
基于GPU的原油液体仿真效率优化研究
2016-03-25 17:05刘贤梅闫冲
计算技术与自动化 2015年4期
关键词:可视化
刘贤梅闫冲


摘要:针对有杆抽油系统的采油过程,原油液体在油管内受力而不断运动。为了将此过程形象、逼真的展现出来以便于相关工作人员观察和分析,需建立一个高精度、高效率、易使用的可视化环境。本文在VC++6.0环境下,运用粒子系统技术模拟原油液体的运动过程,并采用通过GPU加速和非GPU加速对比的方式优化了系统效率。通过数据对比表明:随着粒子数的增加,通过采用GPU加速运算方式的系统效率大大提高。
关键词:可视化;粒子系统;GPU
中图分类号:TP393文献标识码:A
1引言
随着油田钻井技术的发展,有杆采油系统中的可视化问题已经成为了油田行业的一个重大问题,特别是在采油作业的过程中,需要时刻定性、定量的了解井筒中设备的运动状况以及原油液体状态变化,方便相关技术人员观察与分析,以确保采油过程顺利进行。
GPU的并行处理技术已经在各个领域广泛应用。1999年,文献1[1]在求解辐射度方程时利用颜色来标示物体序号,利用深度缓冲来辅助计算物体可见性。2002年,文献22]等利用图形硬件进行实时的运动规划,即用颜色来标记多边形。2004年,文献3[3]等利用图形硬件的多边形光栅化过程和深度缓冲检测来计算二维和三维的通用Voronoi图。2006年,文献4[4]等采用均匀网格来计算场景中的纹理,并建立三角形链表纹理,整个计算过程都放在GPU上进行,提高了效率。自此,GPU的并行计算技术在碰撞检测、数学运算、像素模拟等方面得到了广泛的应用。
本文充分考虑图形处理技术的并行性,以VC++6.0为开发平台,采用GPU加速的方法,运用粒子系统技术模拟了原油液体在油管内的运动状态,建立一个高精度、高效率、易使用的可视化环境。本系统对液体仿真过程进行优化,是GPU技术在液体仿真和油田领域的一次新的突破。最终通过数据对比表明:随着粒子数的增加,通过采用GPU加速运算的方法使系统效率大大提高。
2粒子系统
2.1粒子系统简介
迄今为止,粒子系统作为一种有效的图形生成算法通常被用来模拟不规则的模糊物体,其基本思想就是将无数微小粒子作为最基本的元素来表示不规则物体[5-6]。根据粒子系统的应用,大致分为四种类型:
1)随机粒子系统。在随机粒子系统中,粒子的属性随机变化,例如烟花的绽放过程、流水过程等。
2)流体粒子系统。流体粒子系统中的粒子运动线路和运动轨迹受流体力学的影响。例如,工厂里的烟雾扩散情况、瀑布、以及高温高压下的岩浆流动情况。
3)方向粒子系统。方向粒子系统中的粒子在活动过程中相互作用、相互影响。在方向粒子系统中,所有粒子的属性具有关联性,主要用于绵软不规则的物体,例如纺织物等。
4)结构化粒子系统。结构化粒子系统是由具有一定组织结构的较小粒子组成的系统。其基本单元在一定的时间内变化量较小,例如微风下的花草树木。
2.2粒子的基本性质
1)粒子的物质性。在粒子系统中,在任何时间和空间上,粒子与粒子、粒子与其他物体之间都不会发生重叠,具有绝对的物质性。
计算技术与自动化2015年12月
第34卷第4期刘贤梅等:基于GPU的原油液体仿真效率优化研究
2)粒子的基本属性。粒子系统中的每一个粒子都有其基本属性,包括运动属性和静态属性两种。静态属性是指属性物体的属性不会随时间的变化而变化,例如大小、颜色、生命周期、质量等。运动属性是指物体的属性会随时间的变化而产生变化,这个变化可以是线性的,例如速度、位移等。
3)粒子的生命机制。每个粒子都有其生命周期,一般粒子要经历产生、活动、消亡基本过程。粒子的生命阈值到达上限是会被自动删除,在此过程中会有新的粒子产生。
4)粒子的活动机制。粒子在其生命周期内会按照预先设定好的运动规律在场景中进行运动,直到生命周期结束。
5)粒子的绘制。根据被模拟物体的基本特性设定粒子的静态属性,再分析被模拟物体的运动特性设定粒子的动态属性。系统中的粒子按照产生、活动、消亡、更新的顺序进行全生命周期的活动。
2.3粒子系统模型
粒子系统是按照时间顺序进行全生命周期活动的系统[7]。粒子系统中的每一个粒子都要经历产生、活动、消亡这三个过程。在进行每一次粒子绘制的时候,整个粒子系统要维持一个稳定的循环体系,对于活动中的粒子,我们要根据被模拟对象的属性来更新粒子的属性,其运行基本步骤主要包括五部分:
1)在指定区域随机生成粒子,并赋予粒子随机属性;
2)根据被模拟物体的基本特性来归纳总结粒子的基本活动规律,设置好粒子的静态属性或者动态属性,例如初始位置、颜色、大小、生命周期等。;
3)根据粒子生命周期,将粒子的当前存在时间与生命上线进行对比,判断粒子的生命状态,删除生命值为零的粒子并根据需要更新粒子;
4)根据粒子的动态属性或静态属性,模拟粒子的位移变换;
5)将活动粒子进行渲染,最终描绘出被模拟物体。
3可编程GPU技术
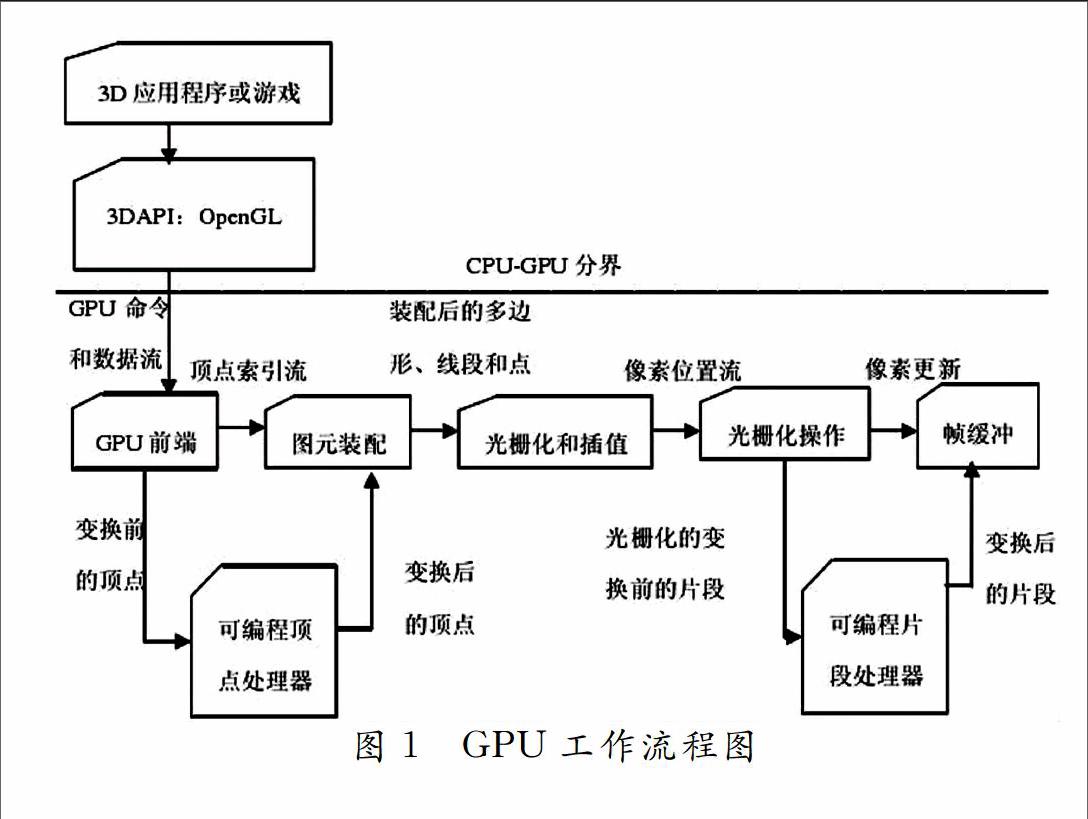
3.1GPU工作流程
GPU处理复杂和大量图形具有很高的效率[8],主要是由于:
1)减少了GPU与CPU之间的数据通信
当整个应用针对图形生成的时候,不再需要在CPU与GPU之间进行多次数据交换,这样就可以将CPU解放出来做其他的任务。这些优势使得GPU比CPU更适用于流处理计算,因此GPU也被认为是一个SIMD的并行机或者流处理器,可以用于处理大规模数据集,使应用得到加速[9]。
2)向量运算架构
GPU本质上是一个向量计算模型架构,计算单元丰富,它的这种架构使它在处理大规模向量运算时体现出较高的性能[10],GPU运算过程如图1所示。
3.2GPU数据存储与访问
在GPU运算中,大量数据需要存储在纹理中,通过纹理坐标来访问纹理中的数据[11]。纹理相当于一个存储颜色值的二维数组,纹理中每个元素都存储着一个四维向量的颜色值。在进行GPU通用计算时,将大量的数据存储到纹理中[12]。纹理有多种像素格式,可以根据每种数据的精度和值域来选择合适的像素格式进行存储。如果存储的数据是布尔型或者是精度很低的整型,可以用低精度的8bitsARGB2222格式来存储;如果是高精度的浮点型数据,可以选用相应的浮点型纹理格式来存储[13]。在GPU通用计算中,浮点像素格式是比较通用的像素格式,其每个颜色通道都可以存储一个32位的浮点数据[14-15]。
在纹理中通过纹理坐标对数据进行索引。纹理坐标是一个二维的实数向量,一般纹理坐标的值域在O到1之间,索引属性值需要精确定位到纹理中的像素。例如在一个m×n尺寸的纹理中索引第x列第y行的像素则纹理坐标的计算方法是:
U=x/m+1/(2×m);V=y/n+1/(2×n)。
其中U和V分别为UV两个方向的纹理坐标值。
4系统实现与分析
4.1GPU下油管内液体粒子的数据组织
实验描述:模拟在上冲程过程中,原油液体在泵筒中由下往上的运动状态,通过机组实验数据对比在粒子数变化幅度相同的情况下,CPU和GPU的效率变化。
在上冲程过程中,抽油杆和柱塞上行,原油液体进入泵筒内部,此时液柱受到重力G(竖直向下)、推力ft(竖直向上)、摩擦阻力fm(沿着泵筒向下)。在泵筒内液柱向上运动,根据原油粒子特点,需要将以下粒子属性储存到纹理中:
Speed:用三维向量表示液体粒子的流动速度;
Live:粒子的生命阈值,存储为布尔型的标量,True表示粒子处于活动中,False表示粒子消亡;
Position:用三维向量存储粒子在世界坐标系下的位置。
由于液体粒子数量很多、大小不一,因此存放粒子时应采取纹理多样化的方式,根据不同精度选择合适的像素格式进行有效存储。例如:当存储低精度数据时,采用低精度的8 bits ARGB 2222格式,反之当存储高精度数据时,采用高精度的32 bits ARGB 8888格式。在GPU的通用计算中,为了满足计算的精度要求,通常浮点像素格式的每一个颜色通道都将存储一个8位或者32位的浮点数据。在存储数据的过程中既要考虑效率问题又要考虑存储空间的合理利用问题,通常的像素格式都是具有RGBA四个颜色通道,粒子的速度和位置都是三维向量,这样把粒子的速度和位置存放到纹理像素中的时候就会剩余一个通道,所以将粒子的Live属性储存到最后一个通道里,这样就充分合理的利用了存储空间。
格式选取完毕后开始创建存储粒子数据的纹理,确保每一个粒子对应一个像素点,这样像素点的最大值等于粒子的最大数目。每一个粒子的属性值存储在通过纹理中并通过各自的纹理坐标进行检索。
4.2液体粒子属性计算
在液体粒子产生、活动、消亡的过程中,把握并控制好粒子的属性,准确实时计算出粒子的速度、生命值、位置是绘制液体粒子的核心。首先编写像素着色器程序,通过GPU的通用计算将粒子属性的计算问题具体化,计算出每一个液体粒子的属性值并存储到纹理中以备使用。
利用GPU通用计算来计算每一个粒子属性的时候,粒子要经历产生、活动。消亡三个过程。由于在GPU下不能动态为粒子分配存储空间,所以每一个活动中的粒子的生命值由最大值降为零时,将此粒子的生命值、位置、速度进行初始化,作为新粒子重新加入到系统中。粒子系统开始运行后,粒子的数量随着时间的推移不断增加,粒子的属性以二维索引的形式存储在纹理中,在进行GPU通用计算时需要将二维索引转化为一维索引。对于二维索引来说,需要依靠纹理坐标来将其转换为一维索引,转换公式为:M=(U+V×H)×W,其中M是二维索引转换为一维索引的序列号,U和V为纹理坐标的两个分量,W和H为两个纹理坐标分量的大小。液体粒子属性值计算步骤如下:
1)液体在受力中的体积和数量的计算
原油液体在油管内流动的过程中,粒子系统在每一帧都要保持产生新的粒子以维持液体的流动,这样就要对新生成的粒子的速度、位置、生命值进行初始化。在上冲程过程中,油管内的液柱随着柱塞的上升而升高,所有液体粒子由下部初始位置升到最高点,初始点的所有粒子位置要添加一个随机值:P=P0+Prant,其中P是粒子的初始位置,P0是油管内液柱上升的初始位置,Prand是一个三维随机向量,此向量决定液柱的粗细。如图2为上冲程过程中原油液体进入泵筒内的示意图。此时泵筒内原油液体受重力G(竖直向下)、推力ft(竖直向上)、摩擦阻力fm(沿着泵筒向下)、泵筒内压力fp。如图2中x表示柱塞在时刻t的位移,表示柱塞位移为x时的液面高度,Lw是尾管长度。设任意时刻活塞t运动到x的位置,进入泵筒内原油液体体积为Vt。根据受力分析,将整个泵筒内空间分为两部分,Va为原油液体未充满泵筒前真空部分的体积,Vb为下半部分体积,其中Va=(x-y)A,Vt=Va+Vb,Vb=(Rs(x)-Rs(0))(1-Lw)(Ls+y)ABo,其中Rs是溶解油气比、Bo为原油体积系数与水的体积系数、A为压力系数。假设单位粒子体积为1,则有:1×Vnum=Vt,其中Vnum为粒子随体积变化的数量。
2)活动粒子属性值的计算
上冲程过程中,液体粒子受力向上运动,其位置和速度在不断地变化着。下面分析粒子的受力状况,根据里的平衡原理得出:fm+fp+G=ft,vm=vm-1+a×Δt,其中Vm是粒子的速度,Vm-1是上一帧粒子的速度,a是粒子的加速度,Δt是一帧持续的时间。在Y方向上,粒子的加速度由受力变化确定,在X和Z方向上粒子的速度分量不变。Pm=Pm-1+(a×Δt)×Δt,其中Pm是粒子的位置,Pm-1是粒子在上一帧的位置,Δt是一帧持续的时间。
3)消亡粒子属性值的计算
当液体粒子在油管内达到最高点时,粒子的生命值降为零,此时的粒子属性不在发生变化。在此粒子重新生成并再次加入粒子系统之前,既不需要计算其属性值,也不用被渲染。
4.3液体粒子绘制
计算完液体粒子的位置和速度,下一步需要读取粒子的属性值并进行绘制。运用纹理获取技术(Vertex Texture Fetch)来获取粒子的属性值,用tex2Dlod函数在顶点着色器读取纹理像素中的粒子属性值进行绘制,这样就不需要通过CPU传输,大大降低了CPU与GPU之间的通信,提高了渲染速度。下面进行粒子的绘制步骤:
1)建立顶点缓冲区
选择圆形作为绘制液体粒子的基本元素,组成每个粒子的最基本单位设定为四边形。首先建立顶点缓冲区,顶点的个数为四倍的粒子数,然后建立顶点索引,将每四个顶点组合在一起组成四边形,粒子以四边形的方式被绘制出来。创建出来的顶点缓冲区需要预先设计其格式。首先给液体粒子贴上纹理(此处选择普通水滴纹理),利用Texcoord0(纹理通道0的纹理坐标)给粒子的顶点的纹理坐标分别赋值为(0,1)(1,0)(0,1)(1,1),这样就可以通过纹理坐标0将水滴的纹理映射在粒子上,并判断出水滴纹理在粒子上的位置。其次要对粒子的属性值进行索引,将粒子的纹理属性存储在Texcoord1(纹理通道1的纹理坐标)中,这样就可以索引到粒子的属性值了。
2)顶点绘制
首先读取粒子的纹理属性并获取粒子在世界坐标系下的位置,由于粒子必须要正对着屏幕,所以要将粒子变换到相机坐标下,利用纹理坐标将粒子的四个顶点分别绘制在粒子的四个角上。由于GPU会将所有顶点绘制出来,即无论是活动中的顶点还是已经消亡的顶点,GPU都会无选择性的将其全部绘制出来,因此把消亡的粒子的顶点位置全部设定到一起,这样粒子就不会显示出来。顶点位置的计算公式如下:
Pt=(P×Mv+(U0,V0,0)×Size×Live)×Mp,其中Pt是最终计算的顶点位置,P是属性纹理中的粒子位置,U0和V0分别是顶点纹理坐标0的两个分量,Size是粒子的大小,Live是粒子的生命值,Mv和Mp分别是相机矩阵和投影矩阵。当粒子消亡时,粒子的Live值为零,粒子不需要被绘制出来;反之当粒子活动时,粒子的Live值为1,粒子顶点的位置会被正确的计算出来。
5效果与结论
本实验硬件环境为:Intel2.8GHz处理器,4G内存,NVIDIAGeForceGT640M显卡,操作系统是64位Window7系统,开发工具为VC++6.0和Directx9.0。图4.1为原油液体的流动效果图。表1为独立环境下CPU模拟的原油液体和GPU模拟的原油液体帧速率的比较。如图4.2为表一数据的对比图。
结论:针对有杆抽油系统采油过程中原油液体在油管内的受力运动,本文设计并建立了一个能满足高精确度、高效率、易使用的可视化环境。从表中我们可以看出,当原油液体粒子数较少时,CPU实现的速度比GPU还要快,但随着粒子数的增大,CPU实现的帧速率快速下降,而GPU实现的帧速率下降速度缓慢,当粒子数达到300万时,GPU仍然能够实时的绘制,而CPU实现每秒只有6.8帧,这说明GPU对大量粒子的处理能力远远高于CPU。
参考文献
[1]HopfMatthias,ErtlThomas.Accelerating 3D convolutionusinggraphicshardware.[J] Proceedings of IEEE Visualization.1999,28(05):56-70,62.
[2]FRANCISCO J Seron,Rafael Rodrigues,Eva Cerezo,AlfredoPina.AddingSupport for Highlevel Skeletal Animation[J]. IEEE Transactions onvisualization and computer graphics.2002,28(05):120-134,122.
[3]Peter Kipfer,Mark Segal,Rüdiger Westermann.UberFlow:a GPUbased particle engine[J]. Proceedings of the ACM SIGGRAPH/EUROGRAPHICS Conference on Graphics HardwareHWWS04.2004, 28(05):128-132,130.
[4]ARON E Lefohn,Shubhabrata Sengupta,Joe Kniss,et al.Glift:Generic,efficient,randomaccess GPU data structures[J]. ACM Transactions on Graphics.2006, 28(05):120-134,123.
[5]田苏昕.虚拟现实中大规模粒子系统的研究[J].沈阳航空工业学院学报,2009,30(3):149-150,160.
[6]徐阳东.基于粒子系统的不规则景物建模研究[J].山东师范大学学报,2009, 28(5):128-132,138.
[7]白玉.基于粒子系统的煤矿火灾模拟系统[J].吉林大学学报,2010,8(2):47-49.
[8]王涛. 基于GPU的程序分析与并行化研究[J].解放军信息工程大学学报,2010,8(2):47-51.
[9]胡杰. CPU-GPU异构平台计算模型的研究与应用[J].大连理工大学学报,2011,29(9):44-48.
[10]郭忠明. 基于CUDA的并行图像处理性能优化[J].大连理工大学学报,2012,99(4):49-58.
[11]方旭东. 面向大规模科学计算的CPUGPU异构并行技术研究[J].国防科学技术大学学报,2009,22(9):165-169.
[12]BUCK I,FOLEY T,HORN D,SUGERMAN J,HANRAHAN P.Brook for GPUs: Stream Computing on Graphics Hardware[J].Proceedings of SIGGRAPH,2004,28(4):55-59.
[13]Jizhu Lu,et.al.HMMerCell: High Performance Protein Profile Searching on the Cell/B.E.Processor[J].Proceeding of IEEE International Symposium on Performance Analysis of Systems and SoftwareISPASS,2008,33(7):94-98.
[14]S.García,A.Fernández,J.Luengo et al.A study of statistical techniques and performance measures for geneticsbased machine learning: accuracy and interpretability[J].Soft Computing,2009,83(7):104-108.
[15]Zhe Wei, Yixiong Feng, Jianrong Tan et al.. Multi-objective performance optimal design of largescale injection molding machine[J]. The International Journal of Advanced Manufacturing Technology 2009, 30(3):166-170,160.
猜你喜欢
工业设计(2022年4期)2022-05-17
江苏教育研究(2022年8期)2022-04-27
中国水运(2022年4期)2022-04-27
小学教学研究(2022年3期)2022-04-08
师道·教研(2022年1期)2022-03-12
物理教学探讨(2022年1期)2022-03-08
现代信息科技(2021年21期)2021-05-07
智富时代(2019年7期)2019-08-16
智富时代(2019年7期)2019-08-16
智富时代(2019年6期)2019-07-24
