,但其行为类别和样本数量也在迅速增加.Hollywood2在原有Hollywood数据库的基础上将行为类别从8类提升到12类,视频样本也从430个增加到2 859个.美国中弗罗里达大学(UCF)计算机视觉研究中心将UCF Sports,UCF YouTube等一些数据库进行融合和扩展,构成了一个50类共6 680个视频片段的UCF50[38]行为数据库.不久前,规模更大、包含101个行为类别的UCF101[3]行为数据库也应运而生.除此之外,布朗大学的SERRE实验室构建了包含51类行为共6 849个视频片段的HMDB[39]行为数据库.英国Kingston大学和西弗吉尼亚大学分别发布的多视角行为数据库采用8个视角的摄像机同时对一个行为进行拍摄,行为类别也从IXMAS Actions的13类增加到了17类.
2) 除数据库规模的增加,行为识别数据库在近期的另外一个特点是多样化.行为识别从简单的单人行为上升到了多人的交互行为。如2010年发布的监控场景下的UT-Interaction[40]数据库,其研究内容是多个目标之间的交互行为.另外,借助传感技术的发展,MSR先后发布了MSR Action 3D[41]和MSR Daily Activity 3D[42]行为数据库,这2个数据库利用KinectRGB-D传感器获取除彩色图像以外的人体深度图像序列,利用Kinect采集的深度数据可获取较为精准的人体关节点骨架序列,这些包含深度和骨架结构的视频序列为深入研究人体的运动模式提供了很好的研究数据.美国西北大学和加州大学洛杉矶分校则将深度、骨架和多视角数据融合在一起构建了Northwestern-UCLA Multiview Action 3D[43]数据库.为了更好地研究人体运动过程中各个关节点的运动规律,CMU Graphics Lab利用8个红外摄像头对带有41个标记点的人体进行重构,更为精确地估计出人体的骨架结构,并发布了CMU Motion Capture[44]行为数据库.除此之外,随着穿戴式智能设备(如Google Glass)的发展,近几年来也出现了一些第1人称视角的行为数据库,如H.Pirsiavash构建的第1人称视角下的Activities of Daily Living (ADL) Dataset[45]和佐治亚理工发布的First-Person Social Interactions[46]数据库.
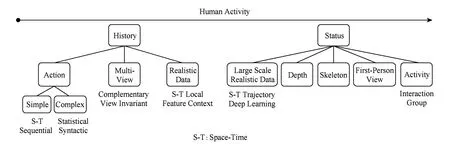
Fig. 3 Taxonomy of human action recognition.图3 行为识别分类框架
通过对行为识别数据库的介绍可以看出,在行为识别研究前期,研究对象主要是在简单场景下的单人行为,行为类别比较少,场景比较简单.针对这些数据库中的行为,研究者们提出的行为识别方法大多集中在单人简单行为的表达.在这段时间,出现了一些基于序列和基于时空体的经典行为识别算法,为后期相对复杂的行为识别打下了坚实的基础.在后期的行为识别中,研究对象相对比较复杂.除了从单人发展到多人、场景更为复杂外,数据库的规模逐步扩大,数据类型也随着计算机视觉及硬件技术的进步变得更加多样化.基于此,我们按时间顺序将行为识别方法分为早期和近期2部分,分别对不同阶段的行为识别方法进行综述性介绍,通过分析不同阶段行为识别方法的差异来了解行为识别这一领域的发展趋势.图3为整个行为识别分类的框架:首先,2001—2009年这段时间的行为数据库主要是用来研究可控环境及规模较小的真实环境下的行为分析方法,本文将在这些数据库上进行研究的方法归为早期行为识别方法.这段时间的行为识别方法按照行为表达方式的不同,可以分为一般行为识别、多视角行为识别和真实场景下的行为识别.然后,2010—2014年发布的行为数据库则着重于与实际应用相结合,在这些数据库上进行研究的方法在本文中被称为近期行为识别方法.按照数据类型的不同,这些方法可以分为大数据真实场景下的行为识别、基于深度图像序列的行为识别、基于骨架序列的行为识别、基于第1人称视角的行为识别以及多人交互行为识别.本文将按这种分类方法对行为识别的相关工作进行介绍.
1一般行为识别方法
一般行为识别方法的研究对象是包含一个简单行为(如走、跑、挥拳等)或由这些简单行为组合而成的复杂行为(如徘徊、打架)的视频.按照行为复杂度,一般行为识别方法可以分为简单行为识别方法和复杂行为识别方法.
1.1简单行为识别方法
对于相对简单的行为,即手势和单人行为,这类行为通常被看作是一个物体在时间序列中的动态变化,因此,这类行为可以直接通过对图像序列进行分析来达到行为识别的目的.简单的行为识别方法主要包括时空体模型方法和时序方法2类.
1) 时空体模型(space-time volume model)方法

Fig. 4 MEI and MHI[16].图4 运动能量图和运动历史图
基于时空体模型的方法是将一个包含行为的视频序列看作在时空维度上的三维立方体,然后对整个三维立方体进行建模.如Bobick等人[16]利用人体在三维立方体中沿时间轴进行投影,构造了运动能量图和运动历史图,然后利用模板匹配的方法对行为进行分类.图4给出了不同行为的运动能量图(motion energy image, MEI)和运动历史图(motion history image, MHI).从图4可以看出,运动历史图可以看作是人体在三维立方体中沿时间轴的加权投影,该投影不仅能反映出运动物体的姿态,还包含了不同姿态的时序性信息.为了能在更复杂的场景下对人的行为进行识别,Ke等人[17]利用层级的均值漂移算法对时空立方体进行分割并自动找到人的行为对应的时空区域,然后利用该部分时空区域对人的行为进行建模.此类将行为作为一个整体进行建模和分类的方法比较直观,对于识别一些简单场景的行为比较有效;但对于复杂场景的行为,由于光照、视角以及动态背景等因素的影响,此类方法的有效性将大大降低.表2列出了基于时空体模型的行为识别方法.
Table 2Space-Time Volume Model Methods for Action
Recognition

表2 基于时空体模型的行为识别方法
2) 时序方法
基于时序的行为识别方法是将视频中的行为看作人体的不同观测姿态的序列,通过分析行为的时序变化来提升行为的表达能力.此类方法可简单地分为基于模本的方法和基于状态的方法2种.
① 模本(exemplar).基于模本的方法把行为表达为一个模板序列,通过把新的图像序列特征和模板序列特征进行比较来进行行为识别.当它们的相似度足够高时,系统认为输入图像序列包含模板序列对应的行为.人们做同样的行为可能有不同的风格和速度,因此计算相似度时需要考虑这些因素.早期语音识别方法中的动态时间归整(dynamic time warping, DTW)算法被广泛用于匹配2个有变化的序列[50-51],DTW算法能够在2个序列之间寻找一个最优的非线性匹配.图5展示了匹配2个不同速度序列的DTW的概念.

Fig. 5 Exemplar-based action recognition with DTW.图5 基于模本DTW匹配的行为识别方法
② 状态(state).基于状态的方法把一种行为表示为由一组状态组成的模型.该模型经过统计方法训练得到,对应属于该行为的一组特征向量序列.对每个模型,它生成观测特征向量序列的概率是通过测量行为模型和输入图像序列之间的似然度计算得到的.使用最大似然估计(maximum likelihood)或者最大后验概率(maximum posteriori probability)分类器来进行行为识别.隐Markov模型(hidden Markov model, HMM)和动态贝叶斯网络(dynamic Bayesian networks, DBN)被广泛用于基于状态的方法[52-55],这2种方法都把行为表达为一组隐状态.假设人在每帧都处于一个隐状态,每个状态会根据观测概率生成一个观测向量(例如特征向量).在下一帧,系统根据隐状态之间的转移概率转移到另一个状态.一旦转移概率和观测概率经训练过程获取后,行为识别的测试过程就是计算一个给定状态模型生成输入序列的概率.如果这个概率足够高,就能够确定该状态模型对应的行为在输入序列里发生了.图6给出了一个序列HMM的示例.DBN是HMM的一个扩展,由多个在每帧直接或者间接生成观测的条件独立的隐节点组成.基于时序的行为识别方法能够通过概率图模型帮助我们更好地理解行为的内在时序、因果结构,因此,这类方法具有很好的发展前景.现在制约这类方法的关键是对单帧图像的表达.怎样获得更好的人体结构表达和确定关键状态的个数是影响这类方法性能的关键,同时训练数据的规模和多样性对模型的泛化能力影响巨大.表3列出了基于序列的行为识别方法.

Fig. 6 HMM-based state transition model for action recognition.图6 基于HMM状态转移模型的行为识别方法
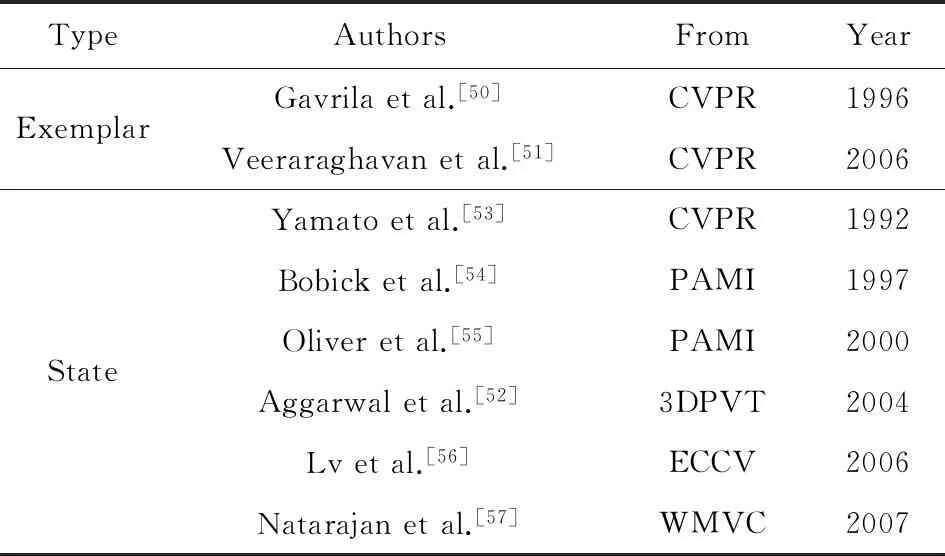
TypeAuthorsFromYearExemplarStateGavrilaetal.[50]CVPR1996Veeraraghavanetal.[51]CVPR2006Yamatoetal.[53]CVPR1992Bobicketal.[54]PAMI1997Oliveretal.[55]PAMI2000Aggarwaletal.[52]3DPVT2004Lvetal.[56]ECCV2006Natarajanetal.[57]WMVC2007
1.2复杂行为识别方法
对于一些由多个简单行为组合而成的相对复杂的行为,由一般行为识别方法是无法对此类行为进行识别的.这类行为识别的思路是先识别容易建模的简单的子行为,在此基础上再识别高层的复杂行为.这些子行为可能被进一步分解为原子行为,因此,复杂行为识别方法常出现层级现象.经典的复杂行为识别方法可以分为统计模型方法和句法模型方法.
1) 统计模型(statistical model)
统计模型使用基于状态的统计模型来识别行为,子行为被看作概率状态,行为被看作这些子行为沿时间序列转移的一条路径.底层的一些子行为可以通过上面提到的时序方法进行识别,这些子行为进一步地构成了一个高层行为序列.在高层的模型中,每一个子行为在这个序列中作为一个观测值.Nguyen等人[58]以及Shi等人[59]等利用HMM对子行为序列建模来进行复杂行为识别;Damen等人[60]则利用子行为构建DBN(动态贝叶斯网络)来实现复杂行为的识别问题.利用HMM和DBN模型可以很好地对子行为序列进行建模,但对于描述一些具有空间关系的子行为,即子行为之间存在着时间的重叠,直接利用这2种模型则无法对复杂行为进行描述.为了能够更好地描述复杂行为中子行为之间的相互关系,Tran等人[61]利用一定的先验知识构建了Markov逻辑网络(Markov logic networks, MLNs)来对子行为之间的时空关系进行描述.
2) 句法模型(grammar model)
句法模型把子行为看作一系列离散的符号,行为被看作这些符号组成的符号串.子行为可以通过上面提到的时空或时序方法进行识别,而复杂行为可以用一组生成这些子行为符号串的生成规则来表示,自然语言处理领域的语法分析技术可以被用来对这种生成规则进行建模,从而实现对复杂行为的识别.这一类基于语法分析技术构建的模型被称为句法模型,常用的有上下文无关语法模型(context-free grammars, CFG)和上下文无关的随机语法模型(stochastic context-free grammars)[62-63].一般的句法模型也只能识别子行为序列构成的复杂行为,对于处理同时发生的子行为则无能为力.为了克服这个局限,Ryoo和Aggarwal[64]在CFG的基础上加入了描述子行为之间复杂时空关系的逻辑连接,即and,or和not,使得构建的句法模型可以解决子行为共同发生的问题.
表4列出了本文引用的复杂行为识别方法:

Table 4 Complex Action Recognition Methods
2多视角行为识别
在多视角的视频数据库中,如图7所示,主要存在2种研究方式:1)利用多视角下数据的互补性对行为进行表达和识别;2)通过分析多个视角下行为表达之间的联系来学习行为特征在多个视角下的转移过程,从而得到更为鲁棒的行为表达.基于这2种研究方式,我们将多视角行为识别分为多视角互补(multi-view information complementary)行为识别和视角不变(view invariant)行为识别.
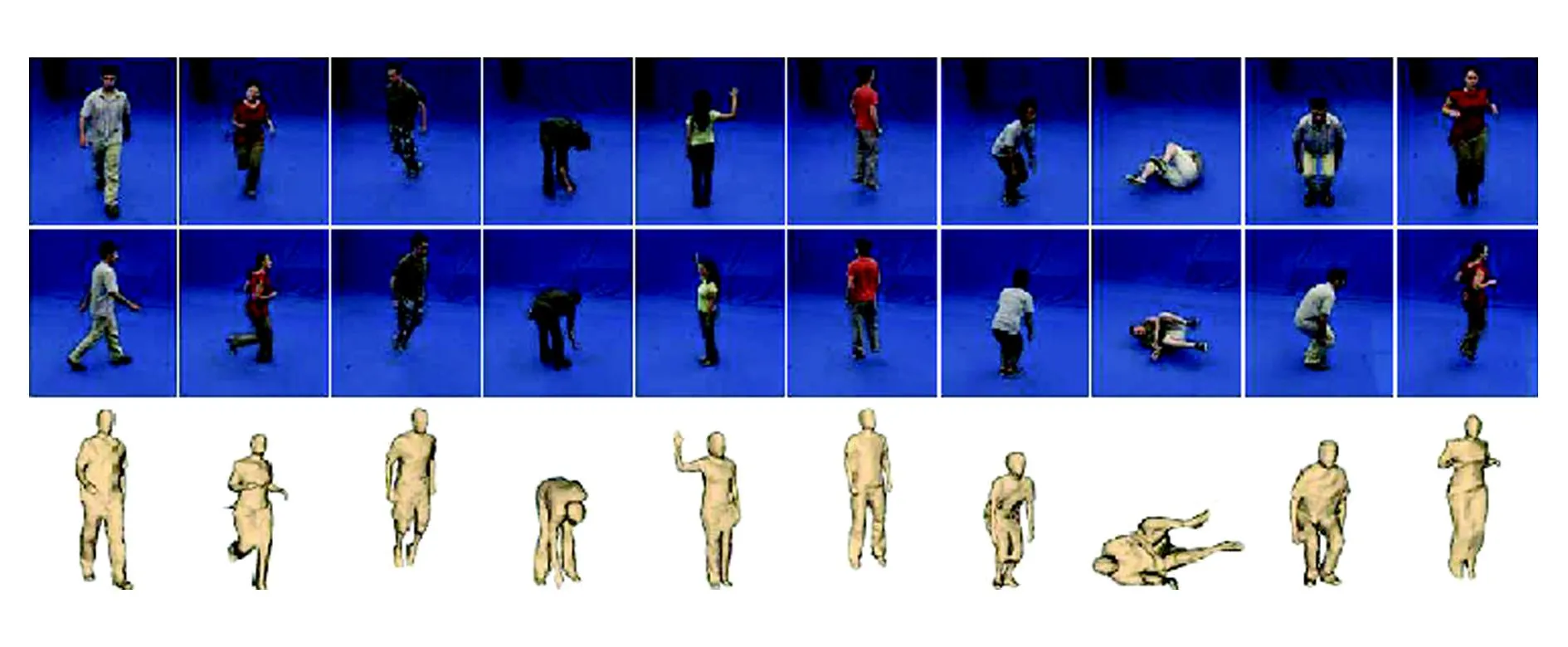
Fig. 7 Images and 3D objects in i3DPost multi-view action dataset.图7 i3DPost多视角行为数据库的图像和三维前景
1) 多视角互补的行为识别
多数行为识别方法只是在单个视角下对行为进行分析,这里面存在一个非常强的假设,即由单个视角提取的底层特征足以描述更高层次的行为.但事实上,单个视角的图像序列存在着自遮挡,人体只有部分的表观数据是可用的,因此,当人体的行为朝向发生变化时,图像序列中表观数据的巨大差异会导致行为无法正确识别.为解决这个问题,很多研究者提出了多视角的行为识别方法,通过分析人体行为在不同视角下的互补特征来对行为进行更为完整的表达.Huang等人[22]利用来自2个正交的摄像机的图像序列中的物体轮廓来提取一种形状表达.Bui等人[23]通过构建抽象的HMM对来自不同角度的空间位置信息进行层级编码,然后在每一层对行为进行更为精细的描述.还有一些方法通过多视角图像构建三维前景,如图7所示,然后对三维前景序列进行行为特征表达.如Huang等人[24]利用颜色信息构建前景的轮廓直方图对三维前景进行表达,然后通过模板匹配的方式对视频序列进行识别.
2) 视角不变的行为识别
虽然利用多视角的互补信息可以对行为进行更为完整的表达,但在实际监控场景下,一般只有一个摄像机在某一时刻记录了人的行为,但由于视角的不同,在不同的摄像机视野下同一行为的表观特征是不同的.为了学习视角不变的行为特征,很多研究者利用多视角下的行为数据进行跨视角行为识别.在文献[25]中,Souvenir等人通过计算轮廓的R变换并利用流形学习来对行为进行视角不变的特征表达.Gkalelis等人利用离散傅里叶变化(discrete Fourier transform, DFT)的循环转移不变性,并结合模糊矢量化(fuzzy vector quantization, FVQ)和线性判别分析(linear discriminant analysis, LDA)的方法对行为进行表达和识别.对于视角不变的行为表达方法,文献[26]有较为详细的综述性介绍.表5列出了多视角行为识别的相关方法.
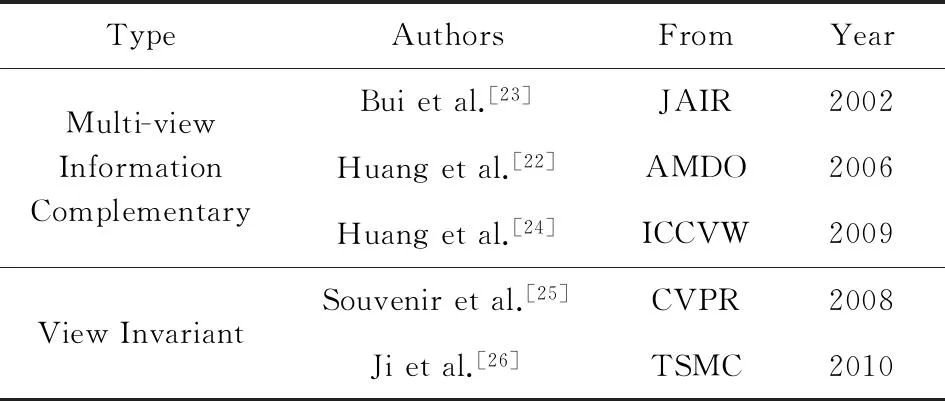
Table 5 Multi-view Action Recognition Methods
3真实场景下的行为识别
相对简单场景下的行为,在真实场景中的行为由于存在大量的遮挡、光照变化以及摄像机运动等影响,使得提取真实场景下的前景信息非常困难,用基于前景的行为表达方法来对这类行为进行识别达不到令人满意的效果.为了获取更为鲁棒的行为表达,受局部特征在图像识别领域成功的启发,很多方法试图从时空立方体的局部出发,获取更多的时空局部特征(local feature).局部特征可以通过构建三维时空滤波器的方式快速地提取时空立方体中的兴趣点,如图8所示,这些底层的时空局部兴趣点(space-time interest point, STIP)具有旋转和尺度不变性,可以很好地提高行为识别方法的鲁棒性.基于局部特征的行为识别方法首先构建兴趣点检测子,如Harris3D检测子[32]、Cuboid检测子[33]和Hessian检测子[34]检测感兴趣点;然后构建局部特征描述子,在兴趣点周围提取表观和运动信息形成局部特征向量,如Cuboid描述子[33]、HOG3D描述子[35]、HOGHOF描述子[32,66]和ESURF描述子[34].此类方法可以直接与词袋模型(bag of words, BoW)结合得到局部特征视觉单词的直方图特征,将该直方图特征作为最终的行为特征送入分类器进行分类学习[14].
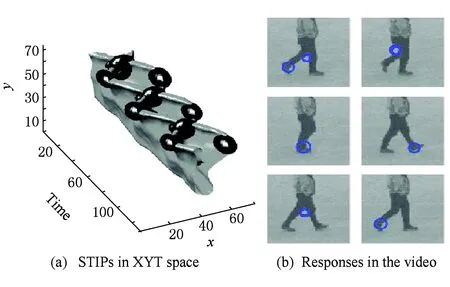
Fig. 8 STIPs of action walk[31]. 图8 行为walk中的时空局部兴趣点.
基于简单词频统计的BoW模型由于丢失了特征点在视频中的空间分布信息,使得单纯的基于特征点统计的行为特征欠缺对行为内在整体结构的表达.为了解决这个问题,Kovashka和Grauman[67]利用时空上下文(context)信息挖掘出时空局部特征点紧邻之间的显著形状,然后利用该形状作为较大尺度的局部特征,并以此往上逐层进行学习,利用得到的不同层次的特征结合BoW模型进行行为表达.Hu等人[68]利用局部特征点周围的近邻特征点构建局部直方图,然后用该直方图对特征点进行特征表达以提高特征点的中层表达能力.一些其他的方法[69-72]也通过利用时空上下文关系获取更为显著的特征表达.
虽然时空上下文可从一定程度上提高局部特征点的全局性表达能力,但只靠上下文是无法真正对行为的全局进行描述的.受二维图像中物体表达方法的影响,一些研究者将图像中的基于部件模型(deformable part-based model)[73]的物体表达从二维图像空间扩展到三维时空空间,对行为进行表达.Wang和Mori[19]利用全局和局部的运动特征结合隐状态随机场构建行为的部件模型.Xie等人[74]利用部件模型对每一帧的人体进行表达,然后将这些部件特征延时间方向串联起来作为行为的表达.Tian等人[75]则直接将文献[73]在三维空间进行扩展,构建了时空可形变部件模型.
表6列出了一些基于局部特征的真实场景下的行为识别方法:
Table 6Local Feature Based Action Recognition Methods in
Realistic Scenes

表6 基于局部特征的真实场景下的行为识别方法
4大数据真实场景下的行为识别
基于局部特征点的行为识别方法虽然可以通过加入时空上下文信息来提升局部特征的表达能力,但由于时空局部特征点本身包含大量的噪声,这决定了基于局部特征点的行为特征的表达能力是有限的.另外,由于真实场景的复杂性,以及数据量的增加所带来的巨大的行为类内差,使得基于部件模型的行为表达也受到限制.为了获取更具表达性和区分性的行为表达,研究者利用行为的时序性信息和卷积神经网络(convolutional neural network, CNN)的自学习机制提出了基于时空轨迹(space-time trajectory)和深度学习(deep learning)的行为识别方法.
1) 时空轨迹
该方法是时空局部特征点方法的扩展,通过跟踪运动物体的关键点来构建更具有表达能力的时空局部轨迹特征.Messing等人[76]结合局部特征检测方法提出了基于局部兴趣点轨迹的行为识别方法.该方法利用Harris3D检测子检测时空兴趣点,然后利用KLT跟踪器[77]跟踪这些兴趣点以获得轨迹.更进一步地,Wang等人[78]为了获得更稠密的轨迹,在每帧中稠密地采样很多特征点,然后利用光流场对这些特征点进行跟踪.在得到原始的特征点轨迹后,这些方法一般会加入一定的约束来对轨迹进行筛选和优化,然后利用轨迹周围的表观信息以及轨迹之间的时空信息对每个轨迹或是多个轨迹进行表达.其中,基于稠密轨迹的行为识别方法在很多公开的真实场景行为数据库中都达到了最好的结果.
2) 深度学习
深度学习模型是受人脑的认知机理启发利用底层特征来学习事物高层抽象的层级式特征.深度学习方法通过构建具有分析学习能力的层级式神经网络来对数据进行解释,该方法已经在大数据下的图像分类与检测、语音识别以及文本分类等领域取得了最好的结果.CNN是生物启发式深度学习模型的一种,也是在图像识别和语音识别中比较常用的模型.CNN是一种前馈人工神经网络,包含多个卷积层,该网络利用局部感受野、权值共享以及空间聚合(pooling)来实现位移、尺度、形状不变的特征表达.Ji等人[79]对二维图像中的CNN作扩展,通过对多帧的局部时空体做卷积来构建一个三维CNN.该方法是深度学习模型在行为识别领域中的一次很好的尝试,在一些真实场景数据库中也取得了不错的效果.Karpathy等人[80]等利用慢融合模型(slow fusion model)对视频中不同的图像帧进行融合,构建图像序列的CNN模型,如图9所示.通过这种融合方式,可以有效地将视频的时序性信息加入到网络中,用于提高行为特征的表达能力.

Fig. 9 Different temporal fusion methods in CNN[80].图9 CNN网络中不同的时序融合方法

Fig. 10 Fusion of space-time CNN[81].图10 时空CNN融合

Fig. 11 Trajectory feature extraction based on CNN[82].图11 基于CNN的时空轨迹特征提取方法
而Simonyan等人[81]则分别对单帧图像和多帧的运动信息(光流)分别构建2个CNN网络,然后在分数层上对2种网络的输出作融合,如图10所示,进而提升特征的表达能力.Wang等人[82]结合时空轨迹和CNN,提出了利用CNN对轨迹进行特征表达的方法,极大地提高了行为特征的表达能力,如图11所示.实验表明,这种融合方法在UCF101和HMDB51两个大数据下的真实场景行为数据库中均达到了深度学习模型所能达到的最好结果.表7列出了大数据真实场景下的一些行为识别方法:

Table 7 Large Scale Realistic Action Recognition Methods
5基于深度图像序列的行为识别
相比一般的投影视觉数据,深度图可以提供一个光照不变的具有深度几何结构的前景信息,如图12所示:

Fig. 12 Two depth action image sequences[41].图12 2种行为的深度图像序列
然而,由于深度相对彩色图片来说包含较少的纹理信息,并且深度数据中常常伴有大量噪声,这使得直接使用一般的特征描述方法(如梯度)对深度图像序列进行描述不能取得令人满意的效果.针对深度数据的优势和问题,很多研究者提出了不同的深度图像序列表达方法用于行为识别.类似于上文简单行为识别方法,按照对深度图像序列处理方式的不同,深度图像序列的表达也可分为时空体模型和时序方法2种.

Fig. 13 DMM behavior feature description based on depth image sequence data[86].图13 基于深度图像序列的DMM特征表达
1) 时空体模型.基于深度图像序列的时空体模型主要是将深度图像构成的四维数据作为一个整体,通过提取包含时空和深度的特征对行为进行表达.Li等人[41]引入了bag-of-points的思想,用少部分从深度图像中提取的三维点来描述身体的显著姿态,然后结合图模型框架利用这些显著姿态构建一个行为图(action graph)来对行为进行表达.该方法用1%的三维点即可在MSR Action3D数据库中达到90%的识别率.虽然此方法非常高效,但由于缺少对时空点之间上下文信息的描述,使得该方法应对处理深度数据中遮挡、噪声以及多视角等问题比较困难.为了解决这个问题,Vieira等人[85]提出了一种称为时空占有模式(space-time occupancy patterns)的特征表达方法.该方法通过将深度图像序列沿空间轴和时间轴划分来构建一个四维网格,然后利用网格中时空块之间的时空上下文关系构成时空占有模式.通过这种方法可以很好地解决深度图像序列中的遮挡和噪声问题,降低行为特征的类内差.Yang等人[86]对相邻帧深度图沿不同的方向投影做差值构建深度运动图(depth motion maps, DMM)来表达深度图像序列的时序信息,如图13所示.通过提取各种角度DMM中的HOG特征,并将整个序列中所有的HOG特征串联起来对行为进行表达.Oreifej和Liu[87]则通过统计深度图形序列中的四位法向量来对行为进行表达.除此之外,Zhang等人[88]则对时空局部特征描述子进行了扩展,分别提出了一种时空和深度的四维局部特征描述子对行为进行表达.
2) 时序方法.基于序列的深度数据行为表达方法的主要思想同1.1节对简单行为识别中的序列方法一样,通过对每一帧的深度图像进行特征表达,然后对构建这些特征之间的状态转移模型.Jalal等人[89]对深度图像轮廓进行R变换得到前景轮廓更紧致的特征表达,然后通过对特征进行主成分分析(principal component analysis, PCA)降维,并利用HMM构建各时刻轮廓特征的状态转移模型.
表8列出了基于深度图像序列的相关行为识别方法:

Table 8 Action Recognition Methods on Depth Image Sequence
6基于骨架序列的行为识别
在行为表达过程中,空间信息来源于了物体的姿态,而运动信息则反映在时间空间中.因此,时间的动态信息对于行为表达至关重要.为了更好地描述行为的运动信息,一些方法单独对骨架序列进行分析.骨架序列提供的主要运动信息反映在骨架节点沿时间轴连接在一起形成的轨迹曲线.节点的轨迹由于能够在更大的时间范围内对行为的动态信息进行描述,因此可以有效地提高行为的表达能力.基于骨架节点轨迹的行为识别方法由来已久.早在1973年,Gunnar[90]就通过如图14所示的MLD(moving light display)实验在黑色背景中人的骨架关节点处贴亮点来获取关节点的运动轨迹数据.这些在单个图像中看似毫无意义的亮点在动态图像序列中通过相互运动能够明显地表达人的各种动作.这些数据抛开了所有的运动获取技术对前景带来的噪声,给研究者提供了更好的空间来单独研究运动的模式.Campbel和Bobick[91]通过将一个行为的轨迹映射为一个相空间中的一条线,通过对相空间中曲线的划分来进行行为的识别.这类方法由于对轨迹的描述比较简单,所以只能识别一些很简单的行为,但是这个工作展示了时空轨迹方法的潜力.Sheikh等人[92]通过将如图15(a)中16个关节点轨迹进行仿射投影得到如图15(b)中所示的归一化的XYT空间中的轨迹.通过构建不同样本轨迹之间的视角不变相似度来实现行为的识别.

Fig. 14 MLD[90] experiment.图14 MLD实验
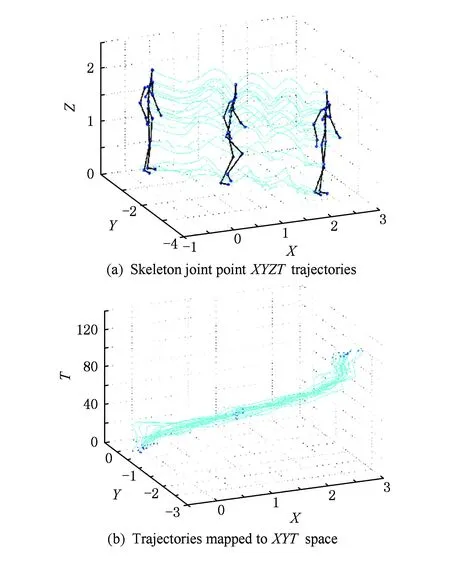
Fig. 15 XYZT skeleton trajectories[91].图15 XYZT关节点轨迹
Lv等人[57]对每个关节点的轨迹学习一个HMM作为弱分类器,然后利用Adaboost方法将这些弱的分类器组合在一起构成一个强分类器来达到行为识别的目的.与之前的方法相比,Lv提出的方法能够更好地利用HMM描述各个节点在时间轴上的变化.以上方法都是利用一些通过运动捕获系统(motion capture system)获取的,但在现实应用中,获取RGB图像的关节点需要用到前景提取、姿态估计和跟踪等相关技术,因此精度不能得到很好的保证.随着硬件技术的发展,一些运动捕获系统如文献[93]可以利用深度摄像机(如Kinect)提供的深度信息精确地估计出人体骨架.基于此,Zhao等人[94]提出了一种基于轨迹的实时手势识别方法.该方法利用文献[93]中的方法估计出深度图像序列的关节点轨迹,结合各个关节点随时间变化的距离,利用BoW对行为进行描述,然后利用DTW的方法实现行为的在线识别.Xia等人[95]提出了一种Histogram of 3D Joint Locations (HOJ3D)的骨架描述方法,通过K-means学习出这些骨架的姿态视觉词典作为不同时刻骨架的状态,然后结合HMM模型对行为进行识别.
除此之外,也有一些同时使用骨架信息和深度信息的方法.如Wang等人[96]同时使用骨架和骨架节点周围的深度点学习由不同节点特征构成的actionlet模型,然后,通过多核学习对不同的actionlet特征进行融合和分类.
表9列出了一些已发表的基于骨架的行为识别方法:
Table 9Skeleton Sequence Based Action Recognition Methods
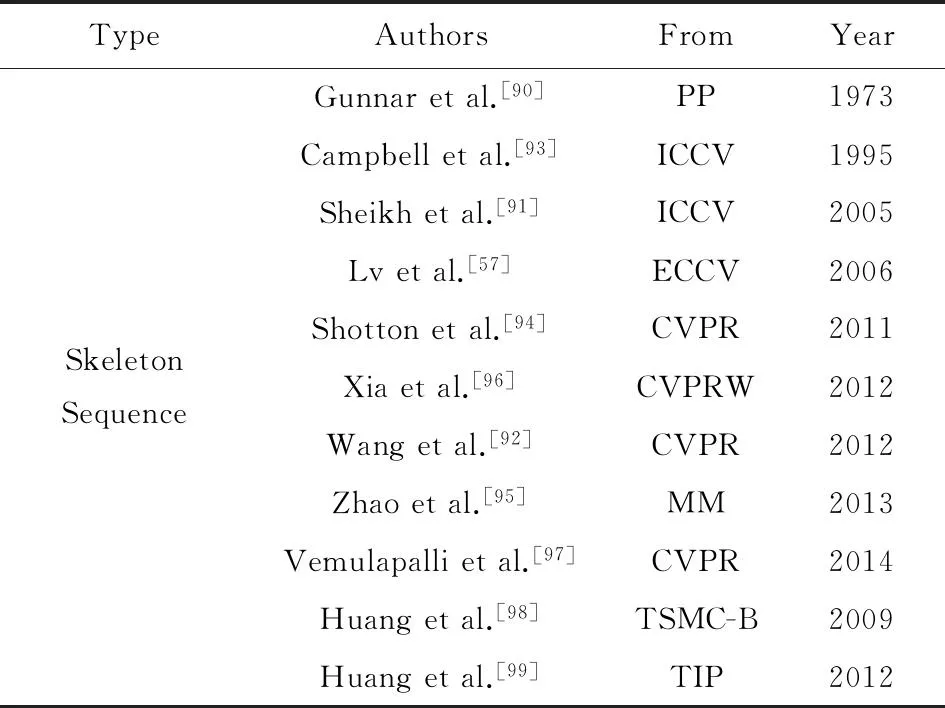
表9 基于骨架序列的行为识别
7第1人称视角下的行为识别
第1~6节介绍的行为识别方法都是对一般摄像机拍摄的行为视频进行特征表达和分类学习.随着穿戴式智能设备的兴起,我们可以随时记录日常生活中的时间,为我们带来了很多的视频素材.摄像机除了记录外界发生的情况以外,也记录了佩戴者本身的行为动作,如倒水、做饭或者跑步等.基于第1人称视角的行为识别方法主要是利用物体检测和手势识别技术,结合场景理解和语义理解等方法对第1人称视角下的行为进行识别.通过挖掘来自第1人称视角下行为动作所包含的固有物体、手以及物体运动的信息,Fathi等人[100]构建了一种层级模型用于行为识别,通过物体与手之间的交互行为进行表达,可以很好地反映出运动主体的行为.Pirsiavash等人[101]分别对物体图像和物体与手势共同出现的图像进行建模来区分运动主体与物体的交互,然后结合时间金字塔模型来对运动主体在日常生活中的行为进行特征表达.为了判别更复杂的第1人称视角下的运动行为,Kitani等人[102]提出了一种非监督的学习方法,使用Dirichlet过程混合模型自动学习第1人称视角视频中的运动直方图词典和不同的行为类别集.利用该方法可以非常有效和快速地对第1人称视角下的行为进行识别.以上的第1人称视角下的行为都是描述行为主体在干什么,而Ryoo等人[103]则研究在第1人称视角下别人对观察者做了什么的问题上提出了自己的方法.该方法分别提取了视频中的全局运动表达和局部运动表达来分别描述观测者和交互者的运动信息,然后利用多通道核方法对这2种描述进行融合,并提出一种可以准确学习行为结构的核方法对行为进行分类.
表10列出了第1人称视角下的行为识别相关方法:

Table 10 First Person View Action Recognition Methods
8多人行为识别方法
多人行为识别方法是为了识别人与人(或物)之间的交互行为以及人的群体行为.虽然多人行为识别方法基本可以包含在前面提到的不同的行为识别方法中,但对于多人的行为识别方法本身,此类方法拥有自身的特性.本文将多人行为识别方法分为交互行为(interaction)识别方法和群体行为(crowd behavior)识别方法2类.
1) 交互行为
为了识别人与物的交互行为,首先要做的是识别物体和分析人的运动信息,然后联合这2种信息进行交互行为的识别.最经典的交互行为识别方法[59-60,104-106]是忽略物体识别和运动估计的相互影响,即先利用物体分类方法来识别物体,然后再识别这些物体参与的运动行为.也就是说这没有利用物体识别和运动分析两者的相互关系,运动估计是严格依赖于物体检测的.为了利用物体与动作之间的相互关系来提高物体检测和行为识别的性能,Moore等人[107]利用简单行为识别的结果来提升物体分类的性能.一般情况下,行为识别还是依赖于物体分类的,但当物体分类出现错误时,行为信息通过构建的贝叶斯网络对物体分类进行补偿.更进一步地,Gupta和Davis[108]提出了一种概率模型来整合物体表观、人体对物体的动作以及动作对物体的反作用.这些信息通过贝叶斯网络被整合在一起来对物体和行为进行分类和识别.
2) 群体行为
群体行为是由一个或多个人群构成的行为,其研究对象是多人形成的群体.群体行为分析根据所要获取的知识的不同,可以分为2类:①每个个体在整个群体行为中发挥不同的作用[109-111].例如我们分析一个“做报告”的行为,我们需要分析其中报告者的行为和听众的行为.此类群体行为可以很自然地通过由多个个体的子行为构建的多层模型对群体行为进行表达.②所有个体的运动信息作为一个整体来进行群体行为分析,如“军队行军”和“游行”等都属于这类群体行为.在此类群体行为方法中[112],每个个体经常被当作一个点,然后利用这些点的轨迹对整体行为进行分析.
表11列出了引用的事件分析方法的相关工作:
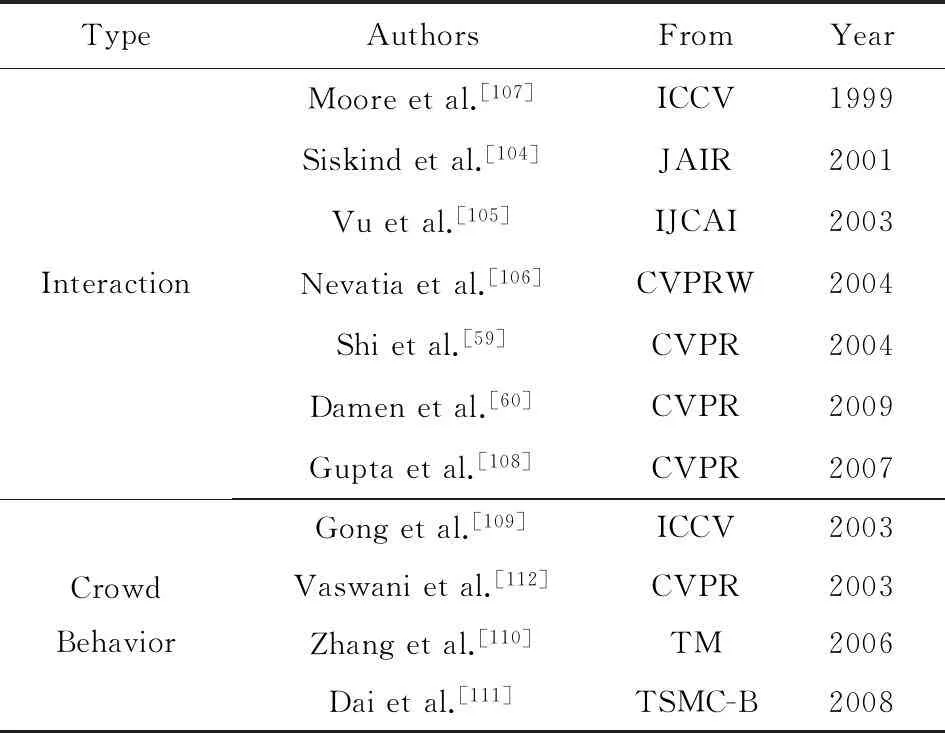
Table 11 Multi-Person Action Recognition Methods
9总结与展望
本文对人的行为识别方法进行了系统性地介绍,以数据库的发展历程为线索介绍了行为识别近15年的发展状况.通过以上的分析可以看出,由于行为数据的类别多种多样,导致行为识别方法也各有差异.但对于每一种行为数据的行为方法来说,不管是将时间和空间作为一个整体的时空体模板、局部特征直方图等,还是将时间和空间分开进行处理的时序方法,时空的运动变化信息对于行为的描述都是非常重要的.只用合理组织表达行为内在的时空运动变化信息,才能得到好的识别性能.
随着数据技术和行为,行为识别的发展将呈现以下特点:
1) 行为识别将聚焦更具挑战性的真实场景中的行为检测问题
当前大部分行为识别工作中对行为的检测问题进行了回避或简化.尤其在如UCF101, HMDB51等数据库中的行为识别工作,可看作是视频分类问题,对其中决定行为发生的关键动作以及行为发生的起始、终止时刻不能准确检测.在TRECVID监控事件检测竞赛中,当前最好的事件检测效果也远远不能令人满意.对此,研究者需要结合更多中层或高层语义特征如物体检测、人姿态估计等结果,与底层运动特征相结合来实现对行为的语义表达建模和准确检测.
2) 深度学习在时序数据中的应用将成为研究热点
深度学习在许多传统视觉任务中取得了巨大进步,但在行为识别任务中,深度学习还尚未完全取得显著性的性能提升.原因是:相比图像样本,由于时间维度的引入,行为样本的类内差异更加丰富、行为模本的特征维度更高、需要的样本数量更多;同时在行为标注中,很难在视频中精确标记行为发生的时空区域(如图像中物体边框),从而无法实现样本对齐(alignment),导致模型训练难度更大.因此如何从时间维度入手建立深度神经网络模型对行为数据进行训练,如Recurrent Neural Network是当前的一个研究热点.
3) 新型传感数据将为行为识别的实用化提供可能
新型的RGB-D传感器可以有效克服光照、遮挡和视角变化的影响,获得准确的前景位置及人体的姿态参数,因此大大降低了行为识别的难度.当前,基于RGB-D传感器的行为识别在一些使用环境中如体感游戏,已被推向实用.未来基于RGB-D数据的行为识别技术还将进一步发展,预计在更多的领域如汽车辅助驾驶等取得令人瞩目的成就.
参考文献
[1]Huang Kaiqi, Ren Weiqiang, Tan Tieniu. A review on image object classification and detection[J]. Chinese Journal of Computers, 2014, 37(6): 1-18 (in Chinese)(黄凯奇, 任伟强, 谭铁牛. 图像物体分类与检测算法综述[J]. 计算机学报, 2014, 37(6): 1-18)
[2]Over P, Awad G, Martial M, et al. Trecvid 2014-anoverview of the goals, tasks, data, evaluation mechanisms and metrics[COL]Proc of TRECVID 2014. [2014-07-09]. http:www.nist.govitliadmigtrecvid_sed_2014.cfm
[3]Soomro K, Zamir A, Shah M. UCF101: A dataset of 101 human actions classes from videos in the wild, CRCV-TR-12-01[ROL]. (2012-12-01) [2015-04-15]. http:crcv.ucf.edudataUCF101.php
[4]Aggarwal J, Ryoo M. Human activity analysis: A review[J]. ACM Computing Surveys, 2011, 43(3): 1-43
[5]Turaga P, Chellappa R, Subrahmanian V, et al. Machine recognition of human activities: A survey[J]. IEEE Trans on Circuits and Systems for Video Technology, 2008, 18(11): 1473-1488
[6]Poppe R. A survey on vision-based human action recognition[J]. Image and Vision Computing, 2010, 28(6): 976-990
[7]Kru¨ger V, Kragic D, Ude A, et al. The meaning of action: A review on action recognition and mapping[J]. Advanced Robotics, 2007, 21(13): 1473-1501
[8]Ye Mao, Zhang Qing, Wang Liang, et al. A survey on human motion analysis from depth data[C]Proc of Time-of-Flight and Depth Imaging, Sensors, Algorithms, and Applications. New York: Elsevier Science Inc, 2013: 495-187
[9]Ke S, Thuc H, Lee Y, et al. A review on video-based human activity recognition[J]. Computers, 2013, 2(2): 88-131
[10]Vishwakarma S, Agrawal A. A survey on activity recognition and behavior understanding in video surveillance[J]. The Visual Computer, 2013, 29(10): 983-1009
[11]Chaquet J, Carmona E, Caballero A. A survey of video datasets for human action and activity recognition[J]. Computer Vision and Image Understanding, 2013, 117(6): 633-659
[12]Popoola O, Wang Kejun. Video-based abnormal human behavior recognition—A review[J]. IEEE Trans on Systems, Man, and Cybernetics, Part C: Applications and Reviews, 2012, 42(6): 865-878
[13]Huang Kaiqi, Chen Xiaotang, Kang Yunfeng, et al. Intelligent visual surveillance: A review[J]. Chinese Journal of Computers, 2015, 38(6): 1093-1118 (in Chinese)(黄凯奇, 陈晓棠, 康运锋, 等. 智能视频监控技术综述[J]. 计算机学报, 2015, 38(6): 1093-1118)
[14]Schuldt C, Laptev I, Caputo B. Recognizing human actions: A local SVM approach[C]Proc of the 17th Int Conf on Pattern Recognition. Piscataway, NJ: IEEE, 2004: 1051-4651
[15]Blank M, Gorelick L, Shechtman E, et al. Actions as space-time shapes[C]Proc of the 13th IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2005: 1395-1402
[16]Bobick A, Davis J. The recognition of human movement using temporal templates[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2001, 23(3): 257-267
[17]Ke Yan, Sukthankar R, Hebert M. Spatio-temporal shape and flow correlation for action recognition[C]Proc of the 20th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2007: 1-8
[18]Jhuang H, Serre T, Wolf L, et al. A biolog-ically inspired system for action recognition[C]Proc of the 14th IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2007: 1-8
[19]Wang Yang, Mori G. Hidden part models for human action recognition: Probabilistic vs max-margin[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2011, 33(7): 1310-1323
[20]Weinland D, Boyer E, Ronfard R. Action recognition from arbitrary views using 3D exemplars[C]Proc of the 14th IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2007: 1-7
[21]Zhang Zhang, Tao Dacheng. Slow feature analysis for human action recognition[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2012, 34(3): 436-450
[22]Huang Feiyue, Di Huijun, Xu Guangyou. Viewpoint insensitive posture representation for action recognition[C]Proc of the Articulated Motion and Deformable Objects. Berlin: Springer, 2006: 143-152
[23]Bui W, Venkatesh S, West S. Policy recognition in the abstract hidden Markov model[J]. Journal of Artificial Intelligence Research, 2002, 17: 451-499
[24]Huang Peng, Hilton A. Shape-colour histograms for matching 3D video sequences[C]Proc of the 15th IEEE Int Conf on Computer Vision Workshops. Piscataway, NJ: IEEE, 2009: 1510-1517
[25]Souvenir R, Babbs J. Learning the viewpoint manifold for action recognition[C]Proc of the 21st IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2008: 1-7
[26]Ji Xiaofei, Liu Honghai. Advances in view-invariant human motion analysis: A review[J]. IEEE Trans on Systems, Man, and Cybernetics, Part C: Applications and Reviews, 2010, 40(1): 13-24
[27]Marszalek M, Laptev I, Schmid C. Actions in context[C]Proc of the 22nd IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2009: 2929-2936
[28]Rodriguez M, Ahmed J, Shah M. Action mach a spatio-temporal maximum average correlation height filter for action recognition[C]Proc of the 21st IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2008: 1-8
[29]Liu Jingen, Luo Jiebo, Shah M. Recognizing realistic actions from videos in the wild world[C]Proc of the 22nd IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2009: 1996-2003
[30]Yuan Junsong, Liu Zicheng, Wu Ying. Discriminative video pattern search for efficient action detection[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2011, 33(9): 1728-1743
[31]Choi Wongun, Shahid K, Savarese S. What are they doing? Collective activity classification using spatio-temporal relationship among people[C]Proc of the 15th IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2009: 1282-1289
[32]Laptev I, Lindeberg T. Space-time interest points[C]Proc of the 9th IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2003: 432-439
[33]Dollar P, Rabaud V, Cottrell G, et al. Behavior recognition via sparse spatio-temporal features[C]Proc of the 2nd Joint IEEE Int Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance. Piscataway, NJ: IEEE, 2005: 65-72
[34]Willems G, Tuytelaars T, Gool L. An efficient dense and scale-invariant spatio-temporal interest point detector[C]Proc of the 11th European Conf on Computer Vision. Berlin: Springer, 2008: 650-663
[35]Alexander K, Marszalek M, Schmid C. A spatio-temporal descriptor based on 3D-gradients[C]Proc of the 19th British Machine Vision Conf. Berlin: Springer, 2008: 1-10
[36]Shan Yanhu, Zhang Zhang, Zhang Junge, et al. Interest point selection with spatio-temporal context for realistic action recognition [C]Proc of the 9th Int Conf on Advanced Video and Signal-Based Surveillance. Piscataway, NJ: IEEE, 2012: 94-99
[37]Deng Jia, Dong Wei, Socher R, et al. ImageNet: A large-scale hierarchical image database[C]Proc of the 22nd IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2009: 248-255
[38]Kishore K, Shah M. Recognizing 50 human action categories of Web videos[J]. Machine Vision Applications, 2013, 24(5): 971-981
[39]Kuehne H, Jhuang H, Garrote E, et al. HMDB: A large video database for human motion recognition[C]Proc of the 24th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2011: 2556-2563
[40]Ryoo M, Aggarwal J. Ut-interaction dataset, icpr contest on semantic description of human activities (sdha)[DBOL]. 2010 [2010-09-08]. http:cvrc.ece.utexas.eduSDHA2010Human_Interaction.html
[41]Li Wanqing, Zhang Zhengyou, Liu Zicheng. Action recognition based on a bag of 3D points[C]Proc of the 23rd IEEE Conf on Computer Vision and Pattern Recognition Workshop. Piscataway, NJ: IEEE, 2010: 9-14
[42]Wang Jiang, Liu Zicheng, Wu Ying, et al. Mining action-let ensemble for action recognition with depth cameras[C]Proc of the 25th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2012: 1290-1297
[43]Wang Jiang, Nie Xiaohan, Xia Yin, et al. Mining discriminative 3D poselet for cross-view action recognition[C]Proc of the IEEE Winter Conf on Applications of Computer Vision (WACV). Piscataway, NJ: IEEE, 2014: 634-639
[44]Han Lei, Wu Xinxiao, Liang Wei, et al. Discriminative human action recognition in the learned hierarchical manifold space[J]. Image and Vision Computing, 2010, 28(5): 836-849
[45]Messing R, Pal C, Kautz H. Activity recognition using the velocity histories of tracked keypoints[C]Proc of the 22nd IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2009: 1550-5499
[46]Fathi A, Hodgins J, Rehg J. Social interactions: A first-person perspective[C]Proc of the 25th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2012: 1226-1233
[47]Schindler K, Gool L. Action snippets: How many frames does human action recognition require?[C]Proc of the 21st IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2008: 1-8
[48]Junejo I, Dexter E, Laptev I, et al. View-independent action recognition from temporal self-similarities[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2011, 33(1): 172-185
[49]Shan Yanhu, Zhang Zhang, Yang Peipei, et al. Adaptive slice representation for human action classification[J]. IEEE Trans on Circuits and Systems for Video Technology (T-CSVT), 2015, 25(10): 1624-1636
[50]Gavrila D, Davis L. 3D model-based tracking of humans in action: A multi-view approach[C]Proc of the 9th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 1996: 18-20
[51]Veeraraghavan A, Chellappa R, Chowdhury A. The function space of an activity[C]Proc of the 19th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2006: 959-568
[52]Aggarwal J, Park S. Human motion: Modeling and recognition of actions and interactions[C]Proc of the 2nd Int Symp on 3D Data Processing, Visualization and Transmission(3DPVT 2004). Piscataway, NJ: IEEE, 2004: 640-647
[53]Yamato J, Ohya J, Ishii K. Recognizing human action in time-sequential images using hidden Markov model[C]Proc of the 5th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 1992: 379-385
[54]Bobick A, Wilson A. A state-based approach to the representation and recognition of gesture[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 1997, 19(12): 1325-1337
[55]Oliver N, Rosario B, Pentland A. A Bayesian computer vision system for modeling human interactions[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2000, 22(8): 831-843
[56]Lv Fengjun, Nevatia R. Recognition and segmentation of 3-D human action using hmm and multi-class adaboost[C]Proc of the 9th European Conf on Computer Vision. Berlin: Springer, 2006: 359-372
[57]Natarajan P, Nevatia R. Coupled hidden semi Markov models for activity recognition[C]Proc of the IEEE Workshop on Motion and Video Computing (WMVC 2007). Piscataway, NJ: IEEE, 2007: 1-10
[58]Nguyen N, Phung D, Venkatesh S, et al. Learning and de-tecting activities from movement trajectories using the hierarchical hidden Markov model[C]Proc of the 18th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2005: 955-960
[59]Shi Yifan, Huang Yan, Minnen D, et al. Propagation networks for recognition of partially ordered sequential action[C]Proc of the 17th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2004: 862-869
[60]Damen D, Hogg D. Recognizing linked events: Searching the space of feasible explanations[C]Proc of the 22nd IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2009: 927-934
[61]Tran S, Davis L. Event modeling and recognition using Markov logic networks[C]Proc of the 10th European Conf on Computer Vision. Berlin: Springer, 2008: 610-623
[62]Ivanov Y A, Bobick A F. Recognition of visual activities and inter-actions by stochastic parsing[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2000, 22(8): 852-872
[63]Joo S, Chellappa R. Attribute grammar-based event recognition and anomaly detection[C]Proc of the 18th IEEE Conf on Computer Vision and Pattern Recognition Workshop. Piscataway, NJ: IEEE, 2006: 1-11
[64]Ryoo M, Aggarwal J. Semantic understanding of continued and recursive human activities[C]Proc of the 18th Int Conf on Pattern Recognition. Piscataway, NJ: IEEE, 2006: 379-378
[65]Zhang Zhang, Huang Kaiqi, Tan Tieniu. An extended grammar system for learning and recognizing visual events in motion trajectory stream[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2011, 33(2): 240-255
[66]Laptev I, Marszalek M, Schmid C, et al. Learning realistic human actions from movies[C]Proc of the 21st IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2008: 1-8
[67]Kovashka A, Grauman K. Learning a hierarchy of discriminative space-time neighborhood features for human action recognition[C]Proc of the 23rd IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2010: 2046-2053
[68]Hu Qiong, Qin Lei, Huang Qingming, et al. Action recognition using spatial-temporal context[C]Proc of the 23rd IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2010: 1521-1524
[69]Wang Yang, Sabzmeydani P, Mori G. Semi-latent dirichlet allocation: A hierarchical model for human action recognition[C]Proc of the 2nd Workshop on HUMAN MOTION Understanding, Modeling, Capture and Animation. Berlin: Springer, 2007: 240-254
[70]Han Dong, Bo Liefeng, Sminchisescu C. Selection and context for action recognition[C]Proc of the 12th IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2009: 1933-1940
[71]Ziaeefard M, Ebrahimnezhad H. Hierarchical human action recognition by normalized-polar histogram[C]Proc of the 23rd IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2010: 3720-3723
[72]Gilbert A, Illingworth J, Bowden R. Action recognition using mined hierarchical compound features[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2011, 33(5): 883-897
[73]Felzenszwalb P, Girshick R, McAllester D, et al. Object detection with discriminatively trained part-based models[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645
[74]Xie Yuelei, Chang Hong, Li Zhe, et al. A unified framework for locating and recognizing human actions[C]Proc of the 24th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2011: 25-32
[75]Tian Yicong, Sukthankar R, Shah M. Spatiotemporal de-formable part models for action detection[C]Proc of the 26th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2013: 2642-2649
[76]Messing R, Pal C, Kautz H. Activity recognition using the velocity histories of tracked keypoints[C]Proc of the 12th IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2009: 104-111
[77]Lucas B, Kanade T. An iterative image registration technique with an application to stereo vision[C]Proc of the 1st Int Conf on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 1981: 674-679
[78]Wang Heng, Klaser A, Schmid C, et al. Dense trajectories and motion boundary descriptors for action recognition[J]. International Journal of Computer Vision, 2013, 103(1): 60-79
[79]Ji Shuiwang, Xu Wei, Yang Ming, et al. 3D convolutional neural networks for human action recognition[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2013, 35(1): 221-231
[80]Karpathy A, Toderici G, Shetty S, et al. Large-scale video classification with convolutional neural networks[C]Proc of the 27th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2014: 1725-1732
[81]Simonyan K, Zisserman A. Two-stream convolutional net-works for action recognition in videos[C]Proc of the 28th Annual Conf on Neural Information. Cambridge, MA: MIT, 2014: 568-576
[82]Wang Limin, Qiao Yu, Tang Xiaoou. Action recognition with trajectory-pooled deep-convolutional descriptors[C]Proc of the 28th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 4305-4314
[83]Wang Heng, Klaser A, Schmid C, et al. Action recognition by dense trajectories[C]Proc of the 24th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2011: 3169-3176
[84]Wang Heng, Schmid C. Action recognition with improved trajectorie[C]Proc of the 14th IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2013: 3551-3558
[85]Vieira A, Nascimento E, Oliveira G, et al. Stop: Space-time occupancy patterns for 3D action recognition from depth map sequences[C]Proc of the 19th Iberoamerican Congress on Pattern Recognition. Berlin: Springer, 2012: 252-259
[86]Yang Xiaodong, Zhang Chenyang, Tian YingLi. Recognizing actions using depth motion maps-based histograms of oriented gradients[C]Proc of the 18th ACM Int Conf on MultiMedia Modeling. New York: ACM, 2012: 1057-1060
[87]Oreifej O, Liu Zicheng. Hon4d: Histogram of oriented 4D normals for activity recognition from depth sequences[C]Proc of the 26th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2013: 716-723
[88]Zhang Hao, Parker L. 4-dimensional local spatio-temporal fea-tures for human activity recognition[C]Proc of IEEERSJ Int Conf on Intelligent Robots and Systems. Piscataway, NJ: IEEE, 2011: 2044-2049
[89]Jalal A, Uddin M, Kim J, et al. Recognition of human home activities via depth silhouettes and transformation for smart homes[J]. Indoor and Built Environment, 2012, 21(1): 184-190
[90]Gunnar J. Discriminative video pattern search for efficient action detection[J]. Perception and Psychophysics, 1973, 14(2): 201-211
[91]Campbell L, Bobick A. Recognition of human body motion using phase space constraints[C]Proc of the 5th Int Conf on Computer Vision. Piscataway, NJ: IEEE, 1995: 624-630
[92]Sheikh Y, Sheikh M, Shah M. Exploring the space of a human action[C]Proc of the 10th IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2005: 144-149
[93]Shotton J, Fitzgibbon A, Cook M, et al. Real-time human pose recognition in parts from single depth images[C]Proc of the 24th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2011: 1297-1304
[94]Zhao Xin, Li Xue, Pang Chaoyi, et al. Online human gesture recognition from motion data streams[C]Proc of the 19th ACM Int Conf on MultiMedia Modeling. New York: ACM, 2013: 23-32
[95]Xia Lu, Chen Chiachih, Aggarwal J. View invariant human action recognition using histograms of 3D joints[C]Proc of the 25th IEEE Conf on Computer Vision and Pattern Recognition Workshop. Piscataway, NJ: IEEE, 2012: 20-27
[96]Wang Jiang, Liu Zicheng, Wu Ying, et al. Mining action-let ensemble for action recognition with depth cameras[C]Proc of the 25th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2012: 1290-1297
[97]Vemulapalli R, Arrate F, Chellappa R. Human action recognition by representing 3D skeletons as points in a lie group[C]Proc of the 27th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2014: 588-595
[98]Huang Kaiqi, Tao Dacheng, Yuan Yuan, et al. View independent human behavior analysis[J]. IEEE Trans on Systems, Man and Cybernetics, Part B: Cybernetics, 2009, 39(4): 1028-1035
[99]Huang Kaiqi, Zhang Yeyin, Tan Tieniu. A discriminative model of motion and cross ratio for view-invariant action recognition[J]. IEEE Trans on Image Processing, 2012, 21(5): 2187-2197
[100]Fathi A, Farhadi A, Rehg J. Understanding egocentric activities[C]Proc of the 13th Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2011: 407-414
[101]Pirsiavash H, Ramanan D. Detecting activities of daily living in first-person camera views[C]Proc of the 25th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2012: 2847-2854
[102]Kitani K, Okabe T, Sato Y, et al. Fast unsupervised ego-action learning for first-person sports videos[C]Proc of the 24th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2011: 3241-3248
[103]Ryoo M, Matthies L. First-person activity recognition: What are they doing to me?[C]Proc of the 26th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2013: 2730-2737
[104]Siskind M. Grounding the lexical semantics of verbs in visual perception using force dynamics and event logic[J]. Journal of Artificial Intelligence Research, 2001, 15: 31-90
[105]Vu V, Francois B, Monique T. Automatic video interpretation: A novel algorithm for temporal scenario recognition[C]Proc of the 23rd Int Joint Conf on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 2003: 1295-1300
[106]Nevatia R, Hobbs J, Bolles B. An ontology for video event representation[C]Proc of the 17th IEEE Conf on Computer Vision and Pattern Recognition Workshop. Piscataway, NJ: IEEE, 2004: 119-119
[107]Moore D, Essa I, Hayes I. Exploiting human actions and object context for recognition task[C]Proc of the 7th Int Conf on Computer Vision. Piscataway, NJ: IEEE, 1999: 80-86
[108]Gupta A, Davis L. Objects in action: An approach for combining action understanding and object perception[C]Proc of the 20th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2007: 1-8
[109]Gong Shaogang, Xiang Tao. Recognition of group activities using dynamic probabilistic networks[C]Proc of the 9th Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2003: 742-749
[110]Zhang D, Perez D, Bengio S, et al. Modeling individual and group actions in meetings with layered hmms[J]. IEEE Trans on Multimedia, 2006, 8(3): 509-520
[111]Dai Peng, Di Huijun, Dong Ligeng, et al. Group interaction analysis in dynamic context[J]. IEEE Trans on Systems, Man, and Cybernetics, Part B: Cybernetics, 2008, 38(1): 275-282
[112]Vaswani N, Chowdhury A, Chellappa R. Activity recognition using the dynamics of the configuration of interacting objects[C]Proc of the 16th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2003: 633-642

Shan Yanhu, born in 1987. Received his PhD degree in pattern recognition and intelligent system from the National Laboratory of Pattern Recognition (NLPR), Institute of Automation, Chinese Academy of Sciences (CASIA), Beijing, China, in 2015, and received his BS degree from Beijing Information Science & Technology University (BISTU), Beijing, China, in 2009. He is currently a researcher in Samsung R&D Institute, Beijing, China. His main research interests include human action recognition, video surveillance and face recognition.

Zhang Zhang, born in 1980. Received his BS degree in computer science and technology from Hebei University of Technology, Tianjin, China, in 2002, and received his PhD degree in pattern recognition and intelligent system from the National Laboratory of Pattern Recognition (NLPR), Institute of Automation, Chinese Academy of Sciences, Beijing, China in 2008. Associate professor. Member of IEEE. His main research interests include activity recognition, video surveillance, and time series analysis (zzhang@nlpr.ia.ac.cn).

Huang Kaiqi, born in 1977. Received his MS degree in electrical engineering from Nanjing University of Science and Technology, Nanjing, China, and received his PhD degree in signal and information processing from Southeast University, Nanjing. After receiving his PhD degree, he became a postdoctoral researcher in the National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences, Beijing, China. Professor. Senior Member of IEEE. His main research interests include visual surveillance, image and video analysis, human vision and cognition, computer vision, etc.
中图法分类号TP391
通信作者:黄凯奇(kaiqi.huang@nlpr.ia.ac.cn)
基金项目:国家自然科学基金项目(61322209,61473290);国家“九七三”重点基础研究发展计划基金项目(2012CB316302);新疆维吾尔族自治区科技专项基金项目(201230122)
收稿日期:2015-05-28;修回日期:2015-11-09
This work was supported by the National Natural Science Foundation of China (61322209,61473290), the National Basic Research Program of China (973 Program) (2012CB316302), and Xinjiang Uygur Autonomous Region Science and Technology Project (201230122).
猜你喜欢
话语研究论丛(2022年0期)2022-11-02
石油沥青(2018年6期)2018-12-29
NBA特刊(2018年21期)2018-11-24
电子制作(2018年14期)2018-08-21
计算机应用(2016年12期)2017-01-13
中国新通信(2016年22期)2017-01-13
无线互联科技(2016年13期)2017-01-10
现代电子技术(2016年22期)2016-12-26
功能高分子学报(2016年1期)2016-04-26
四川党的建设(2014年9期)2014-08-23
