
智能铁路大数据服务平台选型方法研究
2016-02-16 11:37:05史天运徐贵红杨连报
铁路计算机应用 2016年9期
刘 俊,史天运,李 平,徐贵红,杨连报
(1.中国铁道科学研究院 铁路大数据研究与应用创新中心,北京 100081;2.中国铁道科学研究院 电子计算技术研究所,北京 100081)
智能铁路大数据服务平台选型方法研究
刘 俊1,史天运2,李 平1,徐贵红1,杨连报1
(1.中国铁道科学研究院 铁路大数据研究与应用创新中心,北京 100081;2.中国铁道科学研究院 电子计算技术研究所,北京 100081)
本文针对困扰众多企业的大数据服务平台选型问题,对当前主流的大数据服务平台技术架构进行了分析,并结合铁路行业的特点从测试指标和测试基准两方面研究了大数据服务平台产品的选型方法,对于促进智能铁路的逐步落地及其大数据服务平台的建设实施具有一定的指导意义。
大数据;智能铁路;平台;选型;测试
智能化技术可理解为广义的信息技术,即为计算机、电子工程、软件工程和自动化这些领域所涉及的各种技术的集合。随着铁路列车运行速度、规模和环境的变化,以及人类社会生活的不断发展,信息技术在铁路行车安全、故障诊断、客户服务等诸多领域得到了越来越多的应用,同时也遇到了许多新的挑战。智能铁路应运而生。近年来,移动互联网、物联网、大数据、云计算等信息新技术的发展和应用,对人类生产方式、社会生活以及思维方法等方面带了越来越广泛而深入的影响。在“互联网+”和创新驱动等国家战略带来的新形势下,电网等传统行业对其智能化进行了新的诠释和规划,也给我国铁路智能化理念的发展提供了参考。另外,人们对便捷交通需求的日益增强和铁路运营效率瓶颈的出现也要求我国铁路以更加开放的理念融入综合交通体系,思考如何通过提高综合交通整体效率的同时取得自身效率的提升。事实上,遍布铁路建设、运营、管理中积累的大量数据中蕴含着巨大的价值,可用于提升铁路行业的智能化水平。然而,传统的数据分析技术已难以满足从这些数据中及时、准确地获取价值所提出的要求。对此,迫切需要建立大数据服务平台来实现对铁路业务数据的智能分析。
由于铁路运输组织、生产管理、经营决策之间联系紧密,需要有一个将其全都纳入的总体框架来统一分析和规划,以实现铁路整体的智能化。在如图1所示的智能铁路总体框架中。业务应用层包括7大智能应用系统,是针对运输组织、客货服务、经营管理等3个业务领域的7项核心业务应用[1]。在业务应用层和数据资源层之间的公共信息服务层包括主数据平台、信息共享平台、智能信息服务平台和大数据服务平台。其中,大数据服务平台为铁路行业各个大数据应用提供统一的数据存储、处理、分析和可视化等服务。
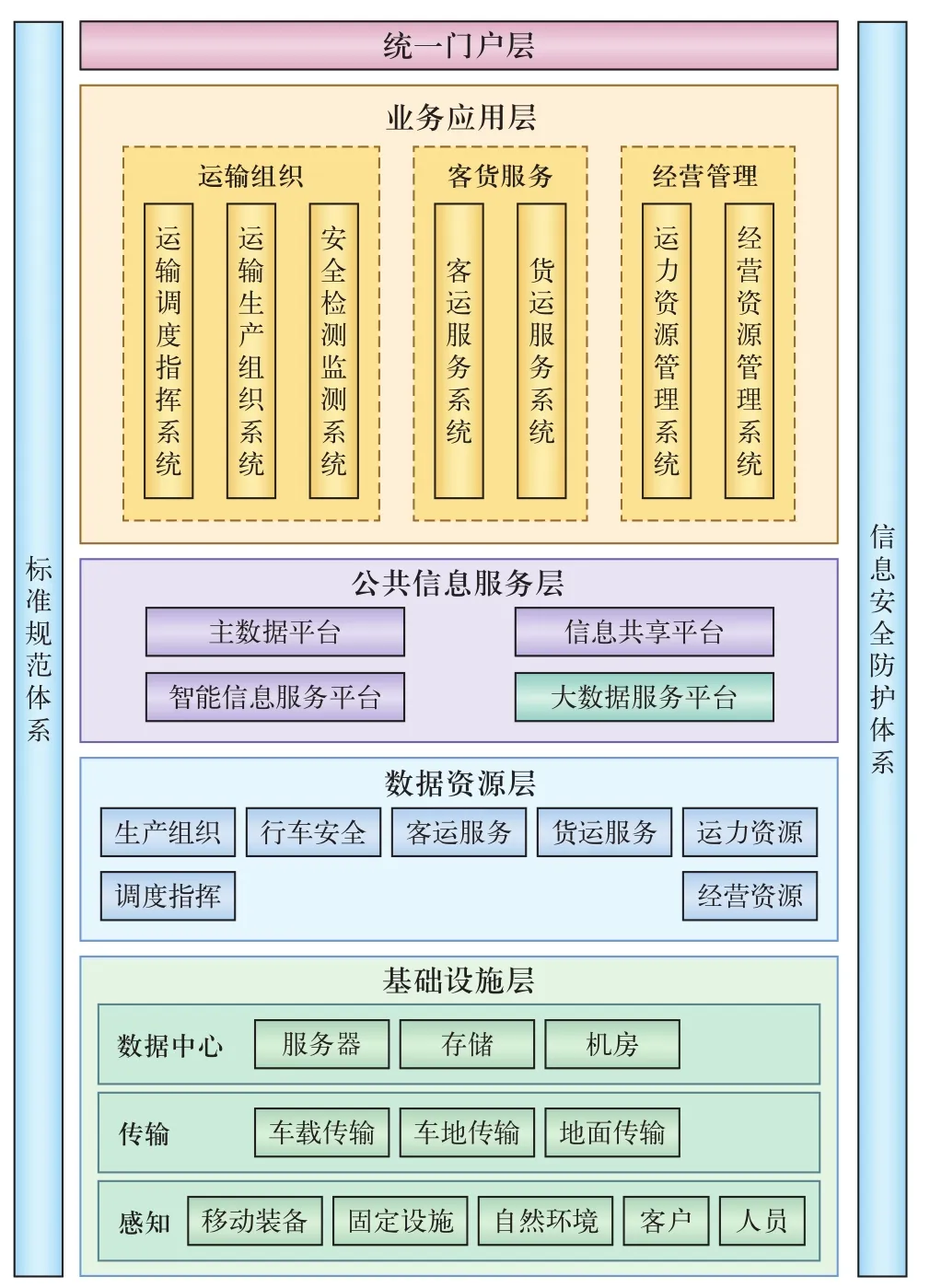
图1 智能铁路总体架构
由此可见,铁路智能化发展中所面临的挑战对大数据服务平台提出了迫切需求。并且,大数据服务平台作为智能铁路总体框架中的核心要素之一,充分利用数据资源层获取所需数据,为智能铁路的各种核心业务应用提供关键支撑。智能铁路的典型特征包括自感知、自协同、自处理、自诊断、自决策、自适应及自学习[2],而大数据服务平台则是智能铁路“自诊断、自决策、自适应、自学习”典型特征的实现基础。事实上,在大数据时代到来之前,数据分析已在铁路行业的多个领域有所应用,并发挥了重要的作用。在新时代下随着大数据相关技术及数据感知与传输技术的发展,大数据分析已替代原有的数据分析,是实现铁路智能化的核心技术之一。
不同行业对大数据应用的需求可能有所不同,其适合的大数据服务平台也有差异。如何进行大数据服务平台选型是铁路行业应用大数据的前提条件,同时也是比较棘手的一项工作。对此,本文旨在从技术角度研究智能铁路大数据服务平台的选型方法。
1 智能铁路大数据服务平台选型需求分析
铁路行业在客运服务、物流及多式联运、运输安全、基础设施和移动装备维修等多方面都有大数据分析应用的需求。对于不同的业务需求,其适配的智能铁路大数据服务平台的层次架构、技术方案以及所支持的系统功能和业务功能都可能有所不同。例如,大数据服务平台的技术方案包括技术架构和应用技术方案,其中,可采用的技术架构主要有基于Hadoop生态圈的大数据服务平台、大数据一体机、基于MPP架构的新型数据库集群及其混合架构,各有其特点和适用场景。因此,需要对各种大数据技术架构进行评估,根据业务需求来选择合适的大数据技术架构及其中的功能组件。对于同一类大数据技术架构,其实施部署中可采用的产品繁多,比如Hadoop发行版就有很多种,因此还需要确定采用哪家厂商的产品,即对大数据产品进行选型。当前,构建合适的大数据服务平台所必须的大数据技术架构和产品选型是困扰众多企业应用大数据的首要难题。对此,通常对各厂家的大数据产品进行POC测试,以判别各个大数据产品是否能支持和满足用户所要求的功能和性能。然而,由于不同行业对大数据应用的需求可能有所不同,相应的大数据平台选型方法也有所不同。对于铁路行业而言,大数据服务平台选型同样具有行业自身的特点,是一件比较棘手的工作。
下面,对现有的大数据服务平台技术架构进行分析,为铁路行业用户确定符合自身需求的大数据技术架构提供依据。从测试指标和测试基准两方面提出智能铁路大数据服务平台选型方法,为大数据产品选型提供技术上的参考。
2 大数据服务平台技术架构分析
目前,大数据服务平台技术架构可分为4种:
(1)采用MPP架构的新型数据库集群。重点面向行业大数据,通过列存储、粗粒度索引等多项大数据处理技术,再结合MPP架构高效的分布式计算模式,完成对分析类应用的支撑,运行环境多为低成本PC Server,具有高性能和高扩展性的特点。对于结构化数据分析,目前最佳选择是MPP数据库。
(2)Hadoop生态系统。围绕Hadoop衍生出相关的大数据技术。相比于采用MPP架构的新型数据库集群,Hadoop生态系统更擅长非结构、半结构化数据处理、复杂的ETL流程、复杂的数据挖掘和计算模型。这种技术架构已成为大型互联网企业的标准方案[3]需要说明的是,Hadoop生态系统包含很多组件,分别为大数据服务平台支撑不同的功能。其中,除了HDFS、MapReduce、Hbase等基本组件外,有些组件旨在支持特定的应用,如Mahout提供数据挖掘算法库及其支持架构、Flume用于海量日志收集、Sqoop主要用于传统数据库和Hadoop之前传输数据,等。因此,通常根据实际业务需求来选择Hadoop生态系统中的部分组件搭建大数据服务平台。
(3)大数据一体机。这是一种专为大数据的分析处理而设计的软、硬件结合的产品,由一组集成的服务器、存储设备、操作系统、数据库管理系统以及为数据查询、处理、分析用途而特别预先安装及优化的软件组成。高性能大数据一体机具有良好的稳定性和纵向扩展性,但其价格相对较高。
(4)是采用MPP架构的新型数据库与Hadoop生态系统相结合。相比于MPP架构,Hadoop架构更擅长非结构、半结构化数据处理。近年来,许多SQL-on-Hadoop数据库不断涌现,包括Hive、Hadapt、Citus、Impala、Stinger和Apache Drill等。总的来说,和市场上主流的MPP数据库相比,SQL-on-Hadoop在SQL性能方面还存在一定的差距。对此,一些企业采用了基于MPP架构的新型数据库与Hadoop生态系统混搭的方式,用MPP处理PB级别的、高质量的结构化数据,同时为应用提供丰富的SQL和事务支持能力;用Hadoop实现半结构化、非结构化数据处理。这样可同时满足结构化、半结构化和非结构化数据的处理需求。文献[4]针对未来电信运营商,建议大数据平台采用以Hadoop为核心的融合化技术方案。
包括传统关系型数据库、采用MPP架构的新型数据库、Hadoop生态系统等,在大数据应用中都有其擅长的领域。要在充分利用现有信息设施的基础上建设智能铁路大数据服务平台,高效支撑铁路的智能化发展,就须根据需求方面业务功能和系统功能所涉及的应用类型、数据量等因素以及平台方面涉及的性能、扩展性、价格、运维、稳定性等因素,从数据整合、存储、计算、分析等各层次对这些技术架构及其组件进行合理的评估选型。
3 智能铁路大数据服务平台选型方法
由于Hadoop平台在非结构、半结构化数据处理、复杂的ETL流程、复杂的数据挖掘和计算模型方面具有明显的优势,并随着技术的不断发展在SQL方面与MPP架构的差距正在缩小,因此本节仅针对基于Hadoop架构的大数据平台选型方法进行研究。
3.1 测试指标
通过对大数据服务平台选型方法进行广泛深入地调研分析,本文提出的铁路大数据服务平台测试指标体系如图2所示。该指标包括产品运维管理、数据接入/导出支持、数据处理、数据流程管理、多租户与权限管理等13项测试内容。铁路行业用户可根据其具体需求选择其中部分项目进行测试。
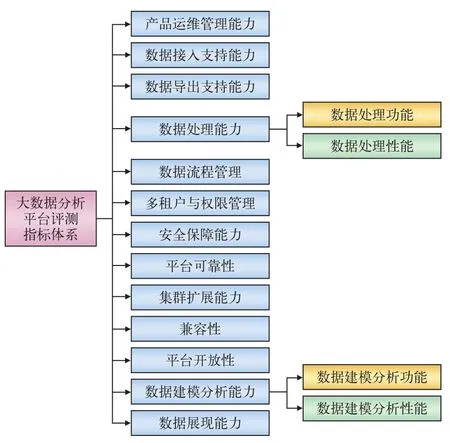
图2 智能铁路大数据测试指标体系
测试指标可分为功能和性能两方面。功能测试旨在确定某个大数据平台能够提供哪些功能,测试结果只有“是”和“否”之分;性能测试则是测试该平台在指定负载下的性能,测试结果是衡量不同性能的具体数值。图2中,除了 “数据处理性能”和“数据建模分析性能”外,所有测试项目都属于功能性测试。
3.1.1 性能测试
性能测试又可分为平台级性能测试和应用级性能测试,其中,平台级性能测试不采用企业用户的实际业务数据和负载,仅利用公开的标准大数据及其负载,相应的数据和业务模型都是公开的。应用级性能测试则需采用企业用户的实际业务数据和负载,相应的数据和业务模型有待建立,因此相对于平台级测试需要更多的测试时间。图2中的“数据处理性能”为平台级性能测试,包括SQL、NoSQL和离线分析3类智能铁路大数据应用典型负载的执行性能。而“数据建模分析性能”则为应用级性能测试,可根据铁路行业各用户的测试时间限制以及大数据厂商的意愿来确定是否进行测试。
3.1.2 功能测试
功能测试包括从运维管理、数据接入/导出/处理、数据流程管理、多租户与权限管理、安全性、可靠性、兼容性、开放性、扩展性、数据建模及展现等方面。其中,运维管理用于测试大数据服务平台在自动化部署、日志管理、配置管理、故障告警管理等方面的功能,是智能铁路大数据服务平台必须具备的基本功能;考虑到目前我国铁路行业很多单位都已建设并运转着传统数据库或FTP,所以数据接入/导出用于测试大数据服务平台与传统数据库及FTP之间的数据交互功能,以便新建的大数据服务平台与现有的数据库或FTP能够共享数据,协同工作;另外,支撑智能铁路列车安全运行的各类业务系统数据关系着旅客及工作人员人身安全甚至社会稳定,不能开放,这就要求对这些数据开展大数据分析的前提条件是保证平台的安全性,因此安全性测试也是智能铁路大数据服务平台选型中很重要一项内容。此外,智能铁路大数据服务平台的建设应循序渐进,逐步扩大应用范围,因此还需测试平台的扩展性,以便在不影响原分析任务的同时水平扩容。
在具体开展测试时,应根据自身需求对图2中各个测试项目的重要性分配权值,以使测试结果反映用户业务特点。
3.2 测试基准
一般来说,大数据应用具有明显的行业特点。由于不同行业对大数据的需求可能有所不同,有些传统行业甚至可能对大数据具有比较特殊的应用需求,因此大数据平台评测的另一核心是根据用户具体需求来确定测试基准。
由于企业常常将数据看作是比较敏感的资产,通常不愿公开,即使是公开也仅是样本数据。因此,很多企业都需面临测试数据的来源问题。对此,一种可行的办法是采用公开的大数据测试基准。目前,可用于大数据平台选型的公开基准繁多,包括TPCDS、BigBench[5]、YCSB(Yahoo! Cloud Serving Benchmark)[6]和BigDataBench[7],CALDA[8]、CloudSuite[9]等。其中,有的为传统数据管理系统测试基准,有的为针对大数据的测试基准。总的来说,现有的大多数相关基准没有完整地涵盖大数据的特性。对于我国铁路行业而言,可参考TPC-DS、YCSB和BigDataBench这3种测试基准。下面分别进行简要介绍。
3.2.1 TPC-DS
该基准是由TPC组织提出、面向决策支持应用的测试基准。TPC-DS针对SQL测试,属于关系型数据管理系统测试基准[10],其业务模型以现实中的商品零售业务为蓝本,一共包括99个测试案例。测试案例中包含各种业务模型,如分析报告性,迭代式的在线分析性,数据挖掘性等。对于各测试案例,该基准提供公开的数据集和负载。
3.2.2 YCSB
YCSB由雅虎设计,用于测试云服务系统、NoSQL及键值存储。目前YCSB自带6种负载,但用户可自定义read/update/insert/scan操作的比例,并选择操作目标记录的分布。YCSB支持Hbase、Cassandra、CouchDB、MongDB等多种NoSQL数据库,但没有提供可扩展的数据集。
3.2.3 BigDataBench
BigDataBench由中国科学院计算所牵头研制,其设计方法紧密联系工业界,完成了工业标准的大数据平台性能测试标准。BigDataBench从搜索引擎、社交网络、电子商务、多媒体、生物信息学5个典型应用场景出发,其 BigDataBench 3.1包含14个真实的数据集和33个负载,负载类型主要包括离线分析、NoSQL和交互式分析(SQL)。该基准提供公开的数据集和负载。
铁路行业用户可通过研究以上3种基准中各负载与各种铁路大数据应用之间的近似映射关系,以尽可能利用公开测试基准的负载和数据集,减少铁路业务建模和数据收集清洗的工作量。对于映射负载集中可获得部分铁路业务数据的负载,可利用大数据生成工具将这些数据生成大数据集来替代原有的公开数据集,以取得更加符合铁路数据特点的测试效果。经过多年的发展,铁路行业已积累了丰富的业务模型,其中有些甚至做了并行化处理,对此可选取部分模型加入到映射负载集合中,以构建尽可能反映铁路业务特点的大数据服务平台测试基准。
4 结束语
大数据服务平台对于当前铁路智能化发展具有非常重要的作用。本文针对大数据服务平台在铁路行业应用中面临的选型问题,通过对目前主流的大数据平台技术架构进行对比分析,为智能铁路大数据服务平台技术架构选型提供了一定的支撑;同时,结合铁路领域大数据应用的特点,提出了智能铁路大数据服务平台选型中的测试指标体系,给出测试基准的确定方法,为智能铁路大数据服务平台相关产品选型提供一定的技术参考。
[1] 马小宁.智能铁路总体框架研究[D].北京:中国铁道科学研究院,2013.
[2] 史天运,郭 歌,李 平.智能铁路总体框架的研究[C].第六届中国智能交通年会暨第七届国际节能与新能源汽车创新发展论坛优秀论文集(上册)—智能交通.2011.
[3] 于富东.大数据平台的关键技术及组网方案[J].电信科学,2015,31(7):158-163.
[4] 王 晖,唐向京.共享开放的运营商大数据平台架构研究[J].信息通信技术,2014(6):52-58.
[5] 2012 Ghazal A,Rabl T,Hu M,et al.BigBench:towards an industry standard benchmark for big data analytics[C].ACM SIGMOD International Conference on Management of Data.ACM,2013:1197-1208.
[6] Cooper B,Silberstein A,Tam E,et al. Beanchmarking cloud serving systems with YCSB[C].Proceedings of the 1st ACM Symposium on Cloud Computing.lndianapolis,Indiana,USA,2010:143-154.
[7] 詹剑锋,高婉铃,王 磊,等.BigDataBench:开源的大数据系统评测基准[J].计算机学报,2016(1):196-211.
[8] Paulson,A.Rasin,D.J.Abadi,D.J.DeWitt,S.Madden,and M.Stonebraker,A comparison of approaches to large-scale data analysis[C].SIGMOD Conference,pp.165-178,2009.
[9] Ferdman M,Adileh A,Kocberber O,et al.Clearing the clouds:a study of emerging scale-out workloads on modern hardware[J].ACM SIGPLAN Notices,2012,47(4):37-48.
[10] 金澈清,钱卫宁,周敏奇,等.数据管理系统评测基准:从传统数据库到新兴大数据[J].计算机学报,2015,38(1):18-34.
责任编辑 徐侃春
Type selection method of big data service platform for intelligent railway
LIU Jun1,SHI Tianyun2,LI Ping1,XU Guihong1,YANG Lianbao1
( 1.Research and Application Innovation Center for Big Data Technology in Railway,China Academy of Railway Sciences,Beijing 100081,China;2.Institute of Computing Technologies,China Academy of Railway Sciences,Beijing 100081,China)
Focusing on the problem of how to select the big data service platform,which was disturbing many enterprise users at present,this paper analyzed the current main technical structures of the big data service platform,and studied on the product selection method of the big data service platform from the perspectives of both testing metrics and testing benchmark according to the characteristics of railway industry.The work is expected to be instructive to the gradual advancing of intelligent railways and the construction of railway big data service platform.
big data;intelligent railway;platform;type selection;test
U29-39
A
1005-8451(2016)09-0067-05
2016-06-15
中国铁路总公司科技研究开发计划课题(2015X003-F);中国铁道科学研究院院基金重大项目(1551DZ8004)。
刘 俊,在读博士后;史天运,研究员。
猜你喜欢
信息安全与通信保密(2023年8期)2023-10-12 11:19:30
加油站服务指南(2022年6期)2022-07-28 06:07:08
一重技术(2021年5期)2022-01-18 05:41:54
建材发展导向(2021年15期)2021-11-05 08:20:40
昆钢科技(2020年4期)2020-10-23 09:32:14
湖北农机化(2020年4期)2020-07-24 09:07:38
网络安全和信息化(2020年3期)2020-04-20 11:25:46
通信电源技术(2018年3期)2018-06-26 06:33:54
公民与法治(2016年19期)2016-05-17 04:18:15
读者·校园版(2015年7期)2015-05-14 13:11:40
