
一种改进的LZ77无损数据压缩算法设计
2016-03-21 00:47张永棠
佛山科学技术学院学报(自然科学版) 2016年1期
张永棠
(广东东软学院计算机科学与技术系,广东佛山528225)
一种改进的LZ77无损数据压缩算法设计
张永棠
(广东东软学院计算机科学与技术系,广东佛山528225)
摘要:研究了LZ77无损数据压缩算法的原理,在对LZ77各种改进算法进行深入分析的基础上,结合TUNEDBM单模式匹配算法,提出了一种新的改进的LZ77无损数据压缩算法。实验结果表明,改进的LZ77压缩率比原LZ77稍有降低,但在压缩时间有很明显的优势,尤其当文件较小时,这种优势体现得更加明显。
关键词:通信编码;无损压缩;LZ77;算法设计;TUNEDBM
随着大数据和云计算的应用,给互联网数据的存储和传输带来了更大的挑战。应用数据压缩技术解决这一难题是重要手段。为了达到最好的压缩效果,无损压缩法(也叫熵编码)是一种最常用的压缩编码方法。目前无损压缩主要有两大分支,一种是基于字符概率统计的,如Huffma等;一种是基于字典的,如LZ系列[1]。
现在的字典压缩算法大都可以追溯到由ZIV和LEMPEL[1-2]提出的LZ77和LZ78算法。日常使用的通用压缩工具有WinZip,RAR,GZip,ACE,ZOO,TurboZip,Compress,JAR等,此外,许多网络设备中内置的压缩程序都可以归结为这些算法及其变种。虽然现有的LZ78其压缩思想有较大变化,它采用了保存先前所遇到的字符串的字典方法来取代传统的滑动窗口。由于字典中的表项很少,弥补初期的低效,逐渐显出自己的优势。但是LZ78算法实现起来较为复杂,而且需要额外的内存开销,这对资源有限且处理能力不足的平台数据压缩并不适合,比如单片机。对LZ77进行改进,可使其能实现嵌入式平台的数据压缩。
1 LZ77压缩算法
LZ77压缩是一种基于字典及滑动窗的无损压缩技术,广泛应用于通信传输。LZ77的基本原理是:以经常出现的字母组合(或较长的字符串)构建字典中的数据项,并且使用较短的数字(或符号)编码来代替比较复杂的数据项。数据压缩时,将从待压缩数据中读入的源数据与字典中的数据项进行匹配,从中检索出相应的代码并输出。从而实现数据的压缩。
LZ77算法执行流程如下:
步骤1:从输入的待压缩数据的起始位置,读取未编码的源数据,从滑动窗口的字典数据项中查找最长的匹配字符串。若结果为T,则执行步骤2,若结果为F,则执行步骤3;
步骤2:输出函数F(off,len,c)。其中,off为滑动窗口边界的偏移,len为可匹配的长度,c为下一个字符。然后将窗口向后滑动到len++,继续步骤1;
步骤3:输出函数F(0,0,c),其中c为下一个字符。并且窗口向后滑动(len + 1)个字符,执行步骤1。
从上面对LZ77算法的分析可以看到,LZ77算法是二叉树遍历查找最优良的字符串匹配,改变以往的逐一文本比对,提高了LZ77的压缩速度。该匹配算法的时间复杂度可以表示为O(n*q),其中n为滑动窗口编号,并且执行n++,q为平均可匹配长度。如果n大到一定程度,则这种压缩速度会下降到让人无法接受的程度,则对实时性要求较高的嵌入式平台不能胜任。
因此,很多压缩程序都对LZ77进行了改进,提高搜索的速度。应用得较多的一种是用二叉搜索树的数据结构来改进,这也是LZSS对LZ77进行的一个关键改进。建立二叉搜索树的方法的确对查找匹配串的速度有很多的提高,但是需要耗费一定的空间去存储这棵二叉树结构,并且需要不断维护二叉搜索树,增加了程序的复杂性和时间耗费[3]。有人将KMP应用到LZ77的字符串查找中,但是KMP本身实现起来较为复杂,不能真正提高LZ77的压缩速度。本文提出的压缩算法将LZ77与BM单模式匹配算法结合起来,可以有效提高LZ77的压缩速度。
2 TUNEDBM算法
BM算法是一种比较新颖的单模式匹配算法,其基本思想是从右向左的把模式同文本做比较[4]。基于BM算法主要有3种算法:QS算法、HORSPOOL算法、TUNEDBM算法,它们都是BM算法的简化。其中TUNEDBM被证明是单模式匹配算法中最快的算法[5]。BM算法只使用了坏字符规则,在搜索阶段只查找待压缩模式串的最后一个字符。如果不匹配则指针向前一个字符移动,直到找到它。
采用BadCharacter对字符表P中字符的偏移值进行计算,并将计算结果在跳跃表bmBc中存储并对比。若待压缩的字符没有在表P中出现,偏移值为m;否则偏移值为m-i-1(i为输入字符在表P中的位置),表示如下:
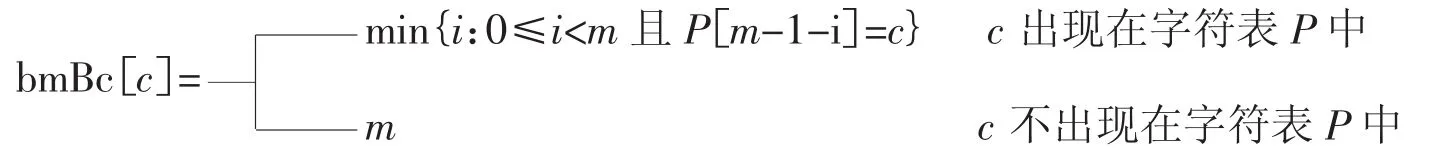
3一种改进的LZ77无损压缩算法
LZ77算法中的history窗口就相当于TUNEDBM中的目标串T,lookahead窗口的内容就相当于模式串P,在history窗口中查找lookahead的最长匹配串的过程其实就相当于模式匹配[5]。但是TUNEDBM并不能直接应用到LZ77中。
TUNEDBM直接应用到的LZ77中存在以下几个方面的问题:
(1)TUNEDBM算法中,字符表P的长度是固定的,是在匹配操作前确定的。所以可以用模式串的最后一个字符和正文中的字符进行比较。而LZ77中的lookahead匹配串的长度是未知的,最长的匹配串的长度是在窗口匹配完后才确定。不知道模式串最后一个字符,就不能运用TUNEDBM的查找思想;
(2)TUNEDBM算法中,需要首先对模式串进行预处理,也就是使用坏字符规则,以计算每字符在失配时滑动的长度。由于LZ77中的待匹配串预先不能确定,就无法使用坏字符规则进行预处理;
(3)TUNEDBM算法返回的是匹配是否成功和成功的匹配位置,而LZ77搜索算法要寻找的是最长匹配串长度和匹配的位置。
针对上面的问题,必须对TUNEDBM算法实现做必要的调整。调整的思路主要是这样的:事先并不计算失匹配函数,而是当比较失败时再计算失配字符的滑动距离。刚开始查找时,让模式串P的长度m 为0,内容是整个未编码的字符串。当找到更长的匹配串时,更新m的值,这样当将窗口遍历时,就可以找到最长的匹配串。
3.1预处理阶段
改进后的LZ77压缩算法不是直接计算出待压缩数据流的滑动距离,而是采用预处理的方式在待压缩数据流中找到的最长匹配值m。当出现失配字符ch时,调用skip()函数计算出其最大滑动距离,直接滑动。改进后LZ77压缩的skip()函数算法描述如下:

3.2查找最长匹配串
在窗口中查找最长匹配串的过程和TunedBM算法非常类似。设当前的窗口为T,待编码数据流为P,最长匹配字符长度为m,滑动窗口的长度为n。下面对匹配成功与不成功进行分析,如图1所示。

图1滑动窗口查找匹配字符串示意图
假设待编码数据流P[m-1]位置的字符与窗口T中相应字符进行匹配比较。若匹配不成功,则调用skip()函数,求出窗口位置为T[j+m-1]的最大滑动距离s,将j的指针地址右移到j+s的位置,继续重复这个过程直至读取的待编码字符为’/0’匹配结束;若成功,则从匹配的字符串的头部开始逐一匹配,并记录下匹配长度tml,直到数据流位置P[tml-1]与窗口位置T[j+tml-1]匹配失败。根据tml与m的返回值:
若tml≤m,则查找更长的匹配串失败,地址指针指向字符T[j+m],继续进行匹配;
若tml>m,则查找更长的匹配串成功,更新匹配长度m=tml,调用skip()函数求出T[j+tml-1]位置的最大滑动距离,文件指针j=j+1,继续进行匹配;
从上面描述可以看出,改进后的LZ77算法如果某一个字符比较失败后,立即停止从后往前依次匹配,转而跳到数据流的开关位置进行匹配,从而提高数据编码搜索速度,达到快速的查找最长匹配串的目的。整个查找最长匹配串算法描述如下:
算法:FindLongestStr
输入:窗口T,待编码字符串P,窗口长度max_win_size
输出:最长匹配串长度len和窗口偏移


返回最长匹配串长度和窗口偏移;
4实验结果及分析
为了验证改进后LZ77压缩算法的效果,对改进前后的压缩效率进行了对比,如表1所示。本实验中,取滑动窗口长度为1024,并用变长编码Gamma编码来表示匹配串的长度值,这样可以提高压缩率。

表1改进前后的LZ77算法压缩性能对比
从表1可以看出,改进的LZ77压缩率比原LZ77稍有降低,但是改进后的LZ77比原LZ77在压缩时间有很明显的优势,尤其当文件较小时,这种优势体现得更加明显。当文件较大时,两种压缩耗时都较长,改进的LZ77时间优势也并不明显,这是由LZ77本身压缩算法的局限性决定的。本文提出的压缩算法适合于实时性要求较高的场合,比如基本于嵌入式系统的数据采集与传输,一次压缩的数据并不大,对实时性特别要求。
参考文献:
[1]ZIV J, LEMPELA. A universal algorithm for sequential data compression[J]. IEEE Transactions on Information Theory,1977,23(5): 337- 342.
[2]ZIVJ, LEMPELA. Compression ofindividual sequence via variable- rate coding[J]. IEEE Transactions on Information Theory, 1978, 24(5): 530- 536.
[3]刘存良,张秉权,黄河燕.基于嵌入式系统的改进快速压缩算法[J].兵工自动化, 2003, 22(1): 46- 48.
[4]BOYER R S, MOORE J S. Afast stringsearchingalgorithm[J]. Commun ACM, 1977, 20(10): 762- 772.
[5]巫喜红,凌捷.单模式匹配算法研究[J].微计算机信息, 2006, 22(8): 202- 204.
【责任编辑:周绍缨410154121@qq.com】
An improved LZ77 lossless data compression algorithm design
ZHANGYong- tang
(Department of Computer Science and Technology, Guangdong Neusoft Institute, Foshan 528225, China)
Abstract:This paper studies the principle of LZ77 lossless data compression algorithm based on the in- depth analysis of various LZ77 algorithms combining with TUNEDBMsingle mode matching algorithm, and proposes a new improved LZ77 lossless data compression algorithm. Experimental results show that the improved LZ77 compression ratiois slightlylower than that ofthe original LZ77, and the improved LZ77 is more obvious than the original LZ77 in the compression time, especiallywhen the file is small, this advantage is more obvious.
Keywords:Communications encoding; lossless compression; LZ77; algorithmdesign; TUNEDBM
文章编号:1008- 0171(2016)01- 0057- 05
作者简介:张永棠(1981-),江西南昌人,广东东软学院副教授。
收稿日期:2015-09-20
中图分类号:TP301.6
文献标志码:A
