
一种快速的基于特征选择的跨领域情感分类方法
2016-01-29 01:56:20胡学钢张玉红
合肥工业大学学报(自然科学版) 2015年11期
关键词:特征选择
徐 旭, 胡学钢, 张玉红
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
一种快速的基于特征选择的跨领域情感分类方法
徐旭,胡学钢,张玉红
(合肥工业大学 计算机与信息学院,安徽 合肥230009)
摘要:已有的跨领域情感分类方法多通过抽取公共特征空间或建立领域特定特征间的映射关系来消减领域间的差异性,由于不考虑特征情感区分力的差异,使得公共特征空间及特征映射的求解往往不准确。具有高区分力的特征对于文本情感分类具有重要的意义,但标记的缺失使得已有的特征选择方法难以应用。文章基于特征选择方法,提出一种快速的跨领域情感分类方法(cross-domain sentiment classification based on feature selection,CSFS),构建源领域特征与目标领域特征的词共现矩阵,基于该矩阵对目标领域特征的情感区分力进行评估,在目标领域中选择出其中具有高情感区分力的特征;再利用源领域信息计算目标领域特征的情感语义大小,从而构建目标领域分类器。实验结果表明,该方法在保证准确率的前提下,大大提高了跨领域分类的效率。
关键词:跨领域;特征选择;情感分类
博客、商品评论等信息在网络上大量涌现及其标记信息的相对缺失使得跨领域情感分类成为一个重要且富有挑战性的课题。当前的跨领域情感分类方法大多以领域间的差异性为切入点展开研究,通过特征提取构建特征公共子空间,使不同领域在该子空间中的分布差异性降到最低。文献[1-2]通过构建一个枢纽特征空间解决领域中的特征不匹配问题;文献[3-4]以通用特征为桥梁,构建通用特征和特定特征的共现矩阵,在此基础上采用谱聚类和相似计算等方法建立领域特定特征间的映射关系,并利用这种映射关系将目标领域特征扩充至源领域,从而使得分类器适应于目标领域;文献[5]以解决领域专有词和减弱领域分布差异性为目的实现跨领域分类;文献[6]以通用特征为桥梁,将目标领域的预标记实例加入原始领域迭代训练;文献[7]将Logistic回归模型进行扩展,使原始领域训练的分类器适用于目标领域。
然而这些方法基于词频、互信息选择通用词,并未考虑特征在目标领域的区分力,使得共现矩阵中存在部分冗余和不相关的共现关系,导致特征映射关系求解结果不准确。这在情感分类中尤为突出。如特征“good”、“excellent”,对文本的情感极性具有决定性的作用,而“said”并不具有很强的区分力,基于这些特征进行公共特征空间求解和分类,往往导致部分不相关的特征共现关系和跨领域分类精度的降低。文献[8-9]认为形容词相比于名词更具情感区分力,但仅以词性来区分,没有考虑单个特征之间的差异性。文献[10]提出一种特征加权实现源领域向目标领域的投影。文献[11]通过减弱差异大的特征、增强表现一致特征的方法,将2个领域关联在一起。然而,这些方法以领域的差异性为目标对特征进行选择或加权,而忽视了特征本身的区分力。
由于目标领域数据无标记,采用传统的特征选择方法如信息熵、互信息(mutual information,MI)、优势比(odds ratio,OR)等难以直接在目标领域中进行特征选择[12-13]。为此,本文提出一种基于特征选择的跨领域情感分类方法(cross-domain sentiment classification based on feature selection,CSFS)。该方法利用源领域信息对目标领域特征进行评估,选择出目标领域中具有较高情感区分力的特征,并借助源领域计算目标领域特征的情感语义,从而构建目标领域分类器。
1CSFS方法介绍
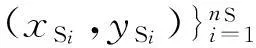
1.1 特征评估
本文利用源领域特征FS对目标领域特征FT的区分力进行评估,并以此作为特征选择的依据。
在标记数据中,MI、OR、分类比例差(proportional difference,PD)等方法可用来计算特征的区分力,文献[14]认为在文本分类中PD方法要优于其他方法。本文考虑到取值范围和正负向倾向值的对应性,采用PD表示特征的情感语义值,具体计算公式为:
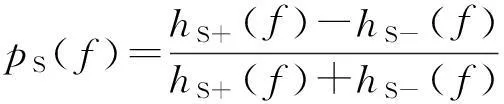
(1)
其中,hS+(f)和hS-(f)分别表示特征词f在领域DS中正向和负向文本中出现的概率。
PD的取值范围为[-1,1],正值表示特征倾向于正向情感,负值表示特征倾向于负向情感,绝对值越大表示其与该方向情感相关度越大。PD可用于衡量特征的情感区分力,在二类情感分类问题中,也可表示情感语义值。

根据源领域的特征FS′对目标领域特征的区分力进行评估,FS′的计算公式如下:
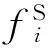
(2)
如果某特征与正语义特征和负语义特征的相似性差异越大,则其区分力也越大。目标领域特征fT的区分力定义为:
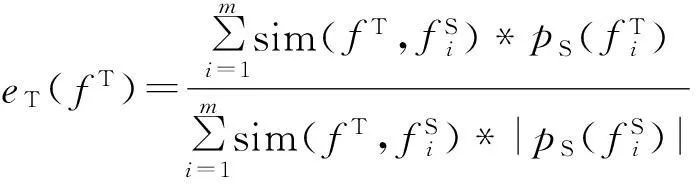
(3)

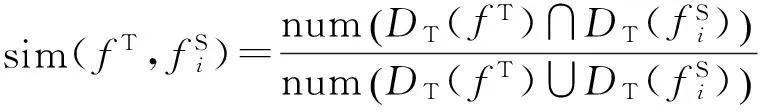
(4)
1.2 特征选择
尽管特征选择方法对目标领域特征的区分力进行了评估,然而领域差异性在一定程度上影响了评估结果的准确性。为此,本文通过综合考虑特征在2个领域的区分力来进行特征选择,强化在2个领域分类表现一致的特征,减弱不一致的特征,从而消减部分领域敏感特征在跨领域分类时的影响。特征最终的评估公式为:
(5)
表1所列为books领域到kitchen领域的部分特征选择示例。对于eT(fT)、pS(fT)表现一致的特征,通过相加后,其绝对值与eT(fT)相比变大,排序上升;而表现不一致的特征恰恰相反。表1中,特征annoying的排序靠前,而特征said-i的排序靠后,这与词语在分类中的实际情况相符。
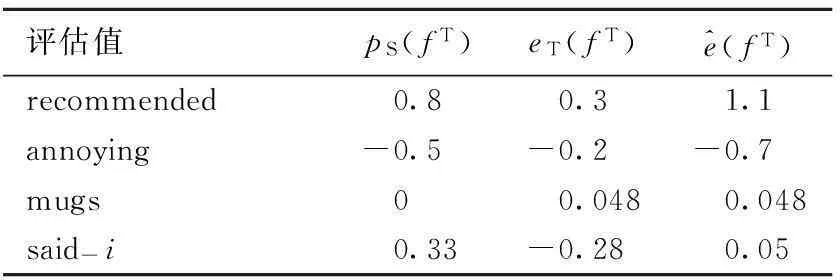
表1 特征选择示例
1.3 分类器构建
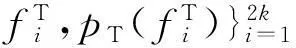
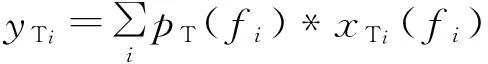
(6)
1.4 方法描述及分析
CSFS方法如下:
输入:源领域DS,目标领域DT,参数α、k。
输出:目标领域分类器C。
(1) 提取特征。
(2) 依据(3)式评估目标领域特征的情感区分力eT(fT)。
(5) 根据(6)式建立目标领域分类器。
2实验结果与分析
2.1 数据集与基准方法
本文采用的跨领域数据集[2]被广泛用于跨领域情感文本分类中,包含亚马逊4个领域产品评价:books(B)、dvd(D)、electronics(E)、kitchen(K)。每个领域有1 000个正类和1 000个负类。在该数据集上可构造D→B、E→B等12个跨领域情感分类任务,前面的字母代表源领域,后面的字母代表目标领域。为了说明CSFS方法的有效性,本文采用如下4个基准方法进行对比。
(1) NoTrans:在源领域训练分类器,直接用于目标领域分类。
(2) LLRTF:该方法选取在源领域极性强的并且在目标领域出现频率大的特征。
(3) SCL-MI:利用MI构建枢纽特征,并利用枢纽特征构建2个领域特征间的映射关系。
(4) SFA:基于共现关系构建领域特定词和通用词的二分图,在二分图上进行谱聚类得出特征簇,从而得到了特征簇内的特征间的对应关系。
2.2 参数讨论
本文参数主要有初始特征FS′的语义门槛α和最终选取的特征数目k。为了简明起见,以12个跨领域迁移实验的平均结果为标准,展示实验结果与参数的相关关系。无迁移和迁移方法分类精度随α参数的变化情况如图1所示,从图1可以看出α值为0.2~0.6为宜。α值太大则选取的特征数目过少,α值太小则会包含一些区分力不强的特征,2种情况都会影响实验的结果。
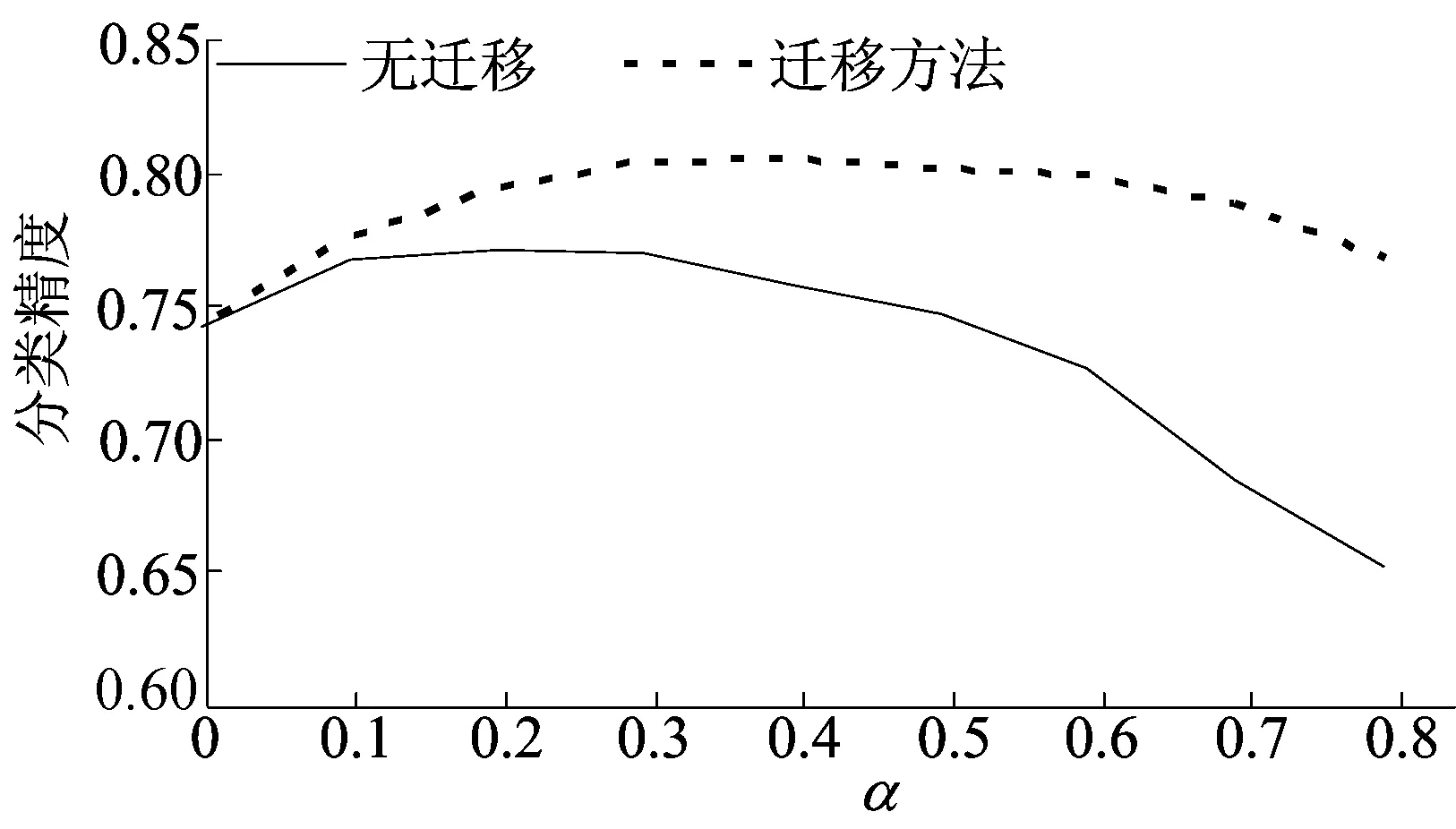
图1 参数α对分类精度影响
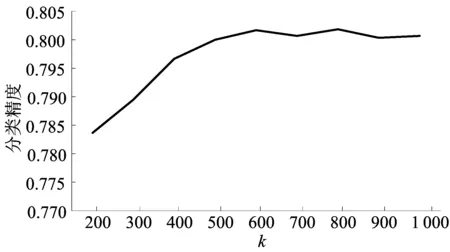
图2 参数k对分类精度的影响
2.3 方法扩展性验证
本文CSFS方法中涉及特征情感语义计算和特征相似度计算。为验证该方法的通用性,将特征情感语义计算方法扩展为OR,特征相似度的计算扩展为点互信息(point mutual information,PMI),如图3所示。图3中的分类精度为D→B,E→B等12个任务的平均精度,SIM-PD-Dall表示基于DS∪DT文档集用sim计算特征相似性,用PD计算情感语义值;PMI-PD-DT为基于DT文档集用PMI计算特征相似性,用PD计算语义值。其他方法说明类似。由图3可见,基于Dall计算相似度结果低于其他基于DT的方法,由此可见,仅在目标数据上进行相似度计算使得计算结果更符合目标领域数据分布;相同数据集上,采用PMI和SIM计算特征相似度对方法影响不大,同样采用OR和PD计算语义大小其结果也相当,说明CSFS方法具有一定的稳定性和扩展性。
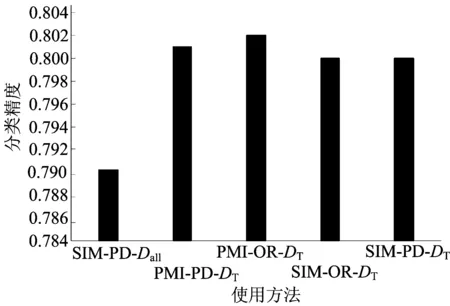
图3 方法扩展性验证
2.4 跨领域情感分类结果
CSFS方法与其他跨领域方法的分类精度对比结果见表2所列,CSFS方法的分类精度为SIM-PD-DT的实验结果。从表2可见,CSFS方法总体上优于其他方法。这是由于SFA和SCL在特征求解过程中均未考虑特征的区分力,选取的共现特征存在部分与分类无关的特征,从而影响求解结果。而CSFS方法通过特征选择筛除了无关特征,仅保留了具有较高区分力的特征,从而提高了分类精度。
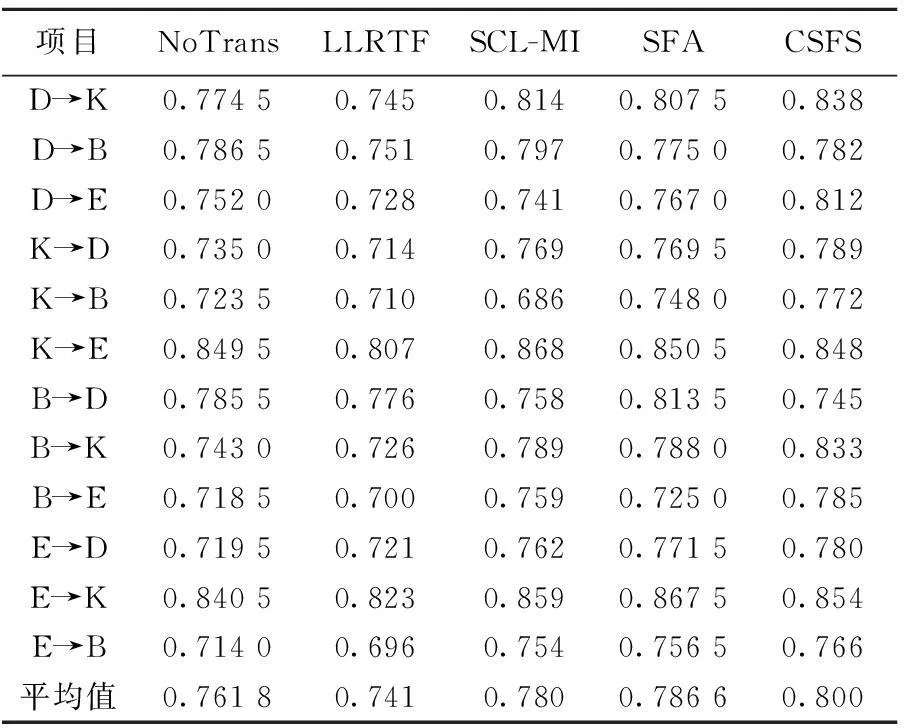
表2 各跨领域情感分类方法精度对比
由表2可知,仅在B→D和K→E任务上,SFA和SCL具有一定的优势,尤其是B→D任务上。其原因主要是由于B和D的领域差异较大,共现特征较少,导致共现矩阵较为稀疏,造成统计过程中的偏差,这将作为进一步工作的重点。
2.5 性能分析
各跨领域分类方法的时间开销对比见表3所列。由于SFA实验平台不同,故没有给出其运行时间。假设通用特征和特定特征个数分别为m和n,一般来说,SCL-MI和SFA需要对m×n阶矩阵进行奇异值分解和谱聚类,其方法的时间复杂度在串行环境下大约为O(n3)[15]。CSFS和LLRTF属于特征选择方法,其时间复杂度主要在特征排序上,约为O(nlbn),所需时间较短。两者分别需要对每一个特征求对数似然比和评估特征区分力,但由于CSFS方法采用特征选择方法,特征数目逐级降低,且只使用目标领域数据来计算特征相似度,数据规模较小,因此在时间效率上优于其他方法。
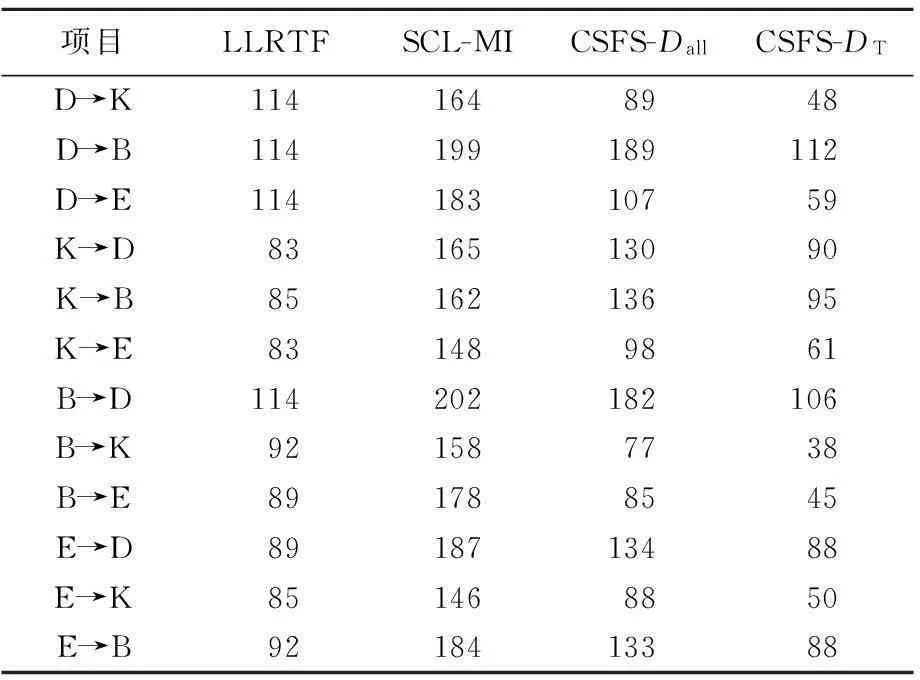
表3 各方法的时间性能对比 s
3结束语
具有较高情感区分力的特征对情感分类有重要的影响,因此,本文提出一种特征选择的跨领域情感分类方法,利用源领域信息对目标领域特征进行评估和选择,从中选取区分力较大的特征,并过滤其中不适用于目标领域的特征,利用源领域信息计算特征的语义值来构建目标领域分类器。本文以特征为表示主体,直接进行特征的选择和标记,具有较好的效率和分类精度。由于本文方法中的特征相似性是由贡献比例计算所得,因此该方法实际上具有隐含的假设,即训练数据正负文本要大致保持平衡。
[参考文献]
[1]Blitzer J,McDonald R,Pereira F.Domain adaptation with structural correspondence learning[C]//Proceedings of Empirical Methods in Natural Language Processing.Sydney,Australia,2006:120-128.
[2]Blitzer J,Dredze M,Pereira F.Biographies,Bollywood,boom-boxes and blenders domain adaptation for sentiment classification[C]//Proceedings of the 45th Association for Computational Linguistics,Prague Czech Republic,2007:440-447.
[3]Pan S J,Ni X C,Sun J T,et al.Cross-domain sentiment classification via spectral feature alignment[C]//Proceedings of the 19th International World Wide Web Conference.Raleigh,North Carolina,USA:ACM,2010:751-760.
[4]Bollegala D,Weir D,Carroll J.Cross-domain sentiment classification using a sentiment sensitive thesaurus[J].IEEE Transactions on Knowledge and Data Engineering,2013,25(8):1719-1731.
[5]Liu K,Zhao J.Cross-domain sentiment classification using a two-stage method[C]//Proceedings of the 18th ACM conference on Information and Knowledge Management,Hong Kong,China,2009:1717-1720.
[6]欧倩倩,张玉红,胡学钢.基于实例重构的多领域快速适应方法[J].合肥工业大学学报:自然科学版,2014,37(7):794-797,844.
[7]胡学钢,方玉成,张玉红.基于Logistic回归分析的直推式迁移学习[J].合肥工业大学学报:自然科学版,2010,33(12):1797-1801,1810.
[8]Xia R,Zong C Q.A pos-based ensemble model for cross-domain sentiment classification[C]//Proceedings of the 5th International Joint Conference on Natural Language Processing,Chiang Mai,Thailand,2011:614-622.
[9]Shi Y,Sha F.Information-theoretical learning of discriminative clusters for unsupervised domain adaptation[C]//Proceedings of the 29th International Conference on Machine Learning,Edinburgh,Scotland,UK,2012:1079-1086.
[10]Arnold A,Nallapati R,Cohen W.A comparative study of methods for transductive transfer learning[C]//Proceedings of the Seventh IEEE International Conference on Data Mining Workshops,Washington,DC,USA,2007:77-82.
[11]Satpal S,Sarawagi S.Domain adaptation of Conditional probability models via feature subsetting[C]//Proceedings of the 11th European Conference on Principles and Practice of Knowledge Discovery in Databases.Berlin:Springer-Verlag,2007:224-235.
[12]Whitehead M,Yaeger L.Building a general purpose cross-domain sentiment mining model[C]//Proceedings of the Computer Science and Information Engineering,Los Angeles,CA,2009:472-476.
[13]Church K,Hanks P.Word association norms,mutual information and lexicography[J].Computational Linguistics,1990,16(1):22-29.
[14]Simeon M,Hilderman R.Categorical proportional difference:a feature selection method for text categorization[C]//The Australasian Data Mining Conference,2008:201-208.
[15]王玲,薄列峰,焦李成.密度敏感的谱聚类[J].电子学报,2007,35(8):1577-1581.
(责任编辑闫杏丽)
齐美彬(1969-),男,安徽东至人,博士,合肥工业大学教授,硕士生导师.
A fast cross-domain sentiment classification based on feature selection
XU Xu,HU Xue-gang,ZHANG Yu-hong
(School of Computer and Information, Hefei University of Technology, Hefei 230009, China)
Abstract:Many existing cross-domain sentiment classification methods reduce the distribution difference between domains by extracting a common sub-space or establishing the mapping relationship between domain specific features, and do not consider the difference of features’ sentiment orientation. Some features with lower sentiment orientation will influence the result of sub-space and mapping relationship. Features with higher sentiment orientation are important for sentiment classification. However, it is difficult to apply existing feature selection methods on unlabeled data. In this paper, a fast cross-domain sentiment classification based on feature selection(CSFS) is proposed. Firstly, the word co-occurrence matrix between the source features and target features is constructed, the sentiment orientation of target domain features is evaluated, and then words with higher sentiment orientation are selected as the feature space of target domain. Secondly, the features in target domain are labeled using the source features, and then a classifier is created based on the labeled features. The empirical result shows that CSFS highly improves the time efficiency of cross-domain classification while maintaining the classification accuracy.
Key words:cross-domain; feature selection; sentiment classification
doi:10.3969/j.issn.1003-5060.2015.11.011
作者简介:侯建民(1988-),男,山西大同人,合肥工业大学硕士生;
基金项目:国家高技术研究发展计划(863计划)资助项目(2011AA7054019)
收稿日期:2014-11-13;修回日期:2015-01-16
中图分类号:TP181
文献标识码:A
文章编号:1003-5060(2015)11-1488-05
猜你喜欢
河南科学(2021年3期)2021-05-06 03:06:46
电信科学(2017年6期)2017-07-01 15:44:35
自动化学报(2017年5期)2017-05-14 06:20:50
电子制作(2017年23期)2017-02-02 07:17:06
电测与仪表(2016年23期)2016-04-12 00:23:08
西北工业大学学报(2015年4期)2016-01-19 03:31:47
智能系统学报(2015年4期)2015-12-27 09:38:21
电测与仪表(2015年24期)2015-04-09 12:04:32
振动工程学报(2014年4期)2014-03-01 01:15:41
计算机工程(2014年6期)2014-02-28 01:26:36
