
分布式数据流决策树VFDT分类算法研究
2016-02-13 07:50刘寿强祁明
现代计算机 2016年36期
刘寿强,祁明
(1.华南师范大学物理与电信工程学院,广州 510006;2.华南理工大学经济与贸易学院,广州 510006)
分布式数据流决策树VFDT分类算法研究
刘寿强1,2,祁明2
(1.华南师范大学物理与电信工程学院,广州 510006;2.华南理工大学经济与贸易学院,广州 510006)
随着大数据时代的到来,网络上充斥着大量高速变化的数据流,然而传统数据挖掘技术不能很好地直接应用到数据流上。研究基于决策树的数据流分类挖掘算法,其研究思路是首先描述一般决策树;然后重点阐述数据流决策树VFDT的算法的实现,采用Twitter Storm分布式流式计算框架的并行计算和Yahoo SAMOA机器学习平台,对VFDT算法进行并行化设计;最后通过实验验证并行化的VHT决策树算法具有良好的运行效率与性能。
数据流;数据挖掘;决策树;Storm;SAMOA
1 数据流及其典型处理平台概述
随着互联网应用的发展,产生大量的流数据(下文采用通用的说法“数据流”),与传统的静止数据不同。数据流是海量的、高速的、实时的。其蕴涵着大量信息,可以用来作为智能决策的依据。预测和分类是基本数据分析两种形式[1],可以用于提取描述重要数据类的模型或预测未来的趋势。目前大部分算法是内存驻留算法,通常假定数据量很小,无法有效地应用于数据量潜在无限的数据流。传统的数据挖掘方式并不能很好地适用于数据流挖掘,数据流分类对传统的分类技术提出了许多新的挑战。由于分类理论和方法在不同领域有着相当广泛的应用,在对大量数据流进行数据挖掘处理时,如何利用有限的计算资源对实时的数据流信息进行快速的处理是一个很大的挑战和难点,因此,研究快速的、精确的、稳定的数据流分类系统具有极高的理论价值和应用价值。
目前数据流的研究与应用在国内刚刚起步,主要是一些大的互联网公司如腾讯、百度、阿里巴巴用于内部的数据与业务处理,国外则主要是TwitterStorm实时平台和Yahoo的SAMO数据挖掘平台[2]。这两个平台是开源的,本文所做的实验基于这两个平台。
2 数据流快速决策树算法(Very Fast Decision Tree,VFDT)
VFDF算法是一种基于Hoeffding树的对数据流模型进行分类的决策树方法[3-4]。Hoeffding树在最坏情况下能在恒定时间内对一个实例进行学习,而且所构建的决策树的准确率不差于其他算法。VFDT系统则是在Hoeffding树的基础上发展而来的,它对每一个实例只扫描一次,不会对它们保存,所以适合大量数据流的挖掘,VFDT最主要的贡献在于用Hoeffding不等式来估算样本的数量。设HT是当前Hoeffding树,E为训练实例,G为不纯度函数,VFDT的算法的主要步骤如下:
(1)训练集经HT逐层分类后,到达叶子,每个叶子都积累若干实例;
(2)对于同一类别实例较多的属性,记录在候选分裂集;
(3)对每个候选分裂集用G函数表示,记Xa是不纯度最小的的属性,Xb是不纯度次小的的属性,根据Hoeffding边界计算出ε;
3 分布式数据流决策树VFDT算法
3.1 垂直Hoeffding树(VHT)算法
该算法是基于VFDT的,在它基础上添加分布式和并行性(注:PI内数字表示并行度)。
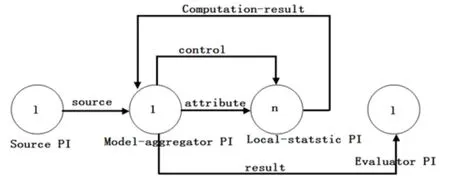
图1 垂直Hoefffding树
由图1可得,Model-aggregator PI包含整个决策树模型,它通过属性流和控制流连接局部统计PI:根据垂直并行模型,Model-aggregator PI根据属性分割instances,instances经由属性流传递信息;控制流通知local-statstic PI运算,且每个local-statsitc PI都会对相应的instances进行局部统计计算。局部统计结果会通过computation-result反馈给Model-aggregator。Modelaggregator PI将分类器结果经由结果流发送给Evalutor PI分类。Evaluator PI评估算法的正确率。
当需要更新决策树时,Model-aggregator PI经由控制流(control stream)发送compute content event到Local-statistic PI。一旦Local-statistic PI接收到compute content event,就开始计算给它分配的属性值的选出最优以及次优属性。此时,Model-aggregator PI有可能会继续处理incoming testing instance或等到接收完Local-statistic PI处理结果后才开始接收数据。
无论何时,算法接收到local-result content event,它都会从splitting leaves检索出正确的叶子l,然后更新当前最优(Xa)以及次优(Xb)属性。当所有的局部结果都反馈给Model-aggregator PI后,决策树归纳算法计算hoeffding界和决定是否分裂出叶子l。仅当满足条件才分裂,否则不分裂。Model-aggregator PI具有超时机制,一旦超时,就直接采用当前的Xa和Xb计算Hoeffding界和做分裂决策。在测试阶段,Model-aggregator PI预测incoming instances的类值。Model aggregatro PI使用决策树模型将新的incoming instances分类到正确的叶子,并且使用叶子预测类。然后,将类的预测值发送到result stream。
3.2 Storm集成到SAMOA
通过SPE-adapterLayer将storm集成到SAMOA,需要建立storm classes与SAMOA组件之间的联系,如图2所示。
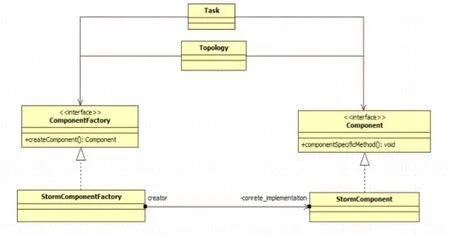
图2 storm-samoa简化设计图
将Storm集成到SAMO称为storm-samoa。stormsamoa由StormEntranceProcessingItem和StormProcessingItem组成,它们继承自Storm-TopologyNode。由StormTopology承担创建StormStream和创建唯一标识的任务。Storm-EntranceProcessingItem包含storm的spout组件,而StromProcessingItem包含storm的bolt组件。利用spout和bolt组件,就可以组成storm的Topology,并且在storm集群上运行。
抽象类StormStream继承自stream。抽象方法put用于发送content event到目标PI,使用抽象类Storm-Stream好处是避免spout和bolt发送tuple方式的差异性。StormSpoutStream继承StormStream,StormEntranceProcessingItem使用stormSpoutStream发送contentevent。StormSpoutStream的put方法puts content event到StormEntranceSpout的队列中,Storm利用pull模式,清空队列并发送content event。另外,StormProcessingItem之间使用StromBoltStream发送content event,它里边调用的就是boltoutputCollector方法实现该功能。
4 系统部署与实验
4.1 系统部署
在本地搭建Storm环境以便开发测试,同时需要配置文件storm.yaml,修改storm的配置文件(storm. yaml),添加Nimbus的主机地址,将修改后的配置文件添加到目录(~/.storm/)中。将Nimbus、Supervisor、Storm UI设置在同一台PC上。在开发过程中,只需将Topology提交到本地Storm环境中,即可模拟集群环境使项目运行,方便调试与测试。选用3台物理服务器来搭建实时数据分析处理系统所需的Storm集群,其中一台只运行Nimbus守护进程,其余2台只运行Supervisor,为每台Surpervisor节点配置4个可使用的端口。
4.2 分布式决策树实验结果与分析
本实验主要对比基于VFDT的并行化算法VHT与VFDT算法在多组数组下的运行情况,并从分类结果、分类时间和Kappa一致性检验进行分析。实验数据采用SAMOA集成的随机决策生成器生成随机数据。该生成器生成的属性均为离散值,不考虑连续属性的情况。VFDT算法数据是使用MOA数据流挖掘软件获得。实验样本个数为107个,10次实验取平均值,并从三个方面进行分析:运行时间,用于分析分类效率;分类精度,用于评价分类的精度;Kappa Statstic,用于检测模型的一致性。
(1)运行时间比较
运行时间用来比较算法的执行快慢,由于节点都是本地虚拟化的,这里忽略Storm节点通信耗时,忽略不同节点执行重复数据的事件。实验中Storm平台节点数设置为3,一台Nimbus,两台Supervisor。
实验参数:VFDT算法的其它参数与VHT参数一致,VFDT与VHT树的深度都为10,标称属性为10,类个数为2。此时VHT的并行度为4。
实验结果(表1)表明,VFDT和VHT算法的运行时间都是随着数据量的增大而增大,VFDT处理相同数据量的时间约为VHT的4倍,而由于VHT算法是基于VFDT算法的,也就是说,并行化使执行时间缩短。
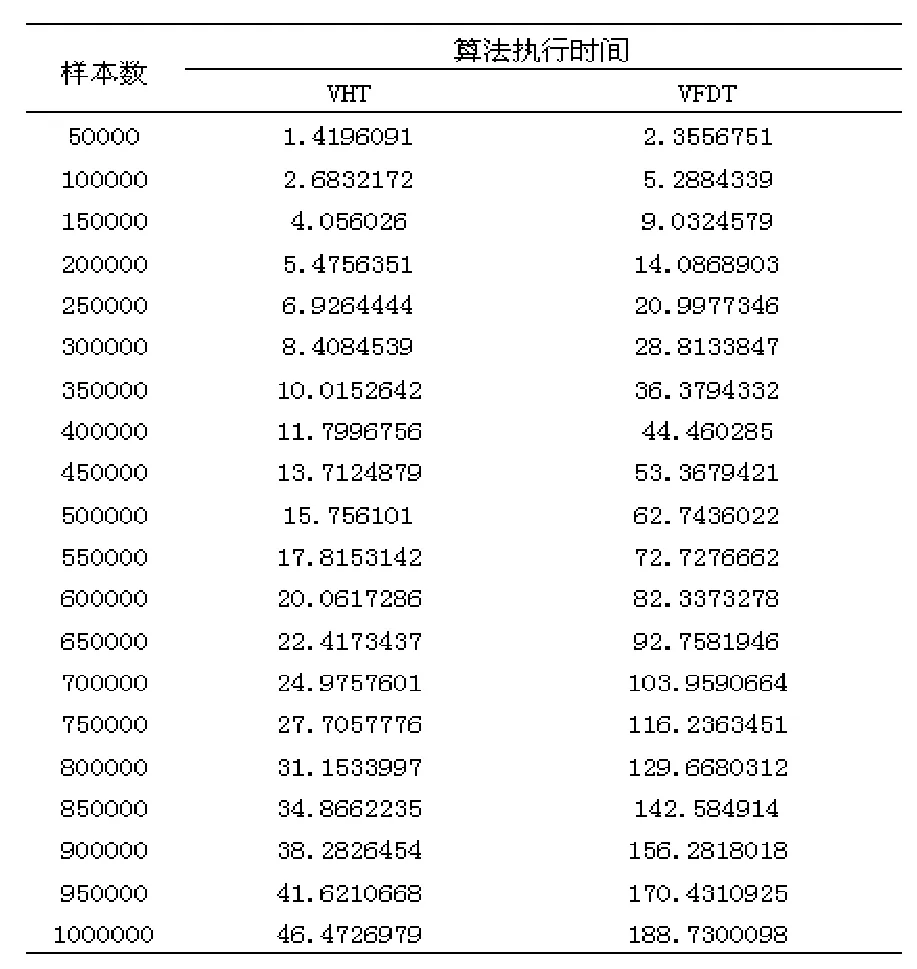
表1 VHT与VFDT算法执行时间比较
(2)分类精度比较
该分析指标表明的是分类的精度。数值越大,分类的精准度越高。该实验将从两个方面验证VHT的分类精度:第一,验证并行度对VHT的分类精度的影响;第二,验证标称属性个数对VHT的分类精度的影响。
第一部分验证实验:设VHT算法实验参数为树深度10,标称属性个数10,类个数2;并行度分别为1、4、10。
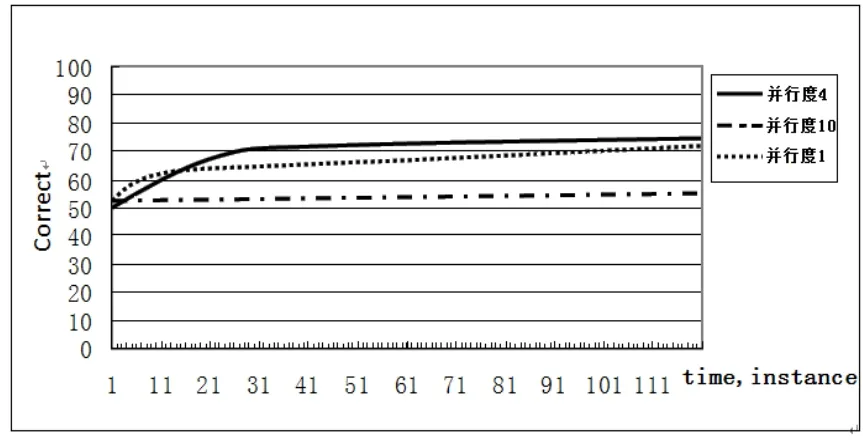
图3 VHT在不同并行度下分类精度对比图
图3给出了在相同模拟数据下不同并行度下VHT算法的分类精度对比:第一,可以得出并行度4时,分类精度最高,并行度1的分类精度相对较好,而并行度10的分类精度最差。也就是说,并行度对整体的分类精度有影响,但在实验中不是积极影响,并非并行度越高VHT算法的精度越好。这是因为Local-statstic-Pi在分裂属性并没有选取准确,导致决策树模式出现问题;第二,无论并行度如何,分类精度曲线基本上会随着样本数的增加呈现平滑上升状态,分类精度提高。
第二部分验证实验:设VHT算法实验参数为并行度4,树深度10,类个数2,标称属性个数5,10,20。
图4给出了在同样模拟数据下不同标称属性个数下VHT算法的分类精度对比:从大的方向,可以看出属性个数越小,分类精度越高。实验中,属性个数为5的分类精度最好,属性个数为10的次之,属性个数20的最少。不过从图4中可以看出分类的精度也可以达到70%;从图4中还可以读出,随着样本个数增大,分类精度越来越好。对于海量的数据流的,即使属性个数较多,但该精度值还是在可接受的范围之内。
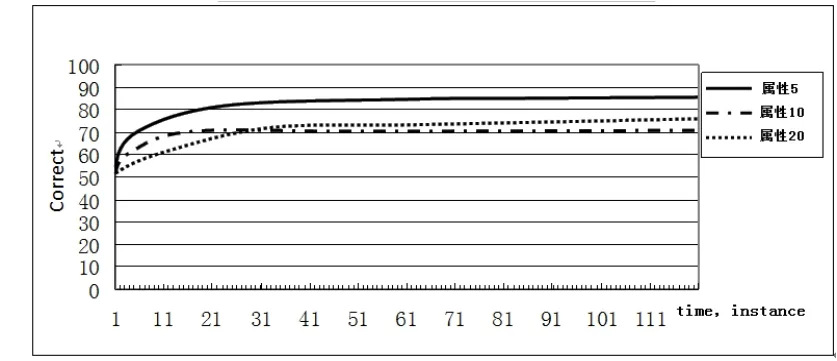
图4 VHT不同属性个数下分类准确率对比图
(3)VHT的Kappa统计(Kappa Statstic)
该实验验证随机决策树与VHT算法的一致性,也可以说是评价VHT决策树模型的优劣性。该实验的数据流生成器产生的是离散属性,Kappa统计是检验分类变量资料一致性以及重现性的指标。该指标正适用于离散属性,(0~0.4]重现性(或一致性)差,(0.4~0.75]重现性(或一致性)好,(0.75~1]重现性(或一致性)极好。
该评价值仍分为两个实验验证:第一部分为不同并行度下VHT的Kappa Statstic值的影响;第二部分为不同标称属性个数对VHT的Kappa Statstic的影响。第一部分实验:参数设置,VHT树的深度为10,标称属性个数为10,类个数为2,并行度分别是1,4,10。
从图5可以看出并行度为10时,Kappa Statstic为负数,接近0,并行度为1时Kappa Statstic曲线虽然呈上升状态,但是最大值只是刚好达到40%;而并行度为4时Kappa Statstic曲线呈上升状态,最大值达48%以上,也就是说并行度有个最好值,实验中为4,随意增加或者减少就会对Kappa Statstic造成不良影响。结合图5,解释并行度10分类精度<并行度1分类精度<并行度4分类精度的问题,这是因为VHT决策树模型与随机决策树最一致就是并行度为4时,此时分类模型最佳;而并行度1、10一致性差,模型较差。
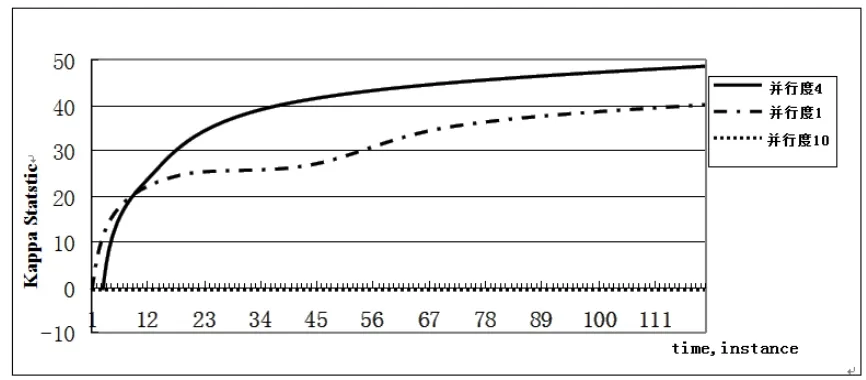
图5 VHT不同并行度下Kappa Statstic对比图
第二部分验证实验:设VHT算法实验参数为并行度4,树深度10,类个数2,标称属性个数5,10,20。从图6可以看出,属性个数对Kappa Stastic的影响:属性个数为5时,Kappa Statstic最优;属性个数为10时,Kappa Statstic次之;属性个数为20时Kappa Stastic最差。也就是说,属性个数越多,Kappa Statstic越差,说明VHT算法并不适合用于多属性的数据流分类中。用该参数就可以解释图6的现象,属性个数为5时,该算法模型与随机决策树模型最佳,因此分类精度最好。换句话说,当VHT算法模型与随机决策树模型一致性较好时,分类的精度越好。
以上决策树生成器生成人工数据对VHT分类器的性能进行一系列的验证,主要从三个角度去分析VHT算法的性能:第一,运行效率;第二,分类精度;第三,一致性检验。从上述实验结果可得,当数据量越来越大,VFDT执行时间比VHT的执行时间长得多,运行效率慢。也就是说,VHT算法对于大数据量时有较好的运行效率。但是对于改变VHT算法的并行度并不一定能够提高性能,有可能造成性能降低。而且属性个数较多时,VHT算法分类结果也不太理想。从Kappa Statstic分析可知,改变并行度以及属性个数会导致VHT算法模型与随机决策树模型一致性变化,当一致性较差时,分类精度就不理想。从理论上讲,就是VHT算法选择分裂属性不太精准,或者进行树剪枝时,选择的分枝不合适。
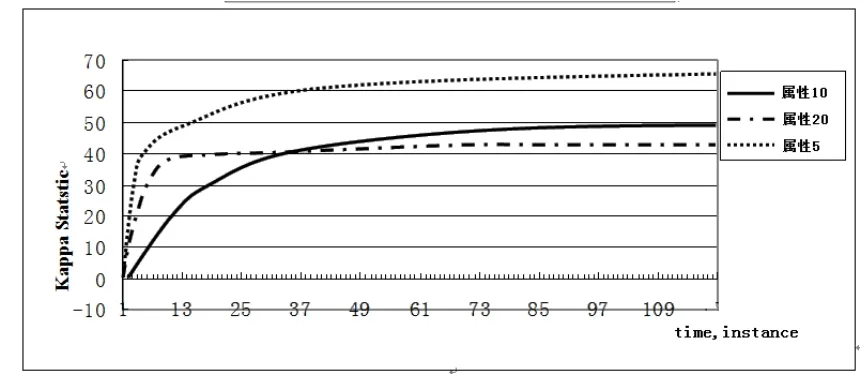
图6 VHT不同属性个数下Kappa Statstic对比图
5 结语
本文结合当前开源的数据流计算框架对数据流挖掘算法进行探索。对于海量的数据,目前最好的做法是并行化处理,它能够有效地提高运行效率。实验证明VFDT分类是有效的:随着样本数目的增加,在分类精度上有了明显的提升,虽然对比原VFDT算法有所减低,但是在并行度适中时,很大程度上提高了分类效率,这个效率在实验测试中约为4倍左右,但是改变并行度并不利于分类精度的提升,而且VHT算法在属性值较多时的分类精度不理想,该算法比VFDT算法更适于挖掘大型散属性数据流[5]。
本文主要的工作是对数据流决策树算法VFDT的并行化改进,但对原有算法缺陷的改进是有限的。VFDT算法主要是针对离散属性的数据流的,对连续属性的数据流缺乏处理能力,同时,对数据流概念漂移问题[6-7]并没有考虑进算法设计当中。本文的设计只适用于数值类型,然而在实际应用中,数据流常常包含多种类型的数据,需要进一步研究如何对实时混合的数据分类。由于一类分类算法一般只解决一类问题,不同的数据流可能会使用到不同的分类方法,为了满足大数据时代对海量数据的要求,需要设计多种并行分类方法,以便提高分类精度与效率。为解决海量数据流挖掘的高效计算问题,最有效途径是采用云计算并行化改造[8],并利用Storm或Spark等实时流计算框架,使海量数据流挖掘算法的性能与效率有着数量级别的提升[9]。
[1]姚远.海量动态数据流分类方法研究[D].大连:大连理工大学,2013.
[2]Arinto Murdopo,Antonio Severien,Gianmarco De Francisci Morales,and Albert Bifet.Samoa-Developers-Guide-0-0-1.http://yahoo. github.io/samoa/,2013.
[3]王涛,李舟军,胡小华,等.一种高效的数据流挖掘增量模糊决策树分类算法[J].计算机学报,2007.
[4]Albert Bifet,Geoff Holmes,Richard Kirkby,Bernhard Pfahringer.Data Stream Mining[M].WAIKATO,2011.
[5]Albert Bifet,Jesse Read,Bernhard Pfahringer,Geoff Holmes.Pitfalls in Benchmarking Data Stream Classification and How to Avoid Them[J].Machine Learning and Knowledge Discovery in Databases Lecture Notes in Computer Science Volume 8188,2013,465-479.
[6]叶爱玲.基于多重选择机制的概念漂移数据流挖掘算法研究[D].合肥:安徽大学.2010.
[7]李培培.数据流中概念漂移检测与分类算法研究[D].合肥:合肥工业大学,2012.
[8]颜巍.基于云平台的数据挖掘算法的研究与实现[D].成都:电子科技大学,2013.
[9]程学旗,靳小龙,王元卓,等.大数据系统和分析技术综述[J].软件学报,2014,25(9):1889-1908.
Research on Decision Tree Classification Algorithm of Distributed Data Stream
LIU Shou-qiang1,2,QI Min1
(1.School of Physics and Telecommunication Engineering,South China Normal University,Guangzhou 510006;2.School of Economics and Commerce,South China University of Technology,Guangzhou 510006)
Since the arrival of the era of big data,data state has been changed,which is not only static but also dynamic streaming,the new type of data is called data stream owned the characteristics such as continuous,high-speed,dynamic and infinities etc.Thus traditional data mining techniques cannot be directly used for data stream mining,stream data mining technology is one of the new research directions in the field of data mining.Focuses on the data stream mining classification algorithm which is based on the decision tree algorithm, describes the general decision tree,after understanding the implementation of VFDT,one data stream decision tree algorithm,uses Twitter Storm distributed stream computing framework of parallel computing ability and machine learning platform framework of Yahoo SAMOA, proposes concurrent parallel design based on the arithmetic of VFDT algorithm,and finally the experiment demonstrates the excellent operating efficiency and performance of parallelized VHT decision tree algorithm.
Data Streams;Decision Treeclasscation Algorithm;Storm;SAMOA
1007-1423(2016)36-0003-06
10.3969/j.issn.1007-1423.2016.36.001
4-),男,湖北人,讲师,博士,研方向为云计算、大数据、电子商务、机器学习
2016-11-18
2016-12-10
广东省公益研究与能力建设专项资金项目(No.2016A020223012、No.2015A020217011)、广东省交通科技计划项目(No.2015-02-064)、广东外语外贸大学南国商学院2016年教改重大项目、广州大学华软软件学院重大科研培育项目(20000104与教研项目KY201412)
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
成都信息工程大学学报(2019年3期)2019-09-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
西北工业大学学报(2015年3期)2015-12-14
