
基于关联规则Apriori算法的物联网海量数据挖掘系统研究
2016-01-08 03:48周芳
河北北方学院学报(自然科学版) 2015年1期
基于关联规则Apriori算法的物联网海量数据挖掘系统研究
周芳
(忻州师范学院计算机系,山西 忻州 034000)
摘要:物联网的出现为人们带来了诸多有利之处,人们在利用物联网的过程中会产生海量的数据,这些数据的不断增多加大了用户从中获取有用信息的难度,因此,物联网海量数据挖掘一直是研究的热点,面对物联网海量业务数据如何能够快速进行分析、处理、存储、挖掘,以实现有价值信息的快速提取,并服务于物联网商业决策,这是亟待解决的主要问题。将基于关联规则Apriori算法设计物联网海量数据挖掘系统。
关键词:Apriori算法;Hadoop平台;物联网;云计算;数据挖掘
中图分类号:TP 301.6
基金项目:河北省重点发展学科“作物栽培学与耕作学”建设项目,(2006)
作者简介:龚学臣(1963-),男,河北张北人,硕士,教授,主要从事旱作农业研究。
Mass Data Mining System for Internet of Things Based on
Association Rules Apriori Algorithm
ZHOU Fang
(Department of Computer,Xinzhou Teachers College,Xinzhou,Shanxi 034000,China)
Abstract:Internet of Things brings much convence.However,in the process of using it mass data increase continuously,which adds the difficulties of obtaining useful information from them.So,mass data mining has been a hot point in research on internet of things.To the mass bussiness data,the key problem to be solved is how to rapidly analyze,process,store and mine data so as to realize swift abstraction of useful data and serve for business decision-making of internet of things.Therefore,mass data mining system for internet of things was designed based on association rules Apriori algorithm in this paper.
Key words:Apriori algorithm;Hadooop platform;Internet of Things;cloud calculation;data mining
0前言
物联网在互联网基础上技术与功能获得了不断的升级,实现了用户对信息的传感、收集与感知。但利用物联网进行信息交换与通信的过程中会产生海量的数据(如RFID数据流、传感器网络数据等),这些数据不断的增多加大了用户从中获取有用信息的难度。为了提高物联网的数据处理功能,相关研究人员结合应用云计算、数据挖掘技术,构建百万计算机集群的云模式,以丰富物联网的弹性可扩展技术、分布式计算技术与存储机制,增强物联网的可信计算功能,利于物联网在面对海量业务数据时能够快速进行分析、处理、存储、挖掘,进而实现有价值信息的快速提取以服务于物联网商业决策。物联网海量数据挖掘仍是研究热点,本文将结合数据挖掘技术中的关联规则Apriori算法、云计算技术、PML来探究与设计物联网海量数据挖掘系统。
1数据挖掘
1.1 物联网海量数据的特点
物联网在应用过程中会产生海量的数据,经研究可总结出这些海量数据的4大特点:①数据量大。传感设备是每一物联网系统中的基本设备,所占数量高达成千上万以上,其功能是向数据中心传输已采集到的数据。为满足对象的状态跟踪、数据统计分析、数据挖掘,数据中心保存大量历史数据与接收当前采集的数据,海量的数据增加了物联网数据中心的负荷。②数据类型复杂。由于物联网系统的监控对象涉及种类众多,且不同种类的监控对象所采集信息也不尽相同,决定了物联网系统数据类型(如文本、图像、视频等)的复杂性。③数据的异构性。GPS传感终端、RFID传感终端等多种传感终端都是构成物联网系统的组成部分,而传感终端的不同决定了终端所采集数据的语义、格式各不相同,产生了物联网系统数据的异构性,这在一定程度上加大了数据存储、挖掘的难度。④数据的高度动态性。在物联网系统中拥有大量的传感终端与传感节点,不同的传感终端在系统中的每一时刻或被添加或被移除,所以,物联网系统数据库中如果要增加传感节点存储采集到的数据,一旦传感节点被移除,存储在系统数据库中的数据将没有保留记录,因此,频繁动态变化的传感节点使得物联网系统中的数据呈现出高度动态性特点。
1.2 物联网海量数据挖掘
RFID信息数据是研究物联网海量数据挖掘问题的主要对象,结合数据挖掘技术可从该研究对象中挖掘出潜在、有价值的信息。RFID传感器可采集到EPC(标签的标识码)、Location(阅读器读取标签的地点)、Time(阅读器读取标签的时间)的3个原始数据,这些数据的特征主要体现在海量性、分布式、时间与空间性、异构性、动态性、节点资源有限性,因而要想精确挖掘出物联网海量数据难度极大。在实际领域中,RFID数据流分析、频繁与序列模式分析、分类与聚类的路径分析等是RFID信息数据挖掘的主要内容,这些数据的挖掘对物联网商业决策具有重要意义。
2数据处理模式
2.1 处理海量数据的流程
处理物联网海量数据挖掘中的RFID动态异构数据,需要基于云计算技术与数据挖掘技术,以Hadoop为平台,利用Map/Reduce模式来实现数据挖掘处理。具体的操作流程包括:①过滤、转换、合并物联网中的RFID数据,以PML文件形式在分布式系统HDFS中保存。为解决高效存储、处理、节点失效的问题,可运用副本策略将PML文件的2~3个副本在同一机构的不同节点上保存,或在不同机构的某一节点上保存。②主控程序Master在执行任务中主要负责创建与管理控制的任务,空闲状态的Worker会得到相关分配任务且配合Map/Reduce进行操作处理,之后通过Master归并最终结果及向用户反馈结果。
2.2 计算和存储的整合及迁移
由于系统采用分布式数据存储方式,所以能够满足计算与存储的整合、迁移,这也是基于云计算、关联规则Apriori的物联网海量数据挖掘系统的一大特征。系统计算和存储的整合及迁移处理过程需要借助Map/Reduce模式,具体的实施策略是在本地计算机上进行操作,由于Map在每一节点上的操作都具有独立性且不存在数据传输,只是在Reduce过程中需要将计算结果传送给Master,利于实现计算和数据的同步密集及计算向存储的迁移,数据传输时间大大加快。同时,系统还结合应用PML文件副本策略,预防出现节点失效时DataNode节点会存有一个副本节点提供给Master,该副本节点会实现计算迁移(该过程中数据不会在DataNode节点间相互传递)并重新开启数据处理,如此不必重启全部的工作,数据传输效率大大提高。
具体的Map/Reduce操作过程如下:
①采用Map/Reduce思想,依据参数将输入文件分割成大小在16~64 M范围的M块;②执行程序主要包括主控程序Master、分工作机Worker,其中Map操作有M个,Reduce操作有R个,空闲Worker会接收到Master分配的Map或Reduce处理任务;③Worker在处理Map任务时会对处理数据进行读取,而后将
3数据挖掘系统的设计
3.1 系统结构
图1是基于关联规则Apriori算法与云计算的物联网海量数据挖掘系统的基本结构。
整个系统主要包括数据存储层、数据挖掘算法层、挖掘任务处理层。系统的主控节点是Master,任务是交互用户、调度与管理整个系统节点。系统Map/Reduce化的数据挖掘算法被存储在一部分的节点中,利于实现挖掘的高效性。在HDFS分布式存储系统中,主要由1个NameNode主节点、若干DataNode构成,其中NameNode负责接收用户的请求,同时向用户返回存储数据的DataNode的IP,并向其它接收副本的DataNode发送通知。
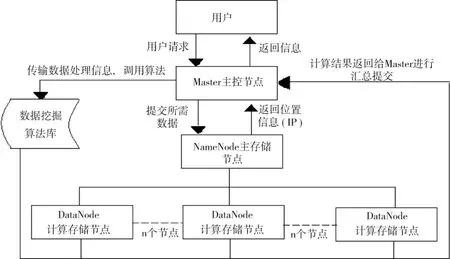
图1 系统基本结构
3.2 数据挖掘算法层
数据挖掘中的常用算法都进行了Map/Reduce化,本文中分布式并行的关联规则算法就是将Apriori算法进行Map/Reduce化获得的,这些常用算法都集成在系统数据挖掘算法层的算法节点中。在实际使用过程中借助了云计算平台,利用Master主控节点来进行控制与管理,根据客户需求向相关节点传送算法来计算。
3.3 挖掘任务处理层
挖掘任务处理层相当于任务调度层,是系统的核心层次,Master可调度系统中所有的挖掘器。具体的挖掘任务处理流程:①将空闲的DataNode节点利用Master找出,并将其放置在空闲节点列表中;②用户请求由Master来接收,并获取DataNode各个数据块中的存储信息、挖掘调用算法;③由Master向算法存储节点申请需要的挖掘算法,而后通过挖掘算法存储节点将所需算法传送给DataNode(原始数据)节点;④在HDFS服务器中根据计算任务启动工作,将工作完成结果传送给Master,经过汇总Master会生成最终结果并反馈给用户,该过程因不必进行数据重组与传送,所以系统每一节点的计算和存储的文件传输效率大大提高。
4基于关联规则Apriori的数据挖掘算法
尽管数据挖掘算法分类众多,但在物联网数据挖掘中最有效的还是关联规则的Apriori算法。Apriori算法运用逐层搜索迭代方式来通过K项集进行(K+1)项集的探索,首先需对数据集进行一次扫描,进而生成频繁1-项集L1,之后利用L1进行频繁项集L2的探索,以不断迭代的方式持续到频繁项集为空集。由于频繁项集具有任一子集都为频繁项集的特性来压缩处理搜索空间,以此加快频繁项集的生成效率。在经历了第K次循环搜索后,数据挖掘的具体过程:①操作JOIN(连接),令Lk-1产生候选集CK并进行连接操作;②按照Apriori性质来完成支持度统计与剪枝的操作,令CK产生频繁集LK。这种算法的不足之处是需要多次扫描数据库才可探索出所有的频繁项集,显然具有海量数据的物联网应用并不适合这一算法,多次扫描会耗损大量内存及时间。因此,本文借鉴云计算平台的分布式并行计算性质,将该性质移植在Apriori算法上,建立Hadoop架构以存储扫描数据库,查找频繁项集所获得的并联规则,扫描处理将在各个DataNode节点中并行操作,由此获得各计算节点上的局部频繁项集。之后,利用Master将实际的全局的支持度、频繁项集统计与确定出来,以此来节省系统的时间与内存消耗,实现数据挖掘效率的大大提高。
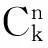
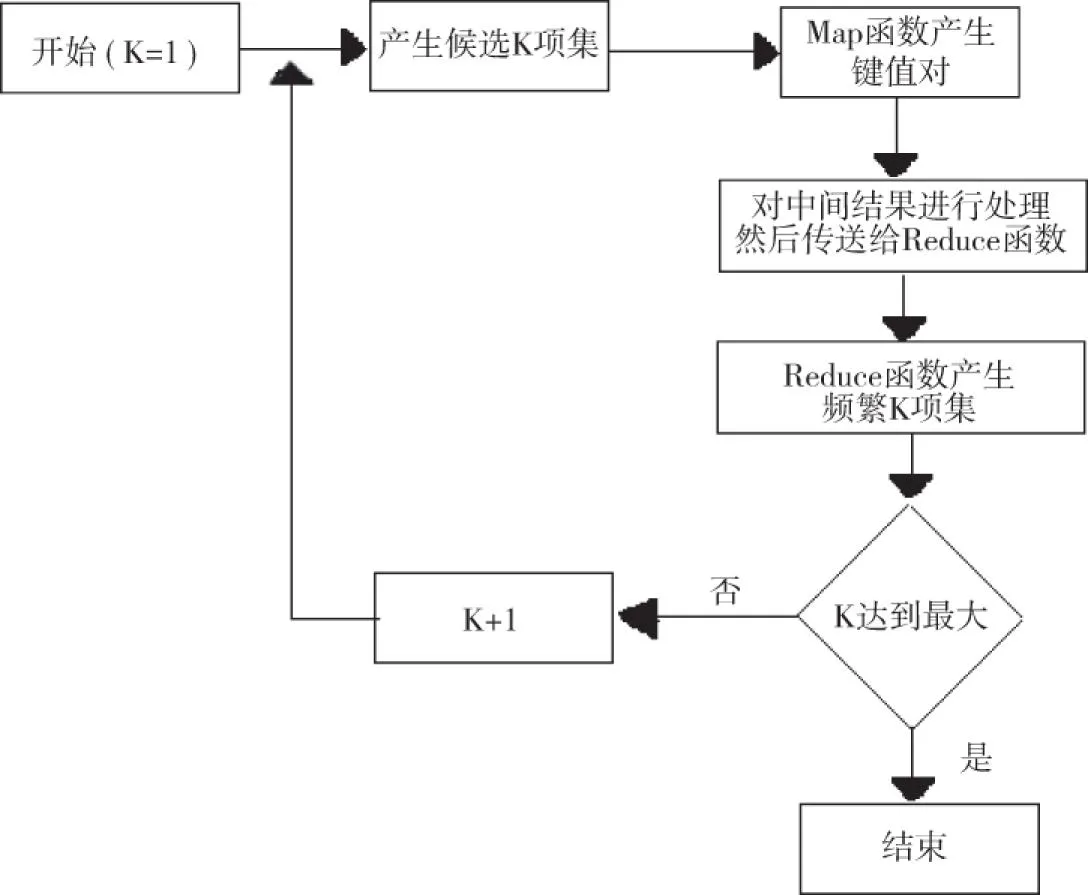
图2 Map/Reduce 化的Apriori挖掘算法实现流程
5结语
针对数据挖掘在物联网应用的重要性及物联网海量数据挖掘的问题,本文基于关联规则Apriori算法与云计算技术来研究与设计物联网海量数据挖掘系统。同时,结合物联网数据的特点,在数据挖掘技术与云计算技术的支持下提出了物联网海量数据挖掘的算法,实现了物联网海量数据挖掘系统的设计,有效解决了物联网海量数据挖掘问题。
参考文献:
[1]刘茂华,史文崇.物联网数据处理之浅论.计算机与信息技术,2011,(06):52-53.
[2]丁静,杨善林,罗贺,等.云计算环境下的数据挖掘服务模式.计算机科学,2012,(S1):217-219+237.
[3]张海江,赵建民,朱信忠,等.基于云计算的物联网数据挖掘.微型电脑应用,2012,(06):10-13.
[4]赵又霖,邓仲华,陆颖隽.数据挖掘云服务分析研究.情报理论与实践,2012,(09):33-36+44.
[5]何清.物联网与数据挖掘云服务.智能系统学报,2012,(03):189-194.
[6]陈磊,王鹏,董静宜,等.基于云计算架构的分布式数据挖掘研究.成都信息工程学院学报,2010,(06):577-579.
[7]范玉,王鑫,张清辰.基于云计算的物联网数据挖掘模型.电脑与信息技术,2012,(06):49-52.
[8]曹聪.云计算支持下的数据挖掘算法及其应用.广州:广州大学,2012.
[责任编辑:郑秀亮英文编辑:刘彦哲]
猜你喜欢
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
电子技术与软件工程(2016年20期)2016-12-21
中国市场(2016年36期)2016-10-19
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
大学教育(2016年9期)2016-10-09
科技视界(2016年20期)2016-09-29
环球时报(2016-08-01)2016-08-01
