
基于基元重启的OpenGL和CUDA图形渲染算法探索
2016-04-11 10:51刘敏娜李延香魏浩
计算技术与自动化 2016年1期
刘敏娜 李延香 魏浩

摘要:针对OpenGL渲染图形要多次访问缓存区的问题,提出一种OpenGL和CUDA混合编程的图形渲染算法来加速PerlinKernel生成虚拟地形图。首先,通过OpenGL将缓存映射到CUDA内存空间,利用CUDA完成加速计算任务;然后,为几何图形设置开始和结束的位置标志,使用基元重启对图形进行组合;最后,对缓冲区对象进行渲染。实验结果表明,改进后的基于基元重启的混合算法在GTX650GPU上的平均帧速率为960fps,帧速率提高6%,算法改进后渲染方法的执行效率提高了63倍。实验证实基元重启可以提高3D处理性能。
关键词:图形渲染;OpenGL;CUDA;基元重启;Perlin
中图分类号:TP393文献标识码:A
1引言
图形渲染在核试验、DNA分子分布、天气预报等大规模科学计算任务中扮演着重要的角色[1,2]。在OpenGL中图形渲染是由CPU进行单独完成的,CPU从RAM中获得数据并且处理数据,然后写入RAM中[3]。这样做性能并不高,原因如下:①CPU的负载重而导致响应速度慢,影响渲染速度和质量;②图形渲染中使用了multiDraw()方法,绘图开销过大。multiDraw()用一条命令代替了多条glDraw*()方法,但是使用这个方法,导致顶点数组扩大了1/2,大量的冗余数据传输到CPU中,造成极大的开销[4-7]。
本文提出了一种CUDA和OpenGL混合图形渲染的方法。CUDA(ComputeUnifiedDeviceArchitecture),是NVIDIA显卡厂商推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题[8-10]。在本文中,为了进一步提高数据传输效率,图形渲染中引入了基元重启,使用基元重启可以对几何图形进行组合,组合之后,需要处理的集合图形数据更少,系统运行速度更快。
2.1传统的OpenGL图形渲染
OpenGL中的顶点,颜色,法线和其它顶点属性数据都是由GLTools库管理的。每次调用glDrawArrays、glDrawElements等一些需要顶点数据的函数时,信息是从一个带有本地GPU的高性能系统中的应用程序内存中获取的,数据将从应用程序的内存中通过PCI-Express接口总线传递到GPU本地内存[11],将会耗费大量时间,降低应用程序的运行速度。
如果将对象的所有顶点数据打包到单个缓冲区中,程序中必定包含循环,会产生很多OpenGL调用,每次调用都会有一定的系统开销。如果场景中存在大量对象,每个对象都有相关的三角形,那么对glDrawArrays的调用中的开销将会积累,从而对应用程序性能产生负面影响。
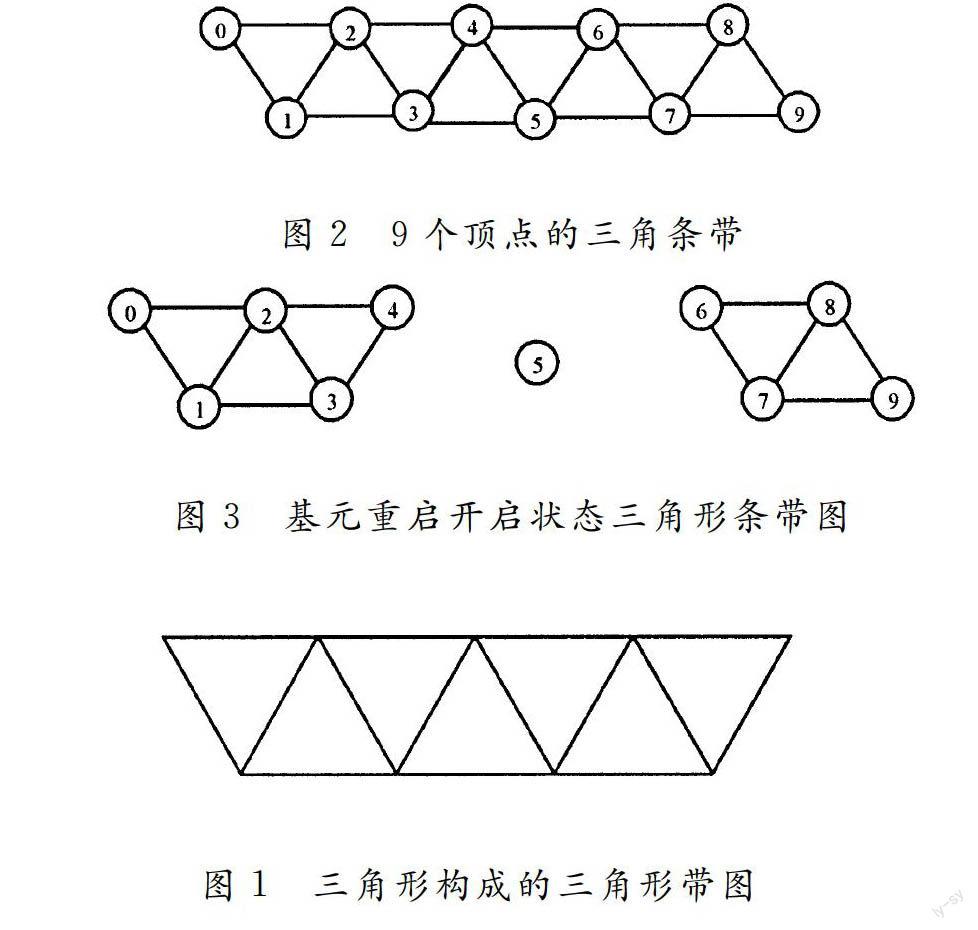
为了提高系统的处理效率,可以将大批非连接的三角形组合成三角形带,如图1所示。本来独立的三角型需要3个顶点才能进行表示,经过组合之后每个三角形所需的顶点数减少到1个(不包含三角形带中的第一个三角形)。这样需要处理的集合数据更少了,系统运行速度会更快。
但是问题是,一个三角形可以通过单次调用glDrawArrays或者glDrawElements进行渲染,一组三角形带的渲染就要单独对OpenGL进行多次调用,这意味着在一个使用条带化集合图形的程序中有更多的函数,这可能会抵消使用条带化所获得的性能提升。所以针对条带化处理应该有更好的方法来提高系统的性能,文中提出了基元重启算法。
2.2基元重启
基元重启是设定一个可以被OpenGL状态机识别的数据值,该数据值用于标识当前图形图元已经绘制完成。下一个数据项表示同样类型的另一个图形图元开始。基元重启应用在GL_TRIANGLE_TRIP、GL_TRIANGLE_FAN、GL_LINE_STRIP和GL_LINE_LOOP几何图形类型中。方法在一个条带(或者扇,环)结束和另一个开始时通知OpenGL。在几何图形中指示出一个条带结束,下一个条带的开始位置,实现时需要在元素数组中放置一个作为保留值的特殊标志。由于OpenGL是从元素数组中获取顶点索引(或者在内部生成它们),在glDrawArrays非索引绘制命令情况下,会检查这个特殊索引值,并且在遇到它时结束当前条带并在下一个顶点开始一个新的条带。在基元重启模式开启时,OpenGL会在遇到它时停止当前的条带并开始一个新的条带。
如图2所示,三角形带由9个顶点组成,在单个连接的三角形带中一共产生了8个三角形。通过开启基元重启模式并将基元重启索引设置为5,三角形带会在顶点4处结束,如图3所示。顶点5的实际位置将被忽略,下一个进行处理的顶点6将称为新的三角形带的起始位置。所以,在向OpenGL传递9个顶点的情况下,得到两个独立的三角形带,一个绘制3个三角形,另一个绘制2个三角形。这样一次数据传输的数据量就增加了。
基元重启的好处:
1)基元重启的标记值和绘图的数据可同时生成并存放于GPU上。
2)不同基元重启标记值可以指定不同数量的绘图元素,可通过给glDrawElements()指定不同的绘图模式,绘制任意数量的线段、三角条带、三角扇面等图形,所以可以绘制不规则的网格或表面。
3)通过安排索引可以优化渲染性能,达到在纹理单元中最大限度重用数据高速缓存。
2.3基于基元重启的OpenGL和CUDA图形渲染的实现
采用Perlin噪声生成器创建虚拟地形的立体地图[12],通过按键命令改变地形特征。框架分成4个独立的文件,分别如下:
1)kernelVBO.cpp,CUDA数据生成器;
2)simpleGLmain.cpp,定义OpenGL和GLUT的主体框架;
3)simpleVBO.cpp,是通用的OpenGL与CUDA设置以及内存管理;
4)callbackVBO.cpp,用于定义键盘,鼠标,显示的回调函数。
kernelVBO
kernelVBO的处理流程如下:
1)指定Perlin噪声计算中使用的头文件、变量和方法;
2)colorElevation()方法根据地形各点的海拔返回像素的颜色,选用不同颜色可以为用户呈现一种观看地图的感觉;
3)错误检查函数;
4)k_perlin()函数利用Perlin噪声生成地形图,将低于海平面的区域的高度设为0。调用cudaThreadSynchronize(),主机刷新OpenGL缓冲区需要等待Kernel执行完毕。
simpleGLmain
simpleGLmain用来在屏幕上打开一个窗口,并设置一些基本的视角变换参数。调用gluPerspective(),在三维空间中设置一个摄像机,从该摄像机的位置观察CUDA生成的数据。当数据或视角位置发生变化时,OpenGL会识别和刷新显示像素。
渲染需要进行如下3D变换:
[1]视角变换,场景中摄像机的安放与定点;
[2]模型变换,安排场景构成;
[3]投影变换,调整摄像机的变焦;
[4]可视区变换选择最终的尺寸。
OpenGL的视角、模型、投影、可视区变换,以及坐标系统的设定都要慎重。
simpleGLmain处理流程:
1)main函数初始化用于计算帧速率的定时器,然后调用用户自定义的方法初始化CUDAKernel,然后注册用户的回调函数,最后调用GLUT主循环;
2)计算帧速率,并将其显示在窗口的标题栏中;
3)GLUT和OpenGL初始化函数创建一个窗口,并在3D空间中指定一个视角位置。
simpleVBO
simpleVBO的算法如下:
1)定义创建和映射色彩信息PBO和顶点VBO的逻辑。
2)creatVBO()调用glBufferData(),在GPU上分配图形缓存区。GL_DYNAMIC_DRAW标志位告知OpenGL该数据存储会被重复修改与使用。cudaGraphicsGLRegisterBuffer()将缓冲对象注册为CUDA可访问数据。deleteVBO()方法将OpenGL缓冲对象解除注册并释放对应的存储空间。
3)runCUDA()完成所有色彩PBO的与顶点VBO的映射和检索指针。地址传给lauch_kernel()方法,并被用户自定义的Kernel使用。Lanuch_kernel()在返回之前会等待所有的Kernel执行完毕,因此该方法返回时可以安全交回OpenGL资源。
使用基元重启渲染三角形时,通过glPrimituveRestartIndexNV()方法告知OpenGL状态机重启的标记值,然后在OpenGL客户状态机上启动基元重启功能。调用glDrawElement()渲染数据。当渲染结束,在OpenGL状态机上关闭基元重启。
3实验结果及性能分析
实验平台为Intel2.3GHzCore2双核处理器,图形加速器为NVIDIA公司的GTX650,核心频率为1000MHz,显存频率为4500MHz,显存位宽为128b,显存为1024MB,操作系统为Linux,运行的是PerlinKernel生成虚拟地形图的示例。驱动程序的版本号是9.18.13.2057,总线采用PCIExpress3.0x16接口。应用程序在VS2010环境编译及执行,采用CUDA平台GPU设备编写kernel程序,程序使用扩展的C语言编写。
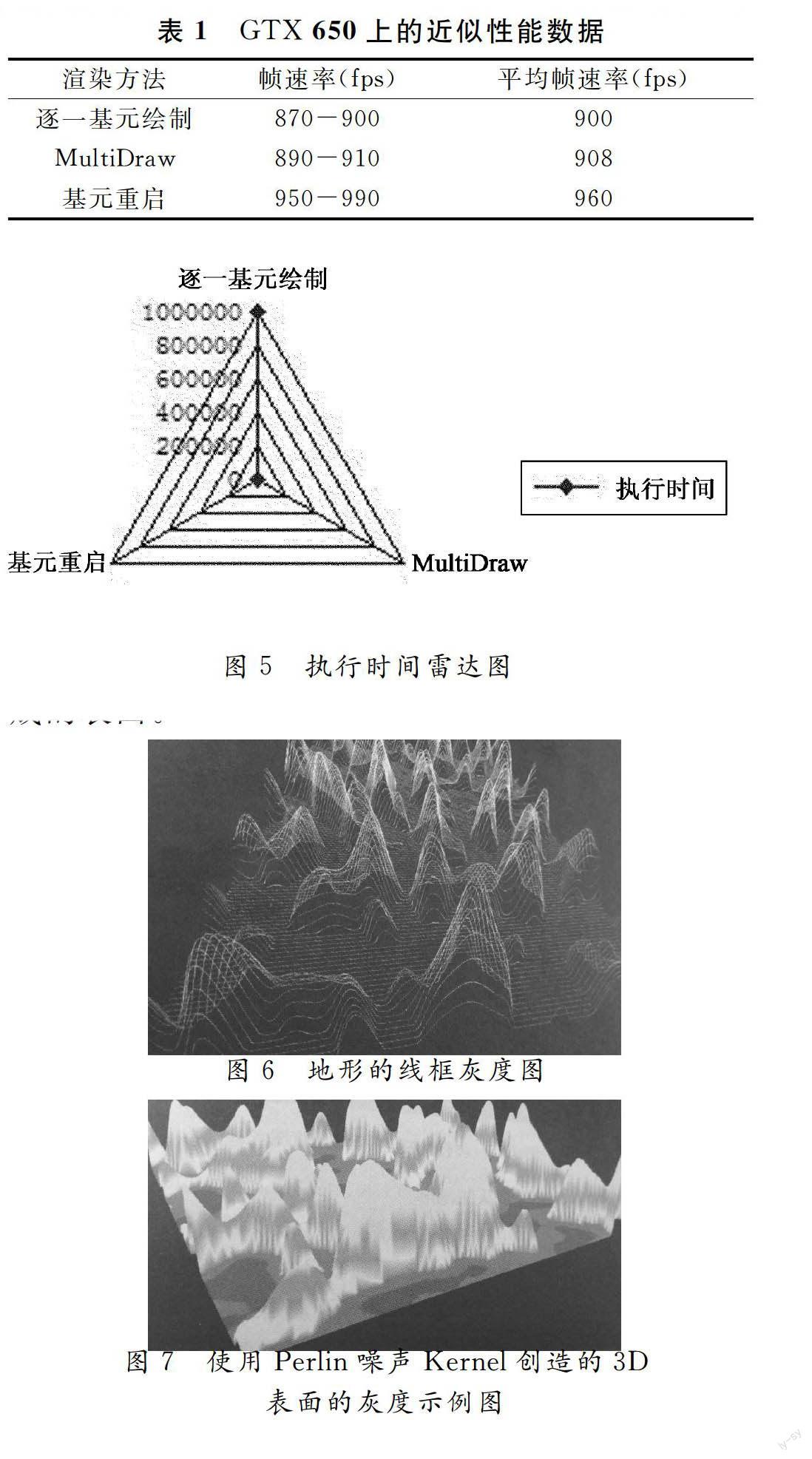
表1中的数据代表在最差情况帧速率方案中,程序混合使用CUDA和OpenGL所展示的能力和速度。实际的应用程序仅会重新计算渲染场景所必需的最小数据量,显然会获得更高的性能。帧速率包含了重新计算每个顶点3D坐标和颜色的时间,以及图像中每个像素颜色所需要的时间。
在ParallelNsight中查看程序执行时间,PerlinKernel只消耗了很短的(几乎可以忽略不计的)执行时间,执行的时间主要耗费在OpenGL的缓冲交换,需要多次进行缓冲数据交换。
在ParallelNsight中查看OpenGLAPI函数调用的情况,得到各种渲染方法的执行时间:基元重启,大约30μs,multidraw大约1900μs,逐一绘制各扇形:大约1000000μs。执行时间雷达图如下图5所示。因为基元重启减少了PCIe总线上的数据传输,避免了数据传输对性能的影响,因此使用基元重启比使用优化的OpenGL的multiDraw()方法性能要高出1900/30=63倍。
4结语
本文研究了基于基元重启的OpenGL和CUDA图形渲染算法,在OpenGL和CUDA之间实现互操作的原理,OpenGL将内存映射入CUDA内存之后,利用CUDA进行并行处理。但是如果两者之间的数据需要频繁交换,一定程度上会降低执行效率。通过在传输数据上设置基元重启标志,一次传输的数据信息量大了,这样降低了数据的交换次数,提高了处理的速度。从实验结果上分析,采用OpenGL和CUDA混合编程改写Perlin噪声生成的人工地形程序比使用优化的OpenGLMultiDraw()方法性能有了大幅度的提高。接下来需要解决的问题是OpenGL和CUDA混合编程实现网络摄像头的现场视频流处理。
参考文献
[1]张权.渲染技术在虚拟仿真中的应用[J].电子制作,2015,(09):62-63.
[2]QIAOShaojie,WANGYouwei,NIShengqiao.HighspeedimagerenderingmethodbasedonOpenGL[J].ComputerEngineeringandDesign,2011,47(21):47-49.(乔少杰,王有为,倪胜巧.基于OpenGL的快速图像渲染方法[J].计算机应用研究,2008,25(5):1589-1595.)
[3]孙晓洁,叶桦,费树岷.基于OpenGL的混凝土泵车智能臂架系统仿真[J].科技通报,2014(05):22-25.
[4]吴恩华.辐射度技术用于随机分维几何面的全局光照计算[J].计算机学报,2000,(05):321-323.
[5]ZHAOJianbin,LILingqiao,YANGHuihua.Researchongraphicrenderingenginewiththreadlevelparallelismmethod[J].ComputerEngineeringandDesign,2011,47(21):47-49.(赵建斌,李灵巧,杨辉华.线程级并行计算在图形渲染引擎中的研究[J].计算机工程与设计,2011,32(12):4143-4147.
[6]RICHARDS.WRIGHT,JR.NicholasHaemel.OpenGlSuperBibleFifthEdition[M].北京:人民邮电出版社,2012:380-420.
[7]李妮,陈铮,龚光红.多核并行计算技术在景象匹配仿真中的应用[J].系统工程与电子技术,2010,32(2):428-432.
[8]张林波,迟学斌,莫则尧,等.并行计算导论[M].北京:清华大学出版社,2006:1-59.
[9]RobFarber.CUDAApplicationDesignandDevelopment[M].北京:机械工业出版社,2012:178-185.
[10]GORDERPF.Multicoreprocessorsforscienceandengineering[J].ComputinginScience&Engineering,2007,9(2):3-7.
[11]NVIDIACUDAProgrammingGuide,version2.1[S].NVIDIA,2008.
[12]项予,许森.基于Perlin噪声的动态水面实时渲染[J].计算机工程与设计,2013,34(11):3966-3969.
第35卷第1期2016年3月计算技术与自动化ComputingTechnologyandAutomationVol35,No1Mar.2016第35卷第1期2016年3月计算技术与自动化ComputingTechnologyandAutomationVol35,No1Mar.2016
