
车载自组织网络中的大数据技术应用研究
2016-03-25 23:08:55李铎赖粤
无线互联科技 2016年3期
李铎 赖粤
摘要:大数据吸引了越来越多的关注并应用于不同的研究领域。文章重点阐述了车载自组织网络中的几点关键问题,具体映射大数据的4V特征,提出车载大数据处理平台框架,探索新的解决思路。
关键词:车载自组织网络;云计算;大数据;Hadoop; Spark
2011年5月,在“云计算相遇大数据”为主题的EMCWorld 2011会议中,EMC抛出了大数据(Big Data)概念。根据IDC的定义:大数据技术被设计用于在成本可承受的条件下,通过非常快速(velocity)的采集、发现和分析,从大量(volumes)、多类别(variety)的数据中提取价值(value),将是IT领域新一代的技术与架构。
在通信系统中大数据技术的实现主要是通过收集和整合来自异构服务所提供的数据。在异构网络环境中,深入的科学研究有待突破,使得技术服务更加贴近用户需求。这一块的研究主要集中包含有大规模分布式数据处理平台(Hadoop)提供的数据仓库产品和一些数据分析技术,比如机器学习和数据挖掘等。
大数据时下还是一个新兴的热门技术,不可避免地碰到诸多挑战,需要采用合适的技术去管理和分析大数据创造价值,增加预测的准确性,提高管理和安全性。
车载自组织网络(Vehicular AdHoc Networks,VANETs)被认为是智能交通系统的一部分,是以车为节点的一种特殊形式的移动自组织网络,在交通工程中有其自身的一些特点,近年来得到更广泛的关注。车载自组织网络由2个部分组成:车与车之间的通信(V2V),车与路边基础设施之间的无线通信(V21)。每辆自发参与的车变为一个中继或者无线节点连接其他的车辆,从而成为网络的一部分,覆盖的范围大概是l00-300m之间。一旦车辆行驶超出这个范围,网络就会掉线。
汽车现在已经是人们生活中的一部分,车辆作为移动终端越发智能化,在车载自组织网络中,数据由车辆和路侧单元配置的智能传感器件生成,从而导致不断增加的数据复杂度,特别是突发的数据量增大,需要结合云计算的弹性进行快速处理。基于车载自组织网络的车载安全、安保、信息娱乐、交通信息、导航、车辆故障诊断、预判等业务蓬勃发展。不难看出,在车载自组织网络应用需求的推动下,大数据无疑为其提供了坚实的技术后盾。因为无论是车辆的接入、服务内容的选择还是服务的精准性,都为大数据提供了有利的介入空间。大数据很平滑地拓展到了交通领域。通过应用大数据技术,可以从巨量的操作数据中获得更好的认知和了解,以期提高交通管理效率。
1 车载自组织网络中的大数据问题
大数据的特征通常用4个V来概括:大量化(Volume)、多样化(Variety)、快速化(Velocity)、价值密度低(Value),只有具备这些特点的数据,才是大数据。大数据是工程技术和策略技术的结合。大数据要求改变人们以往对精确性的苛求,转而追求混杂性,不再偏执于对因果关系的追问,转为追求相关关系,这种思维的转变是革命性的。
车载自组织网络前进的动力主要来自于大众的应用需求,交通安全、交通堵塞、车辆智能管理、环境保护等一系列问题。本文试图阐述将车载自组织网络的特征映射到大数据的属性,以期验证车载自组织网络中的有些问题可被当作大数据问题,并使用大数据技术进行解决分析处理。这些问题包括:
实时数据:车载自组织网络中的数据是实时更新的并存储在数据库中,生成很大的表给予路由决策使用。这部分对应大数据的体量大的特征,巨量的数据由不同的数据源实时生成。
变化的网络密度:车辆配置的智能传感器件产生不同形式的数据,网络的密度随着车辆密度而改变。这部分对应大数据的多样性特征,包含有结构化数据和非结构化数据。
高度动态拓扑和移动模型:车辆作为中继或者节点的网络中,由于速度的高度改变影响频繁的网络分片和网络密度的变化。这部分吻合大数据快速化特征,不单单是生成数据速率很快,而且也要求处理输入数据的耗时更短。
大规模网络和超强计算能力:大规模网络中汽车配置的智能传感期间增强了节点的计算能力,这要求抽取数据的价值来预测路由决策。这部分对应于大数据的价值密度特征,在对节点分析和预测行为以期论证某个理论或者做决策优化的时候很重要。
因此,车载自组织网络问题可以被当作一个很好的大数据分析的案例。
2 车载自组织网络的大数据分析
车载自组织网络的研究有助于改善交通系统、供应链管理以及物流。通过GPS、RFID、传感器、摄像头处理等装置获得道路、汽车和驾驶员成千上万的变量参数,车辆可以完成自身环境和状态信息的采集。弄清道路的交通流量、本地天气情况、驾驶员的操作习惯以及对突发情况的应变反应。这个规模是巨大的。仅百万公里的道路、百万辆的汽车、百万名的驾驶员几年下来提供的数据量就很令人震惊。当下,唯有采用大数据技术可在合理的时间对这些巨量的数据进行处理才能获取有价值的东西。
在汽车及其相关的设备已经或正在向数字化转变的今天,汽车产业生态圈急需大数据技术对数据进行处理,并使之产生真正可见的价值。从技术上讲,它包括大数据的收集、转化、存储、分析、共享、可视化和应用集成等领域,需要对产生于各系统终端的结构化、非结构化数据进行采集,对数据分析挖掘,建立相关模型,并针对客户及行业需求。
一个简单的服务应用就能够产生、收集很多类型的数据。数据产生的速度很快并且要求快速的处理。这些数据隐藏了部分有价值的信息,必须进行深入的挖掘、分析。车载大数据的处理,就是挖掘其中的隐含价值,将大数据从某个方面进行加工处理得到特定业务的便利性甚至是预见性的核心数据。传统的关系型数据库处理不了这么巨大的数据,大数据必然无法用单台的计算机进行处理,必须采用分布式计算架构。对海量数据的挖掘必须依托云计算的分布式处理、分布式数据库、云存储和虚拟化技术,需要采用新的技术来处理这么巨量车载大数据。本文重点考察2个具有代表性的技术:
Hadoop是一个能够对大量数据进行分布式处理的软件框架,用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力高速运算和存储。Hadoop的框架的最核心的设计就是:HDFS和MapReduce。HDFS实现存储,而MapReduce实现分析处理。主要应用批量处理,计算完成的数据如需数据仓库的存储,存入Hive中,然后进行展现。
Spark为大数据的多种计算场景提供了一个通用的计算引擎,它立足于内存计算,兼顾数据仓库、流处理和图计算等多种计算范式,是大数据系统领域的全栈计算平台。针对源源不断的数据,可以尽快处理,不产生积压。在迭代处理、流式处理中表现优异,提供的MLib组件实现了很多的机器学习算法。
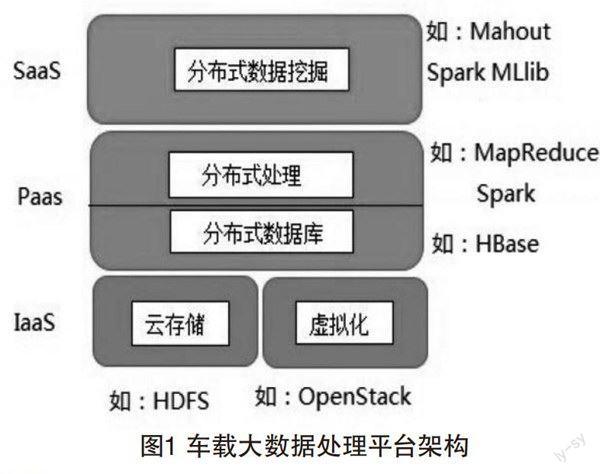
本文综合上述2个技术提出车载大数据处理平台框架,如图1所示,可兼容离线、近实时和实时环境下的不同业务场景。当大数据联合车载自组织网络提供服务时,车载大数据所包含的丰富的兴趣点和海量资料,通过整合地图资源和LBS领域的优秀数据,挖掘客户深层次的需求,为客户提供增值应用服务。
3 结语
随着云时代的来临,大数据技术也渗透到了不同的研究和应用领域。车载自组织网络作为以车为节点的一种特殊形式的移动自组织网络,借助大数据技术的力量,可以焕发新的生机。
猜你喜欢
电脑知识与技术(2016年21期)2016-10-18 22:11:15
大学教育(2016年9期)2016-10-09 08:54:03
科技视界(2016年20期)2016-09-29 13:34:06
科技视界(2016年20期)2016-09-29 10:53:22
