
计算机文本信息挖掘技术在网络安全中的应用
2016-01-22 09:07韩文智
华侨大学学报(自然科学版) 2016年1期
韩文智
(四川职业技术学院 计算机科学系, 四川 遂宁 629000)
计算机文本信息挖掘技术在网络安全中的应用
韩文智
(四川职业技术学院 计算机科学系, 四川 遂宁 629000)
摘要:针对网络文本信息的安全性判别问题,采取改进的邻近分类算法挖掘文本.该改进邻近分类方法在传统方法定义分类特征的同时,起用共线性判别矩阵,对具有共线属性的特征合并处理.这种改进策略,不仅可以增加分类特征的准确性,也可以加快文本信息的分类进程.对Spambase语料库开展实验研究,从精度、召回率、联判度、误差4个维度对分类效果进行评价.结果显示:改进的邻近分类方法具有明显的优势,可以更加准确地区分安全文本和危险文本.
关键词:文本信息; 文本挖掘; 文本分类; 邻近分类
在信息量爆炸式增长的今天,人们生活方式发生了极大改变[1].人们很少通过纸质文件进行信息交流,代之的是电子邮件、微博、短信、微信.这种信息交流方式确实更为便利,但也出现了新的安全隐患.部分广告人员和诈骗者,借助网络渠道向广大网络用户的邮箱、微信中发布广告信息和诈骗信息,拦截这些垃圾信息已经成为当今网络安全的重要课题之一[2].计算机文本信息挖掘技术在信息分类、信息识别方面具有重要作用.网络信息的典型特征对于准确判断这些信息是否是垃圾信息、提升网络安全具有重要意义[3].文献[4-10]对文本挖掘进行了研究.本文对邻近分类文本挖掘方法进行改进,提升其在网络安全中的实用效果.
1文本挖掘和邻近分类
1.1 文本挖掘
文本挖掘是数据处理领域的一个重要分支,其操作对象主要针对文本信息.文本挖掘是从大量的文本信息中抽象、提取出具有可以理解的特征、知识,便于对文本信息进行进一步的分类、识别.
文本挖掘的过程涉及到多个环节,具体的流程如图1所示.文本挖掘的对象包含了各类文本信息,如期刊中的文本信息、网页中的文本信息、基于文本信息构建的数据库.文本挖掘之前,一般需要执行与处理文本信息,包括对文本信息的去噪处理、分词处理、停词处理、特征表示、特征提取.在文本挖掘这个核心阶段中,挖掘结果最终体现为文本分类、文本聚类、关联分析、趋势预测等.文中研究的重点在于文本分类.

图1 文本挖掘的流程Fig.1 Process of text mining
1.2 邻近分类
邻近分类算法是文本分类的重要执行方法之一,它构建c个分类方案,并将待区分的文本分别和这c个方案进行比较,并以最接近的方案来定义文本的属性.在分类的过程中,首先要制定各个方案的描述特征,之后,对待分类文本进行分词和特征设置,再根据相似性计算判断邻近性,其核心计算公式为
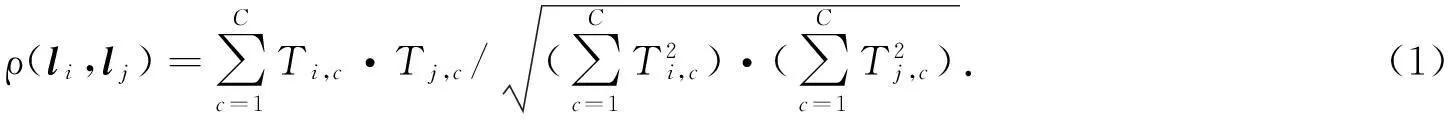
式(1)中:ρ表示相似性;li,lj表示参照文本信息和待挖掘文本信息的特征向量;Ti,c,Tj,c表示参照文本信息和待挖掘文本信息的分词.
通过式(1)可以在文本集中选取出和待挖掘文本信息相似的几个文本,判断待挖掘文本到底属于哪一个类别的公式为

式(2)中:F(l,Lj)为待挖掘文本信息的最终分类结果;w(li,Lj)为待挖掘文本信息,属于某一分类权重.
2邻近分类方法的改进
邻近分类方法是一类原理简单、操作方便的文本挖掘方法,但其最大的问题在于不同分类特征可能存在共线,这可能造成分类结果的不准确性.为此,在传统邻近分类方法的基础上,通过对文本特征的描述进行进一步修正.改进策略的核心思想是,将共线属性明显的文本特征进行合并,从而压缩特征向量的维度.这样,不仅能提升分类结果的准确性,也有利于算法执行速度的提高.在合并共线特征的过程中,统计变量为

式(3)中:H1为特征tA和特征tB一起出现的次数;H2为特征tA出现,而特征tB没有出现的次数;H3为特征tA没有出现,而特征tB出现的次数;H4为特征tA,tB都没有出现的次数.其共线性判别矩阵为

由式(4)可知:R越大,特征tA和特征tB的共线特征越明显.根据这个统计变量,对传统的邻近分类方法进行改进,有如下5个操作步骤.
步骤1对于邻近分类形成的各个特征计算其统计变量R,得到全部分类下全部特征的共线性判别矩阵(式(4)).

步骤4归一化后得到的共线性判别矩阵中,差距非常小的两个元素将被合并,从而形成更精简的特征集合.
步骤5根据精简后的特征集合,采用式(1),(2)所示的方法执行邻近分类.
3实验结果与分析
3.1 实验条件
为了验证所提出的基于改进邻近分类算法的文本挖掘方法的有效性,以网络安全检测中的应用为背景,展开实验研究.实验对象选择国际上标准的文本信息预料库Spambase语料库.在Spambase语料库中,共包含4 600条独立的文本信息,其中,带有危害用户信息安全的文本信息1 800条,其余2 800条为正常的文本信息.根据Spambase语料库的设定原则,上述4 600条信息可以用58个特征进行概括性描述,每条文本信息到底是属于安全信息还是有危害信息,需要根据这些特征进行区分.
实验方法上,选择了传统邻近分类方法和文中方法,以便进行网络安全文本挖掘效果的横向对比.对于Spambase语料库中的4 600条文本信息,将其中1 600条作为训练样本,剩余3 000条作为实验中的检测样本.先通过1 600条训练样本,对两种方法进行训练,确定分类参数后,再通过另外3 000条文本信息检验两种方法的分类效果.
3.2 评价参数
全部文本信息的判定,只有安全信息和危险信息这两类判定结果,这是一个典型的二分类问题.为了提升判别结果的可信度,一般同时采取算法判定和专家判定两种方式.这样就出现了4种可能:
1) 算法判定结果和专家判定结果都是安全信息的文本信息,用T1表示;
2) 算法判定结果为安全,专家判定结果为危险的文本信息,用T2表示;
3) 算法判定结果为危险,专家判定结果为安全的文本信息,用T3表示;
4) 算法判定结果和专家判定结果都是危险信息的文本信息,用T4表示.
精度、召回率、联判度都是和分类效果好坏同向的,而误差则和分类效果好坏是反向的.
3.3 实验结果
为了验证基于改进邻近分类算法的文本分类方法的有效性,设计一个网络信息安全检测分类系统软件平台.
平台以Spambase语料库分类的文本对象,分类方法集成了传统邻近分类方法和文中方法.软件平台的操作界面,如图2所示.由图2可知:软件平台上方为一级功能菜单区,包含了首页、用户管理、预处理、分类、趋势预测等功能,文中关注的是分类功能的设计;平台左侧是对应一级功能菜单的二级功能菜单,当前情况是选中分类菜单后其下的3项子功能,包括分类方法、参数评价、分类结论;平台中下方是主显示区,用于显示分类结果和对应的评价参数.

图2 网络信息安全检测分类系统Fig.2 Network information security detection and classification system
针对Spambase语料库的具体情况,分别选择10个特征进行安全信息和危险信息的区分,利用传统邻近分类方法改进邻近分类方法得到分类结果评价参数,如表1所示.由表1可知:所构建的基于改进邻近分类算法的文本分类方法,在精度、召回率、联判度、误差这4项评价指标上,分类效果都明显高于传统邻近分类方法;对于总数为3 000的测试文本信息,以5特征进行区分时,分类误差低于9%.
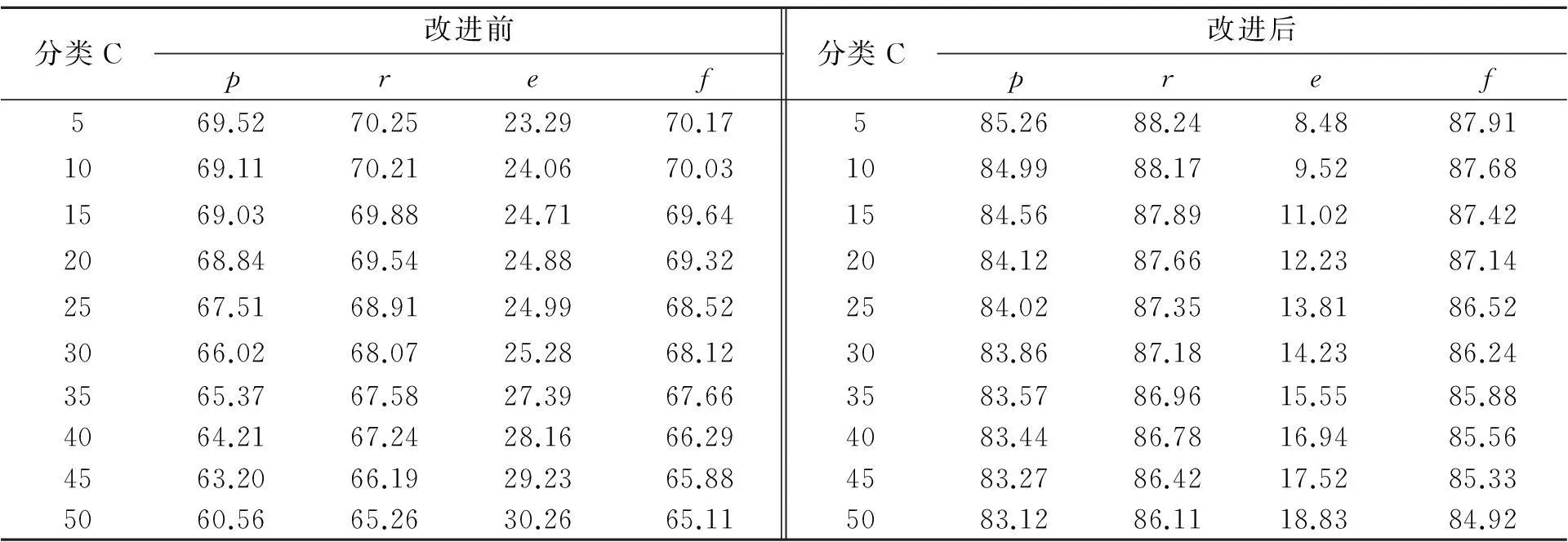
表1 传统邻近分类方法实验结果
4结束语
对邻近分类算法进行改进,并用于文本信息的安全性判别.此方法采取了共线性判别矩阵对文本信息的共线属性进行合并处理,这样可以增加属性分类的准确性,也通过合并特征属性达到提速的效果.实验结果表明,改进方法可以准确地区分安全文本和危险文本,适用于网络安全技术
参考文献:
[1]DAVIES S,MOORE A.Bayesian networks for lossless dataset compression[C]∥Proceeding of International Conference Knowledge Discovery and Data Mining.San Diego:ACM Press,2013:387-391.
[2]喻小光,陈维斌,陈荣鑫.一种数据规约的近似挖掘方法的实现[J].华侨大学学报(自然科学版),2008,29(3):370-374.
[3]MERETAKIS D,WUTHRICH B.Extending naïve bayes classifiers using long item sets[C]∥Proceeding of International Conference Knowledge Discovery and Data Mining.San Diego:ACM Press,2013:165-174.
[4]ESPOSITO F,MALERBA D,SEMERARO G,et al.A comparative analysis of methods for pruning decision trees[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,19(5):476-491.
[5]LAM S L Y,LEE D L.Feature reduction for neural network based text categorization[C]∥Digital Symposium Collection of 6th International Conference on Database System for Advanced Application.[S.l.]:IEEE Press,2015:1121-1130.
[6]CESTNIK B,BRATKO I.On estimating probabilities in tree pruning, machine learning: EWSL-91[C]∥Kodratoff Lecture Notes in Artificial Intelligence.Berlin:Springer,2015:138-150.
[7]ANDROUTSOPOULOS G,PALIOURAS V,KARKALETSIS G,et al.Learning to filter spam e-mail: A comparison of a naïve Bayesian and a memory based approach[C]∥Proceedings of 4th European Conference on Principles and Practice of Knowledge Discovery in Databases.London:Jerry Press,2000:1-13.
[8]SUN Lihua,ZHANG Jidong,LI Jingmei.An improved knearest neighbor system and its application to text classification[J].Applied Science and Technology,2002,29(2):25-27.
[9]寸待杰,刘韶涛.采用内容挖掘的缅甸文字相似性文档检索[J].华侨大学学报(自然科学版),2013,34(5):521-524.
[10]RASTOGI R,SHIM K.Public: A decision tree that integrates building and pruning[C]∥Proceeding of 24th International Conference on Very Large Data Bases.New York:[s.n.],2014:404-415.
(责任编辑: 陈志贤 英文审校: 吴逢铁)

Application of Computer Text Information Mining
Technology in Network Security
HAN Wenzhi
(Department of Computer Science, Sichuan Vocational and Technical College, Suining 629000, China)
Abstract:In view of the security problem of network text information, we adopt an improved neighbor classification algorithm to carry out text mining. In improved nearest neighbor method, definition and classification are carried out by traditional method, and characteristics are merged by reinstating co-linear discriminant matrix of collinear attribute features. This improved strategy not only increase the accuracy of classification features, but also speed up the classification process of text information. An experimental study is carried out on the Spambase corpus, and the classification results are evaluated from 4 dimensions. Namely accuracy, recall rate, the degree of error, and the error. Results show that the improved method has obvious advantages, and that is more accurate in the area of security text and dangerous text.
Keywords:text information; text mining; text classification; neighbor classification
基金项目:四川省自然科学基金重点资助项目(15ZA0349).
通信作者:韩文智(1966-),男,副教授,主要从事网络安全、软件技术的研究.E-mail:1691289966@qq.com.
收稿日期:2015-11-16
中图分类号:TP 393
文献标志码:A
doi:10.11830/ISSN.1000-5013.2016.01.0067
文章编号:1000-5013(2016)01-0067-04
猜你喜欢
软件导刊(2016年12期)2017-01-21
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
电子技术与软件工程(2016年22期)2016-12-26
商(2016年34期)2016-11-24
中国远程教育(2016年9期)2016-11-19
数字技术与应用(2016年9期)2016-11-09
电脑知识与技术(2016年23期)2016-11-02
科教导刊·电子版(2016年23期)2016-10-31
科技视界(2016年24期)2016-10-11
