
结合负荷形态指标的电力负荷曲线两步聚类算法
2016-02-16 05:07:35彭勃张逸熊军董树锋李永杰
电力建设 2016年6期
彭勃,张逸,熊军,董树锋,李永杰
(1.浙江大学电气工程学院,杭州市 310027;2.国网福建省电力有限公司电力科学研究院,福州市 350007;3.国网厦门供电公司,福建省厦门市 361000)
结合负荷形态指标的电力负荷曲线两步聚类算法
彭勃1,张逸2,熊军3,董树锋1,李永杰1
(1.浙江大学电气工程学院,杭州市 310027;2.国网福建省电力有限公司电力科学研究院,福州市 350007;3.国网厦门供电公司,福建省厦门市 361000)
为改善基于欧式距离的全维度负荷曲线聚类算法在负荷形态相似度上的不足,提出了结合负荷形态特征指标的电力系统负荷曲线两步聚类算法。算法第一步采用基于欧式距离的负荷曲线聚类方法获得初步聚类结果,并通过负荷聚类评价指标选取一次聚类算法和聚类数目;第二步基于负荷形态特征指标采用监督学习算法对负荷进行重新分类。之后比较了不同算法的分类效果,最后给出了聚类结果的应用建议。算例结果表明,所提出的两步聚类算法可以改善传统的负荷曲线聚类方法在形态相似度上的不足,在二次分类方法中,支持向量机(support vector machine,SVM)算法表现较好,所提出的方法具有实际应用意义。
负荷聚类;电力数据挖掘;负荷形态;监督学习算法
0 引 言
随着智能电网的发展,配用电侧的智能量测装置广泛普及,电力系统获得了海量的用电侧数据。如何对用户的用电数据进行数据挖掘是当前电力系统面临的重要问题[1]。对电力系统负荷曲线进行聚类分析,研究电力用户的用电行为特点,进而对用户进行合理的分类是配用电数据挖掘的基础[2]。电力系统不同时段电能成本不同,统一的电价模式不能反映电能成本的时序变化。在电力市场中,可采用分时电价或分类电价来反映电能成本的时序变化。在分类电价制定中,电力服务供应商需要根据用户的用电行为特点对用户进行分类,使同类别内部用户用电行为相似,不同类别用户用电行为具有差异,基于不同类别用户的用电时序特点进行差异化营销[3-4]。此外,电力系统负荷曲线聚类分析在不良数据检测[5]、负荷控制[6]、状态估计[7]以及需求侧管理[8]等方面均有应用。传统的电力系统负荷分类方法是基于负荷曲线的欧式距离,采用Kmeans、模糊C均值(fuzzy C-means,FCM)、层次聚类法、自组织映射神经网络(self-organizing map,SOM)[9-12]等算法实现。采用全维度负荷曲线的欧式距离进行聚类的优点是考虑负荷曲线全部时段的数值,具有最全面的信息。不足之处在于,采用欧氏距离的实质是几何平均距离的相近性,不能充分保证时间序列的形态或轮廓的相似性[13-14]。此外,采用全维度负荷曲线的欧式距离进行聚类还易受噪声和尖峰值影响。实际工程中常提取某些指标来表示负荷的形态信息,如负荷率、峰谷差率、峰期负载率、谷期负载率[15-17]。聚类结果应使同类用户的负荷形态指标接近,不同类别用户的负荷形态特征指标具有差异度[15]。但负荷特征指标是对原始曲线的降维,直接根据负荷特征指标进行聚类对原始负荷曲线的信息具有较大的损失[18-19]。
为改善基于欧式距离的全维度负荷曲线聚类在负荷形态相似度上的不足,提出结合负荷形态特征指标的电力系统负荷曲线聚类方法。算法首先采用基于欧式距离的负荷曲线聚类方法获得初步聚类结果,然后基于负荷形态特征指标采用监督学习算法对负荷进行重新分类。首先介绍本文算法的基本思想;然后结合算例介绍算法的具体实现细节,对比不同算法的二次分类效果;最后给出聚类结果的实际应用建议。
1 电力负荷曲线两步聚类算法
1.1 经典聚类算法
(1)Kmeans聚类算法。Kmeans算法是一种属于划分的聚类算法,其基本思想是以空间中k个点为中心,对靠近中心点的样本进行归类,反复迭代中心点的数值,直到目标函数收敛或者达到最大迭代次数。
(2)FCM算法。FCM算法与Kmeans算法类似,也是通过反复迭代得到最终的聚类结果。与Kmeans算法不同的是,在FCM算法中,每个样本对于不同的聚类中心通过隶属度来表示,而不是只从属于某个中心。
(3)Ward算法。Ward算法又称离差平方和法,是层次聚类法的一种。算法先将每个样本单独作为一类,然后对类逐级进行合并,每次合并时将使离差平方和增加幅度最小的两类进行合并。
1.2 经典监督学习算法
(1)分类回归树(classification and regression tree,CART)。CART[20]是决策树算法的一种,CART是一种二叉树,每个非叶子节点根据某个属性将当前样本分割为2个子集,属性的选择采用基尼指数(Gini index)。对于每个属性,考虑所有可能的划分,如果划分效果越好,则基尼指数越小。选择该属性产生最小的基尼指数的子集作为其分裂子集。在此规则下从上至下直到生成整棵树。
(2)随机森林(random forest,RF)。RF[21]算法是一种集成学习算法,将众多CART组合在一起形成一片森林,在随机森林中,每棵树之间的训练样本相互独立,是由bagging算法从总样本中有放回地抽取与原始样本等数量的样本。在CART学习过程中,内部节点的分支是随机选取若干属性值进行的,最终形成一片决策树群。随机森林的最终结果为各个决策树的结果进行投票决定。当利用bagging生成训练集时,对于每棵决策树,原始样本中约有37%的样本不会出现在训练样本中,这些样本成为袋外样本,用这些数据估计模型的性能成为袋外估计。
(3)支持向量机(support vector machine,SVM)。SVM[22]是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,在解决小样本、非线性及高维模式识别中表现出一定的优势。支持向量机来源于线性分类器,支持向量机的学习策略是寻找最优超平面使其分类间隔最大化,最终可转化为一个凸二次规划问题的求解。对于低维不可分问题,支持向量机通过非线性变换函数φ(x)将样本空间x映射到高维空间中,使其在高维空间中线性可分。通过引入核函数解决了高维空间中的内积运算,从而解决了非线性分类问题。
(4)K最邻近(K-nearest neighbors,KNN)。KNN[23]是一种简单而有效的监督学习算法,KNN算法从训练集中找到和新数据最接近的k个样本,根据最多的类别判定为新样本的类别。
1.3 聚类评价指标
常用的负荷聚类评价指标有平均适用度指标(mean index adequacy,MIA),聚类分散度指标(clustering dispersion indicator,CDI),相似度矩阵标(similarity matrix indicator,SMI),Davies-Bouldin 指标(Davies-Bouldin indicator,DBI),类内类外离差平方和比率(ratio of within cluster sum of squares to between cluster,variation WCBCR)等[12],本文采用MIA指标评价聚类的效果。
首先定义距离函数
(1)
式中:li,t为第i个用户t时刻的负荷或者第t个特征指标;T为时段数目。
MIA指标为
(2)
式中:Ωj为第j类所有负荷向量的集合;K为类别数目;l为负荷向量;ωj为第j类负荷向量的平均值;Nj为第j类负荷的总数。LMIA值越小聚类效果越好。
1.4 两步聚类算法
本文所提出的两步聚类算法的流程图如图1所示。负荷曲线聚类应选取用户典型负荷曲线,可取用户一段时间日负荷曲线的平均值,或系统典型日的用户负荷曲线。聚类前需对负荷进行标准化处理,以消除不同负荷数量级差异对聚类结果的影响。数据标准化后分别采用不同的聚类算法和聚类数目对全维度负荷曲线进行聚类,通过负荷聚类结果评价指标选取聚类算法和聚类数目,得到第一步的负荷分类结果。
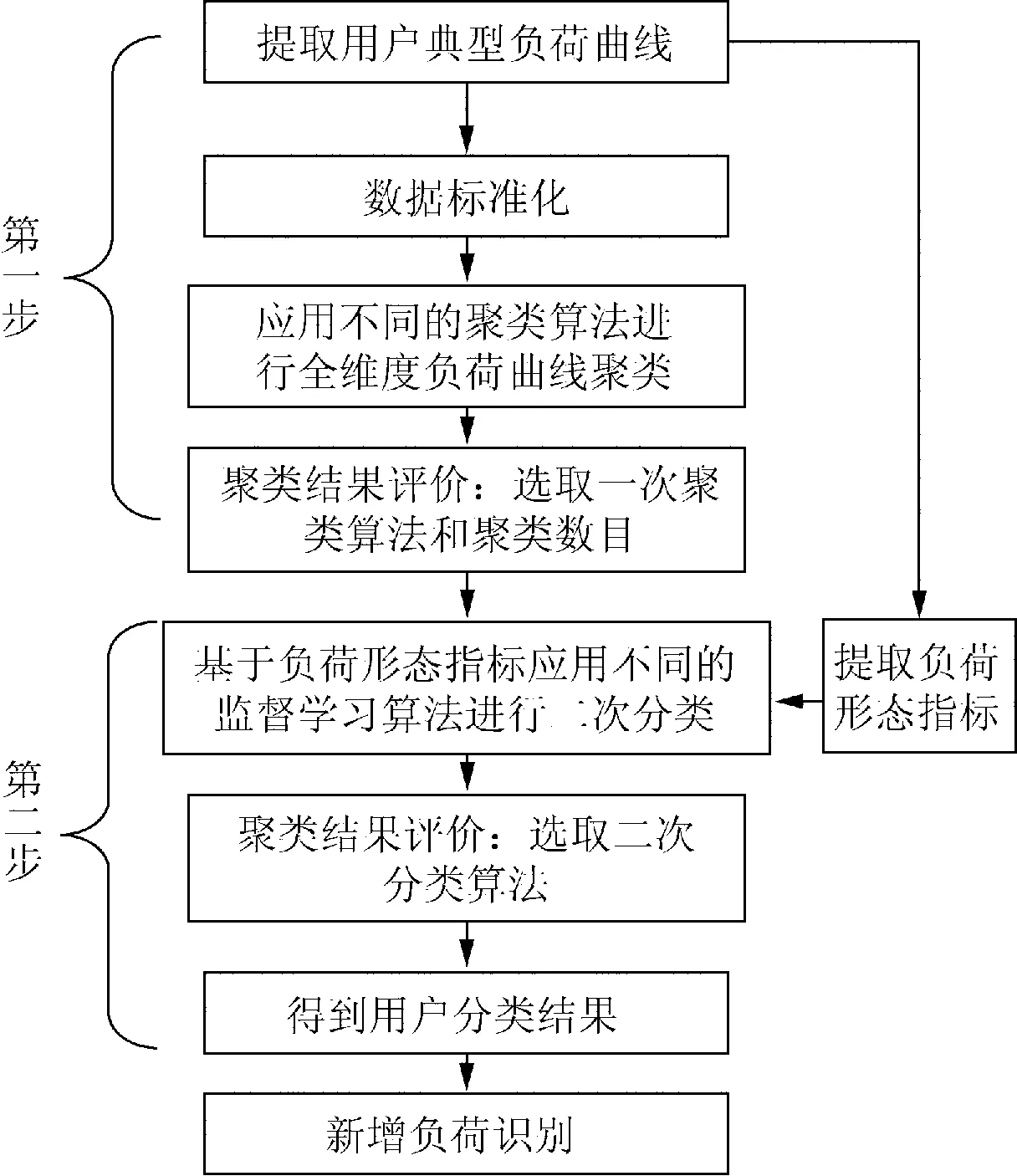
图1 算法流程图Fig.1 Algorithm flow chart
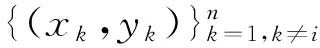
2 一次聚类算法以及聚类数目的选取
首先采用全维度负荷曲线聚类方法获得初步结果。由于数据来源有限,采用我国南方某省电网春季典型工作日负控端的负荷数据,剔除不良数据后得到2 712个用户的日96点有功功率曲线。采用峰值标准化方法[9]对负荷曲线进行标准化处理,即pij,norm=pij/pimax。式中:pij中为用户i第j个时段的功率;pimax为用户i全天最大用电功率;pij,norm为标准化之后的功率。采用Kmeans、FCM以及Ward算法对负荷曲线进行聚类,聚类数目选取4到25。其中Kmeans算法和FCM算法为不稳定聚类算法,聚类结果受初始聚类中心选择的影响,本文以Ward算法聚类结果的聚类中心以及随机选取5次初始聚类中心分别作为聚类中心初值进行聚类,取MIA指标值最小的结果作为最终的聚类结果。3种算法聚类结果的MIA指标如图2所示,FCM聚类算法在聚类数目为8时为所有类别的MIA指标最低点所形成的曲线的拐点,因此本文一次聚类选择FCM聚类算法,聚类数目选择8类。
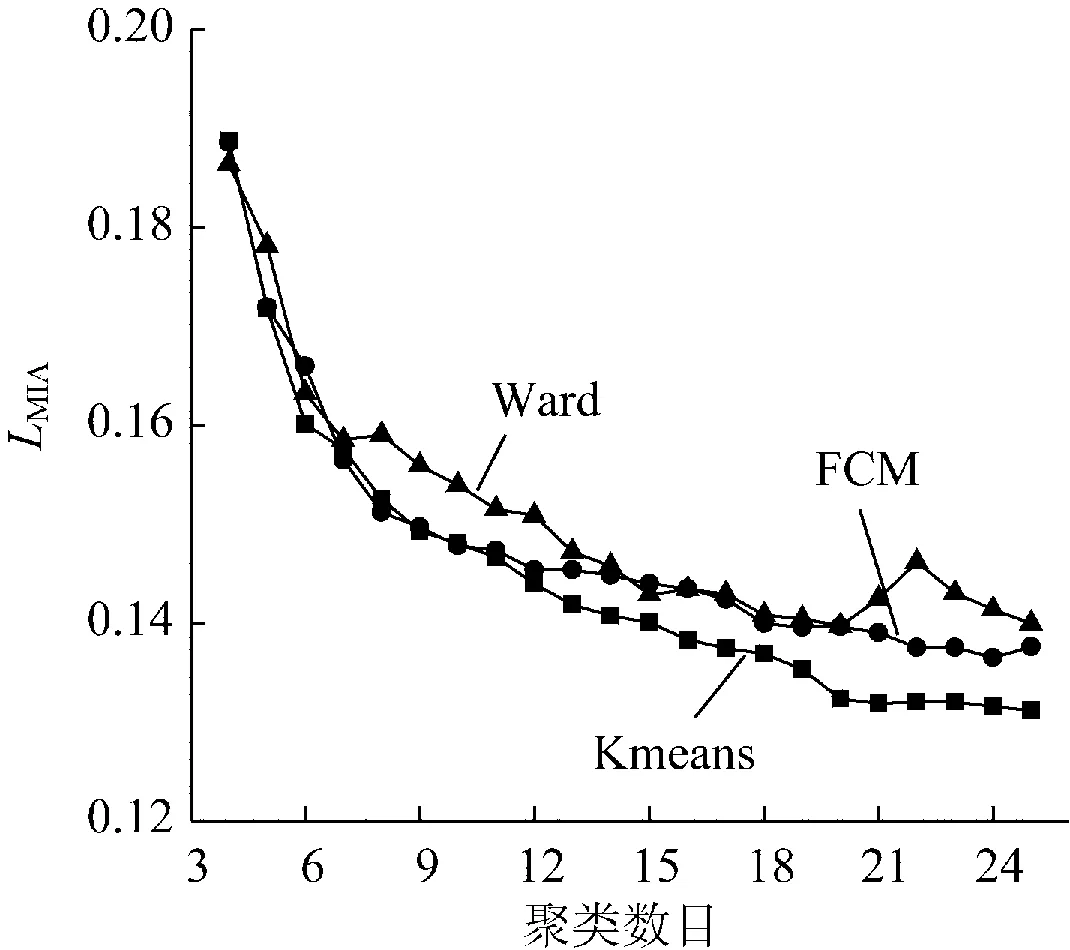
图2 MIA指标与聚类数目的关系Fig.2 Relationship between MIA index and number of clusters
3 基于负荷形态特征指标的二次分类
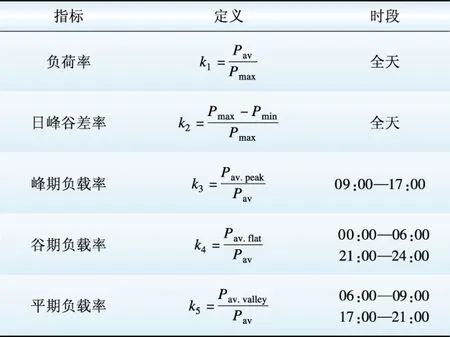
二次分类之前需提取负荷形态特征指标,基于文献[15-17]及实际工程经验,本文选取的负荷形态特征指标如表1所示。
本文采用CART算法、RF算法、SVM算法及KNN算法分别进行二次分类。在RF算法中,由于有袋外数据的存在,对于每个训练样本,约有37%的树没有采用该样本进行训练。在不考虑树的数目情况下,采用不包含某一样本的所有树对该样本进行分类等同于采用除该样本外的样本进行RF算法训练,然后对该样本进行分类。因此,RF算法只需要训练一次就可以完成二次分类,而CART算法和SVM算法对每个样本都需要训练一次,训练次数为样本的总数目。KNN算法是一种惰性学习方法,它不需要对样本进行预先训练,直到需要分类的时候才进行分类。
表1 负荷形态指标
Table 1 Load shape indexes
3.1 二次分类可视化分析
本文的二次分类是基于负荷的形态特征指标与类群的特征指标的相似度,采用监督学习方法来实现。相似度的另一种评估方法是基于负荷的特征指标与类群特征指标中心的距离。为了直观表现本文所提方法的二次分类效果,并与按类群特征指标中心的距离进行重新划分的方法对比,采用主成分分析法对负荷特征指标降维以实现聚类结果的可视化。主成分分析法是对原始变量进行线性组合来构造不相关的较少的新变量来代替原来较多的变量。选取新变量的原则是较多地反映原始变量的信息,用方差来表征其所含的信息,方差越大所含信息越多。对负荷形态指标(k1,k2,k3,k4,k5)进行主成分分析。所得的主成分中,方差占比最大的两个主成分的方差比率分别为45.01%和31.42%,采用这两个主成分进行聚类可视化。为了清晰地展示效果,选取一部分区域进行展示。图3为采用基于欧式距离的负荷曲线聚类方法的聚类结果,图4为对图3的结果采用SVM进行二次分类的结果。原始的2 712个样本中有281个样本被重新分类。虽然降维会导致原始数据信息的损失,进行降维可视化不能完全反映样本在负荷特性指标空间的分布情况,但从图中仍可看出二次分类可以使得负荷被重新划分到负荷特性指标相近的类别,同时二次分类使得不同类别之间的负荷特性指标空间的边界更加明显。以负荷指标中心进行重新分类的结果如图5所示。从图5中可以看出该方法由于只考虑类群中心,忽略了原始聚类结果在负荷特性指标空间的分布情况,25.15%的用户被重新分类,对基于负荷曲线进行聚类的原始聚类结果影响较大。而基于监督学习的二次分类可以保持一次聚类结果在负荷特性指标空间的分布情况,保留了一次聚类可以考虑曲线全维度信息的优点。
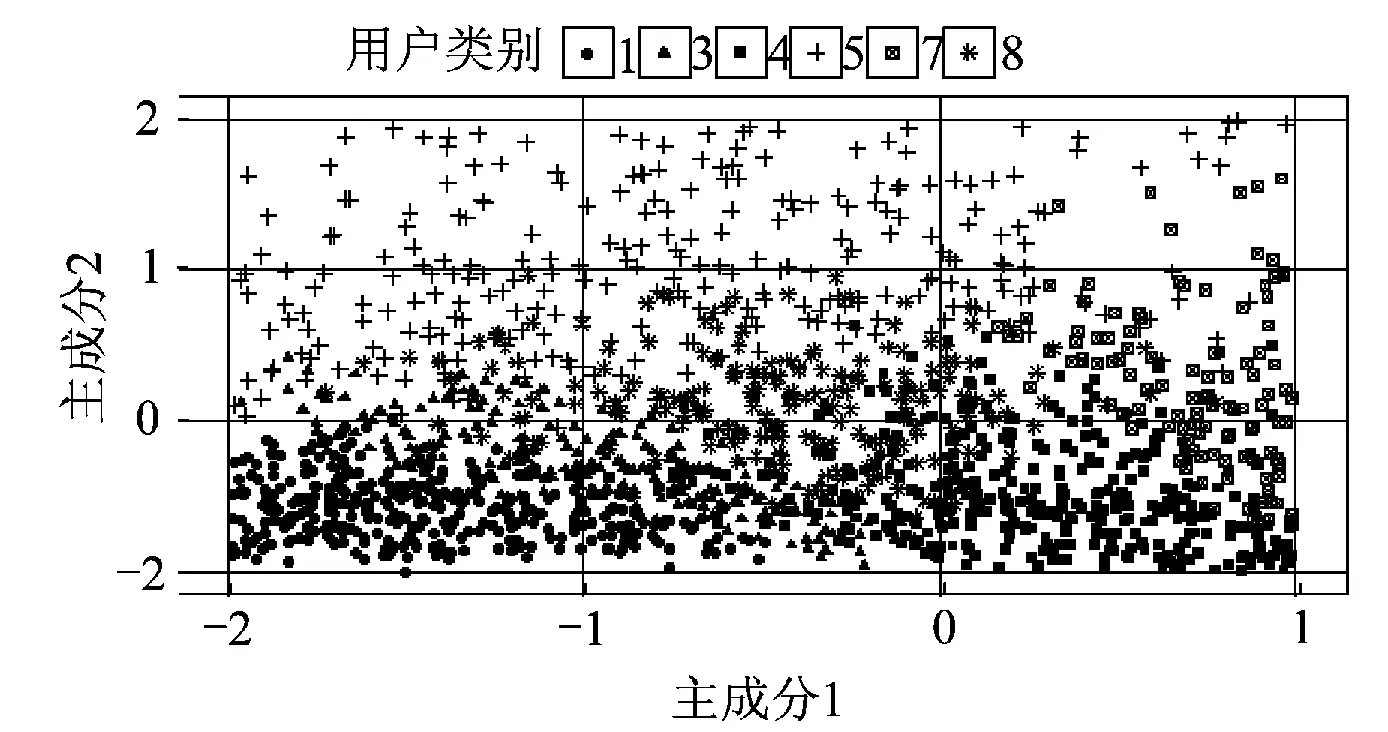
图3 一次聚类结果Fig.3 Result of first-step clustering
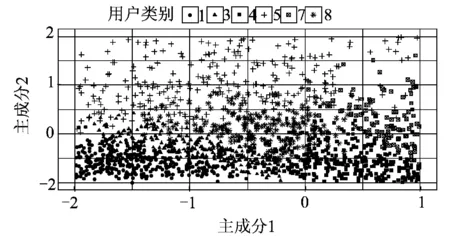
图4 SVM二次分类结果Fig.4 Second-step classification result using SVM
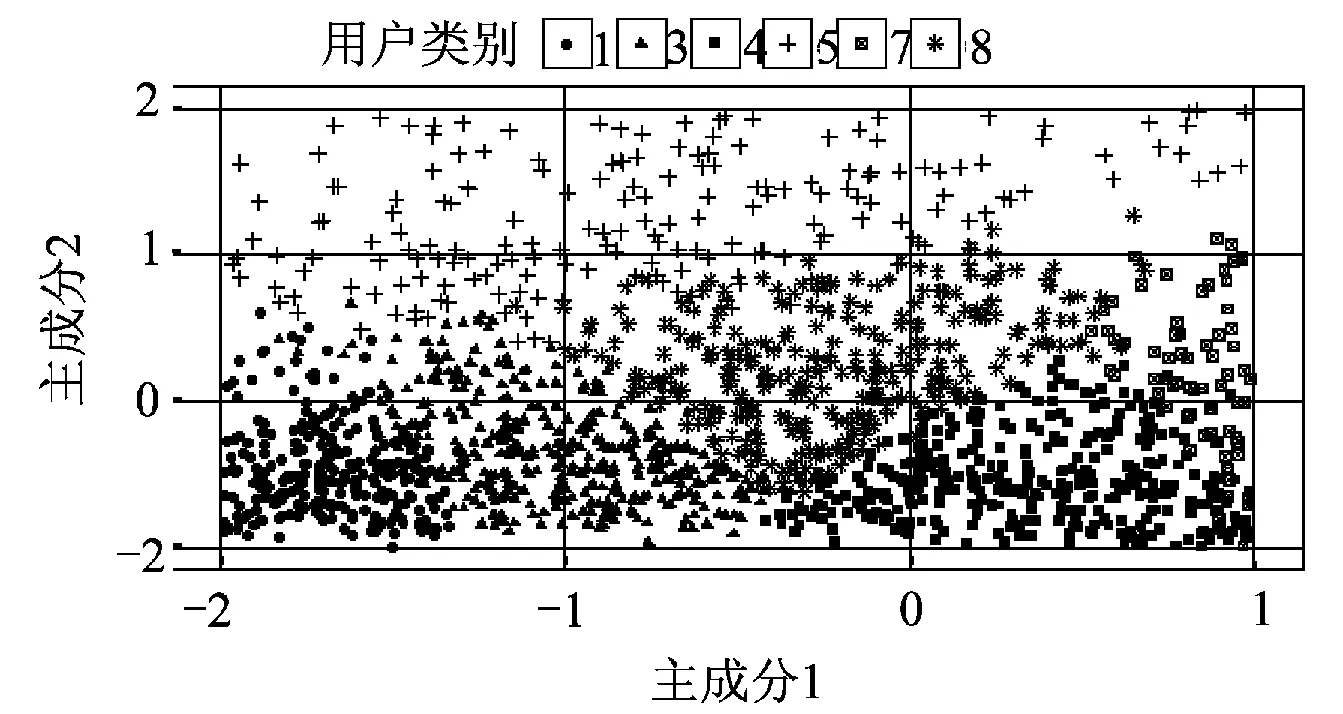
图5 基于类群特征中心的二次分类结果Fig.5 Second-step classification result based on center of cluster indexes
3.2 具体用户分析
图6为第一步聚类结果的箱型图。在二次分类中,类别5中的用户有13.6%被重新划分,比例最高,选择该类用户进行分析。图7分别是一次聚类类别5的用户被重新分类到类别1,类别2,类别3,类别7,类别8中的所有用户用电曲线,类别4和类别6与类别5的负荷特性指标差异较大,未有用户被重新划分到这两类中。图7中较多用户是波动型或者具有尖峰值的用户,基于欧式距离的全维度负荷曲线聚类难以对其正确划分。而本文的二次分类将负荷根据特征指标进行重新划分,可以考虑到负荷的形态特征,使得负荷被重新划分到具有相似形态的类群中。

图6 负荷一次聚类箱型图Fig.6 Boxplots of fist-step clustering
4 算法对比
以标准化后的负荷特性指标计算的MIA指标值记为LMIA1,负荷曲线的MIA值记为LMIA2。分别基于指标、负荷曲线的聚类以及用不同监督学习算法对负荷曲线聚类结果进行二次分类后的MIA指标值如表2所示。由表2可得,对负荷曲线聚类结果进行二次分类后负荷特征指标的聚类评价指标变好,但负荷曲线评价指标略微变差。基于指标的聚类在负荷形态指标聚类效果上表现较好,但在负荷曲线上表现较差。综合考虑负荷特征指标以及全维度负荷曲线信息,采用LMIA1*LMIA2评价聚类结果。从表2中可以看出采用SVM算法进行二次分类表现最好,其次是KNN算法和RF算法。
5 聚类结果应用建议
图8为最终得到的8类负荷的典型负荷曲线。对用户数据进行分析得到的各类别的主要用电类型分别为:(1)类别1主要为日间营业的商业用户,政府机关以及中等教育;(2)类别2为路灯等照明公共设施;(3)类别3为综合零售以及其他的商业服务;(4)类别4为综合零售,餐饮以及部分居民用户;(5)类别5为建筑安装业以及市政公共设施;(6)类别6为工业用户以及照明用电;(7)类别7为城镇居民以及餐饮用电;(8)类别8为小型工商业用电。负荷曲线聚类结果的应用主要体现在以下2个方面。
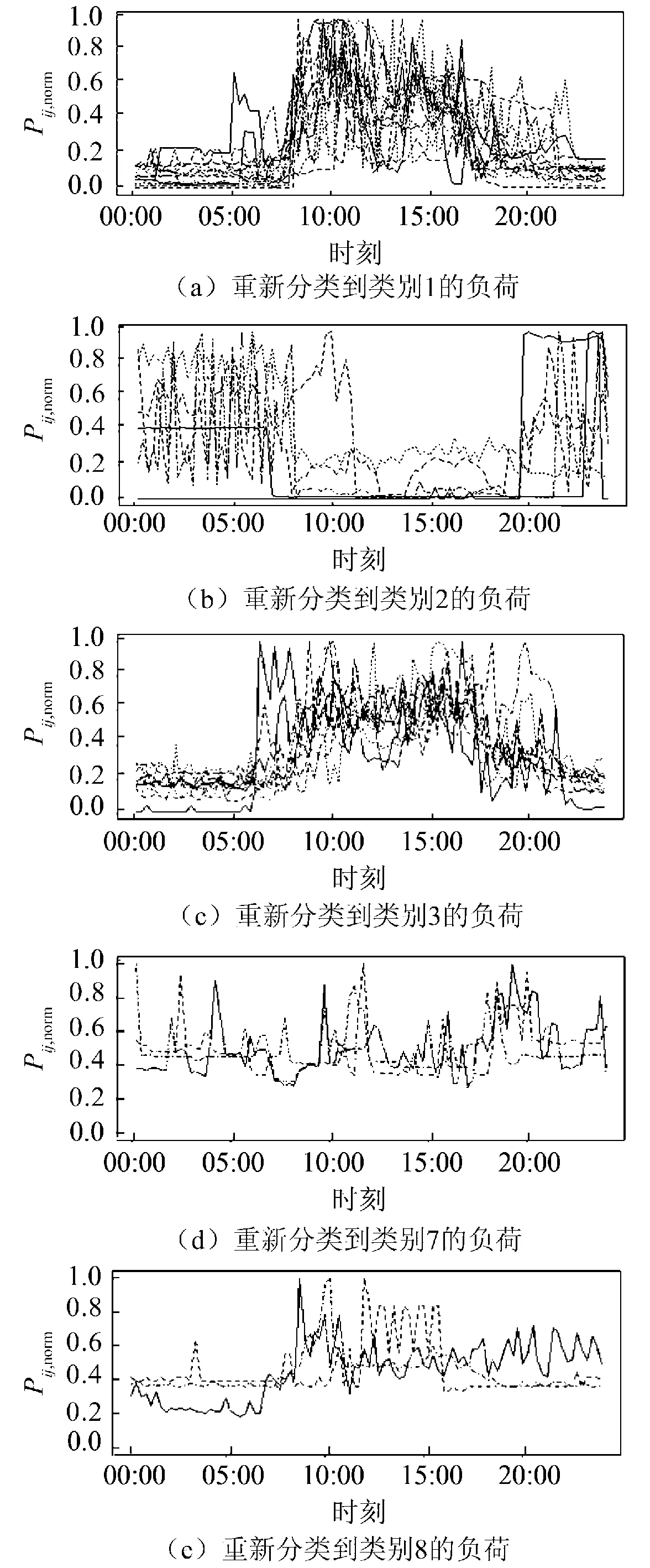
图7 类别5被重新划分的负荷Fig.7 5 types of reclassified loads表2 MIA指标对比情况Table 2 Comparison of MIA indexes
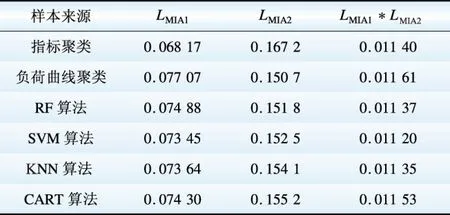
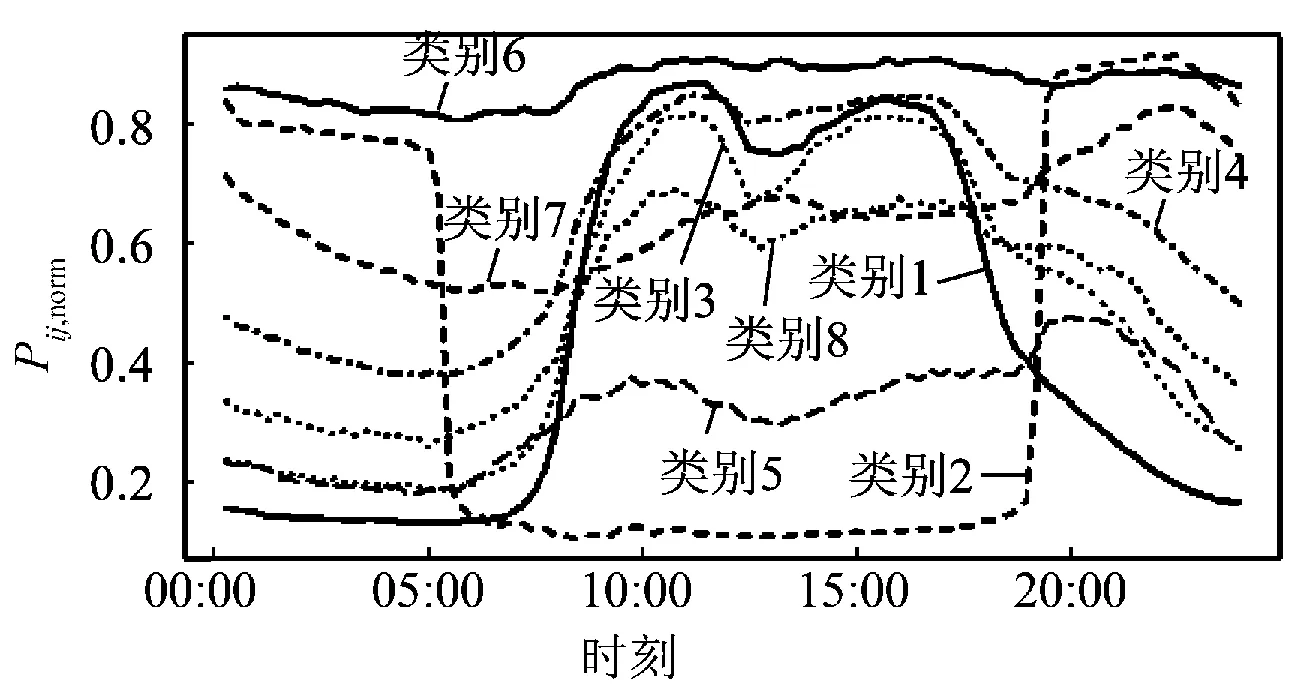
图8 8类典型负荷曲线Fig.8 8 typical load curves
5.1 分类电价的制定
电能在不同时段成本不同,售电商可以通过对不同用电模式的负荷制定分类电价,例如:类别1、类别3和类别4主要在用电高峰用电,可以制定较高的单位电价;类别2和类别7主要在用电低谷时用电,可制定较低的电价。分类电价在反应电能成本的同时也可以引导用户移峰填谷,改变其用电模式。
5.2 需求侧管理
在电力短缺时期采取的有序用电措施往往缺乏对负荷形态精细的考虑,采用粗放的轮休措施。通过对聚类后的典型负荷形态进行分析,可以帮助电力公司根据负荷形态安排合理有序的用电用户组合,优化消纳用电缺口,提高有序用电的效果。同时,通过对不同类别的用户进行错峰,提高电网的安全性和经济性。
6 结 论
本文提出了一种结合负荷形态指标的的电力系统负荷曲线两步聚类方法。算法首先采用基于欧式距离的负荷曲线聚类方法获得初步聚类结果,然后基于负荷形态特征指标采用监督学习算法对负荷进行重新分类。
算例结果表明本文的二次分类方法在保持一次聚类结果的负荷形态特征指标空间的基本分布下,可以改善全维度负荷曲线聚类在负荷形态相似性上的不足。二次分类后负荷类群内部特性指标更加紧凑,类群间负荷特性指标差异增大。不同算法的MIA指标的对比情况表明,采用SVM算法进行二次分类具有较好的效果。
通过对电力系统负荷曲线聚类可以帮助售电商进行分类电价制定,引导用户改善用电模式。此外,掌握用户的负荷形态特点可以辅助提升负荷管理的精细化程度。建立基于负荷形态的需求侧管理模型将是下一步的研究重点。
[1]郑海雁,金农,季聪,等,电力用户用电数据分析技术及典型场景应用[J].电网技术,2015,39(11):3147-3152. ZHENG Haiyan, JIN Nong,JI Cong,et al.Analysis technology and typical scenario application of electricity big data of power consumers[J].Power System Technology,2015,39(11):3147-3152.
[2]ZHONG S,TAM K S.Hierarchical classification of load profiles based on their characteristic attributes in frequency domain[J].IEEE Transactions on Power Systems,2015,30(5):2434-2441.
[3]CHICCO G,NAPOLI R,POSTOLACHE P,et al. Customer characterization options for improving the tariff offer[J].IEEE Transactions on Power Systems,2003,18 (1):381-387.
[4]CHEN C S,HWANG J C,HUANG C W.Application of load survey to proper tariff design[J].IEEE Transactions on Power Systems,1997,12(4): 1746-1751.
[5]NIZAR A H,DONG Z Y,WANG Y.Power utility nontechnical loss analysis with extreme learning machine method[J]. IEEE Transactions on Power Systems,2008,23 (3):946-955.
[6]YANG H T,CHEN S C,PENG P C. Genetic k-means-algorithm-based classification of direct load-control curves [J].IET Proceedings of Generation, Transmission and Distribution,2005,152 (4):489-495.
[7]MUTANEN A,RUSKA M,REPO S,et al.Customer classification and load profiling method for distribution systems[J].IEEE Transactions on Power Delivery,2011,26 (3): 1755-1763.
[8]宗柳,李扬,王蓓蓓.计及需求响应的多维度用电特征精细挖掘[J].电力系统自动化,2012,36(20):54-58. ZONG Liu,LI Yang,WANG Beibei.Fine-mining of multi-dimension electrical characteristics considering demand response[J].Automation of Electric Power Systems,2012,36 (20):54-58.
[9]CHICCO G,NAPOLI R,PIGLIONE F.Comparisons among clustering techniques for electricity customer classification[J].IEEE Transactions on Power Systems,2006,21 (2):933-940.
[10]徐衍会,张蓝宇,宋歌.基于核的模糊C均值逐层聚类算法在负荷分类中的应用[J].电力建设,2015,36(4):46-51. XU Yanhui, ZHANG Lanyu,SONG Ge.Application of clustering hierarchy algorithm based on kernel fuzzy C-means in power load classification [J].Electric Power Construction,2015,36(4):46-51.
[11]郭昆亚,熊雄,金鹏,等.基于模糊聚类-量子粒子群算法的用电特性识别[J].电力建设,2015,36(8):84-88. GUO Kunya, XIONG Xiong,JIN Peng,et al.Electricity characteristic recognition study based on fuzzy clustering-quantum particle swarm algorithm [J].Electric Power Construction,2015,36 (8):84-88.
[12]TSEKOURAS G J,HATZIARGYRIOU N D,DIALYNAS E N,et al.Two-stage pattern recognition of load curves for classification of electricity customers[J].IEEE Transactions on Power Systems,2007,22 (3):1120-1128.
[13]黄宇腾,侯芳,周勤,等.一种面向需求侧管理的用户负荷形态组合分析方法[J].电力系统保护与控制,2013,41(13):20-25. HUANG Yuteng,HOU Fang,ZHOU Qin,et al.A new combinational electrical load analysis method for demand side management[J].Power System Protection and Control,2013,41(13):20-25.
[14]贾慧敏,何光宇,方朝雄,等.用于负荷预测的层次聚类和双向夹逼结合的多层次聚类法[J].电网技术,2007,31(23):33-36. JIA Huimin,HE Guangyu,FANG Chaoxiong,et al.Load forecasting by multi-hierarchy clustering combining hierarchy clustering with approaching algorithm in two directions[J].Power System Technology,2007,31(23):33-36.
[15]李欣然,姜学皎,钱军,等.基于用户日负荷曲线的用电行业分类与综合方法[J].电力系统自动化,2010,34(10):56-61. LI Xinran,JIANG Xuejiao,QIAN Jun,et al.A classifying and synthesizing method of power consumer industry based on the daily load profile[J].Automation of Electric Power Systems,2010,34(10):56-61.
[16]FIGUEIREDO V,RODRIGUES F,VALE Z,et al.An electric energy consumer characterization framework based on data mining techniques[J].IEEE Transactions on Power Systems,2005,20(2):596-602.
[17]刘友波,刘俊勇,赵岩,等.基于多目标聚类的用电集群特征属性计算[J].电力系统自动化,2009,33(19):46-51. LIU Youbo,LIU Junyong,ZHAO Yan,et al.Calculation of characteristic attributes of consumer aggregations based on multi-objective clustering[J].Automation of Electric Power Sytems,2009,33(19):46-51.
[18]张斌,庄池杰,胡军,等.结合降维技术的电力负荷曲线集成聚类算法[J].中国电机工程学报,2015, 35(15):3741-3749. ZHANG Bin,ZHUANG Chijie,HU Jun,et al.Ensemble clustering algorithm combined with dimension reduction techniques for power load profiles[J].Proceedings of the CSEE,2015,35(15):3741-3749.
[19]CHICCO G,NAPOLI R,PIGLIONE F,et al.Emergent electricity customer classification[J].IEE Proceedings-Generation, Transmission and Distribution,2005,152(2):164-172.
[20]TRENDOWICZ A,JEFFERY R.Software project effort estimation [M]. Berlin, Germany: Springer International Publishing, 2014:1174-1176.
[21]BREIMAN L.Random forests[J].Machine Learning,2001,45(1):5-32.
[22]方瑞明.支持向量机理论及其应用分析[M].北京:中国电力出版社,2007:1-19.
[23]COVER T M,HART P E.Nearest neighbor pattern classification[J].IEEE Transactions on Information Theory,1967,13(1):21-27.
(编辑 景贺峰)
A Two-Step Clustering Algorithm Combined with Load Shape Index for Power Load Curve
PENG Bo1, ZHANG Yi2,XIONG Jun3,DONG Shufeng1,LI Yongjie1
(1. College of Electrical Engineering, Zhejiang University, Hangzhou 310027, China;2. Electric Power Research Institute, State Grid Fujian Electric Power Company, Fuzhou 350007, China;3.State Grid Xiamen Electric Power Supply Company,Xiamen 361000,Fujian Province, China)
To make up for the drawback that clustering method based on Euclidean Distance considering all dimensions of load curves is weak in load shape similarity, this paper proposes a two-step clustering algorithm combined with load shape characteristic index for power load curve. First, this algorithm obtains the preliminary clustering result by using clustering method based on the Euclidean Distance of load curves and selects the clustering method and number through cluster evaluation index. Second, this algorithm uses supervised learning algorithm to reclassify load based on load shape characteristic index. Then, different clustering algorithms are compared. At last, we propose the suggestions for the application of the clustering results. The example results show that the proposed two-step clustering algorithm can make up for the weakness of traditional clustering algorithm in load shape similarity. Support vector machine (SVM) algorithm has better performance in the second-step classification. The proposed algorithm has practical significance.
load clustering; data mining for power system; load shape; supervised learning algorithm
国家高技术研究发展计划项目(863计划)(2014AA051901)
TM 714
A
1000-7229(2016)06-0096-07
10.3969/j.issn.1000-7229.2016.06.014
2016-03-08
彭勃(1991),男,硕士研究生,主要研究方向为电力需求侧管理,电力系统数据挖掘以及负荷预测;
张逸(1984),男,博士,高级工程师,主要研究方向为电能质量,分布式能源以及主动配电网;
熊军(1979),男,博士,高级工程师,主要研究方向为配电自动化以及智能电网;
董树锋(1982),男,博士,副教授,主要研究方向为电力系统状态估计及优化运行;
李永杰(1989),男,博士研究生,主要研究方向为电力系统小干扰稳定分析。
Project supported by the National High Technology Research and Development of China(863 Program)(2014AA051901)
猜你喜欢
经营者(2023年10期)2023-11-02 13:24:48
中国化肥信息(2021年12期)2021-04-19 12:25:22
中学生数理化·中考版(2020年12期)2021-01-18 06:59:44
小学生必读(中年级版)(2018年10期)2019-01-04 05:11:10
电子测试(2017年15期)2017-12-18 07:19:27
新校长(2016年8期)2016-01-10 06:43:59
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
