
SaaS环境下基于服务质量的资源分配算法
2015-12-23 00:55:20张志超
计算机工程与设计 2015年8期
张志超,彭 蓉+,黄 华,2
(1.武汉大学 计算机学院 软件工程国家重点实验室,湖北 武汉430072;2.景德镇陶瓷学院 信息工程学院,江西 景德333001)
0 引 言
在云计算环境下,面对的一个重要问题是:需要设计有效的资源分配算法,以保证租户的服务质量,并最小化底层资源的使用。大量研究试图提供云服务在质量上的保障。文献 [1]通过虚拟机复用进行有效的资源管理;文献[2]根据任务的紧张程度,基于SLA 来为任务提取资源;文献 [3]通过应用加载分析来动态的提取底层资源,以满足SLA;文献 [4,5]通过在线资源需求预测来提取底层资源。SaaS提供商,如Compiere ERP[6],为每个租户维护一个虚拟机,并在租户请求拥堵时,实时添加应用实例,是保证租户服务质量的一种基本做法,但由于为每个租户提供单独的虚拟机,大多数租户都会有一个没有完全使用的虚拟机,造成底层资源低效使用,增加了底层资源成本。文献 [7]提出通过多租户技术,以一个虚拟机应用实例来为多个租户服务来节省资源。不过,多租户共用虚拟机的方式会更容易受到租户请求变化的影响,如不能及时提取足够的资源,则会造成大量的SLA 违背及赔偿。
在本文提出的算法中,利用SaaS服务的多租户特性,采用多个租户共用虚拟机的方式以节省底层资源。本文采用协调虚拟机处理增长的租户请求,根据协调虚拟机的使用情况,以提取适当的虚拟机资源。采用协调虚拟机机制,可以更精确更及时地提取适当底层资源,以保证租户的服务质量。在租户请求减少时,本文则采用慢收缩策略来防止租户请求量反弹。通过模拟实验验证了算法的有效性。
1 SaaS服务模型
云计算主要可以分为底层架构即服务 (IaaS)、平台即服务 (PaaS)和软件即服务 (SaaS)。在云计算中的SaaS模型如图1所示[7]。SaaS层管理SaaS提供商提供给租户的所有服务的应用。PaaS层包含映射和调度政策,以将租户的服务质量需求转换为底层架构参数,并分配虚拟机以处理租户的服务请求。IaaS层控制虚拟机的实际的初始化和销毁。IaaS层,如Amazon EC2service[8],提供多种类型的虚拟机,其处理能力、内存及I/O 性能均不一样,客户可以购买所需要的虚拟机实例,并按实际使用收费。这样,SaaS应用可以按实际需求,动态提取所需要的底层资源。
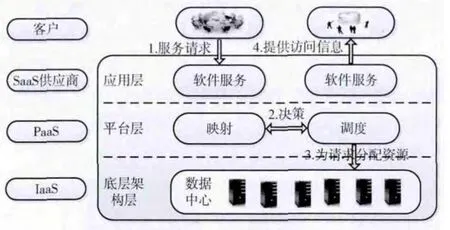
图1 SaaS服务的系统模型
在SaaS服务模型下,PaaS平台为SaaS服务提供底层资源运行环境,并对SaaS服务对应的底层资源进行监控和管理。当租户请求到来时,PaaS平台获取租户请求信息,将请求发送到SaaS服务对应的底层资源,使租户请求得到服务。当租户请求增长,现有的底层资源已不能处理租户请求时,PaaS平台则需要为SaaS服务提取新的底层资源。由于IaaS层创建新的虚拟机,并部署相应的应用实例是需要时间的,为了能提取恰当的资源,在PaaS平台的资源分配算法中,需要一些值记录IaaS层正在为SaaS服务提取的底层资源。当IaaS层为SaaS服务创建的底层资源已经生成时,PaaS平台则对SaaS服务与底层资源的映射关系及这些状态值进行更新。同时,根据SaaS服务的底层资源使用状态,PaaS平台需要定期对底层资源进行更新,当租户请求减少时,及时释放底层资源,以节省成本。
一般而言,SaaS环境下的资源分配算法包括3个部分。一是在租户请求到来时,对租户请求的处理。在该算法中,当现有的资源不能处理租户请求时,则需要提取新的底层资源。二是定期的对底层资源进行更新。对底层资源的定期更新,是为了在租户请求减少时,及时的释放底层资源,以节省成本。三是当IaaS层生成了需要提取的新的虚拟机时,PaaS层对SaaS服务映射的底层资源及记录正在生成的虚拟机的记录值进行更新。
SaaS提供商与租户需要签订SLA 协议,以保证SaaS服务质量,并对违背SLA 做出赔偿。响应时间是SaaS 服务质量好坏的一个重要标准。SLA 协议往往需要规定请求响应时间上限,并保证在租户请求中响应时间超出SLA 响应时间上限的请求量低于某个概率值,如5%,当SLA 违背的请求量超出该概率值时,对超出的请求做出一定的赔偿。故SaaS环境下的资源提取算法,需要最小化SLA 违背,并最小化SaaS提供商的底层资源成本。
2 资源分配算法
记云平台生成新的虚拟机应用实例的时间为T,SLA规定的响应时间上限为tr。
在SaaS服务模型下,为了使得被处理的租户请求都能在tr内得到服务,需要根据虚拟机的处理能力及虚拟机现有的待处理请求数量,对租户请求作请求处理时间预测。虚拟机的处理能力可通过压力测试获得。一个请求到来时,当虚拟机可以在tr内处理该请求时,则将该请求发送到该虚拟机。当SaaS服务现有的虚拟机资源都不能保证在tr内处理该请求时,则放弃当前请求 (此时是SLA 违背),并令IaaS层生成新的虚拟机应用实例,以适应租户请求的增长。
在现实的SaaS环境下,租户请求的到来是随机离散事件,在模拟环境下,为了方便观察租户请求量变化对底层资源的影响,我们以一个固定时间为间隔来发送租户请求。记请求发送间隔为ts,并设置ts=tr。即以tr为间隔来发送请求,并在每个请求发送间隔结束时,对虚拟机进行更新。由于预测处理时间超出tr的请求被放弃,本文假定请求处理时间预测是有效的,则在tr时间后虚拟机资源就会完全恢复处理能力。若ts<tr,每次请求发送时,底层资源要以部分处理能力来处理上一次未处理完的请求,而只能以剩余处理能力来处理该次发送的请求,则此时间段放弃的请求量不能真实的反映该时间段内请求量变化对底层资源的影响。若ts>tr,则底层资源在每次请求发送间隔的 [tr,ts]时间内处于闲置状态。故设置ts=tr时,可以更好的观察请求变化量对底层资源的影响。
一个SaaS应用可以有多个版本,如标准版、专业版和企业版等。以下讨论均指部署为同一个版本的SaaS应用,并且SaaS提供商对该版本的SaaS应用只使用同种类型的虚拟机,即下文所说的所有虚拟机都有相同的处理能力、内存及I/O 性能等。
如引言所述,Compiere ERP[6]为每个租户维护单独的虚拟机,并在租户请求拥堵时,可以为各个租户生成新的虚拟机应用实例,以保证服务质量。本文把Compiere ERP的资源分配算法作为一个基本的算法进行介绍。然后描述了本文提出的基于服务质量的资源分配算法。
2.1 基本算法
我们用BaseAlg来表示基本算法。在该算法中,为各个租户都分别维护了专用虚拟机列表。数组tenantVmCreating[N](N 表示租户的数量)表示各个租户是否有新的专用虚拟机正在生成中。各个租户的请求,都只使用该租户的专用虚拟机来处理,当专用虚拟机不能在tr时间内处理时,则为该租户生成一个新的专用虚拟机。
算法初始时,每个租户的专用虚拟机列表都只有一个虚拟机,数组tenantVmCreating 中的各个元素都为0。当一个租户请求c到来时,对请求处理的算法BaseAlg_RequestSolve如下:

在每个请求发送间隔结束时,对虚拟机更新的算法BaseAlg_VmsUpdate如下:


当IaaS层生成了新的虚拟机时,需要对记录虚拟机生成状态的状态值tenantVmCreating 进行更新,并将虚拟机加入到对应租户的专用虚拟机列表中。其算法BaseAlg_VmsCreated如下:

BaseAlg算法的虚拟机如图2所示。这一算法为各个租户提供单独的虚拟机,并且能在租户请求增长时,生成新的虚拟机,以处理增长的租户请求。不过,在该算法中,首先,为每个租户提供单独的虚拟机,大多数租户都会有一个没有完全使用的虚拟机,故会造成虚拟机的低效使用,增加了底层资源成本;其次,当租户请求量增长,需要生成新的虚拟机应用实例来处理租户请求时,在生成新的虚拟机应用实例期间,会造成SLA 违背,即不能及时响应租户请求的增长。

图2 BaseAlg算法的虚拟机
2.2 基于服务质量的资源分配算法
我们用QoSBasedAlg来表示本文提出的基于服务质量的资源分配算法。SaaS服务可分为四级成熟度模型[9]。在第四级SaaS成熟度模型下,SaaS服务有规模可伸缩,可定制和多租户效应。通过多租户和定制技术,一个SaaS服务实例可以为多个租户服务。在QoSBasedAlg算法中,在多个租户共用虚拟机应用实例的基础上,将虚拟机分成了两类:公用虚拟机和协调虚拟机,以实现在保障租户的服务质量的基础上,最小化底层资源的成本。本小节首先对虚拟机分类进行介绍,然后对算法进行描述。
2.2.1 虚拟机分类
在算法中,将虚拟机分为两类:公用虚拟机和协调虚拟机。
公用虚拟机:是所有租户都可以使用的虚拟机。与基本算法相比,其优势在于可以减少非满负荷运行的虚拟机,从而减少对虚拟机资源的占用。
协调虚拟机:当公用虚拟机已满时,则使用协调虚拟机来处理租户请求。协调虚拟机开始使用,则需要生成新的公用虚拟机,以应对租户请求的增长。有多少个协调虚拟机在使用,则需要生成多少个公用虚拟机。
QoSBasedAlg算法的虚拟机如图3所示。QoSBasedAlg算法使用多租户共用虚拟机的方式来处理所有租户的请求,可以高效的使用虚拟机,节省底层资源。不过,多租户共用虚拟机的方式会更容易受到租户请求变化的影响。当租户请求增长时,如不能及时的提取足够的资源,则会造成大量的SLA 违背。故本文提出了协调虚拟机来处理增长的租户请求,并根据协调虚拟机的使用数量来确定所需要提取的底层资源数量。协调虚拟机机制可以减少及避免租户请求增长时,生成新的虚拟机期间的SLA 违背。
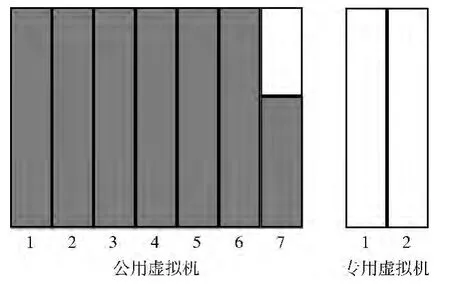
图3 QoSBasedAlg算法的虚拟机
记租户的数量为N,初始时,各个租户的请求发送量为ri(i=1,2,…N),公用虚拟机数量的初始值J 则要求其总的处理能力不小于初始时总的租户请求量。记虚拟机在响应时间tr内的最大并发处理能力为M。故J 的值为式(1)所示

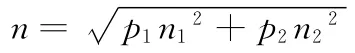

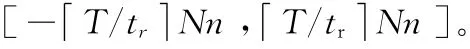
2.2.2 算法描述
在QoSBasedAlg算法中,用pubVmCrtCnt来记录正在生成的公用虚拟机的数量。
算法初始值如下:pubVmCrtCnt的值为0,公用虚拟机的数量按式 (1)来确定,协调虚拟机的数量按式 (2)来确定。
当一个租户请求c到来时,对租户请求处理的流程如图4所示。对租户请求进行处理的算法QoSBasedAlg_RequestSolve描述如算法4所示。
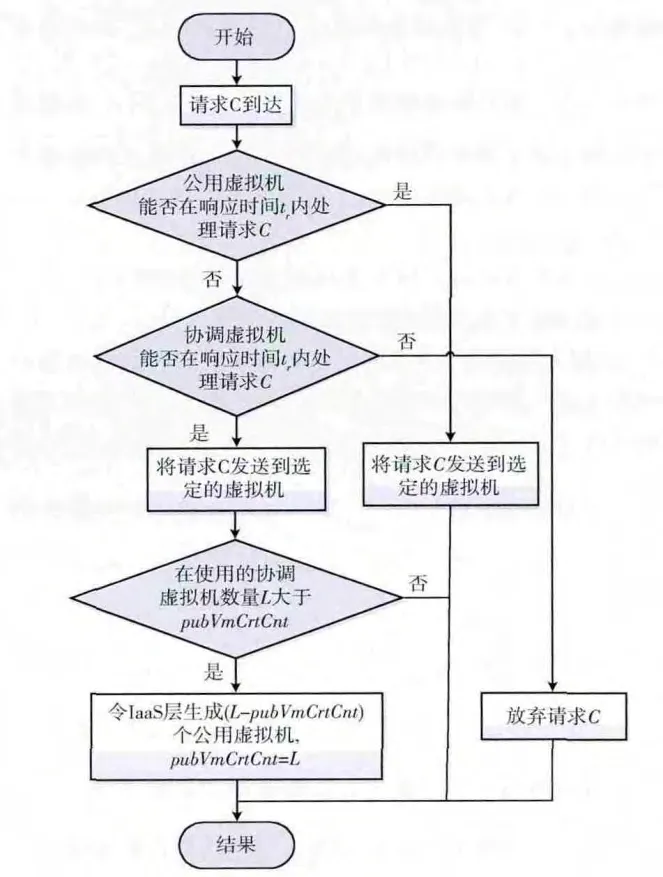
图4 请求处理流程


多租户共用虚拟机的方式会更容易受到租户请求变化的影响。在某个时刻租户请求量减少之后,在下一个时刻有可能会增加。如果在租户请求量减少时,立刻释放空的公用虚拟机,在下一个时刻租户请求量增加时,又需要生成新的公用虚拟机,这无疑会增加SLA 违背的可能性,并影响算法的健壮性。为了防止租户请求量减少了之后再反弹,对虚拟机更新则采用了慢收缩策略,即对所有空闲的公用虚拟机采用超时销毁政策。每个请求发送间隔结束时,对虚拟机更新的算法QoSBasedAlg_VmsUpdate如下:

新的虚拟机生成时的算法QoSBasedAlg_VmsCreated如下:

3 性能评估
本文通过模拟实验来评估QoSBasedAlg 算法的性能。在实验中,本文使用CloudSim[11]来模拟在SaaS环境下的资源分配算法。如上节所述,本文假定SaaS提供商只使用同一种类型的虚拟机,则BaseAlg算法和QoSBasedAlg算法中的所有虚拟机都有相同的处理能力、内存及I/O 性能。在实际情况下,为确定虚拟机在SLA 响应时间上限内的最大处理能力,需要考虑不同请求类型及其比例。本文的主要目的是验证QoSBasedAlg算法的有效性,为简单起见,本文只考虑所有请求都为同一种类型的情况。在性能评估中,主要以SLA违背量、SLA 违背率以及底层资源的使用数量作为评估标准,并在不同的实验环境参数下,对BaseAlg算法和QoSBasedAlg算法的实验结果进行比较分析。
3.1 性能测试
实验环境的主要配置参数如下:数据中心的每个主机包含4 核处理器,16GB 的RAM,每个核的处理能力为1000mips。每个虚拟机的处理能力为250 mips,1GB 的RAM。每个服务请求需要处理15 million条指令。响应时间tr为6s。租户请求发送间隔tr为6s。QoSBasedAlg算法中空虚拟机保留时间为31s。在模拟环境下,测试得:在6s的响应时间内,SaaS服务的最大并发处理能力M 为99个请求。每个租户的初始请求量ri(i=1,2,…N)都为50个请求。在实验中,本文分别在不同请求变化量、不同虚拟机生成时间、不同的租户数量的实验条件下,对比BaseAlg算法和QoSBasedAlg 算法的底层资源使用量与SLA 违背量及SLA 违背率。
为了保证可比性,首先对QoSBasedAlg进行实验,在实验中记录每个租户每次发送的请求数量。然后在BaseAlg实验中,按照QoSBasedAlg中记录的每个租户每次的请求发送量,来发送租户请求。
在下面的每个实验条件下,对每个实验都重复5 次,每次实验的实验时间为半个小时。在每次实验中,取平均虚拟机使用量作为底层资源 (虚拟机)使用量的衡量标准,即各个请求发送间隔内的虚拟机使用量的总和与请求发送间隔总数量之比;SLA 违背量则取每次实验中放弃的请求的总数量;SLA 违背率取每次实验中放弃的总的请求量与总的请求发送量之比。每个实验条件下,虚拟机使用量、SLA 违背量及SLA 违背率都取5次实验的平均值作为最终的评估标准。
3.1.1 不同请求变化量对实验的影响
在实验下,主要看不同的租户请求变化量对实验的影响。设置租户数量N 为200,虚拟机生成时间T 为40s。请求变化量分别设置为n=4、8、12、16、20 时,对比BaseAlg与QoSBasedAlg算法。初始时,在BaseAlg实验中有200个专用虚拟机。初始时在各个实验中都有,ri=50(i=1,2,…N),M =99,N =200,由式 (1)得QoSBasedAlg的公用虚拟机J 都为102;当n=4 时,T=40,N=200,M=99,tr=6s,代入式 (2)计算得协调虚拟机数量K 为3。类似地,当n 分别为8、12、16、20 时由式(2)可计算得协调虚拟机的数量K 分别为5、7、9、11。实验结果见表1。
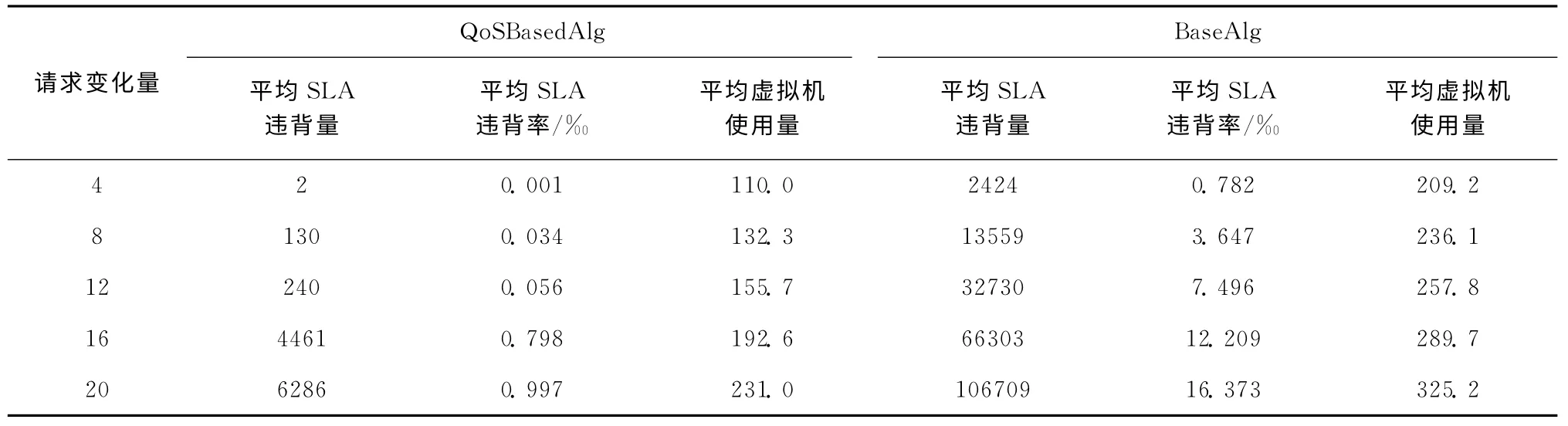
表1 不同请求变化量下的实验结果对比
从实验结果中可以得出,在不同的请求变化量条件下, QoSBasedAlg算法都比BaseAlg有更少的SLA 违背及底层资源的使用量,并且QoSBasedAlg算法在各次实验中的SLA违背率低于1%。同时,QoSBasedAlg算法的SLA 违背量也随请求变化量的增长而增长。由2.2.1节的分析可知,当各个租户的请求变化量n更大时,在新的虚拟机生成期间,总的请求变化量Y 有更大的变化区间,故会有更多的SLA违背。
3.1.2 不同虚拟机生成时间对实验的影响
在实验下,主要看不同虚拟机生成时间对实验的影响。设置租户数量N 为200,请求变化量n 设置为12。虚拟机生成时间T 分别为20、30、40、50、60时,对比BaseAlg与QoSBasedAlg算法。初始时,在BaseAlg 实验中有200个专用虚拟机。初始时,由式 (1)得QoSBasedAlg的公用虚拟机数量J 都为102;由式 (2)计算得协调虚拟机数量K 分别为5、6、7、8、8。实验结果见表2。
从实验结果中可以得出,在不同的虚拟机生成时间条件下,QoSBasedAlg算法都比BaseAlg有更少的SLA 违背及底层资源的使用量,并且QoSBasedAlg算法在各次实验中的SLA 违背率低于1%。QoSBasedAlg算法的SLA 违背量受虚拟机生成时间变化的影响并不是很明显。
3.1.3 不同租户数量对实验的影响
在实验下,主要看不同租户数量对实验的影响。设置请求变化量n为12,虚拟机生成时间T 为40s。租户数量N 分别为50、100、200、300、400、500时,对比BaseAlg与QoSBasedAlg算法。初始时,在各次实验中,BaseAlg算法的专用虚拟机数量分别为50、100、200、300、400、500。初始时,在各次实验中,由式 (1)得QoSBasedAlg算法的公用虚拟机的数量J 分别为26、51、102、152、203、253;由式 (2)计算得协调虚拟机数量K 分别为4、5、7、9、10、11。实验结果见表3。
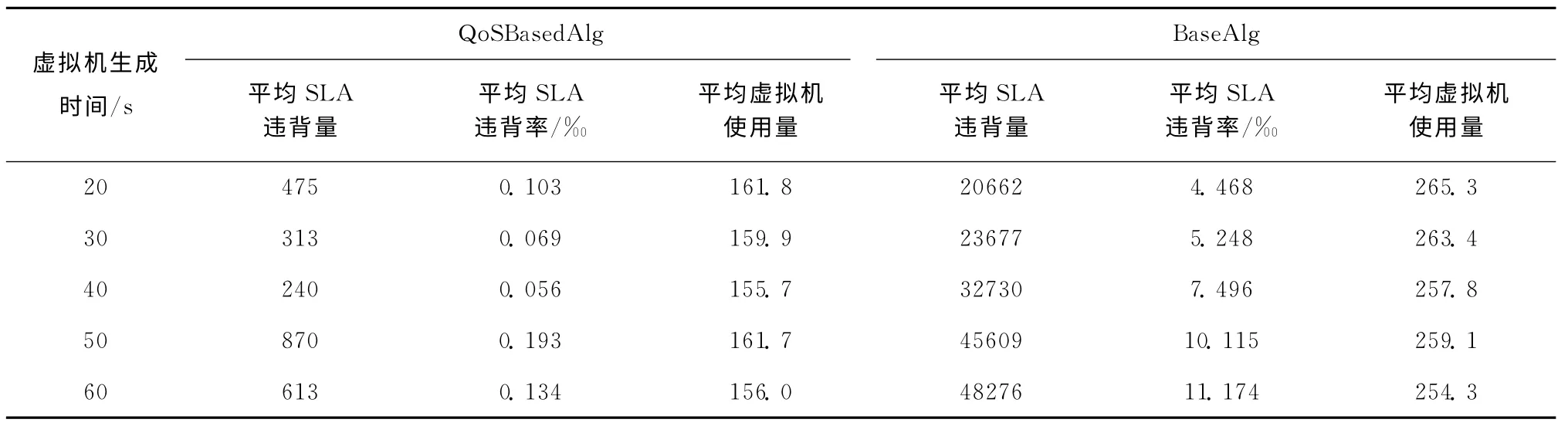
表2 不同虚拟机生成时间下的实验结果对比

表3 不同租户数量下的实验结果对比
从实验结果中可以得出,在不同租户数量条件下,QoSBasedAlg算法都比BaseAlg有更少的SLA 违背及底层资源的使用量,并且QoSBasedAlg 算法在各次实验中的SLA 违背率低于1%。同时,QoSBasedAlg算法的SLA 违背量也随请求变化量的增长而增长。由2.2.1 节的分析可知,当租户数量N 更大时,在新的虚拟机生成期间,总的请求变化量Y 有更大的变化区间,故会有更多的SLA违背。
3.2 实验分析及算法改进
从实验结果中可以得出,与BaseAlg算法相比,QoSBasedAlg算法使用更少的底层资源,达到了更少的SLA 违背。并且在每一次实验中,QoSBasedAlg算法的SLA 违背率都低于1%,各个实验条件下,其平均SLA 违背率甚至都低于1‰。实验结果表明,在QoSBasedAlg 算法中,使用多租户共用虚拟机的方式可以有效地节省底层资源,协调虚拟机机制和慢收缩策略可以有效地减少SLA 违背及改进服务质量。
通过实验可以得到,在请求变化量更大、虚拟机生成时间更长、租户数量更多时,QoSBasedAlg算法也趋向于产生更多的SLA 违背。一方面,由于实际的租户请求量不可能为负数,故在每次请求发送时,对于请求量r 小于n的租户,则在下一次请求发送时,这些租户的实际请求发送量只能在 [-r,n]之间变化,而不是在 [-n,n]之间随机变化。因此在实验中,每次发送租户请求时,总的租户请求发送量往往呈现增长的趋势。从实验结果来看,QoSBasedAlg算法这种请求增长趋势具有一定的适应能力。另一方面,虽然在协调虚拟机数量满足式 (2)的条件下,Y 的数量超出协调虚拟机处理能力的概率为0.82%,但仍然有可能会超出协调虚拟机处理能力。当请求变化量更大、虚拟机生成时间更长、租户数量更多时,在虚拟机生成时间内总的租户请求变化量Y 有更大的变化区间,超出协调虚拟机处理能力的请求量会更大,故SLA 违背量也更大。
需要指出的是,QoSBasedAlg算法的核心就是确定协调虚拟机的数量,因为它决定着是否能及时提取恰好足够的资源来为租户服务。如果协调虚拟机的数量相对不足,而实际的租户请求变化量较极端的情况下,仍然会有可能出现SLA 违背率超出SLA 违背赔偿率的情况。
为了能更好的提高服务质量,QoSBasedAlg算法可以在以下方面做进一步改进。
对协调虚拟机的数量设置有两种改进方法。一种是静态的措施,即增加协调虚拟机的数量,使得在虚拟机生成时间内总的租户请求变化量Y 落在协调虚拟机处理能力之内的概率更大,由标准正态分布表可知Φ(3.0)=0.99865,可令协调虚拟机数量K 满足式 (3)
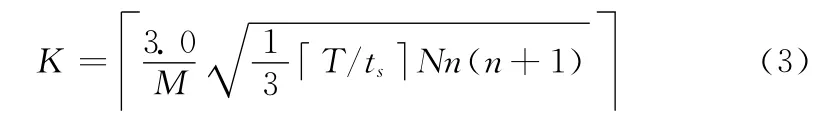
另外一种改进的方法是动态的措施,即在协调虚拟机数量满足式 (2)或Y 落在协调虚拟机处理能力之内的概率较大的条件下,如果在单位时间 (如一个小时)内放弃的请求量超出M 的h 倍 (h>0)时,则生成一个新的协调虚拟机。在动态的方案中,并不是不允许有SLA 违背,而是将SLA 违背控制在一定的范围内。因为从正态分布的特点来看,Y 的值很大的可能性很小,要使得Y 完全在协调虚拟机的处理能力之内的话,需要很多协调虚拟机,而大部分协调虚拟机往往大多数时间都处于闲置状态,同样也会造成资源的低效使用,而增加了成本。动态的改进方案比静态的改进方案有更好的适用性。
对慢收缩策略也可以进行改进。在实验中可以看到,仍然有公用虚拟机刚刚销毁,又需要生成新的公用虚拟机的情况出现。一种改进的策略是,在对虚拟机更新时,如果有空的公用虚拟机,则无条件的保留一定数量的空的公用虚拟机,记无条件保留的空公用虚拟机数量为G,而对超出G 的空公用虚拟机采用超时销毁政策。G 的值可设置为,单次请求发送时的总的租户请求变化量X 以较大概率落在G 个虚拟机的处理能力之内。由2.2.1 节可知,X ~N(Nμ,Nσ2),又由μ =0,σ2=n(n+1),故有X ~N(0Nn(n+1))。由标准正态分布表可知Φ(2.0)=0.97725,可取G 的值满足式 (4)
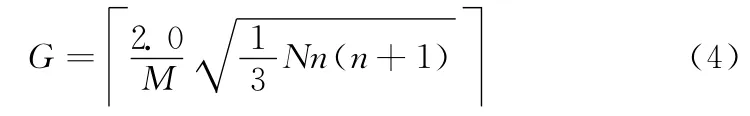
本文主要是针对各个租户请求变化量在 [-n,n]之间的随机变化的情况进行了分析验证。实际的SaaS服务的各个租户的请求变化量可能有各自的特点,并不一定服从[-n,n]之间的随机分布。要推断租户的请求变化规律,以确定协调虚拟机的数量,并不是一件容易的事。此时,则可以使用动态的协调虚拟机生成方案,根据单位时间内的SLA 违背量,动态的生成协调虚拟机,以控制单位时间内的SLA 违背量低于预期值,进而保证SLA 违背率低于SLA 违背赔偿率。
4 结束语
本文提出的资源分配算法,利用SaaS应用的多租户特性,在各个租户共用虚拟机资源的基础上,将虚拟机分为两类:公用虚拟机和协调虚拟机。通过公用虚拟机为多个租户服务,以节省底层资源;通过协调虚拟机来处理增长的租户请求,并根据其使用状态来提取适当的资源。本文采用慢收缩策略以防止租户请求量减少之后再反弹。对照实验结果表明,本文提出的资源分配算法可以最小化SLA违背及底层资源使用量。根据实验结果,对算法提出了进一步控制SLA 违背并改进服务质量的方法。
[1]Meng X,Isci C,Kephart J,et al.Efficient resource provisioning in compute clouds via VM multiplexing [C]//ACM International Conference on Autonomic Computing,2010:11-20.
[2]Das A K,Adhikary T,Hong C S.An intelligent approach for virtual machine and QoS provisioning in cloud computing[C]//International Conference on Information Networking,2013:462-467.
[3]Calheiros R N,Ranjan R,Buyya R.Virtual machine provisioning based on analytical performance and QoS in cloud computing environments [C]//International Conference on Parallel Processing,2011:295-304.
[4]Gong Zhenhuan,Gu Xiaohui,Wilkes John.Press:Predictive elastic resource scaling for cloud systems [C]//International Conference on Network and Service Management,2010:9-16.
[5]Shen Zhiming,Subbiah Sethuraman,Gu Xiaohui,et al.Cloudscale:Elastic resource scaling for multi-tenant cloud systems[C]//The ACM Symposium on Cloud Computing,2011.
[6]Compiere.Compiere ERP on cloud [EB/OL].[2014-03-10].http://www.compiere.com/.
[7]Wu L,Garg S,Buyya R.Sla-based resource allocation for software as a service provider(SaaS)in cloud computing environments [C]//IEEE/ACM International Symposium on Cluster,Cloud,and Grid Computing,2011:195-204.
[8]Amazon EC2.Amazon elastic compute cloud [EB/OL].[2014-03-10].http://aws.amazon.com/ec2/.
[9]Kang Seungseok,Myung Jaeseok,Yeon Jongheum,et al.A general maturity model and reference architechture for SaaS service [G].LNCS 5982:Database Systems for Advanced Applications,2010:337-346.
[10]SHENG Zhou,XIE Shiqian,PAN Chengyi,et al.Probability and mathematical statistics [M].4th ed.Beijing:Higher Education Press,2008(in Chinese). [盛骤,谢式千,潘承毅,等.概率论与数理统计[M].4版.北京:高等教育出版社,2008.]
[11]Calheiros Rodrigo N,Ranjan Rajiv,Beloglazov Anton,et al.CloudSim:A toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms[J].Software:Practice and Experience,2011,41(1):23-50.
猜你喜欢
军民两用技术与产品(2022年2期)2022-06-01 06:29:44
当代陕西(2019年6期)2019-04-17 05:04:08
电子制作(2017年17期)2017-12-18 06:40:45
计算机与数字工程(2016年11期)2016-12-13 06:51:06
中国卫生(2016年5期)2016-11-12 13:25:50
特别文摘(2014年17期)2014-09-18 01:31:21
清风(2014年10期)2014-09-08 13:11:04
小说林(2014年5期)2014-02-28 19:51:47
西安工程大学学报(2014年2期)2014-02-28 18:02:52
电子设计工程(2014年18期)2014-02-27 12:00:11
