
图像处理耦合模板定位的答题卡识别研究与应用
2016-03-25 17:29郝平�k
计算技术与自动化 2015年4期
郝平�k


摘要:当前大多数机器阅卷中采用的识别算法基于模糊识别,即针对某类型的试卷,更换多种试卷或者同种试卷不同采集方式下很难准确对应,具有一定的局限性。对此,本文提出一个基于OpenCV耦合模板定位的答题卡识别机制。首先基于人机交互划定学号区与客观题区;然后基于图像处理算法定位得到填涂位置,评价填涂结果,完成答题卡识别。本系统模板制作模块由C#编程实现,答题卡识别由C++和OpenCV实现。最后测试本文机制性能,结果表明:与基于模糊识别的普通方法相比,本文机制具有更好的定位效果和识别准确度。
关键词:模板定位;OpenCV;人机交互;模糊识别;图像处理
中图分类号:TP391文献标识码:A
1引言
答题卡识别系统是针对客观题答案进行检测识别的应用性软硬件的综合,目前使用的答题卡识别系统具有阅卷速度快、效率高、准确率高等优点,但也存在一定的局限性,必须采用光电阅卷机和专用机读答题卡,成本高昂,普通学校难以承受;且一旦确定规格就难以修改[1-3]。而利用价格相对低廉的数码相机或复印机作为图像数据输入设备采集答题卡图像,再经过软件处理、识别将获得的考试信息存入数据库,同样可以实现自动阅卷的目的,并可以降低设备成本[4-6]。而且软件实现方式方便修改答题卡结构以适应不同需求易于普及推广。
基于软件处理的答题卡识别主要应用图像处理与识别算法,总体分为两种模式:第一种是模糊识别,以答题卡图像中某特定目标为参照进行识别,然后根据位置信息定位客观题区域,然后进行识别,实现答题卡信息读取。第二种是先模板制作,然后根据模板定位客观题位置,进行识别,实现答题卡信息读取。第一种方式,由于依靠特定目标,在更换试卷类型同样存在识别不准的问题。第二种方式,在前期基于人机交互,用软件制作出模板,可对应于试卷类型变更。本文研究的机制就是采用第二种方式,先基于C#编程实现模板制作软件的开发,得到模板信息即客观题位置信息;然后用图像处理的方式对客观题进行识别,完成答题卡识别。
计算技术与自动化2015年12月
第34卷第4期郝平:图像处理耦合模板定位的答题卡识别研究与应用
为了解决当前光电阅卷机和专用机读答题卡成本高昂的问题和模糊识别通用性差的问题,本文提出了一个基于图像处理耦合模板定位的答题卡识别系统,实现对考生学号与客观题答案的识别。首先基于模板定位软件得到考生学号区域和答题卡答案区域的图像坐标;然后开始进入批量阅卷阶段,基于图像处理识别学号和答案,再最后在界面上显示,并上传至服务器数据库。最后实验证明本文识别机制的性能。
2答题卡识别的整体机制
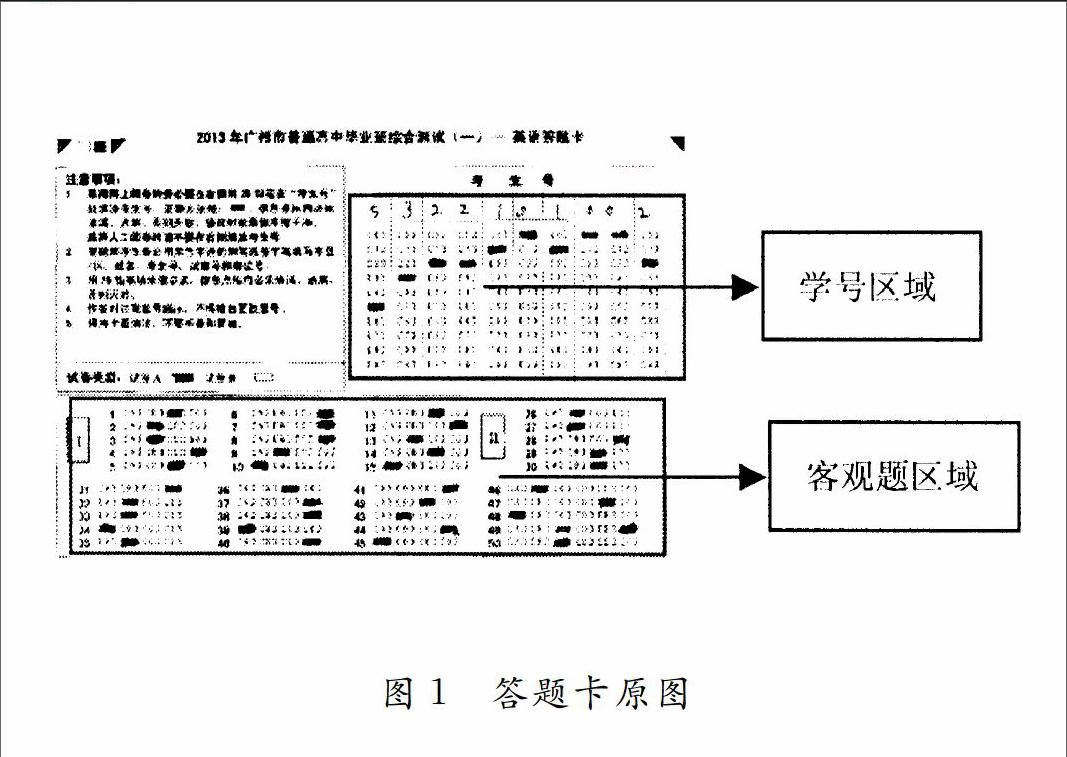
程序控制扫描仪采集答题卡图像,供模板制作和阅卷识别,具体扫描仪端采集控制程序不是本文研究的重点,本文从图像采集完成开始研究。答题卡上待识别的内容主要是考生学号和客观题答案,如图1所示。模板的主要信息是:划定区域的左上角图像坐标和长宽、学号或者客观题、单选或多选、区域几行几列。这些信息在图像载入C#模板制作软件后,用鼠标基于人机交互的方式划定和输入。
模板制作完成并保存后,基于模板信息对后面的试卷开始批量阅卷,主要经过模板定位、填涂位置定位、识别、显示结果,整体机制的框架如图2所示。
3基于模板制作的区域定位
采用模糊识别定位某个特定目标然后根据位置信息推算客观题或者学号区位置,这样方法在变更试卷类型时往往准确率严重下降。本文先用人机交互的方式,用软件制作出模板,该模板包含的信息强大,可以有学号和客观题的区域坐标、学号的位数、客观题是多选或者单选,客观题的选项数和个数等等(如图3所示)。模板制作,为后期图像准确识别做好了数据准备,只要在前期花很少的制作时间,而且制作软件界面友好易操作,每次不同类型的试卷批量阅卷前,只需制作一次即可用于后面大量的试卷阅卷。
经过本文的模板制作软件处理,得到目模板信息,如图4所示。本模板制作软件基于.NET平台C#语言开发实现,秉承了界面友好和开发效率高的优点,成功运用在了本系统中,为后期图像处理扫清定位障碍。
模板制作部分关键代码:
var jsonModel = new JsonModel();//初始化模板
jsonModel.Items = new List
jsonModel.ImageBase64String=Convert.ToBase64String(image);//模板格式转换
jsonModel.PicBoxSize=string.Format("{0},{1}",picBoxSize.Width, picBoxSize.Height); //图像格式转换
jsonModel.RealImageSize=string.Format("{0},{1}",realImageSize.Width, realImageSize.Height);//图像格式归一化
double ratio = (double)realImageSize.Width / (double)picBoxSize.Width;
//遍历模板
list.ForEach(x =>jsonModel.Items.Add(new Item {
Id = x.Id,
Name = x.Name,//模板对象名
RectPointType = x.RectPointType,//模板点类型
RectType = x.RectType.ToString(),
DeawType = x.DeawType,
Direction = x.Direction,
ColCount = x.ColCount,//数据列
RowCount = x.RowCount,// 数据行
Table = x.Table,
Rect = string.Format("{0},{1},{2},{3}", x.SelectRectangle.X, x.SelectRectangle.Y,
x.SelectRectangle.Width, x.SelectRectangle.Height),
RealRect = string.Format("{0},{1},{2},{3}", Convert.ToInt32(x.SelectRectangle.X * ratio), Convert.ToInt32(x.SelectRectangle.Y * ratio),Convert.ToInt32(x.SelectRectangle.Width * ratio), Convert.ToInt32(x.SelectRectangle.Height * ratio))}));
var json = JsonConvert.SerializeObject(jsonModel);
File.WriteAllText(fileName, json);//文件写入
4基于OpenCV的答题卡识别
通过模板数据易定位学号和客观题区域,本节以学号为例,展开研究,得到的学号区域图像如图5所示。由于试卷背景为白色,填涂颜色为黑色,具有很强的对比度,本机制利用自适应阈值分割[7-8]和图像取反[9],得出学号区域二值图,如图6所示。然后用形态学开运算[12]进一步去除噪声,最后基于OpenCV[10-11]匹配函数,定位出填涂目标。
本文使用的匹配函数[12]主要基于面积、周长、长轴短轴比、长轴短轴差,由于检测矩形目标,因此目标的面积、周长、长轴短轴比、长轴短轴差具有区别性,经过调试,可计算出经验值范围,从而判断目标是否是填涂目标。
L=∑s[n](1)
CDB=aixs/aiys(2)
CDC=aixs-aiys(3)
其中,所示L为周长,S[n]为目标轮廓边缘像素点组成的数组。如式2所示CDB为目标轮廓长轴与短轴的比例,aixs为长轴,aiys为短轴。如式3所示CDC为目标轮廓长轴与短轴的差值,aixs为长轴,aiys为短轴。
经过本文的阈值分割、形态学处理、匹配函数相结合的方法,得到学号填涂目标定位结果,如图7所示。
答题卡识别部分关键代码:
IplImage* gray = cvCreateImage( cvGetSize(ipl), 8, 1 ); //图像初始化
cvCvtColor( ipl, gray, CV_BGR2GRAY );//颜色空间转换
IplImage* erzhi = cvCreateImage(cvSize(width,height), 8 , 1);
cvThreshold( gray, erzhi,179,255,CV_THRESH_BINARY);//阈值分割
IplImage* qufan=cvCreateImage(cvSize(width,height), 8 , 1);
cvNot(erzhi,qufan);
IplConvKernel*element=cvCreateStructuringElementEx(5,5,1,1,CV_SHAPE_RECT,0);//构建形态学结构分子
cvMorphologyEx(qufan,qufan,NULL,element, CV_MOP_OPEN, 1); //形态学处理
tmparea=fabs(cvContourArea(contour1)); //面积计算
zhouchang=fabs(cvArcLength(contour1)); //周长计算
End_Rage2D = cvMinAreaRect2(contour1);//最小内接矩形
CDB=End_Rage2D.size.height/End_Rage2D.size.width;
CDC= End_Rage2D.size.height-End_Rage2D.size.width;
5实验与讨论
本文机制基于模板制作得到学号与客观题区域,图像处理采用阈值分割与形态学处理得到目标分明的二值图,再通过匹配得到目标的精确坐标,轮廓特征有面积、周长、长宽比、长宽差,实现答题卡信息读取。经过实验验证,试卷类型变更和试卷采集位置变换的情况下,传统定位方式是基于模糊识别定位算法,存在定位不准确和无法识别答题卡信息的问题,如图9所示。
本文定位机制基于C#模板制作软件得到准确的学号和客观题位置坐标,然后用图像处理OpenCV函数,准确定位目标位置,并精确完成答题卡识别,如图8所示。
为了量化不同算法的识别精确度,本文采用对相同一组试卷进行检测,先用传统算法识别;然后本文算法识别,分别记录所用时间和识别结果,最后进行人工校验。结果见表1。从表中可知,本文算法的识别精度比传统机制要高,所用时间也少于传统机制;而传统机制还存在较高的漏检。
6结论
为了解决当前模糊识别通用性差的问题,本文提出了一个基于图像处理耦合模板定位的答题卡识别系统,采用C++、C#主流语言实现。首先基于模板定位软件得到考生学号区域和答题卡答案区域的图像坐标;然后开始进入批量阅卷阶段,基于图像处理识别学号和答案。
结果表明:与普通识别卡识别定位算法相比,本文机制具有更好的识别精度和更高的效率。
参考文献
[1]杨青燕. 基于灰度图像的答题卡识别技术[J].山东科技大学学报:自然科学版,2009,13(17):43-46.
[2]KAUL T,GRIEBEL R,KAUFMANN E. Transcription as a Tool for Increasing Metalinguistic Awareness in Learners of German Sign Language as a Second Language[J]. Teaching and Learning Signed,2014,18(11):383-387.
[3]RUSHTON VE,HIRSCHMANN PN,BEARN DR. The effectiveness of undergraduate teaching of the identification of radiographic film faults[J]. Dentomaxillofacial Radiology, 2014, 34(6): 225-232.
[4]HSIUNG CM,LUO LF,CHUNG HC. Early identification of ineffective cooperative learning teams[J]. Journal of Computer Assisted Learning,2014, 30(6):534-545.
[5]李翀伦. 复杂背景下红外图像目标的快速定位[J]. 海军工程大学学报,2013, 33(10):2886-2890.
[6]吕鸣. 提高自学考试答题卡识别准确率的探讨及实践[J]. 中国考试,2011, 23(2):371-376.
[7]RAJKUMAR TMP,LATTE MV. Adaptive Thresholding Based Medical Image Compression Technique Using Haar Wavelet Based Listless SPECK Encoder and Artificial Neural Network[J]. Journal of Medical Imaging and Health Informatics,2015, 5(2):223-234.
[8]SHARMA P,KHAN K,AHMAD K. Image denoising using local contrast and adaptive mean in wavelet transform domain[J]. International Journal of Wavelets, Multiresolution and Information Processing,2014, 12(06):1450038-1~1450038-15.
[9]SHARMA Y,MEGHRAJANI YK. Extraction of Grayscale Brain Tumor in Magnetic Resonance Image[J].International Journal of Advanced Research in Computer and Communication Engineering, 2014, 3(11): 8542-8545.
[10]叶昕, 秦其明, 王俊. 结合数学形态学与多角度模板匹配的高分辨率遥感图像救灾帐篷识别[J]. 测绘通报, 2015, 5(1): 86-89.
[11]CHOU LD,CHEN CC,KUI CK. Implementation of Face Detection Using OpenCV for Internet Dressing Room[J]. Advanced Technologies, 2014, 260(23): 587-592.
[12]张亚荣, 裴志利. OpenCV耦合三目视觉的标准件目标定位研究与应用[J].组合机床与自动化加工技术, 2015, 2(1): 35-38.
猜你喜欢
电脑知识与技术(2022年9期)2022-05-10
电脑知识与技术(2022年9期)2022-05-10
计算技术与自动化(2022年1期)2022-04-15
教育教学论坛(2018年5期)2018-01-22
科技创新导报(2016年23期)2016-12-23
计算机教育(2016年7期)2016-11-10
