
CVS中基于多参考帧的最优多假设预测算法*
2016-02-25 12:37杨春玲欧伟枫
华南理工大学学报(自然科学版) 2016年1期
杨春玲 欧伟枫
(华南理工大学 电子与信息学院, 广东 广州 510640)
CVS中基于多参考帧的最优多假设预测算法*
杨春玲 欧伟枫
(华南理工大学 电子与信息学院, 广东 广州 510640)
摘要:现有的视频压缩感知(CVS)多假设预测方法均以当前块在参考帧对应搜索范围内的所有搜索块为假设块,造成求解线性权值系数的计算复杂度过高和预测精度受限.针对该问题,文中提出了一种基于多参考帧的最优多假设预测视频压缩感知重构算法.该算法首先从多个参考帧中选取出与当前块测量域绝对差值和(SAD)最小的一部分搜索块作为当前块的最优假设块集,然后对假设块进行自适应线性加权,充分地挖掘视频帧间相关信息,提升了预测精度,同时降低了求解线性权值系数的计算复杂度;最后对测量值进行帧间DPCM量化,以提高视频压缩效率和率失真性能.仿真实验表明,与现有的视频压缩感知重构算法相比,文中算法具有更高的视频重构质量.
关键词:压缩感知;视频重构;多参考帧;多假设预测;量化
压缩感知(CS)[1-2]的核心思想是,对于可压缩信号(在某个变换域可稀疏表示),可以用一个与变换基不相关的测量矩阵将高维信号投影到一个低维空间上,通过求解非线性优化问题从低维投影中以高概率重构出原信号,以降维的方式实现了信号采样与压缩的同时进行.压缩感知理论为节省信号采集资源和降低信号采集复杂度提供了强有力的理论支撑,近年来在图像/视频压缩成像、无线传感器网络等领域受到了广泛的关注[3- 4].
在图像/视频压缩感知领域,为了提升率失真性能,已有不少作者进行了大量的深入研究.现有的方案大致可分为两类:①在采集端利用测量值进行视频时间相关性分析或图像纹理复杂度分析,根据视频的时间相关度或图像纹理复杂度进行自适应采样率分配,使有限的码率资源得到最大化利用,从而在相同采样率下提高图像/视频重构质量[5-7].文献[5]提出了利用分块图像纹理信息的自适应采样方案,先在采集端通过测量值计算出图像各子块的灰度熵,再根据各子块的灰度熵自适应分配采样率;文献[6]提出了一种利用测量值计算图像块样本方差的方法,根据图像块样本方差自适应调整采样率;文献[7]提出了一种自适应帧采样率分配算法,利用视频帧间相关性的不同,以当前帧对帧组重构的贡献率为参考标准自适应分配各帧采样率.上述自适应采样方法虽然使有限的码率资源得到了合理利用,有效提高了图像/视频的重构质量,但以增加采集端复杂度为代价,违背了压缩感知采集端简单的初衷.此外,文献[8]通过反馈信道把重构端的码率控制信息反馈回采集端进行自适应调整采样率,但反馈信道的引入并不符合实际应用.②通过研究重构端高性能的重构算法来达到提升率失真性能的目的.对于视频压缩感知,在重构端如何充分利用视频信号固有的时间相关性进行高质量的视频重构是研究视频压缩感知的一个核心问题.文献[9]提出了一种自适应稀疏重构算法,利用参考帧中的滑动块自适应估计当前块的Karhunen-Loeve变换基,得到当前块更稀疏的表示;文献[10]基于轮换测量矩阵提出了一种测量域运动估计方法,可以直接在测量域进行运动估计;文献[11]基于测量域相关模型也提出了一种测量域运动估计方法,但运动补偿精度并不高.文献[12]提出了一种像素域运动估计方法,在重构端多次迭代地进行四分之一像素精度的运动全搜索和BCS-SPL[13]残差重构,以高计算复杂度为代价换取了非关键帧质量的一定提升;文献[14]提出了一种多假设(MH)运动补偿方法,以参考帧中某一搜索范围内所有滑动块作为当前块的假设块,通过求解各个假设块与当前块的测量值距离所形成的Tikhonov正则项约束下的最小二乘问题,得到加权系数,再用这些加权系数对假设块进行线性组合来预测当前块,此方法充分利用了各个假设块的信息,有效地克服了块效应,与文献[12]相比预测精度得到较明显的提升,因此该运动补偿方法被一些文献所采用[15-17].文献[15]分别将时空AR模型和MH模型与全变差模型相结合,形成两种不同的联合时空特征的预测-残差重构模型,有效利用了视频信号的时间和空间相关性,提高了视频重构质量;文献[16]提出的变采样率测量方法根据不同块具有的不同场景复杂度和变换强度自适应调整采样率,并与多假设预测-残差重构方法相结合得到了较好的重构性能;文献[17]联合考虑了待重建图像块及对应残差值的梯度稀疏性,提出了一种基于联合TV最小化的残差重建模型,并基于Split Bregman方法提出了该模型的迭代求解算法,该残差重构算法与多假设预测相结合得到了较高的重构质量.虽然文献[14]的多假设预测方法在视频压缩感知中已经得到了较广泛的使用,但这种多假设预测方法由于假设块的选取不恰当,导致求解假设块线性权值时计算复杂度过大,且由于假设块集合中混有大量低匹配度块,使预测精度的提升受限.
鉴于视频压缩感知多假设预测方法能获得高效的运动补偿效果,但其存在计算复杂度过高、预测精度受限等不足,因此,文中提出了一种最优假设块选择方案(HSS),以降低求解多假设线性权值的计算复杂度,提升预测精度.另外,结合传统视频编码标准H.264中的多参考帧技术[18],文中提出了基于多参考帧的最优多假设预测算法(MRMH),利用更多的时间相关信息来得到更好的补偿帧.最后,为了进一步提高视频压缩感知的压缩率,文中将文献[19]的分块图像DPCM量化方法应用到视频压缩感知中,提出了帧间DPCM量化方法,以获得高效的率失真性能.
1视频压缩感知中的多假设预测
文中采取分块压缩感知(BCS)[20]的采样方式,将每个视频帧分成b个不重叠的B×B大小图像块,对每个子块采用相同的高斯随机矩阵Φ进行独立测量,
yi=Φxi,i=1,2,…,b
(1)
式中,xi为第i个图像块的B2维列矢量,Φ为M×B2维矩阵,M维列矢量yi为第i个图像块的测量值,定义M/B2为采样率.
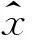
(2)
由于是在重构端进行运动估计,因此没有码率的限制,为了得到更高的预测精度,可以充分发挥多假设预测的优势.文献[14]提出的多假设预测是用一组假设块的线性组合来作为当前块的预测,即
(3)
式中:B2×K维矩阵Hi为该组假设块,K为假设块的数量,Hi的各列即为各假设块的向量化形式;ωi∈RK为最佳线性组合系数矢量,
(4)
在式(4)中,由于测量点数M通常小于假设块数量K,即方程个数小于未知数个数,此时式(4)是病态问题,文献[14]在式(4)的基础上加入由各个假设块与当前块的测量域距离所形成的Tikhonov正则项来约束该问题,即
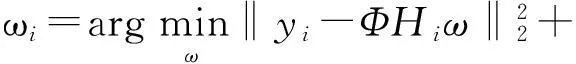
(5)
式(5)有如下闭式解:
(6)
虽然多假设运动补偿的精度较单假设预测有了明显的提升,但文献[14]的多假设预测方法以当前块在参考帧相应搜索范围内的所有滑动块作为假设块,这种对假设块不加以任何选择的做法使得多假设预测无论在精度上还是计算复杂度上都存在着较大的改进空间.
在预测精度上,并非所有搜索块都能对当前块提供有用信息.事实上,在所有的搜索块中,有相当一部分的搜索块与当前块的匹配度是很低的,若以所有搜索块作为假设块,这些低匹配度块将会成为干扰块,降低预测精度.
在计算复杂度上,当求解线性加权系数时,由于式(6)的计算复杂度随着矩阵尺寸的增加而迅速增加(约为O(K3)),以全部搜索块作为假设块将会导致计算复杂度过高.
既然并非假设块的数量越多就会预测得越精确,而过多的假设块又是造成多假设预测计算复杂度高的一个关键因素,因此,文中提出了一种最优假设块选择方案,并结合多参考帧技术提出了一种基于多参考帧的最优多假设预测算法.
2多参考帧的最优多假设预测
2.1 最优假设块选择方案
文中提出的最优假设块选择方案如下:在所有搜索块中,只保留和当前块测量值的SAD最小的前若干块作为最优假设块,通过求解式(6)得到最优加权系数,对最优假设块进行线性组合,得到最终预测块.按照这种方式选择的假设块有以下两个优点:①降低求解假设块线性权值的运算量.由于减少了假设块数量,从而极大地减少了利用式(6)求解假设块线性权值的运算量,降低了多假设运动补偿算法的复杂度.②提高预测精度.在所提出的HSS方案中,由于只用和当前块匹配度较高的那部分搜索块作为假设块,线性地表示当前块,剔除了大量与当前块匹配度较低的块,从而排除了许多低匹配度块的干扰,因此与全假设块(文献[14]将全部搜索块作为假设块)相比预测精度得到了有效的提升.
可见,文中HSS方案不仅提升了多假设预测算法的预测精度,还有效降低了其计算复杂度.此外,该方案还具有较强的可扩展性,即可在该方案的基础上方便地加入其他技术(如多参考帧技术),以进一步提高多假设预测的性能.
2.2 MRMH算法描述
运动估计中的多参考帧技术能有效地提高编码效率,已被H.264视频编码标准所采纳[18].为了进一步提高预测块质量,文中把最优假设块选择方案和多参考帧技术相结合,提出了基于多参考帧的最优多假设预测算法:对多个参考帧进行运动全搜索,并从所有搜索块中挑选出测量域SAD准则意义下的一部分最优假设块来线性地表示当前块.由于所选的假设块来自于多个相邻参考帧,可充分挖掘各参考帧的有用信息,因此能进一步提升预测精度.
文中提出的基于多参考帧的最优多假设预测算法结构如图1所示,图中每个图像组(GOP)的第1帧为关键帧,其他帧为非关键帧.关键帧采样率R1一般都高于非关键帧采样率R2.关键帧采用MH-BCS-SPL重构算法[21]进行帧内多假设预测重构,非关键帧采用文中的MRMH算法进行重构.考虑到前后关键帧的重要性,把运动估计时用到的参考帧分为长期参考帧和短期参考帧,将当前GOP及下一GOP的关键帧作为长期参考帧,而当前解码帧的前若干已解码帧作为短期参考帧,对每个非关键帧进行预测时,都会用到这两个长期参考帧.
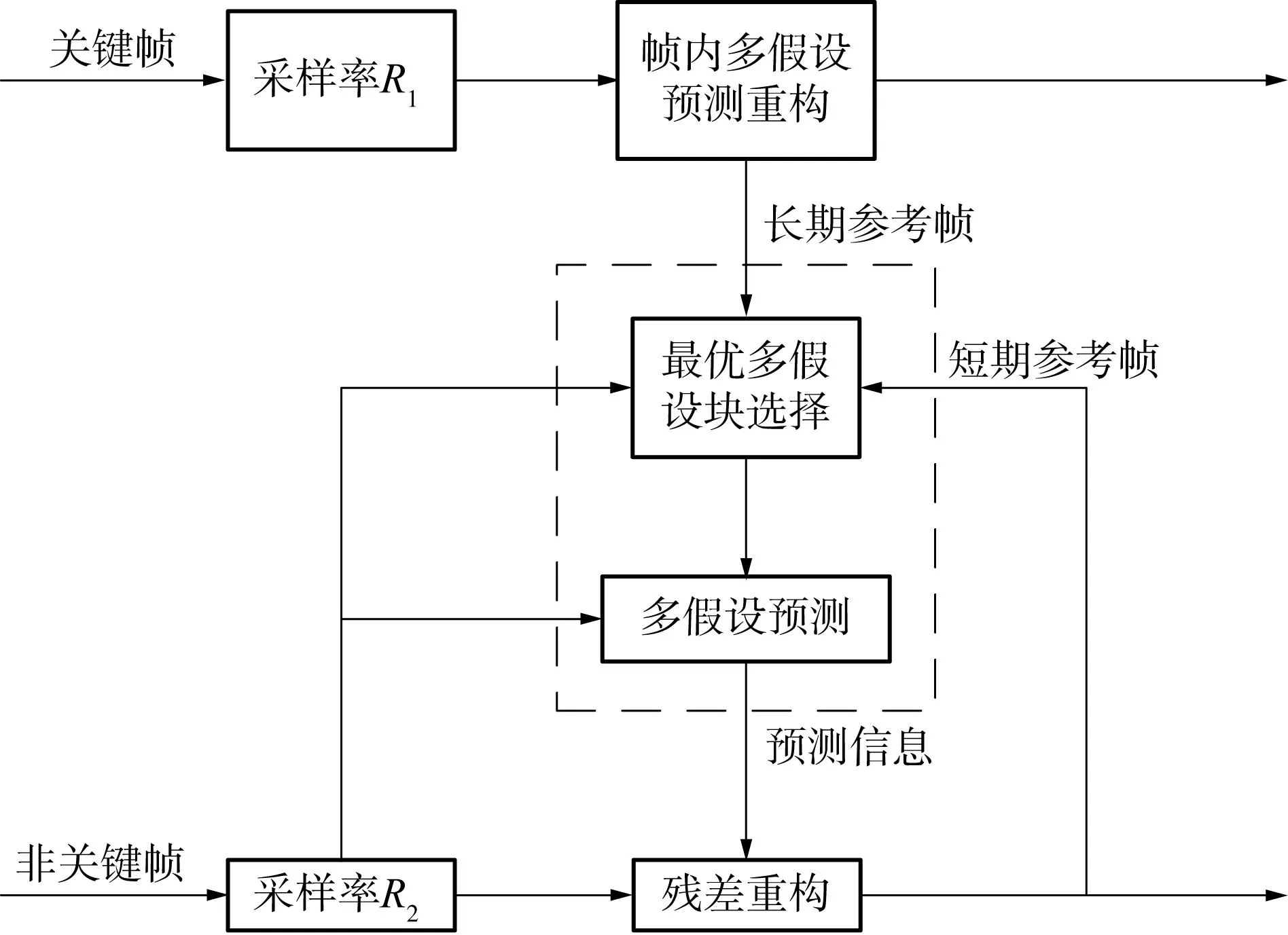
图1 MRMH算法的结构Fig.1 Architecture of MRMH algorithm
为降低运动全搜索的计算复杂度,同时考虑到前后关键帧的重要性,文中提出了一种高效的运动搜索策略:对长期参考帧及最近邻的短期参考帧进行较大范围的运动全搜索,对其余短期参考帧进行快速运动搜索.从长期参考帧和短期参考帧的所有搜索块集合中选取出测量域SAD最小的一部分搜索块作为最优假设块集,然后进行多假设预测.得到预测帧后,采用BCS-SPL-DDWT重构算法[13]进行残差重构,得到最终重构帧.
对短期参考帧的快速运动搜索方案是,先利用前面多帧的运动矢量对各参考帧进行运动矢量预测,再以预测运动矢量所指的位置为中心进行小范围搜索,以避免大范围运动搜索,减少计算量[18].另外,文中所提算法还利用了自适应加权中值矢量滤波技术[22],以防止个别错误运动矢量的错误累加延播.
文中以GOP=8为例给出MRMH算法的具体实现过程.在该结构下,最大参考帧数为4时各帧及其参考帧的示意图见图2.其中,第1帧为当前GOP的关键帧,第9帧为下一个GOP的关键帧,称第5帧为中间帧,称第2~4帧为前半个GOP,第6~8帧为后半个GOP.MRMH算法的具体实现步骤如下:
(1)对当前GOP及下一GOP的关键帧进行帧内多假设预测重构,并把重构图像作为当前GOP非关键帧的长期参考帧;
(2)对前半个GOP进行前向运动估计和BCS-SPL-DDWT残差重构解码,并把每一解码帧作为下一解码帧的短期参考帧,每帧的最大参考帧数为4;
(3)对后半个GOP进行后向运动估计解码,过程与步骤(2)一样,只是解码顺序相反;
(4)对中间帧进行双向运动估计解码,中间帧的解码不再进行快速搜索,而直接对所有参考帧进行同等范围的全搜索,并取中间帧前后同等数目的已解码帧作为短期参考帧,依然取前后关键帧作为长期参考帧.至此,当前GOP解码完成.
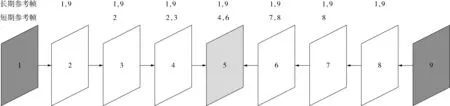
图2 一个GOP内各帧的参考帧情况Fig.2 Reference frame pattern of each frame within a GOP
3实验与结果分析
本实验分为两部分,一部分是采集端的测量值直接传到重构端进行视频信号重构;另一部分是在采集端增加测量值帧间残差量化技术,量化后再传到重构端进行视频重构,以进一步提高压缩效率.
每个GOP的关键帧采用MH-BCS-SPL算法[21]进行独立帧内重构,非关键帧采用文中的MRMH算法进行重构,其中最大参考帧数设为4(2帧长期参考帧,2帧短期参考帧),长期参考帧和最近邻短期参考帧的搜索范围取±16像素,其余短期参考帧的搜索范围为±6像素.最优假设块的数量随采样率的不同而不同,采样率0.1、0.2、0.3、0.4、0.5分别对应的假设块数为81、100、121、144、169.由于采样率越高,每个块的测量值数量越多,对不同假设块的区分能力越强,大量仿真实验也验证了该理论,实验中选取假设块的数量是综合考虑重构质量与重构时间所得到的一个折中经验值.所有分块大小均为16×16.
3.1 采集端测量值无量化情况下
为了方便和现有文献的实验结果进行对比,文中对GOP=4和GOP=16两种情况进行实验分析.
为了和现有最新文献[12,14-15]的实验结果进行比较,实验条件完全按文献中给出的设置,采用3组CIF@30Hz的标准视频序列Foreman、Mobile、Football的前21帧(GOP=4,共5组GOP)进行实验,不同采样率下5种算法的平均PSNR如表1所示.
表1GOP=4时5种算法的PSNR比较
Table1ComparisonofPSNRamongfivealgorithmswhenGOPis4
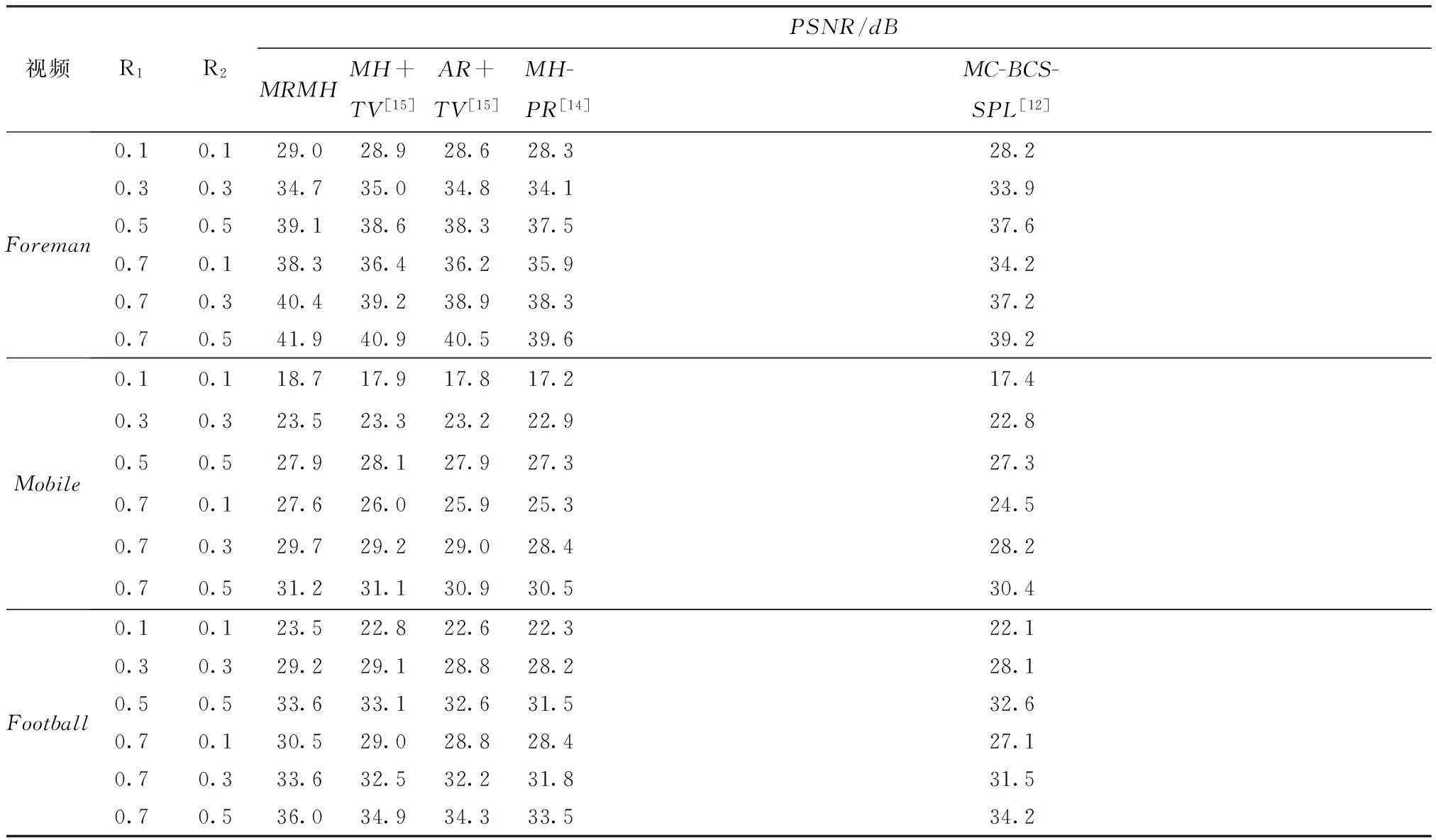
视频R1R2PSNR/dBMRMHMH+TV[15]AR+TV[15]MH-PR[14]MC-BCS-SPL[12]Foreman0.10.129.028.928.628.328.20.30.334.735.034.834.133.90.50.539.138.638.337.537.60.70.138.336.436.235.934.20.70.340.439.238.938.337.20.70.541.940.940.539.639.2Mobile0.10.118.717.917.817.217.40.30.323.523.323.222.922.80.50.527.928.127.927.327.30.70.127.626.025.925.324.50.70.329.729.229.028.428.20.70.531.231.130.930.530.4Football0.10.123.522.822.622.322.10.30.329.229.128.828.228.10.50.533.633.132.631.532.60.70.130.529.028.828.427.10.70.333.632.532.231.831.50.70.536.034.934.333.534.2
从表1可见,MRMH算法的PSNR值明显高于其他算法,特别是关键帧和非关键帧的采样率不同时(R1=0.7>R2,这种结构更适合实际应用),文中算法的优越性更加明显,在采样率为0.1时文中算法对于Foreman、Mobile、Football序列的平均PSNR值比MH+TV算法[15]分别高出了1.9、1.6、1.5dB.这是因为文中算法将当前GOP的前后关键帧作为长期参考帧,因而高质量重构的关键帧信息得到了有效利用,从而大幅提升了非关键帧的重构质量.对于关键帧和非关键帧采样率相同的情形,文中算法的PSNR值仍然在多数情况下高于其他算法,但优势不如关键帧和非关键帧采样率不同时那么明显.
在实验条件完全相同的情况,采用5个CIF@30Hz标准视频序列Soccer、Mobile、Foreman、Coastguard、Mother-daughter来测试文中算法和BCS-SPL-DDWT算法[13](每个序列均为289帧,GOP长度为16,共18组GOP),实验结果如图3所示.由图可见,对于每一序列,文中算法的重构质量与帧内独立重构相比均有显著的提升,对于运动缓慢的Mother-daughter序列,在低采样率0.1下的增益达到9.6dB,而对于运动较为剧烈的Soccer序列,采样率为0.1时增益为2.5dB.可见,文中算法即使在低采样率下仍然具有较好的重构性能.
3.2 采集端测量值帧间残差量化情况下
为了进一步降低码率,提高视频压缩感知的压缩率,文中将文献[19]的分块图像压缩感知DPCM量化方法应用到视频中,提出了视频压缩感知帧间DPCM量化方法:在采集端对当前帧的真实测量值与前一帧的量化测量值的差值进行均匀量化,在重构端对残差进行解量化并加上前一帧的量化测量值得到当前帧的量化测量值.由于相邻视频帧的测量值残差与视频帧自身测量值相比能量小了很多,因此与各帧单独均匀量化相比有效地节省了码率,获得了高效的率失真性能,其量化框图如图4所示.
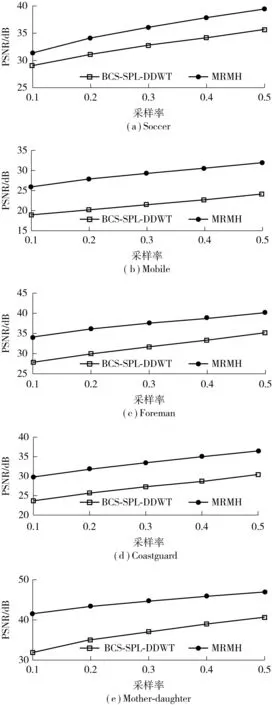
图3 GOP=16时两种算法的PSNR比较Fig.3 Comparison of PSNR between two algorithms when GOP is 16
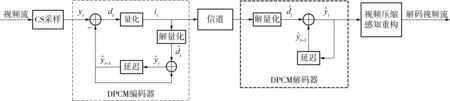
图4 视频压缩感知帧间DPCM量化框图Fig.4 Architecture of frame-based DPCM quantization in compressed video sensing
由于现有文献中还没有给出类似条件的实验结果,因此,该部分实验结果没有和其他视频压缩感知算法做对比.文中仅给出了文中算法和传统视频编码标准H.264帧内编码的率失真性能.
在GOP长度为16时,采用5个QCIF@15Hz测试序列Soccer、Coastguard、Foreman、Hall、Suzie对文中算法进行仿真,每个序列为150帧,其中帧率为15Hz的序列是从帧率为30Hz的序列隔帧抽取所得.H.264帧内编码在H.264/AVC参考软件JM18.6平台上实现,将所有编码帧设为I帧,量化步长QP的取值为20,24,28,…,44.实验结果如图5所示.
由图5可见,在对测量值进行帧间DPCM量化后,MRMH算法的压缩率得到有效的提升:对于运动缓慢的Suzie序列,PSRN为30dB时对应的码率约为73kb/s,此时的压缩率约为1/42;对于运动中等剧烈的Foreman序列,PSRN为30dB时对应的码率约为255kb/s,此时的压缩率约为1/12.从图5还可以看出,MRMH算法与H.264帧内编码还存在着较大的率失真性能差距,而且差距随着码率的增加逐渐扩大,对于运动剧烈的Soccer序列,码率为500kb/s时PSNR差距达到10dB.可见,文中视频压缩感知重构算法的率失真性能与传统视频编码仍然有较大的差距,研究高性能的视频压缩感知重构算法仍然是一个关键而艰巨的问题.
实验中发现,关键帧采样率R1、非关键帧采样率R2、关键帧量化精度B和非关键帧量化精度b的选取对码率和重构性能都有影响,文中通过遍历各种不同的量化参数组合(R1,R2,B,b)得到最优率失真性能曲线.如何在实际中根据信号特征选取最优参数组合是下一步研究的重点.
4结论

图5 MRMH算法在帧间DPCM量化下与H.264帧内编码的率失真性能比较Fig.5 Comparison of rate-distortion performance between MRMH algorithm under frame-based DPCM quantization and H.264 intra-coding
文中提出了基于多参考帧的最优多假设预测视频压缩感知重构算法.首先,针对多假设预测提出了一种最优假设块选择方案(HSS),该方案通过选取与当前块测量域SAD最小的一部分搜索块作为最优多假设块,在使多假设线性权值系数的求解计算复杂度大大降低的同时有效地提升了预测精度.其次,引入多参考帧技术,从多个参考帧中选取最优假设块,进一步挖掘了视频帧间相关信息,使预测精度进一步提升.最后,为了进一步提高压缩效率,文中提出了视频压缩感知帧间DPCM量化方案,获得了高效的率失真性能.仿真实验结果表明,与现有的视频压缩感知重构算法相比,文中MRMH算法具有更高的视频重构质量,但与传统视频编码标准H.264帧内编码相比仍然存在较大的率失真性能差距.如何根据不同视频序列特征及不同采样率自适应地设定最优多假设块数量,以及基于不同信号特征的最优量化参数设置方法,是后续研究的重点.
参考文献:
[1]CANDESEJ,ROMBERGJ,TAOT.Robustuncertaintyprinciples:exactsignalreconstructionfromhighlyincompletefrequencyinformation[J].IEEETransactionsonInformationTheory,2006,52(2):489-509.
[2]DONOHODL.Compressedsensing[J].IEEETransactionsonInformationTheory,2006,52(4):1289-1306.
[3]QAISARS,BILALRM,IQBAlW,etal.Compressivesensing:fromtheorytoapplications,asurvey[J].JournalofCommunicationsandNetworks,2013,15(5):443- 456.
[4]曾春艳,马丽红,杜明辉.前向预测与回溯结合的正交匹配追踪算法 [J].华南理工大学学报(自然科学版),2012,40(8):14-19.
ZENGChun-yan,MALi-hong,DUMing-hui.Lookaheadandbacktracking-basedorthogonalmatchingpursuitalgorithm[J].JournalofSouthChinaUniversityofTechnology(NaturalScienceEdition),2012,40(8):14-19.
[5]王蓉芳,焦李成,刘芳,等.利用纹理信息的图像分块自适应压缩感知 [J].电子学报,2013,41(8):1506-1514.
WANGRong-fang,JIAOLi-cheng,LIUFang,etal.Block-basedadaptivecompressedsensingofimageusingtextureinformation[J].ActaElectronicaSinica,2013,41(8):1506-1514.
[6]李然,干宗良,崔子冠,等.图像分块压缩感知中的自适应测量率设定方法 [J].通信学报,2014,35(7):79-85.
LIRan,GANZong-liang,CUIZi-guan,etal.Adaptivemeasurementratesettingmethodinblockcompressedsensingofimages[J].JournalofCommunications,2014,35(7):79-85.
[7]胡伟,朱卫平,康彬,等.帧测量率自适应分配的分布式视频压缩感知 [J].信号处理,2014,30(5):575-582.
HUWei,ZHUWei-ping,KANGBin,etal.Distributedcompressivevideosensingbyadaptiveallocationofframemeasuringrate[J].JournalofSignalProcessing,2014,30(5):575-582.
[8]LIUZ,WANGAH,ZENGB,etal.Distributedcompre-ssivevideosensingwithadaptivemeasurementsbasedonstructuralsimilarity[J].ChineseJournalofElectronics,2013,22(3):594-598.
[9]LIUY,LIM,PADOSDA.Motion-awaredecodingofcompressed-sensedvideo[J].IEEETransactionsonCircuitsandSystemsforVideoTechnology,2013,23(3):438- 444.
[10]NARAYANANS,MAKURA.Compressivecodedvideocompressionusingmeasurementdomainmotionestimation[C]∥ProceedingsofIEEEInternationalConfe-renceonElectronics,ComputingandCommunicationTechnologies.Bangalore:IEEE,2014:1-6.
[11]GUOJ,SONGB,LIUHX,etal.Motionestimationinmeasurementdomainforcompressedvideosensing[C]∥ProceedingsofIEEEInternationalConferenceonCompu-terandInformationTechnology.Xi’an:IEEE,2014:441-445.
[12]MUNS,FOWLERJE.Residualreconstructionforblock-basedcompressedsensingofvideo[C]∥ProceedingsofIEEEDataCompressionConference.Snowbird:IEEE,2011:183-192.
[13]MUNS,FOWLERJE.Blockcompressedsensingofimagesusingdirectionaltransforms[C]∥ProceedingsofIEEEInternationalConferenceonImageProcessing.Cairo:IEEE,2009:3021-3024.
[14]TRAMELEW,FOWLERJE.Videocompressedsen-singwithmultihypothesis[C]∥ProceedingsofIEEEDataCompressionConference.Snowbird:IEEE,2011:193-202.
[15]李然,干宗良,崔子冠,等.联合时空特征的视频分块压缩感知重构 [J].电子与信息学报,2014,36(2):285-292.
LIRan,GANZong-liang,CUIZi-guan,etal.Blockcompressedsensingreconstructionofvideocombinedwithtemporal-spatialcharacteristics[J].JournalofElectro-nics&InformationTechnology,2014,36(2):285-292.
[16]练秋生,田天,陈书贞,等.基于变采样率的多假设预测分块视频压缩感知 [J].电子与信息学报,2013,35(1):203-208.
LIANQiu-sheng,TIANTian,CHENShu-zhen,etal.Blockcompressedsensingofvideobasedonvariablesamplingratesandmultihypothesispredictions[J].JournalofElectronics&InformationTechnology,2013,35(1):203-208.
[17]常侃,覃团发,唐振华.基于联合总变分最小化的视频压缩感知重建算法 [J].电子学报,2014,42(12):2415-2421.
CHANGKan,QINTuan-fa,TANGZhen-hua.Reconstructionalgorithmforcompressedsensingofvideobasedonjointtotalvariationminimization[J].ActaElectronicaSinica,2014,42(12):2415-2421.
[18]KIMSE,HANJK,KIMJG.AnefficientschemeformotionestimationusingmultireferenceframesinH.264/AVC[J].IEEETransactionsonMultimedia,2006,8(3):457- 466.
[19]MUNS,FOWLERJE.DPCMforquantizedblock-basedcompressedsensingofimages[C]∥Proceedingsofthe20thEuropeanSignalProcessingConference.Bucharest:IEEE,2012:1424-1428.
[20]GANL.Blockcompressedsensingofnaturalimages[C]∥Proceedingsofthe15thInternationalConferenceonDi-gitalSignalProcessing.Cardiff:IEEE,2007:403- 406.
[21]CHENC,TRAMELEW,FOWLERJE.Compressed-sensingrecoveryofimagesandvideousingmultihypo-thesispredictions[C]∥Proceedingsofthe45thAsilomarConferenceonSignals,Systems,andComputers.PacificGrove:IEEE,2011:1193-1198.
[22]GUOJ,KIMJ.Adaptivemotionvectorsmoothingforimprovingsideinformationindistributedvideocoding[J].JournalofInformationProcessingSystems,2011,7(1):103-110.
Multi-Reference Frames-Based Optimal Multi-Hypothesis Prediction
Algorithm for Compressed Video Sensing
YANGChun-lingOUWei-feng
(School of Electronic and Information Engineering, South China University of Technology, Guangzhou 510640, Guangdong, China)
Abstract:The existing multi-hypothesis prediction methods for compressed video sensing (CVS) select all possible blocks within the search space of reference frames as the hypotheses, which causes a high computation load in solving linear weighting coefficients and impairs prediction accuracy. To address this issue, a multi-reference frames-based optimal multi-hypothesis prediction algorithm for CVS reconstruction is proposed in this paper. In the algorithm, first, those search blocks which have the smallest sum of absolute differences (SAD) from current block in measurement domain are selected from multi-reference frames as the optimal hypotheses of current block. Then, the hypotheses are weighted both linearly and adaptively to fully excavate the temporal correlation between video frames. Thus, the prediction accuracy is improved and the computation load in solving linear weighting coefficients is reduced. Finally, the compressed sensing measurements are quantized through the frame-based DPCM quantization to improve video compression efficiency and rate-distortion performance. Simulation results show that, in comparison with the existing CVS reconstruction algorithms, the proposed algorithm achieves higher video reconstruction quality.
Key words:compressed sensing; video reconstruction; multi-reference frames; multi-hypothesis prediction; quantization
doi:10.3969/j.issn.1000-565X.2016.01.001
中图分类号:TN919.8
作者简介:杨春玲(1970-),女,博士,教授,主要从事图像/视频压缩研究.E-mail:eeclyang@scut.edu.cn
*基金项目:国家自然科学基金资助项目(61471173)
收稿日期:2015- 04-13
文章编号:1000-565X(2016)01- 0001- 08
Foundation item: Supported by the National Natural Science Foundation of China(61471173)
猜你喜欢
历史教学·高校版(2016年10期)2017-01-05
吉林省教育学院学报(2016年8期)2016-12-26
科学与财富(2016年18期)2016-12-22
电子技术与软件工程(2016年20期)2016-12-21
电脑知识与技术(2016年26期)2016-11-24
电脑知识与技术(2016年23期)2016-11-02
科教导刊·电子版(2016年24期)2016-10-29
电脑知识与技术(2016年21期)2016-10-18
考试周刊(2016年79期)2016-10-13
科技视界(2016年10期)2016-04-26
