
电力大数据平台建设及实时线损异常检测应用
2016-02-13 07:50杨漾张诗军陈丰李远宁张世良
现代计算机 2016年36期
杨漾,张诗军,陈丰,李远宁,张世良
(1.中国南方电网有限责任公司信息部,广州 510600;2.广东电网有限责任公司信息中心,广州 510000)
电力大数据平台建设及实时线损异常检测应用
杨漾1,2,张诗军1,陈丰1,李远宁1,张世良1
(1.中国南方电网有限责任公司信息部,广州 510600;2.广东电网有限责任公司信息中心,广州 510000)
以某区域电网公司为例,结合电网行业的数据特征以及现有的大数据技术,完成电力大数据平台的设计及建设。同时,以电力大数据平台的流数据处理架构为基础,整合计量自动化数据、GIS数据、营配数据等,开展实时线损异常检测分析场景建设,验证平台的流数据分析能力,为后续电力行业开展其他大数据应用场景的建设奠定基础。
电力大数据平台;实时线损;异常检测;神经网络;聚类
0 引言
电力大数据平台是电力行业大数据应用的基础和技术支撑,为大数据应用提供数据基础以及存储、计算、分析等能力。由于电力大数据的固有特征与其他行业大数据的特征不尽相同,当前一些较为成熟的大数据平台所采用的处理方法并不能完全适用于电力行业,因此研究与开发电力大数据平台,以此支撑电力大数据应用,显得非常必要且迫切。
欧美各国对电力大数据的应用研究开展较早,主要围绕配电、用电等领域基于智能电表用户的采集分析、配电网的管理等方面[1]。在大数据平台方面,IBM[2]、HP[3]、Oracle[4]等传统IT巨头积极开展大数据技术与平台工具的研发,开发了面向或适用于智能电网的大数据平台、模型与工具。学者Shyam R等人提出了基于Spark的智能电网大数据平台[5]。2015年2月,AutoGrid宣布与微软达成全球合作,基于AutoGrid的能源数据平台为全球公用事业公司和创新能源服务供应商提供大数据和智能电网分析解决方案[6]。
反观我国,大数据主要在互联网、金融、电信、交通等领域应用较为广泛[7-9]。随着智能电网的深入建设,电力大数据的挖掘应用要求越来越高。中国电科院朱朝阳等、华中科技大学彭小圣等也相继提出了电力大数据平台核心技术[10-11],但主要停留于理论研究阶段,目前电力大数据平台在大型电力企业的应用仍较为缺乏。
线损是电力企业在电能传输过程中发生的技术上和管理上的损耗,是电网企业经营效益的重要体现之一。及时发现线损异常,对于挽回电力企业损失,提高经营效益具有重要作用。同时,实时线损计算分析过程涉及到大量的运行监控数据流,对于平台的计算能力、扩展能力等都具有较高的要求。因此,本项目以某区域电网公司实时线损计算和异常检测为例,验证了所设计的电力大数据平台的能力,为后续电力行业大数据平台的深化应用奠定了基础。
1 电力大数据平台需求分析与设计
1.1 电力大数据平台需求分析
随着业务的高速发展和信息化的深入建设,电网数据呈现了大数据4V特性,其数据现状及平台需求特征如下:
(1)数据现状:电网数据涉及GIS数据、实时电量数据、在线监测数据、各类业务管理数据等,其数据类型多、体量大、增量快,实时性较高。但目前大部分数据流动性不足,价值转化率低,亟需建设具备处理上述类型数据的平台,实现数据资产的有效应用。
(2)需求特征:结合电网行业的数据现状,电力大数据平台除了必须提供海量结构化数据与非结构化数据的采集、存储、计算、分析与服务能力外,还必须考虑电网数据的实时性特征,形成包括流式计算、内存计算、消息存储等能力。
1.2 电力大数据平台设计
电力大数据平台架构必须包括六个模块:数据采集、数据存储、数据计算、分析组件、数据服务和平台管理。其中数据采集、存储、计算及分析是整个电力大数据平台的核心。结合电网企业的数据现状以及电力大数据平台的需求特征,考虑实时线损异常检测应用对流式数据的采集、存储、计算的需求,电力大数据平台必须具备高可用性、低延迟、水平可扩展性的特点。本文引入了前沿的大数据采集、存储、计算、分析技术等,完成了电力大数据的建设工作。其技术架构如下图所示。
在数据采集方面,本平台采用了Sqoop、Flume、Kafka进行数据采集。Sqoop用于将大规模的业务数据从传统关系型数据库转移到HDFS。Flume技术组件采集了业务系统日志文件,对业务系统发生的数据变更进行及时捕获,并以推送方式在数据中心完成同步更新。而Kafka技术实现了对海量准实时平台和流式采集获取的数据进行队列化处理,为数据仓库和数据应用的数据消费提供稳定、连续的数据输入。
数据存储包括对分布式文件、关系型数据以及内存数据存储,采用Greenplum DB、HDFS、HBASE产品以及关系型数据库Oracle,包括数据湖、数据仓库以及数据集市。数据湖仅存储最新快照数据,每个源系统对应一个分布式存储Schema。数据仓库存储区,各处理单元采用私有的CPU、内存和硬盘并通过协议通信。其数据存储是对表从物理存储上被水平分割,并分配给多台服务器(或多个实例),每台服务器可以独立工作,具备共同的Schema,只需增加服务器数就可以增加处理能力和容量,保证了可扩展能力。
数据计算包括传统的SQL计算、大规模并行计算、内存计算以及流式计算。大规模并行计算采用MPP并行计算技术,内存计算采用Spark,实现基于Redis的内存计算,流式计算采用Spark Streaming采用Spark Streaming计算技术,实现基于消息队列的数据计算。
数据分析包括多维分析引擎、数据挖掘引擎以及数据挖掘算法库,用于支持各类数据分析结果的生成,以支持多种数据分析应用类型。
2 实时线损异常检测方法研究与设计
线损的异常检测对电网合理规划、及时发现违约用电等具有重大意义,因此,本文以实时线损异常检测方法的研究与实现为例,验证电力大数据平台的能力。
实时线损的计算是以电表量测数据为基础,更新频率为15min。利用实时线损数据流实时变化情况及趋势的判断,对线损数据上的异常进行及时预警,辅助业务人员就要对此馈线作进一步检查。使企业以最快速度发现线损异常,并及时采取相应的措施。
本文根据时间序列挖掘技术,研究设计采用基于人工神经网络预测偏离度的方法[12]检测实时线损异常点,同时采用基于滑动窗口的子序列聚类方法[13-16]检测线损时间序列数据异常,从而得到更为精确的异常检测结果。
2.1 基于人工神经网络的预测偏离度的异常点检测
在固定的数据集中,识别离群点可采用多种方法,如拟合优度检验等。但对于流式数据而言,数据通常只能进行单遍处理,应用于固定数据集的分析方法必须进行适应性调整。本文所实时异常点检测的核心思想在于根据时间序列的预测模型,给出实时数据点的预测值,将真实值与其比对分析,在给定的阈值下,判断是否出现异常。
在时间序列预测模型中,BP神经网络由于其出色的自学习能力及一定的推广概括能力而被采纳使用。在这种情形下,从数学角度看,网络成为输入输出的非线性函数,假设线损的时间序列值共有n个,记该时间序列为{xi|i=1,2,…,n},以离预测时间点最近的m个观察值作为输入变量,预测第n+1个值,其预测可用下式描述:

时间序列的预测方法即是用神经网络来拟合函数f(·)并确定m,从而预测未来值。
对于线损序列数据,采用如下步骤检测异常点:
(1)采用BP神经网络拟合函数f(·),检测出相应的异常点,以神经网络拟合值作为异常点的替代值,得到修补后的新序列;
(2)重新采用BP神经网络学习,预测未来的实时线损大小xn+1;
(3)将采集到的线损真实值x'n+1与神经网络预测值进行比对,在给定的阈值α下,当时,判断为异常点,并以预测值作为新的线损大小记录在序列中;
(4)返回步骤2,不断学习更新神经网络,以提高新的数据点的预测精度。
考虑到实时线损数据在不断更新,对所有新产生的序列重新采用BP神经网络学习在技术上难以实现,因此,本研究采用增量式学习方法。其核心思想如下:对于第一个新的数据集的训练学习和原来BP神经网络学习过程一致,每次产生新的数据集后,进行检测,判断是否重新学习。如果需要,采用相同的参数构造新的BP神经网络,更新各神经元节点的权值,将更新后的BP神经网络应用到现有数据中。
由于该方法只关注单个数据点,不代表线损时间序列的过程所发生的根本变化,因此本研究在此基础上,进一步利用线损序列,检测出其中存在的异常子序列,提高线损异常检测的准确率。
2.2 基于聚类的异常子序列检测
与固定数据集不同,线损数据流的分布特征会随着时间的推移而变动。由已有的线损历史数据分析发现:单条馈线的线损数据是以天为周期的时间序列。那么在相邻的几天内同一时间段的线损数据的走势应该是相似的。

图2 单条馈线线损情况
基于上述特征,本文采用基于滑动窗口的聚类方法,对单条馈线的线损异常数据进行聚类,每次聚类只对滑动窗口对应的时间范围内的数据流进行聚类,一方面降低聚类的复杂度,另一方面反映当前数据流的分布特征。
(1)线损子序列的分割
首先确定子序列的时间段长度,然后从最新接收的数据点开始往前分割单条馈线的线损时间序列得到各个子序列。
例如:若最新接收的数据点为3号13:15分,时段长度为4小时,那么分割的每个子序列有16个数据,如表1所示:

表1 线损子序列分割示例
完成序列划分后得到足够多的子序列,但由于时段长度不同可能导致子序列的数据点个数过多,因此需要提取各子序列的特征以便节省运算量并进行更深入的分析。由于子序列可能存在高度异常、均值异常、方差异常、趋势异常,故需要提取这4个特征变量。记子序列为{xi|i=1,2,…,n}
定义1子序列高度:

式中,max(xi)是子序列的最大数据,min(xi)是子序列的最小数据。
定义2子序列均值:

定义3子序列标准差:

定义4子序列趋势

式中,μ1为子序列前半段的均值,μ2为子序列后半段的均值。
(3)子序列聚类分析
提取每个子序列四维特征之后,将子序列按这4个特征变量进行K-Means聚类,聚类数目根据学者周世兵等提出的BWP指标[17],即最小类间距离和类内距离之差与最小类间距离和类内距离之和的比值确定。最后分析聚类形成的簇,若簇内对象数目小于事先给定的阈值ε,则认为该簇为异常子序列形成的簇。
综上,使用基于人工神经网络的预测偏离度对单个数据点进行异常检测,而使用聚类分析对子序列即连续多个的数据点进行异常检测。结合两种检测手段,当检测结果为单个孤立异常点时,认为很大可能为记录错误等一些人为因素造成;当检测结果显示异常点所在子序列存在异常时,应该更深入去分析其背后的异常原因。如此可以快速准确地发现出异常,并且有针对性地分析异常原因。
3 实时线损异常检测算法在大数据平台的实现
3.1 基于人工神经网络的异常点检测在大数据平台的实现
线损异常点的检测方法具有如下特点:一方面本文提出了通过人工神经网络不断学习的方法来预测异常行为,从而检测检测出以前未被发现的异常行为;另一方面实时线损数据每15min更新一次,其频率较高,属于流式数据。数据不间断产生,新的数据可能需要重新训练模型,由于流式数据实时性的特点,难以对全量数据进行训练。
考虑到Kafaka优秀的吞吐量、可靠性和扩展性,以及Spark Streaming的灵活性,本研究采用电力大数据平台中Spark Streaming流式计算框架实现人工神经网络算法的并行化处理,利用Kafka集群将收集到的线损数据交给Spark Streaming,由人工神经网络算法对数据进行实时异常检测。
利用Spark的分布式数据架构——弹性分布式数据集(Resilient Distributed Dataset,RDD),能够将BP神经网络借助集群实现并行化,将原本在单机上执行的分类任务拆分到集群上。Spark为RDD提供了一个partitionBy函数,将原始的RDD数据分配至集群中的多个Worker节点,其步骤如下:
①启动Spark中集群管理分配工作节点,设置Executor的内存及CPU内核大小。
②将程序集分发到集群的所有工作节点。
③初始化Streaming Context,设置流式数据的处理窗口大小。
④使用参数集L,训练数据集TrainData以及测试数据集TestData对基于人工神经网络的异常检测算法进行初始化。
⑤初始化RDD graph、Sceduler、Block Tracker和Shuffle Tracker,启动并行任务。
⑥启动Kafka集群接收并将流式数据转到Spark Streaming执行并行任务。
⑦Executor执行基于人工神经网络的异常检测算法;
⑧如对BP神经网络进行重新学习,将新的神经元间的连接权值进行重新存储。
3.2 基于聚类的异常子序列检测在大数据平台的实现
基于聚类的异常子序列检测方法具有如下特点:该方法主要采用了K-Means聚类算法。K-Means算法的核心思想为通过多次计算新的聚类中心,这个过程需要对聚类中所有数据的矢量求平均值。而实时线损数据量较大,其计算量极为巨大。因此,本文拟采用并行化技术进行处理,以提高聚类的效率,同时降低算法对内存的要求。
MapReduce作为一个通用的分布式计算模型,具有可扩展能力强,效率高等特点,能够可靠地并行处理大规模数据。其特点在于能够将数据分割并分配给Map任务并行处理,不同节点处理完成后,将产生的中间结果输入到Reduce任务,得到最终结果。因此,本研究采用电力大数据平台中的MapReduce批量计算实现基于聚类的线损异常检测。其并行化策略如图3所示。
4 实时线损异常检测应用
以电力大数据平台,项目开展了实时线损应用场景设计,以实时线损曲线为基础,基于异常检测算法,实现线损的单点异常检测和序列异常检测。其异常检测的结果,将利用电力大数据平台的可视化技术,将线损在GIS平台进行可视化展示,对于检测出异常的线损进行告警提示,辅助业务人员及时发现线损异常,采取相应措施。
项目以某一地市局的10kV馈线为例,分别在Oracle平台和电力大数据平台上开展了上述应用建设。其中馈线数据量为4322条,专变数量共24584台,公变数量为24947台(单条kV馈线线损=馈线关口供入量-专变用户的用电量-台区用户的供电量)。在不考虑数据缺失、数据补抄、数据重算、转供电等情况下评估实时线损计算的过程耗时,两个平台结果如下:

图3 MapReduce并行化策略
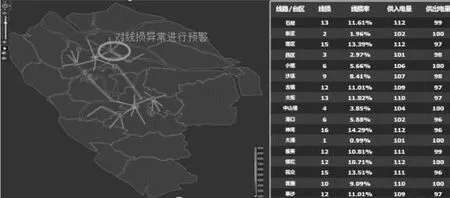
图4 线损可视化展示

表2 平台计算效率比较
综上,大数据量下采用电力大数据平台技术路线相比采用Oracle关系数据库,在同样的数据分析之所以效果下,数据计算分析性能有显著的提升。
5 结语
本文结合电力行业数据管理和应用实际需求,参照业界数据平台领先实践经验,引入前沿的大数据采集、存储、计算、分析等相关技术,设计了较为先进的电力大数据平台架构。同时,选取了涉及海量多源实时数据的线损异常检测场景,以平台的分析挖掘能力为依托,提出了实时线损异常检测算法,并设计了线损异常检测应用场景,充分验证了平台的海量实时数据处理能力。本文的研究结果为开展电力行业企业级大数据平台建设扫清了技术障碍。同时,本文的线损异常检测场景为后续电力行业各类大数据应用场景的建设提供了重要的技术参考,对支撑电网企业深度挖掘数据价值,提高企业决策的科学化,促进业务模式创新,提高企业的市场竞争力,推动创建国际先进电网企业具有十分重要的现实意义。
[1]张东霞,苗新,刘丽平.智能电网大数据技术发展研究[J].中国电机工程学报,2015,35(1):2-12.
[2]The Cornerstone of IBM's Big Data and Analytics Portfolio[EB/OL].[2015-04-20].http://www-01.ibm.com/software/data/bigdata/images/ watson-fondations-final.png.
[3]Big Data Changes Everything[EB/OL].[2015-05-05].http://www8.hp.com/us/en/business-solutions/big-data-overview.html.
[4]Thomas V R,Tanaya B.Oracle Utilities Data Model Reference[R],2013.
[5]Shyam R,Ganesh H.B.B,Kumar S.S,Poornachandran P,Soman K.Apache Spark a Big Data Analytics Platform for Smart Grid.Procedia Technology[J].January 1,2015;21(SMART GRID TECHNOLOGIES):171-178.
[6]王全强,刘敏,成立.智能电网电力大数据技术研究[J].数据库技术,2016(1):181-182.
[7]官建文,刘振兴,刘扬.国内外主要互联网公司大数据布局与应用比较研究[J].中国传媒科技,2012(17):45-49.
[8]林荣耀.大数据及在当代互联网应用中的研究[D].厦门:厦门大学,2014.
[9]郑志来.大数据背景下互联网金融对中小企业融资影响研究[J].西南金融,2014(11):63-66.
[10]朱朝阳,王继业,邓春宇.电力大数据平台研究与设计[J].电力信息与通信技术,2015,06:1-7.
[11]彭小圣,邓迪元,程时杰,文劲宇,李朝晖,牛林.面向智能电网应用的电力大数据关键技术[J].中国电机工程学报,2015,03:503-511.
[12]徐鹏飞,李炜,郑华,吴建国.神经网络在时间序列预测中的应用研究[J].电子技术研发,2010(8):5-7.
[13]张力生,杨美洁,雷大江.时间序列重要点分割的异常子序列检测[J].计算机科学,2012(5):183-186.
[14]蓝敏,李朔宇,李锡祺,曾耀英.基于聚类分群的线损特征分析方法[J].电力科学与技术学报,2013(4):54-58.
[15]Huang X,Ye Y,Xiong L,Lau R,Jiang N,Wang S.Time Series K-Means:A New K-Means Type Smooth Subspace Clustering for Time Series Data[J].Information Sciences.November 1,2016;367-368:1-13.
[16]Ferreira L,Zhao L.Time Series Clustering Via Community Detection in Networks[J].Information Sciences.January 1,2016;326:227-242.
[17]周世兵,徐振源,唐旭清.K-Means算法最佳聚类数确定方法[J].计算机应用,2010,30(8):1995-1998.
Construction of Power Big Data Platform and the Application of the Outlier Detection of Real Time Line Loss
YANG Yang1,2,ZHANG Shi-jun1,CHEN Feng1,LI Yuan-ning1,ZHANG Shi-liang1
(1.China Southern Power Grid,Guangzhou 510600;2.Guangdong Power Grid Information Center,Guangzhou 510000)
Takes a regional power grid corp as an example,combines with the data characteristics of power grid industry and the existing big data technology,completes the design and construction of big data platform.At the same time,based on the big data platform’s streaming data processing architecture,it integrates measurement automation data,GIS data and business data,etc.,to carry out the construction of the outlier detection and analysis of real time line loss,which proves the streaming data analytics capacity of the platform.Lays the foundation for the subsequent power industry to carry out the construction of other big data application scenarios.Lays the foundation to carry out the construction of other big data application in the future.
Power Big Data Platform;Real Time Line Loss;Outlier Detection;Neural Network;Cluster
1007-1423(2016)36-0008-07
10.3969/j.issn.1007-1423.2016.36.002
杨漾(1984-),女,湖南宁乡人,工程师,工学博士,研究方向为计算机系统结构
张诗军(1973-),男,安徽六安人,高级工程师,研究方向为计算机应用技术
陈丰(1973-),男,福建莆田人,工程师,本科,研究方向为计算机应用技术
李远宁(1981-),男,广东梅州人,高级工程师,研究方向为计算机应用技术
张世良(1985-),男,广东梅州人,工程师,硕士研究生,研究方向为计算机系统结构
2016-12-10
2016-12-20
广东省科技厅重大专项(No.20148010117007)
猜你喜欢
数学大王·趣味逻辑(2021年11期)2021-12-03
电子制作(2019年19期)2019-11-23
铁道通信信号(2019年6期)2019-10-08
电子制作(2019年24期)2019-02-23
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
重型机械(2016年1期)2016-03-01
中国工程咨询(2016年3期)2016-02-13
智能系统学报(2015年4期)2015-12-27
海军航空大学学报(2015年4期)2015-02-27
