
道路交通场景事件的语义解释方法
2016-01-15 08:32黄肖肖
山东理工大学学报(自然科学版) 2016年1期
关键词:信息技术
于 云,曹 凯,刘 春,黄肖肖
(1.山东理工大学 交通与车辆工程学院, 山东 淄博 255049;
2.山东英才学院 信息工程学院, 山东 济南 250104)
道路交通场景事件的语义解释方法
于云1,2,曹凯1,2,刘春1,黄肖肖1
(1.山东理工大学 交通与车辆工程学院, 山东 淄博 255049;
2.山东英才学院 信息工程学院, 山东 济南 250104)
摘要:针对传统道路交通事件语义解释方法依赖于定量数学建模方法,且底层语义概念与高级事件表达之间存在语义鸿沟的问题,提出了基于动态描述逻辑框架的事件语义定性表达和推理新方法.首先,对静态道路场景信息进行分类标记,构建交通领域本体模型,给出了本体知识库实时修改算法;其次,基于动态描述逻辑的动作公理,提出了描述车辆运动变化的运动模式集,实现了对一定约束条件下车辆机动能力范畴的刻画;最后,将事件语义解释过程抽象简化为目标的实现过程,提出了子目标生成以及实现规则,达到了依据交通事件语义解释交通态势变化过程的目的.实验结果表明:领域本体知识库的定义明确,拥有统一的框架结构,便于理解,且具有通用性;动态描述逻辑良好的表达和推理能力增强了事件语义描述的可靠性,较好地解决了语义鸿沟问题.
关键词:信息技术;场景理解;动态描述逻辑;领域本体;事件语义描述
收稿日期:2015-01-19
基金项目:国家自然科学基金项目(61074140);山东省自然科学基金项目(ZR2010FM007)
通信作者:
作者简介:于云,男,yuyun839243272@126.com; 曹凯,男,caokailiu@sdut.edu.cn
文章编号:1672-6197(2016)01-0005-07
中图分类号:U121; TP391
文献标志码:A
Abstract:For the issues of existing semantic gap between low-level feature and high-level events and the event semantic representation and reasoning overly relying on quantitative mathematical modeling method, in the paper, a new approach for event representation and reasoning with dynamic description logic is proposed. In the approach, firstly, all types of the static road scene information are classified by employing the domain axioms of dynamic description logic for integrating domain knowledge ontology. And a real-time update algorithm for the domain knowledge ontology is given. Then the action formulary based on action axiom of dynamic description logic is proposed for describing the action categories of vehicle under certain constraints. A rule of sub-goal generation and implementation for the event semantic representation and reasoning are suggested based on the approach to translate event semantic representation into different sub goals. The application results show that the proposed domain ontology has advantages in clear definition, unified framework, easily understanding and general use. In addition, the dynamic description logic language with better expressing and reasoning ability increase the reliability of the semantic description of the event, thus diminishing the semantic gap to a certain extent.
Semantic comprehension method of road traffic events
YU Yun1,2, CAO Kai1,2, LIU Chun1, Huang Xiao-xiao1
(1.School of Transportation and Vehicle Engineering, Shandong University of Technology, Zibo 255049, China;
2.School of Information Engineering, Shandong Yingcai University, Jinan 250104, China )
Key words: information technology; scene understanding; dynamic description logic; domain ontology; event semantic description
目前,动态道路交通场景理解[1]是智能车辆辅助系统研究领域的难点和热点.为了使车辆能适应复杂多变的交通环境,有必要将独立的道路场景信息转化成能够被智能车辆系统自动识别的语义.实现这一转化的关键是如何利用道路交通场景中的抽象化底层基本概念(如,场景区域特征和车辆运动状态特征等)表达道路交通场景事件的高级语义.即如何寻找一种底层基本概念之间的语义关联关系表达方式,在此基础上,依据关联关系对道路交通场景中高级事件语义进行识别,从而在底层基本概念与高级事件语义表达之间建立起一种自下而上的表现方法.
为此,国内外学者做了大量关于交通场景事件理解方法的研究.国外,Haag等人提出了基于光流场模型的三维道路交通场景理解方法[2];Hummel等人借用车载视觉传感器和数字地图获得的数据对特定的交叉口进行场景理解[3]; Ki等人利用车辆的方向、位置及加速度等运动特征模型来推断交叉口复杂事件的语义[4].国内,吴东晖等认为道路场景理解算法必须能够处理不确定性信息,提出了一种基于不确定性知识的场景理解算法[5];康维新等将事件抽象成HMM(隐马尔可夫)模型,并将NCL(自然约束语言)逻辑化,提出事件的语义描述形式[6];徐杨等提出基于SOFM和HMM模型的交通事件自动检测方法[7].
以上研究大多采用传统的定量技术手段进行场景建模,即,将底层基本概念符号化,构建数学模型推理表达交通场景事件的语义.由于定量方法在建模和算法方面的局限性,使得这些定量方法对交通事件类型的依赖性较强,而对于复杂多变的道路交通场景,有些难以抽象出相应的数学模型.因此对于那些无法建立函数关系的交通场景描述及推理,动态描述逻辑框架为其提供了新的思路和方法,从定性描述角度展现了自然语言在交通场景描述及推理方面的表达能力,其优势如下:动态描述逻辑能同时处理静态和动态知识,保证了底层基本概念表达的完整性;动态描述逻辑语言框架拥有良好的推理表达能力,其推理算法总是会终止,并输出正确的结果,为利用底层基本概念表达高级事件语义提供了必要的逻辑推理算法保障,起到了利用底层基本概念表达高级事件语义的桥梁作用;此外,动态描述逻辑语言类似于人类语言,有严格统一的语言框架,这使其在表达不同场景信息时具有通用性.
为此,本文提出了基于动态描述逻辑框架的道路交通动态事件语义表达及建模的新方法.首先利用动态描述逻辑中的领域公理,将所有不同类型的道路交通场景信息集成为领域本体知识库,构建领域本体模型.然后将车辆运动状态公式化,并将道路交通场景中事件的演化过程抽象成多个子目标的演化过程.最后实现对动态道路交通事件的语义解释.
1领域本体模型构建
领域本体是指利用概念性词汇描述领域内基本规律、先验知识、事实等基本信息的知识框架[8-10],是语义表达和推理的基础.因此,构建定义明确、结构统一的本体知识库一定程度上减少了底层基本概念与事件语义表达之间的语义鸿沟.
基于动态描述逻辑公理[11],本文提出的领域本体知识库形如O = < Tbox, Abox, M>.其中,Tbox是指依据概念公理从交通场景中抽象出来的基本概念集(术语集)及其相互关系;Abox是指术语中个体实例的断言集,动态描述逻辑的推理机制能强化原有断言并生成新的断言;M是指运动对象动作能力的逻辑化公式集,用以表达车辆机动能力范畴.
1.1 Tbox和Abox的构建与表达
交通领域本体构建的关键是道路交通场景对象的概念化.即在被观察的动态道路交通场景中,应用形式统一的概念术语分类标记每个场景区域和对象,并汇集成Tbox术语集.然后,利用Tbox表达描述事件的概念及其相互关系的语义,为动态交通场景理解及推理提供前提.
为了统一标定对象区域,以下以图1为例给出道路场景区域之间概念及其关系的分类标记方法.图1(a)是某道路场景片段;图1(b)标定了道路场景片段中每个区域的界限,并用正整数分类标记,分类结果如图1(d),而且每个区域的特性由先验知识获得,并写入Abox中(例如,Sideway为步行道路,Grassplot表示人/车禁行区域).图1(c)是图1(b)的抽象表达,其定义的9个节点对应图1(b)的9个区域,节点间用弧线连接,表示区域之间的相邻关系.其中,节点4、6、8代表行人通行的区域,节点2、9表示车或人都可以通行的区域.于是,在编码时,可以根据既定规则(先验知识)来设置约束条件.
于是,依据表1的语法规则,动态描述逻辑可以利用道路场景概念术语进行知识建模.
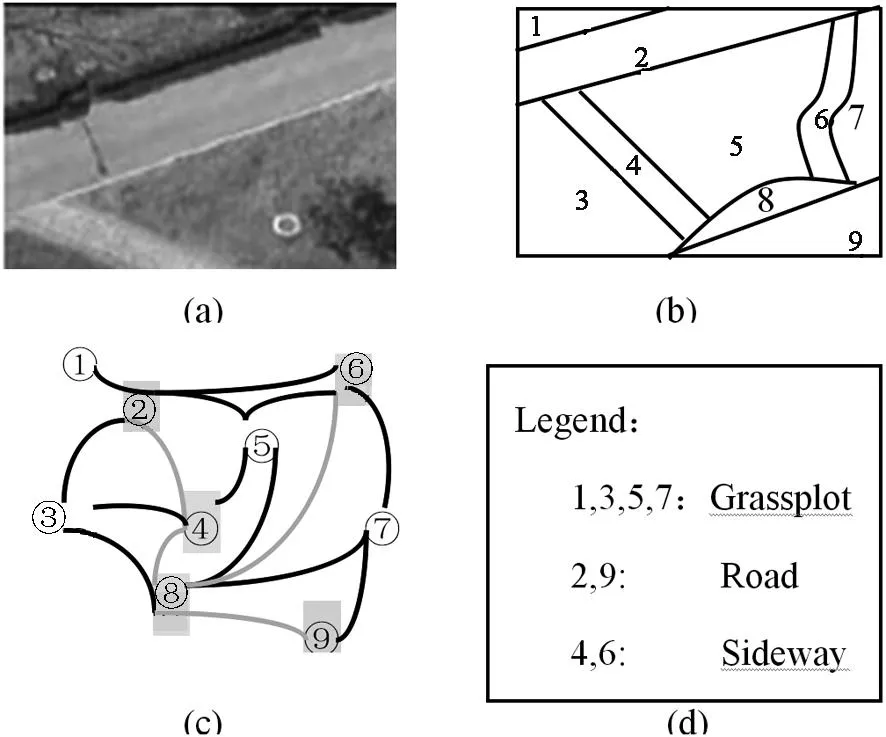
图1 区域间的拓扑关系
表1描述逻辑语法规则

逻辑符号符号C,D→A原子概念⊥底层概念┐A原子否定式C∧D合取集C∨D析取集∀R.C约束关系∃≥nR.有限制的存在变量C⊄D关系否定式
举例说明,假设Road和Highway是2个原子概念,那么,Road∧Highway和Road∧┐Highway就是动态描述逻辑描述的2个概念.其表示的是一些道路是公路,而另一些道路则不是.此外,若“running”是一个原子角色,则表达式Car∧∃≥1running.和Car∧∀running.Black表示至少有1辆行驶的车辆和任意行驶车辆为黑色.而Car∧∀running.⊥应用了底层概念描述没有任何行驶车辆.
于是,依据概念标记分类法以及动态描述逻辑语法规则,可以构建城市道路场景的基本概念集Tbox,其基本概念主要包括: Road,Lane,Marking及Vehicle等.此外,还存在父子概念的包含关系,以转向车道为例:
● 转向车道是车道的子概念,即
TurningLane⊆Lane;
● 左/右转车道又是转向车道的子概念,即LeftTurnLane∨RightTurnLane⊆TurningLane;
● 依据动态描述逻辑包含公理,父概念可以表示为子概念的析取集,即
LeftTurnLane∨RightTurnLane∨StraightAheadLane∨UTurnLane⊆TurningLane;
● 隶属同一父概念的子概念之间也能发生联系,例如
(LeftTurnLane∨RightTurnLane)⊆(┐UTurnLane∧┐ StraightAheadLane).
更具体的城市道路场景的基本概念及其包含关系如图2所示(箭头表示包含关系).
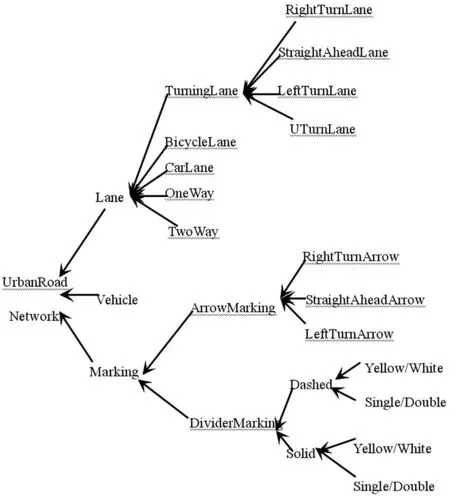
图2 城市道路中的基本概念及其关系
此外,利用描述逻辑的原子否定式及关系否定式规则(如表1),还可以形式化Abox中的断言.例如,图1中写入Abox的断言可以形式化如下:
● Sideway为步行道路,即
┐Pedestrian⊄Sideway;
● Grassplot表示人/车禁行区域,即
Pedestrian∨Vehicle⊄Grassplot.
总之,Tbox和Abox集是交通领域本体模型构建的基础概念.在此基础上,运动模式集M则刻画了车辆在一定条件下能够执行的动作能力范畴.
1.2 运动模式集M的构建与表达
城市道路场景中,车辆的基本运动模式包括:StartUp、Run、GoStraight、TurnLeft、TurnRight、SpeedUp、SpeedDown、Stop,其表示方法如图3所示.
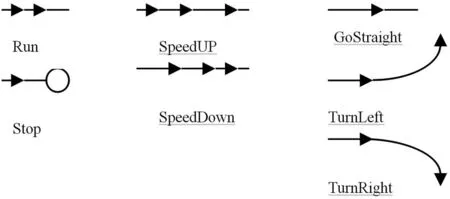
图3 基本运动模式
为了给出动作模式的定义规则及其描述逻辑的表达形式,首先引入动态描述逻辑的动作公理[12]:
(1)前提公理
(1)
(2)后继状态公理
(2)

动作公理描述了事物变化前后的基本特征及其规律.事实上,运动模式是由动作公理衍生而来,即,运动模式的前提集和结果集分别对应动作公理的前提集和后继状态集.因此,依据动态描述逻辑的动作公理,交通场景中车辆的动作描述包括:动作名称、先验断言集(Q)、前提集(P)和结果集(E).以TurnLeft、TurnRight和SpeedUp为例说明动作形式化的表达式.
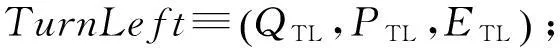
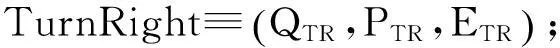
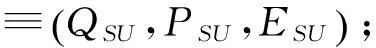
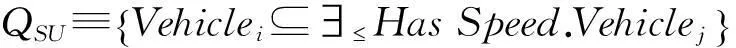
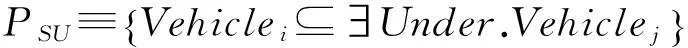
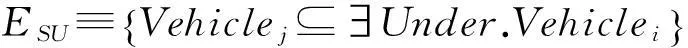
式中,i和j为正整数且i≠j.
这里,描述车辆运动状态变化的关键是如何选用恰当的运动模式变化来表达车辆的运动变化过程,而车辆的运动变化又包含在车辆的轨迹中.为此,举例说明如何将车辆运动模式的变化与车辆的轨迹变化相对应.
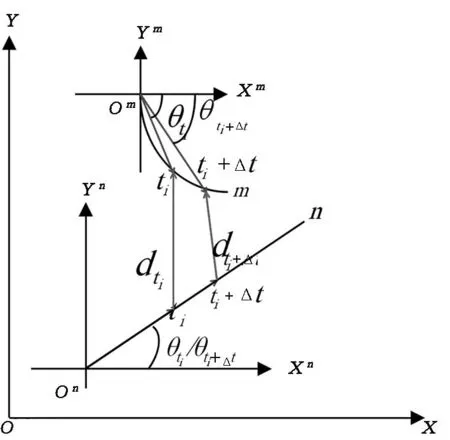
图4 不同坐标下的车辆
如图4所示,在某一观察时刻t,交通场景中有运动状态相互独立的2辆车m和n,并以每辆车初始位置为原点建立车辆运动的局部坐标系.于是,车辆运动轨迹可以表达为
(3)
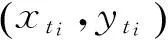
为了更好地反映车辆运动轨迹曲线表达的车辆运动状态变化,需将正交坐标下的车辆运动轨迹转换为极坐标,于是
(4)
并且定义间隔Δρi和Δθi,即
(5)
(6)
当时间间隔Δt→0时,Δρi和Δθi服从正态分布[13],于是,车辆运动模式与车辆轨迹曲线的对应关系可以表达为
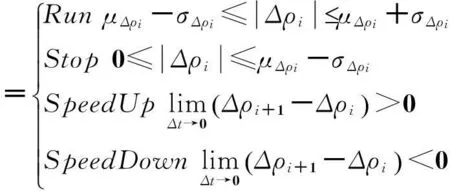
此外,对应于基本变量Δθi的变化,车辆运动方向的变化为
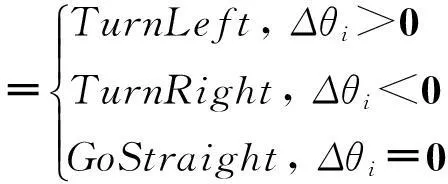
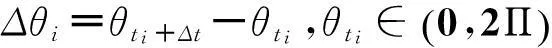
以上通过对Tbox和Abox的构建和表示以及运动模式集的描述逻辑表达,给出了交通领域本体的构建过程,为基于动态描述逻辑的一致性推理提供了框架基础.
2基于动态描述逻辑的一致性推理
为了保证更新后的新知识库同样满足本体框架的一致性和完整性要求,以下给出了基于动态描述逻辑一致性推理的知识库更新的2种主要方式——增补和删除.
(1) 知识增补.其主要思想是:假设B为原本体知识库,F为将要添加的知识集,则利用函数Extend()对公式集B和F进行推理并扩充,其推理依据是动态描述逻辑中的领域公理;然后,基于动态描述逻辑的一致性推理,利用函数 Consistent()进行一致性检测,如果检测出矛盾,则返回被检测公式集的矛盾集,并将其消除.算法流程如图5所示.
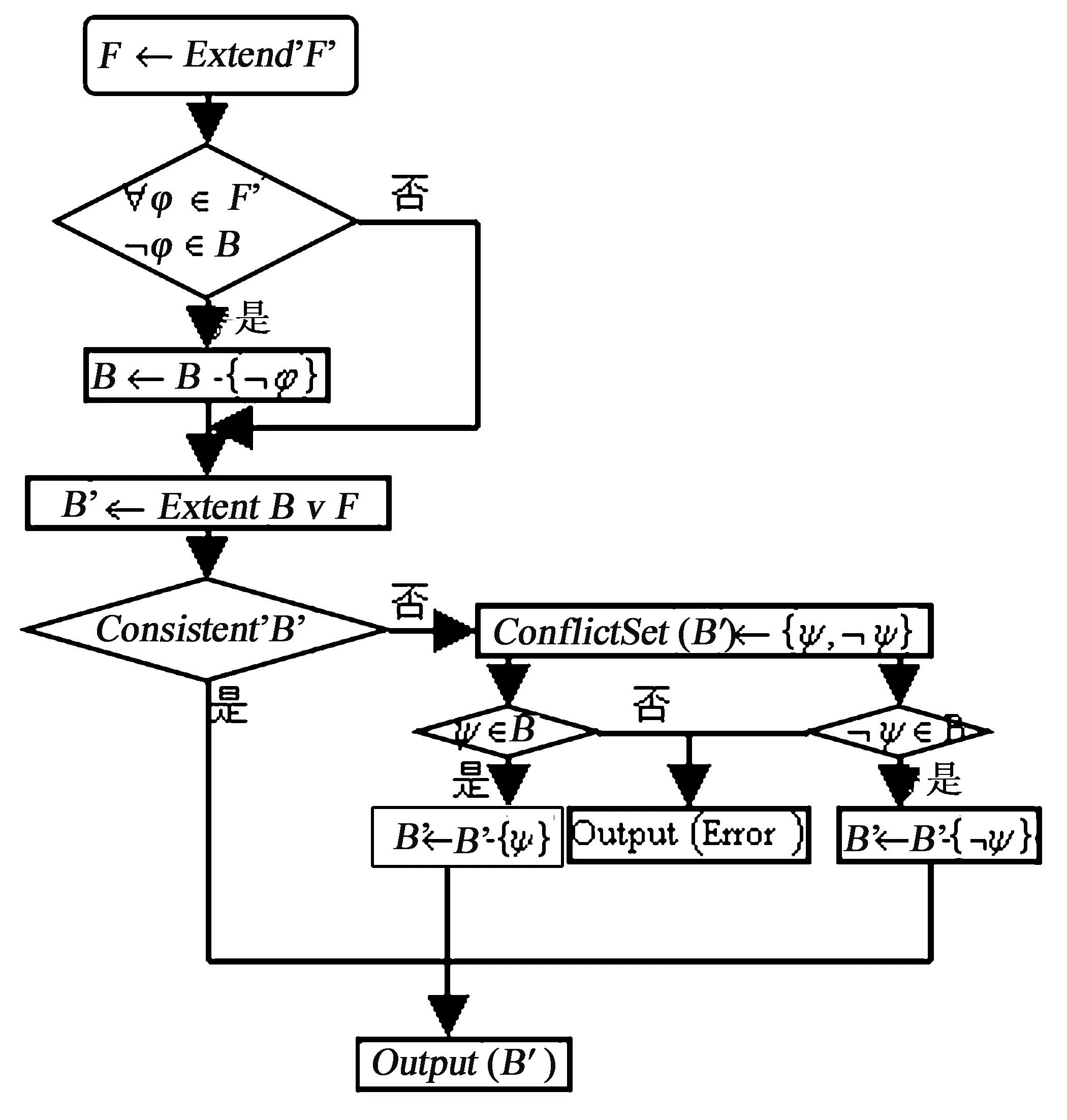
图5 知识添加算法流程图
(2) 知识删除.该算法比较简单,原因是删除操作不会导致不一致性.因此,先利用函数Extend()对更新后的本体库B和导致B不一致的矛盾集H进行推理并扩充,形成新的本体库B’和知识集H’,再从B’中删除H’中出现的所有断言公式.
总之,知识更新算法保证了领域本体知识库随着道路环境的变化以及车辆的运动情况而进行实时更新,而动态描述逻辑的一致性推理保证了新知识库的一致性和完整性,为事件的语义表达奠定了基础.
3事件语义解释
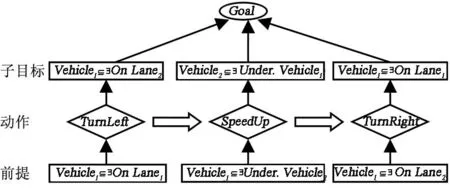
为了更好地解释道路交通场景事件的语义,这里提出一种基于动态描述逻辑的事件语义解释新方法.概括地说,就是将事件的语义解释过程抽象成子目标的实现过程.即,利用基于矛盾的反应式目标生成规则以及基于动态描述逻辑的一致性推理,检测第i和j帧(i 利用目标实现过程解释场景事件语义的关键是将表达车辆状态的断言公式解析成不同的子目标.为此,首先给出状态断言集以及基于矛盾的反应式目标生成规则的定义. 定义1第i帧场景图片中表达对象状态关系的所有断言公式形成的集合Si为总目标φ的第i个状态断言集. 定义2基于矛盾的反应式目标生成规则是指依据动态描述逻辑一致性推理检验相邻状态(按时间顺序产生的状态)断言集的析取集,若存在矛盾,则矛盾集中属于后继状态的断言公式为生成的子目标,即 式中:i>j;“?”指一致性检验符;Si为第i个状态断言集;φi为第i个矛盾集;断言公式Ti为生成的第i个子目标.ψj为第i个子目标的前提断言公式. 为了得到车辆的运动目标,分析实验车采集的视频图像(如图6,帧率(Framerate)约为50帧/s).利用本文提出的领域本体构建方法,首先标记分类场景对象(为了简化分析过程,只标记实验车和目标车及其经过的车道)得到Tbox: 状态1 状态2 状态3 状态4帧数:(78#) (539#) (2646#) (3242#)图6 事件分析 然后,将表达场景先验知识的断言公式写入Abox*: 最后,将第i帧图片中表达对象状态的断言公式写入状态断言集Si: 于是,目标生成过程为: (1) 首先,利用基于动态描述逻辑的一致性推理检测相邻状态断言集S78和S539析取集的一致性,即检测 (2) 同理,检测S539∨S2646以及S2646∨S3242的一致性,得到子目标T2和T3及其前提断言公式集φ2和φ3. 为了实现不同子目标,车辆需要完成相应动作.因此,给出了基于运动模式集M目标实现规则,利用运动模式将状态演化过程衔接起来,为事件语义解释服务. 定义3 基于运动模式集的目标实现规则是依据动态描述逻辑一致性推理分别检验第i个子目标的Ti以及φi与第j个运动模式结果集和前提集的一致性,若无矛盾,则执行第j个动作能够实现第i个子目标. 为了与图6的场景信息相匹配,首先将运动模式具体化,即运动模式定义中的i=1,j=2.对于子目标T1: 为解释场景事件的语义,依据目标分层算法[14]得到目标规划树(如图7).执行运动模式序列 可以完成子目标序列 因此,图6场景中事件高级语义解释为:“实验车跟随目标车行驶,左转变道后加速超越目标车辆,随后右转变道返回原行驶车道”,整个过程与超车事件过程 (“左转变道”→“加速超越”→“右转变道”)相吻合. 图7 规划树示例 综上所述,本节基于动态描述逻辑推理提出将车辆运动状态演化过程演变为目标实现过程,为交通事件语义解释研究开拓了新的思路和方法. 4结束语 本文利用动态描述逻辑框架搭建底层基本概念与事件高级语义之间的桥梁,提出了构建交通领域本体模型和交通场景事件语义表达的新方法,将场景中事件演化过程解析成多个子目标的实现过程.今后还需对交通场景的语义表达提出更加系统的语法及推理规则,而且应考虑基于时空关系的推理和不确定情况下的因果关系推理这一关键问题. 参考文献 [1]Neumann B, Möller R. On scene interpretation with description logics[J]. Image and Vision Computing, 2008, 26(1): 82-101. [2] Haag M, Nagel H. Combination of edge element and optical flow estimates for 3D-model-based vehicle tracking in traffic image sequences[J]. International Journal of Computer Vision, 1999, 35(3), 295-319. [3] Hummel B, Thiemann W, Lulcheva I. Scene understanding of urban road intersections with description logic [J]. Logic and Probability for Scene Interpretation, 2008,9,1-16. [4] Ki Y K,Lee D Y. A traffic accident recording and reporting model at intersections[J].IEEE Trans on Intelligent Transportation Systems,2007, 8( 2) : 188-193. [5] 吴东晖,叶秀清,顾伟康. 基于不确定性知识的实时道路场景理解[J].中国图象图形学报,2002,7(A):70-74. [6] 康维新,曹宇亭.交通事件的语义理解[J].应用科技,2013, 40(2): 5-10. [7] 徐杨,吴成东,陈东岳.基于视频图像的交通事件自动检测算法综述[J].计算机应用研究, 2011, 28( 4) :1 206-1 210. [8] 孙维聪. 基于 OWL 的领域本体构建方法研究[D]. 哈尔滨:哈尔滨工业大学, 2009. [9] 张文秀, 朱庆华. 领域本体的构建方法研究[J]. 图书与情报, 2011 (1): 16-19. [10] 李勇, 张志刚. 领域本体构建方法研究[J]. 计算机工程与科学, 2008, 30(5): 129-131. [11] 史忠植, 常亮. 基于动态描述逻辑的语义 Web服务推理[J]. 计算机学报, 2008, 31(9): 1 599-1 611. [12] 常亮, 史忠植, 陈立民, 等. 一类扩展的动态描述逻辑[J]. 软件学报, 2010, 21(1): 1-13. [13] Xin L, Tan T. Ontology-based hierarchical conceptual model for semantic representation of events in dynamic scenes[C]//Proceedings of the 14th International Conference on Computer Communications and Networks. Piscataway. NJ: IEEE, 2005: 57-64. [14] 吴修国, 曾广周, 许崇敬. 基于描述逻辑的目标推理研究[J]. 计算机科学, 2008, 35(7): 142-144. (编辑:郝秀清)3.1 目标生成
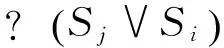

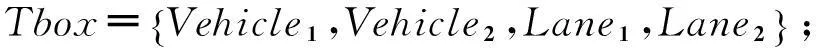
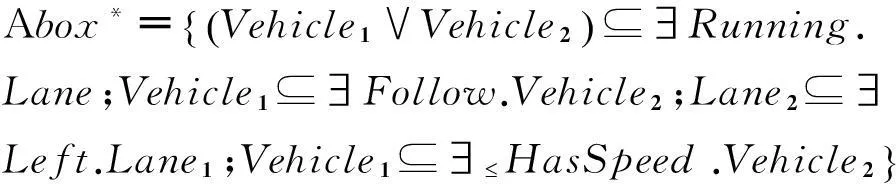
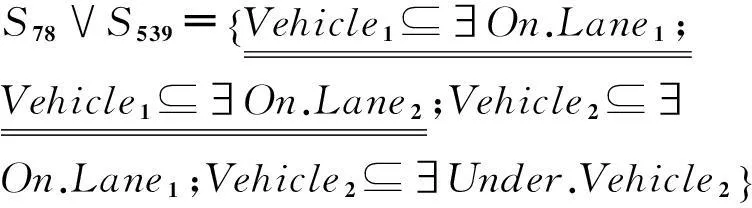
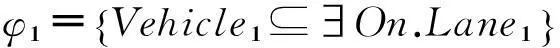
3.2 目标实现
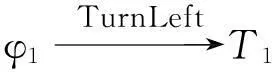
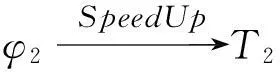
3.3 事件语义解释
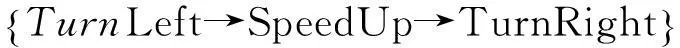
猜你喜欢
新一代信息技术(2021年22期)2021-12-29
新一代信息技术(2021年21期)2021-12-10
新一代信息技术(2021年17期)2021-11-13
新一代信息技术(2021年16期)2021-11-13
新一代信息技术(2021年14期)2021-11-13
新一代信息技术(2021年13期)2021-11-13
新一代信息技术(2021年2期)2021-07-23
新一代信息技术(2021年24期)2021-03-08
新一代信息技术(2021年23期)2021-03-08
新一代信息技术(2021年15期)2021-03-08
