
基于Gwt+Spring+Hibernate的实验室科研成果数据平台设计与实现
2016-01-12 03:00:55胡灵
科技创新导报 2015年5期
关键词:科研成果
胡灵
摘 要:为提高我们的科研成果信息管理水平,设计了一套基于GWT+Spring+Hibernae集成框架的业务系统,实现了从数据采集、数据管理,到数据分发与共享的实验室科研成果数据平台。该文对平台的具体实现进行了详细的说明。
关键词:GWT Spring Hibernate Ajax 科研成果
中图分类号:TH-3 文献标识码:A 文章编号:1674-098X(2015)02(b)-0050-02
随着科研信息化的飞速发展,国家对科研投入的加大,科研成果量也大幅增加。与传统手工收集科研成果相比,如今收集工作至少翻了两番。而每年年终时,各种统计报表要求上报,例如国家重点实验室上报科技部的年报,年终工作量的计算,年终汇报PPT上的基础数据,面向国家测绘局重点实验室的年终工作总结,学科评估,实验室的评估,报奖等等,都迫切需要一套完整的基础的科研成果数据平台来支撑以上数据的收集,如果基础数据不搜集完整,统计数据会不准确,统计工作量也会增加。为提高我们的科研成果信息管理水平,我们设计了一套基于GWT+Spring+Hibernae集成框架的解决方案。GWT提供的丰富的界面控件能满足用户复杂的操作需求,Spring对整个业务流程的控制和Hibernate的ORM解决方案可以让开发人员从传统的JDBC代码编写,事物回滚等底层基础功能编码中解放出来,从而更加专注核心业务逻辑的实现。利用以上技术框架,我们实现了一套的从数据采集、数据管理,到数据分发与共享的实验室科研成果数据平台。
1 相关研究和技术简介
1.1 GWT (Google Web Toolkit)
提到GWT[1]首先要说明AJAX,AJAX是Asynchronous JavaScript and XML的缩写,传统的web技术加载网页是整个网页进行一次性加载,用户体验差,AJAX技术的发展消除了传统web程序中令人讨厌的页面加载等待的过程,通过JavaScript异步地向服务器发送数据请求,而且更新网页也不会整体刷新,使得传统Web程序和桌面应用程序的体验感一致,又比桌面程序多了无需安装只需要浏览器就可以应用的好处,使得AJAX技术风靡web2.0时代。然而和桌面程序相比,无论是传统的Web程序还是基于AJAX技术的Web程序,在开发过程中的调试是无比困难和乏味的过程,由于JavaScritp语言天生的不严谨,和浏览器中调试JavaScritp工具的不稳定,开发人员可能需要花90%的时间来处理调试的问题,如果项目比较大,大量的JavaScritp代码库的维护会更加复杂和容易出错。而Google在2008年发布的GWT(Google Web Toolkit)技术就是针对以上问题而专门提出的一套解决方案,GWT允许开发人员使用java编程语言快速构建和维护复杂但高性能的 JavaScript 前端应用程序,GWT提供的核心功能是把Java语言编写的医用程序编译为AJAX应用程序发布,而且这些应用程序遵循web标准,不需要任何新的运行时环境或者插件支持,对浏览器而言和任何AJAX应用无任何区别。而对熟悉Java的开发者而且,如同是构建传统的桌面应用程序,同时在开发过程中可以利用成熟IDE,如Eclipse提供的高级调试支持和动态编译时候错误检测的功能,还可以充分利用Junit等软件测试工具对程序进行测试。在构建复杂的业务系统的时候GWT的优点体现的更加明显。
1.2 Spring/Hibernate 集成框架
Spring 由Rod Johnson于2002年首次提出[2]。Srping凭借着为企业级应用提供了一系列的轻量级解决方案,替代了冗余复杂的EJB(Enterprise JavaBean)方案,在设计模式上Spring实现了部分优秀的模式例如IOC(控制反转模式)和AOP(Aspect Oriented Programming)面向切面编程模式。被J2EE开发者广泛接受。并且越来越多的开源团队加入Spring开源社区为Spring贡献代码。
Hibernate 是ORM(Object Relation Mapping)对象关系映射的解决方案之一[3],主要是负责应用程序和数据库之间的交互,在ORM技术没有出现之前,开发者和数据库之间的交互是使用原生的JDBC技术,需要开发者对数据库字段一一映射,手动封装。这很容易出错,ORM技术的出现,特别是Hibernate技术使得开发者只需要关心业务实体对象,通过Hibernate的模板技术,自动会建立数据表的DDL语句,并产生CRUD操作,使得开发者从繁冗的JDBC编程中解放出来,更加关注业务的实现,同时由Hibernate接管数据库事务的提交和回滚,进一步保证了数据的一致性。
2 科研成果数据平台业务设计与实现
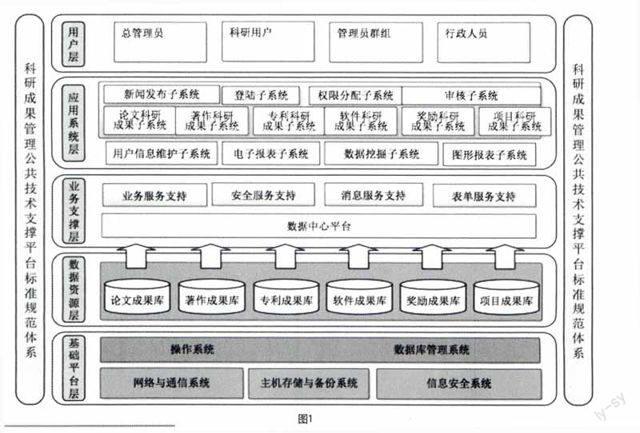
2.1 平台的整体架构
见图1。
2.2 平台功能模块设计
本系统设计了个人信息管理、论文、著作、专利、软件著作权、奖励、项目管理七大模块。包括各模块的新增,送审,查询,删除,审核、退回、生成报表等功能。
各模块组成如下:
个人信息管理包括人员基本信息,人才奖励计划(院士、长江学者、杰青等),学术组织/期刊任职。
论文包括:名称,作者,论文类型(国外重要刊物,国内重要刊物,会议论文特邀,会议论文普通),论文收录类型(SSCI、SCI、EI、ISTP、其他),期刊/会议名称,卷期页/会议时间地点,第一作者,通信作者,所属年份,以及PDF附件,备注。
著作包括:著作名称,作者,ISBN号,出版社,著作类型(编著,专著,译著,标准,教材)出版日期,所属年份,上传的书的封面以及CIP数据页面,备注。
专利包括:专利名称,专利号,专利类型(发明专利、实用新型专利),发明人,是否独立完成单位(是/否),完成单位,申请时间,批准时间,所属年份,上传专利证书,备注。
计算机软件著作权包括:软件名称,软件登记号,是否独立完成单位(是/否),完成单位,完成人,首次发表时间,批准时间,所属年份,上传登记证书,备注。
奖励包括:奖励名称,证书号,类别,奖励等级(国家级、省部级、其他),参加人员,承担单位,授奖单位,所属年份,备注,上传获奖单位证书以及获奖项目的图文说明。
项目包括:名称,项目编号,负责人,来源,类型(973计划、863计划、国家自然基金、国家重大专项、国家支撑计划、省部级项目、GF纵向、GF横向、一般横项、国际合作项目、其他),总经费,参加人,起始年月,终止年月,备注上传项目的批件、任务书或者横向合同首页经费页盖章页;根据每年到账经费的不同,设计了按照年度来统计项目经费到账明细。
2.3 平台的关键技术
由于实验室科研成果丰富,特别是历年来的论文PDF文档多达5000份,从中手动解析出论文题目和作者信息的工作量巨大,我们通过Apace PDFBox[4]这个开源的PDF解析包,从文档内容中分析出论文的标题和作者信息,新增入数据库。减少了手工操作的工作量,并保证了数据的正确性。对于新发表的论文实行人工录入,通过设置谁是第一作者谁录入的规则,我们保证了文章的唯一性。同时合作者也能看到该篇论文的录入。计算工作量时可以很迅速的算出。同时我们采取了VSM(向量空间模型)算法来计算两个论文标题之间的相似度,在人工填写论文标题的时候,我们通过Ajax技术不断的对录入的字符和数据库中的进行比对,把相似度高的论文标题显示在下拉框中提示录入者已经有类似的论文存在于数据库中,通过录入者人工判断是否继续录入该笔数据。
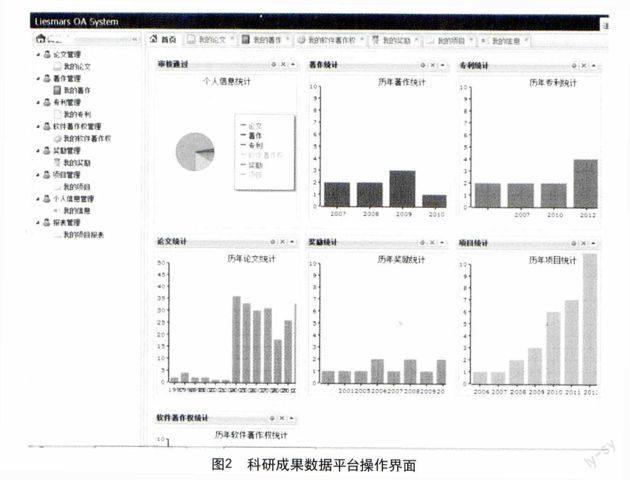
2.4 平台实现及创新
见图2。
(1)提供多维度科研成果库的展现,解决了单项科研成果涉及多位作者,在系统操作界面和数据库中保持多位作者对单项科研成果操作的一致性。实现了多作者共享科研成果的流程设计。
(2)设计了统一的数据格式,避免了由于历史数据冗余和错误等造成的数据分散,数据不准等问题。协同合作流程简化了数据的重复录入,提高了数据的利用率,减轻了科研人员的工作量。
(3)通过数据挖掘算法,提供用户对自己数据的多维度查看的功能,挖掘内在的关联信息。提供整个实验室科研情况的总体分析报表,给决策者提供支持。
3 结语
采用Gwt+Spring+Hibernate的实验室科研成果数据平台,发挥了各框架在各个层次上的优势,降低了开发的难度,在可维护性、交互性上较之一般的 J2EE 开发有明显的优势。本系统已投入使用一年,目前运行稳定,把集中维护的模式转换为个人维护模式,改进了科研机构的管理模式,提高了工作效率,而且也带动了实验室内部管理方法的优化和流程的规范化,得到了用户的好评。作为一个具有普遍意义的技术方案,该系统可为类似的系统开发部署提供参考。
参考文献
[1] GWT 官方网站http://www.gwtproject.org/.
[2] Rod Johnson.Expert One-on-One J2EE Design and Development Wrox2002-10-23ISBN:9780764543852.
[3] 孙卫琴.精通Hibernate:Java 对象持久化技术详解[M].北京:电子工业出版社,2005.
[4] ApathcPDFBoxhttp://pdfbox.apache.org/.
猜你喜欢
水运工程(2022年7期)2022-07-29 08:36:12
新世纪智能(英语备考)(2020年3期)2020-08-11 09:25:12
中国医院院长(2017年7期)2017-06-15 12:58:25
中国卫生(2016年12期)2016-11-23 01:10:16
