
基于支持向量机的超超临界锅炉受热面污染监测模型研究
2016-02-05 08:17周保中
发电技术 2016年6期
周保中
(华电电力科学研究院,浙江杭州310030)
基于支持向量机的超超临界锅炉受热面污染监测模型研究
周保中
(华电电力科学研究院,浙江杭州310030)
通过某发电集团科技(创新基金)项目“超超临界锅炉吹灰优化试验研究”,利用电厂已有的DCS采集系统,得到实时数据样本,采用ε-支持向量机回归机(ε-SVR)来进行模型学习预测,结果表明基于支持向量机的预测模型的均方误差很小,能够准确快速得跟踪实际过程,取得了很好的预测效果。
支持向量机;锅炉;污染监测
0 引言
近年来,国内外研究者对大型燃煤锅炉受热面灰污在线监测和吹灰优化开展了深入地研究,并作为节能与安全运行的重要措施得到了广泛的应用和推广。目前,基于热平衡与传热计算原理开发的在线监测系统,已经在很多亚临界和超临界锅炉中得到运用。
但锅炉是一个非常复杂的动态系统,影响锅炉受热面积灰的因素很多,如受热面布置、烟气流速、负荷波动、煤质、有无吹灰等,这就使传统的基于热平衡和传热原理计算的结果与实际工况常有较大的出入。针对这些问题,国内外研究者开展了基于人工神经网络、模糊系统、专家系统等智能技术的污染监测和智能吹灰研究,对优化锅炉吹灰方案提供了有益的帮助[1-5]。但由于人工神经网络这些非线性方法缺乏统一的数学理论基础,特别是其中的结构选择和权重初值设定均需依赖经验,得到的模型通常并非全局最优,而是局部最优解,并且容易出现“过学习”的现象。本文采用在统计学习理论基础之上发展起来的支持向量机(SVM)算法,对锅炉受热面污染监测模型做回归预测,SVM可以很好得解决神经网络“过学习”、网络模型结构难以确定以及局部最小点等问题。
1 支持向量机回归原理[6]
1.1支持向量机
1995年,Vapnik等人根据统计学习理论中结构风险最小化原则提出了支持向量机(SVM),其通过非线性变换(核函数)将输入空间变换到高维空间,并在这个高维空间中求广义的最优分类面。基于VC维和结构风险最小化原则的SVM根据有限的样本信息在模型的复杂性和学习能力之间寻求最佳折中,能够尽量提高学习机的推广能力并同时有效避免“过学习”现象,并保证找到的极值解就是最优解。SVM在形式上如同神经网络,输出s个中间节点的线性组合,其每个中间节点对应一个支持向量。
1.2 ε-支持向量机回归机(ε-SVR)
支持向量的方法应用到回归预测问题中,就是要最小化一个凸函数,并且要求它的解是稀疏的。回归算法就是要定义一个可以忽略真实值一定范围内误差的损失函数,即ε不敏感损失函数。ε-支持向量机回归机就是建立在使用ε不敏感损失函数上的,而在ε-支持向量机回归机的基础上又发展出了ν-支持向量回归机。下面主要介绍ε-SVR的算法。
设已知训练集T={(x1,y1),…,(xl,yl)}∈(X×Y)l,其中xi∈X=Rn,yi∈Y=R,i=1,…l;
选择适当的正数ε和C;选择适当的核K=(x,x′);
构造并求解最优化问题:


构造决策函数:



2 基于SVM的灰污监测模型
2.1研究对象的介绍
某发电厂超超临界锅炉是本生直流锅炉。根据锅炉各级受热面清洁需求,共安装有82支炉膛吹灰器、40支长伸缩式吹灰器以及12支半伸缩式吹灰器。炉内主要受热面包括:炉膛、屏式过热器、高温过热器、高温再热器、低温过热器、低温再热器、省煤器和空气预热器,各受热面在炉内的布置如图1所示。
2.2 样本的选取
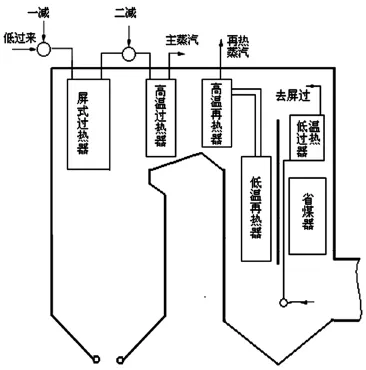
图1 某发电厂超超临界锅炉受热面布置示意图
在基于热平衡及传热原理计算的受热面污染监测模型中,定义受热面的污染因子CF(Cleanliness Factor)为受热面实际传热系数Ksj与理想状态传热系数Klx的比值,直接反映受热面的污染程度。当受热面清洁时,CF=0;CF越大则表明受热面积灰结渣污染越严重。

作为输出样本点的灰污系数是综合反应受热面污染状态的参数,通过试验进行长时间积灰使受热面积灰达到动态平衡,作为灰污系数的上限,假定为0.9;吹灰器动作后,灰污系数将快速下降,以吹灰器吹扫完毕时刻的灰污系数为下限,由于吹灰存在死角,没有完全清洁的状态,可以假定下限为0.2;根据积灰的规律,用多项式拟合积灰和吹灰过程中的灰污系数得到输出样本点。本文选取高再积灰试验的数据作为总样本,选取总样本的一半样本点作为学习样本,另一半作为检验预测样本,并在使用前先进行归一化处理。
2.3 参数和核函数的选取
采用ε-支持向量机回归机(ε-SVR)来进行模型学习预测。首先核函数选取径向基函数:
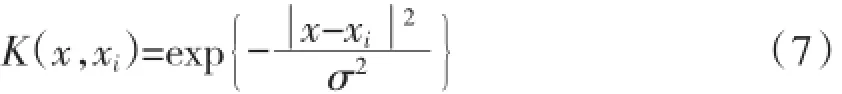
为了获得最佳的参数C和σ,并训练得到最优支持向量回归机,本文采用的寻优方法的多次交叉验证。如根据数据情况将其拆分为3组,先用1和2来训练分类器,预测3以得到误差率;再用1和3训练并预测2得到误差率,最后用2跟3训练并预测1得到误差率。在进行交叉验证时,记录不同参数所对应的误差率平均值,最终选取最小的误差率平均值所对应的C和σ作为最优参数。通过LibSVM软件采用此寻优方法得到最优参数C=2.0,σ=8.0和损失函数ε= 0.0009765625,将寻优得到的参数输入对学习样本进行学习,可以得到一个高再受热面的灰污监测模型。
2.4模型分析
将寻优得到的参数运用到支持向量回归机中对学习样本进行学习,可以得到一个高再受热面的灰污监测模型。再通过此模型对预测数据样本进行预测,所得预测结果的均方误差Means squared error=0. 000593793,相关系数Squared correlation coefficient=0. 989223,结果如图2所示。由于选取的是高再受热面积灰试验的样本,开始吹灰之前的灰污系数已经接近于上限0.9,当吹灰开始后,灰污系数明显下降,吹灰结束后缓慢上升。由均方误差和相关系数可见模型的准确性很高,曲线能够很好的跟踪实际过程,模型能够准确反应出高再受热面污染状况的改变。
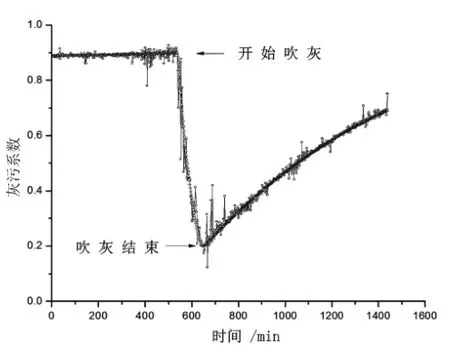
图2 模型预测结果
3 结语
运用支持向量机算法对超超临界锅炉污染监测模型进行了预测,主要得出下面结论:
(1)支持向量机相比于神经网络算法,使用了很小的样本获得了更准确的预测模型,并且避免了神经网络“过学习”和局部最优化的问题。
(2)通过预测曲线可以看到,运用ε-支持向量回归机得到的预测结果均方误差很小,曲线能很好的跟踪实际过程,运用支持向量机预测灰污系数的方案是可行的。
(3)目前基于支持向量机的锅炉污染监测模型的研究还有待推广到实际应用中,这是下一步的研究方向。
[1] 王新,马波,向文国.600MW机组锅炉对流受热面在线监测研究[J].江苏电机工程,2007,26(5):63-65.
[2] 万俊松,向文国.基于神经网络的电站锅炉空气预热器积灰在线监测模型研究[J]. 能源研究与利用,2006,(3):14-16.
[3] 朱予东,阎维平,高正阳,等. 600MW机组锅炉对流受热面污染状况实验与吹灰优化[J]. 动力工程,2005,25(2):196-200.
[4] 吴观辉,向文国.基于神经网络的锅炉对流受热面灰污监测研究[J].锅炉技术,2005,36(2):18-21.
[5] 王广军,栾秀春.基于人工神经网络的电站受热面污染部位诊断[J].锅炉技术,2000,31(11):28-32.
[6] 白鹏,张喜斌,张斌,等.支持向量机理论及工程应用实例[M].西安:西安电子科技大学出版社,2008.
修回日期:2016-12-14
Research on Fouling Monitoring Model for Heating Surface of Ultra-supercritical Boiler Based on the Support Vector Machine
ZHOU Bao-zhong
(Huadian Electric Power Research Institute,Hangzhou 310030,China)
Through the study of“Experiments on Soot-blowing Effect of ultra-supercritical Boiler”from a science (innovative funding)project in a electricity generation group, a novel method was presented in the following part. To begin with, the real-time data sample was gathered by the DCS data acquisition system from the power plant. Furthermore, the ε-support vector regression(ε-SVR)was used to build the learning and prediction model. Eventually, the consequence confirms that the predictive model based on the support vector machine could achieve a minimal mean square error, which means this approach will perform well in actual process tracking and forecast results.
support vector machine (SVM);boiler;fouling monitoring
10.3969/J.ISSN.2095-3429.2016.06.010
TK16
B
2095-3429(2016)06-0036-03
周保中(1984-),男,江苏宝应人,硕士研究生,主要研究领域为热力系统优化、能源战略与规划、碳排放管理、电力市场等。
2016-10-08
猜你喜欢
湖南电力(2022年2期)2022-05-08
云南化工(2021年11期)2022-01-12
应用能源技术(2020年11期)2021-01-26
热力发电(2020年9期)2020-12-05
英语文摘(2019年11期)2019-05-21
环境与发展(2018年1期)2018-02-03
青海政报(2017年16期)2018-01-31
动力工程学报(2016年11期)2016-12-22
工业设计(2016年7期)2016-05-04
现代冶金(2015年4期)2015-02-06
