
基于依赖结构的功能测试集排序方法
2015-12-23 01:01:20曹丽娜高建华
计算机工程与设计 2015年5期
曹丽娜,高建华
(上海师范大学 计算机科学与工程系,上海200234)
0 引 言
软件测试在软件开发和维护的各个阶段至关重要。为了提高软件质量的可靠性,利用测试用例排序技术在有限的资源内及时发现、纠正程序中的错误和缺陷的特点,以达到提高软件测试的实用效率,节约成本的目的。
为了充分提高软件测试的有效性,节约成本。王丹等[1]提出了利用控制依赖控制路径覆盖的Fuzzing模型,分析提取的脆弱性语句;陈树蜂等[2]通过分析UML 类图中的各种静态关系,提出一种基于UML 类图的依赖性分析模型,来解决类之间复杂的依赖性问题;高雪娟等[3]利用UML顺序图为主要模型,结合有向图和顺序图,采用覆盖准则和深度优先搜索算法遍历;陈建勋等[4]分析对象关系图中类间依赖关系,利用边删除规则去除环路,最后运用有向无环图的拓扑序列排序;S.Haidry等[5]根据测试用例之间依赖结构,绘制出有向无环图,根据算法,得出最优的测试集。然而,这些技术却没有考虑下述问题:测试集中的测试用例之间存在功能依赖以及借助什么模型来描述这种依赖关系,并且当测试用例权值相等时怎么去排序。
针对此问题,借鉴上述思想,本文通过改进DSP技术的不足之处,总结出一种表示依赖结构的有向无环图,作为对测试集生成的约束,将测试用例的权值和代码覆盖率相结合根据改进的算法对测试集排序,从而得出最优的测试集,减少测试集的生成,并同时保证代码覆盖率。
1 背景及相关知识
1.1 功能依赖
功能依赖是指在测试场景中,一些交互或需求必须要在其它一些交互或需求完成后才能执行。例如:交互或需求要在交互或需求I2之前执行,则称I2依赖于I1。测试用例之间固有地继承了这些关系,则相对应的测试用例t1,t2,即t2依赖于t1。
依赖结构可以用有向无环图 (directed acyclic graph)表示,即G= (V,E)其中:节点的有限集合V= {t1,t2,t3,t4....tn},边的集合E= {e1,e2,e3....em},E则表示是测试用例之间的功能依赖。依赖结构可以分成两类:开放的依赖结构,封闭的依赖结构。开放的依赖结构是指对于两个依赖的测试用例t1和t2,即在执行时t1在某些情况下要先于t2执行。封闭的依赖结构是指对于两个依赖的测试用例t1和t2,t1必须要在t2之前执行,如图1所示。
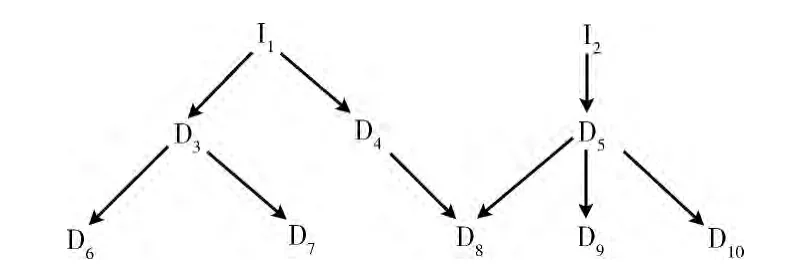
图1 一个有向无环图的例子
对于图1中的测试用例,若是开放依赖结构,则测试顺序是:I1-I2-D3-D4…。即I1已执行,那么D3和D4就处于开放状态,若再执行D3,I1不需再次执行,其好处在于减少不必要的冗余。若是封闭的依赖结构,则测试顺序是:I1-I2-I1-D3…,如I1已执行,接着执行I2,若接下来执行D3,那么其依赖结构I1就需再次执行。本文将重点介绍开放的依赖结构。
1.2 DAG 在测试集中的应用
DAG 是用来描述测试集内部测试用例之间功能依赖,若要想从测试集内部提取这些依赖性,就需要对一个系统的需求和设计有一定的了解,这样才能手动的绘制出DAG。通过分析DAG 图,我们可以找到各个测试用例之间的功能依赖,及复杂交互程度,进而根据算法求出权值,并依次确定各个测试用例的执行顺序[6]。
2 依赖结构的图覆盖范围值的测量标准
DSP是根据图覆盖范围值进行优化的,它是对一个测试用例相关性的复杂程度的一个度量,又因为开放的依赖结构和封闭的依赖结构中的测试用例的执行顺序的标准不同,所以对于它们必须设置不同的衡量标准[7]。
2.1 开放的依赖结构的标准
(1)一个测试用例的所有依赖关联的测试用例。其提高了密切相关的测试用例被更早执行的可能性。例如:图1中的I1的依赖关联测试用例是:D3,D6,D7,D4,D8。D3的依赖关联测试用例是:D6和D7。
(2)一个测试用例的直接或间接的最长路径。其提高了线性相关的测试用例被更早执行的可能性。例如,图1中的I1有三条路径,其长度是一样的,都是其最长路径。
2.2 封闭的依赖结构的标准
(1)在一条路径中没有被执行的测试用例的数量。
(2)在一条路径中没有被执行的测试用例的数量比上已经被执行的测试用例的数量。
(3)未被执行的测试用例除以这条路径的长度。
2.3 DSP依赖结构的弊端
S.Haidry验证了DSP 技术具有一定的优越性,但当DAG 测试用例的权值相等时可以有任意的排序,例如图2中的DAG,若按照S.Haidry 提出的方法进行排序有:t1-t2-t4-t6-t3-t5-t7或 者t1-t3-t5-t7-t2-t4-t6,计 算 两种路径的APFD 结果应该是相同的。若我们在考虑权值相同的排序时结合测试用例的代码覆盖率去排序,可以得到更优的排序结果。例如图2 括号中代表每个测试用例的代码覆盖率,可以算的以上两种排序的APFD 值分别为:APFD (t1-t2-t4-t6-t3-t5-t7)=62%。APFD (t1-t3-t5-t7-t2-t4-t6)=56%。

图2 含有代码覆盖率的有向无环图
3 DSP技术
3.1 开放依赖结构的优先级
根据开放依赖结构的图形覆盖范围值的衡量标准,文献中把优化测试用例的技术分成两种,分别是DSP_volume和DSP_height。
3.1.1 DSP_volume
DSP_volume测量标准给那些具有更多的依赖关联的测试用例更高的权值。这是因为在依赖结构中紧密相连的测试用例,在被测试的系统本身它们也是密切相关的,并且交互也更频繁。这样便能更早的发现更多的错误,最终提高错误检错率。为了计算一个测试用例的DSP_volume,需先计算出这个测试用例所有直接和间接的依赖关联测试用例。在本文中我们利用直接的传递闭包算法来实现。
算法1:直接的传递闭包算法
(1)根据系统的需求和设计得到DAG 图,如一个DAG 的例子如图3所示。
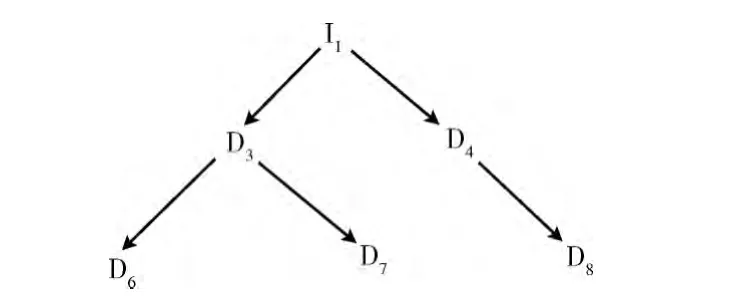
图3 一个有向无环图的例子
(2)根据图3得到其邻接矩阵[8]如图4所示。

图4 一个DAG 的邻接矩阵
(3)根据直接的传递闭包算法,得到布尔邻接矩阵,当D [i,j]=1 时,进行D[i,k]=D[i,k]∨D[j,k]运算,即把第i行和第j列进行 “或”运算之后再赋给第i行,结果如图5所示。
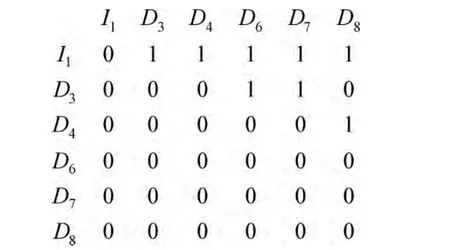
图5 一个布尔邻接矩阵
布尔邻接矩阵中每个测试用例所在行出现1的总次数,即为测试用例的权值。例如,对于测试用例I1的权值则为5,D3则为2。按照这些权值的大小就可以对测试用例进行排序以达到最优的排序结果。
3.1.2 DSP_height
DSP_height测量标准比较倾向于那些具有最长依赖关联的测试用例。这是因为具有更长依赖关联的测试用例有可能存在于更长的场景中。测试用例交互越紧密,测试场景则会包含更多的交互,就会有更高的复杂性。为了计算DSP_height,需算出一个测试用例所在的所有路径的长度,然后选取最长的路径作为衡量测试用例的权值。其是基于Floyd-Warshall shortest-path算法来实现。
我们根据DAG 的布尔邻接矩阵结合算法2进行运算。对于矩阵中的每一项进行D [i,k]+D [k,j]运算,然后再与D [i,j]做比较,得出最大值再赋给D [i,j]。即D [i,j]=max (D [i,j],D [i,k]+D [k,j])。经过Floyd-Warshall算法的思想,对每个测试用例进行遍历,算出其最长路径[9]。
算法2:Floyd-Warshall longest-path algorithm
输入:G:an n×n Boolean adjacency matrix representing direct dependencies between test cases.
输出:D:an n×n integer adjacency matrix representing the length of indirect dependencies between test cases.
(1)D:=copy of G
(2)for(k=1;k<=n;k++)do//k一定放在最外层,确保运行准确性,提高时间效率。
(3) for(i=1;i<=n;i++)do
(4) for(j=1;j<=n;j++)do
(5) D [i,j]:=max (D [i,j],D [i,k]+D [k,j])
(6) end for
(7) end for
(8)end for
(9)return D
按照代码来计算每个测试用例的权值,即每个测试用例所在行的最大值。
3.2 DSP关于测试集的排序
根据算法1或者算法2我们得到了每个测试用例的权值,进而根据依赖结构对测试集进行排序。这样在一个测试场景中的多个测试集便可以有优先的执行顺序,相对于任意的测试顺序,可以节约时间和提高工作效率。却忽略了当权值相等时怎么排序更好的问题。本文对文献中的测试集排序算法WEIGHTED_DSF 和算法WEIGHTED_DFS_VISIT进行了部分优化[10],得出了算法3:WEIGHTED_DSF_COVERAGE (WDC)和算法4:WEIGHTED_DFS_VISIT_COVERAGE (WDVC)的流程。
3.2.1 算法3:WEIGHTED_DSF_COVERAGE
算法的核心主要是根据DAG 对独立的测试用例 (无依赖关联)根据权值对测试用例进行排序,当测试用例权值相等时结合测试用例的代码覆盖率进行排序。例如图1中的I1和I2就是相互独立的用例。利用算法3的流程,如图6所示,可以对它们的执行顺序进行排序。
3.2.2 算法4:WEIGHTED_DFS_VISIT_COVERAGE
算法4是对交互的测试集进行排序,对权值相等的情况,采用测试用例的代码覆盖率进行排序,相对于DSP 中的排序是一个更佳的排序方法。
权值和代码覆盖率的顶点深度优先算法,如图7所示。
其中第5行是防止已经被执行的测试用例再次运行,减少冗余,提高效率。在实际应用中,可以把以上4 种算法结合起来。针对图1,我们可以得到一个最优的执行顺序:I1-D3-D6-D7-D4-D8-I2-D5-D9-D10。
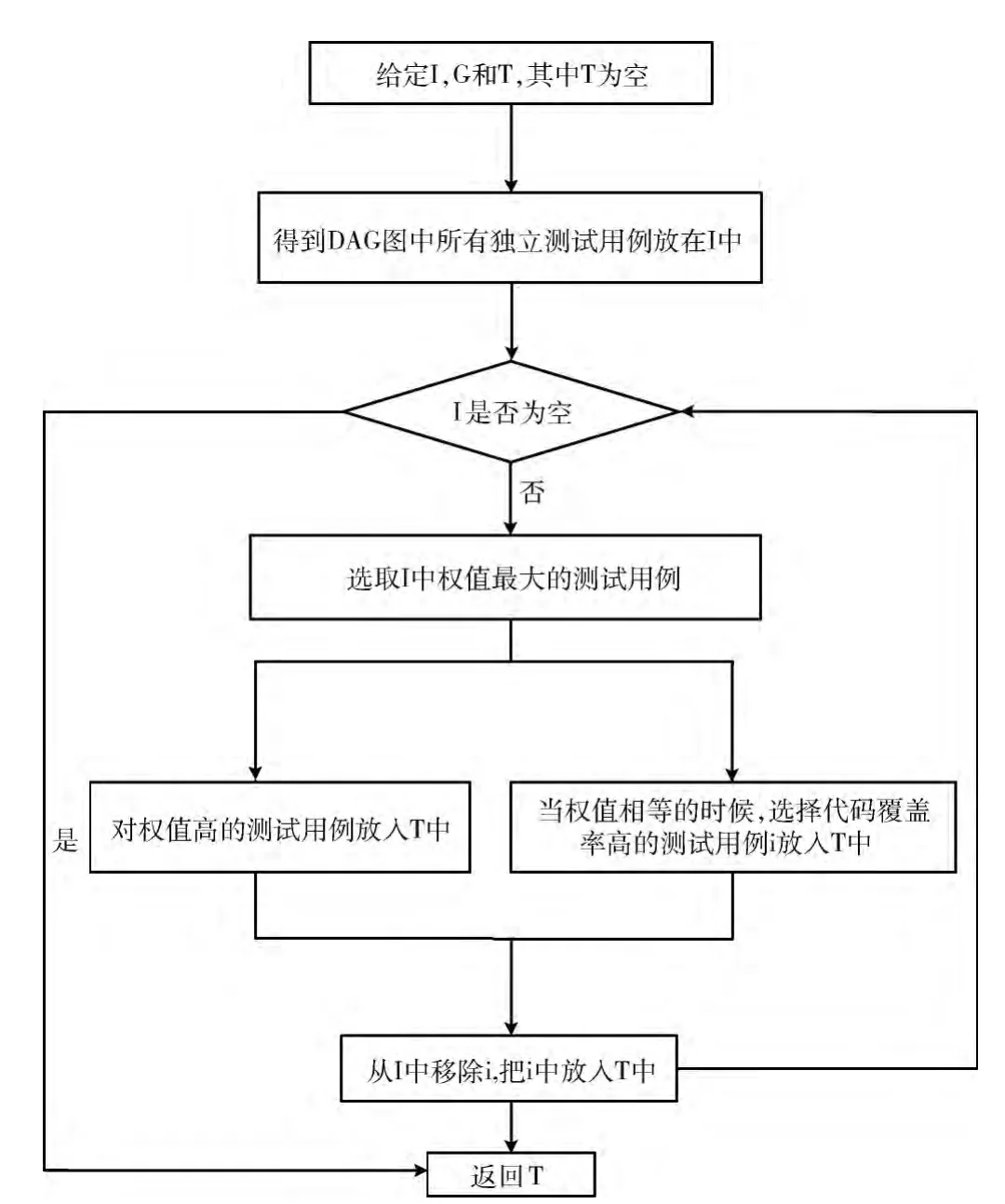
图6 权值和代码覆盖率的深度优先算法
3.3 封闭的依赖结构的优先级
3.3.1 DSP_ratio
DSP_ratio的衡量标准是在一条路径中未执行的测试用例比上已经执行的测试用例的比值,其值越大,说明其权值就越大。此种标准的目的是为了缩减不能发现新错误的测试的测试用例。具体描述如式 (1)所示
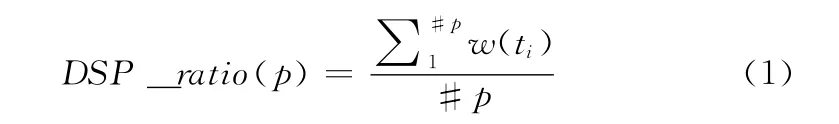
其中w(ti)= {i.0.if seen(ti)otherwise,seen(ti)是真值,如果在当前的测试顺序中,ti已经被执行。#表示一个集合中所包含的测试用例个数。同时,每个测试用例的权值就是在这条路径中的所代表的索引,#p代表这条路径的长度。
3.3.2 DSP_sum/ratio
DSP_sum/ratio度量标准是,未执行的测试用例除以这条路径长度的比值,其优点就在于不用计算每个测试用例的权值。其具体描述如式 (2)所示
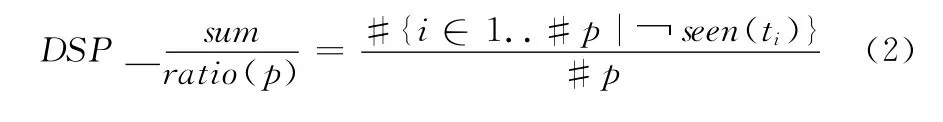
4 实验与讨论
本文的实验主要研究WDC 和WDVC 两种排序方法的优越性,主要关注以下几个问题:①采用WDC 和WDVC两种排序方法是否比随机或贪婪算法错误检错率高,甚至跟最优的排序方法结果一致。②针对相关性比较弱的测试集,新的排序方法结果是否更好。
4.1 实验研究对象
为了验证改进后的算法对测试集排序的有效性,本文选取了几个真实的系统进行测试,它们分别是Elite,GSM,CRM,MET,CZT,Bash。
这些系统涉及的范围比较广,包括网址,组件,单元,系统等。除了GSM 系统的测试集中的依赖结构是为了评估由测试者自己生成的,其它几个系统测试集依赖结构都是手动的,由项目的开发者得到的。
表1描述了每个系统的详细信息,其中依赖结构的密度用式 (3)求得,|E|表示DAG 里所有的边数,|V|代表所有的测试用例
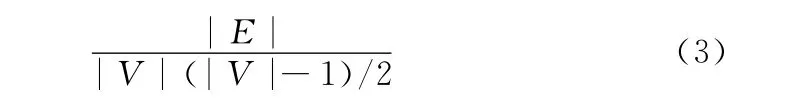
4.2 实验所用的其它测试方法
4.2.1 开放的依赖结构中的其它对比方法
(1)[greedy]:测试用例的排序是选择发现新的最多的测试用例,这种测试只能限制于已知错误的系统。
(2)[untreated]:测试用例的排序顺序是在编写时设定的。
(3)[random]:测试用例的排序是随机的。
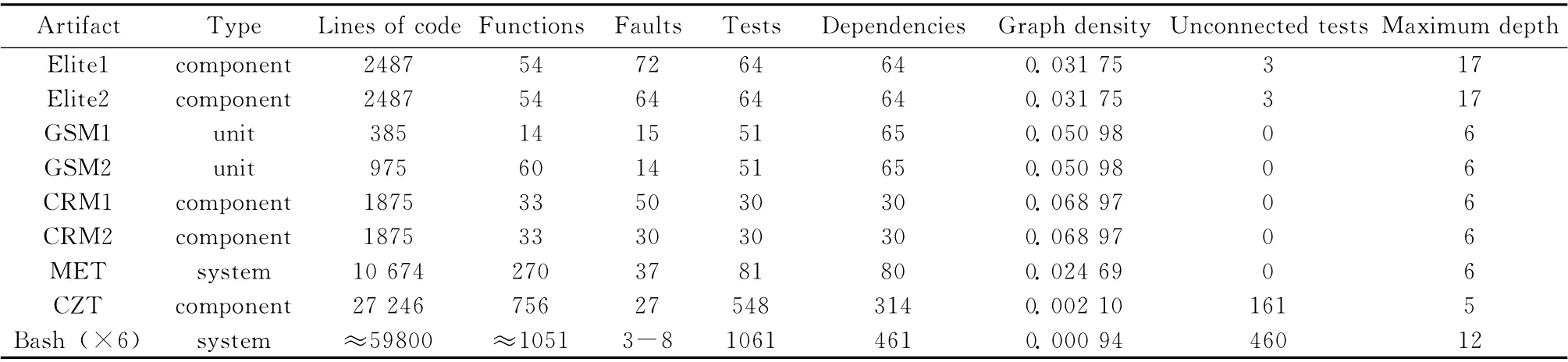
表1 被测系统的度量标准
(4)[optimal]:测试用例的顺序是使得严重错误发现速率获得最大。
4.2.2 封闭依赖结构中的其它对比方法
这些对比方法依次是cg-fn-total,cg-fn-addtal,random,greedy。
4.3 测试用例排序效果度量
4.3.1 错误检错率的加权平均值APFD
针对不同的测试用例排序方法,使用G.Rothermel等提出的APFD 来作为度量标准。其计算公式如式 (4)所示
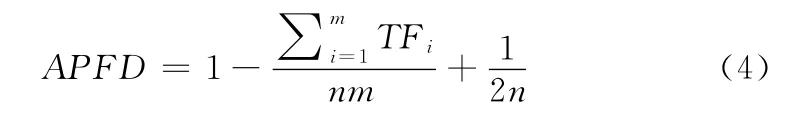
由式 (4)可知,APFD 的取值是从0到1,其数值越大说明发现错误速率越高。
4.3.2 All Faults Metrics(AF)
在以前的测量标准中,对每个测试用例都是用一样的成本来度量,这样在测试成本上就容易造成极大的浪费。为了缓解这个问题,本文提出了一种衡量标准来制约APFD 的不足,即AF (所有缺陷度量),它和APFD 一样是对整个测试集百分比的一种描述,如果T 是包括n个测试用例的测试集,那么F则是T 所发现的错误个数m 的集合,其计算公式如式 (5)所示

其中TFm是指最后发现第m 个错误的测试用例。其值越大,则测试集的测试效率就越低。
4.4 实验结果
基于开放依赖结构的APFD 实验结果见表2。
基于开放依赖结构的AF实验结果见表3。
由表2可知,针对本文介绍的开放依赖结构,实验中的6 个系统相对于任意的和未处理的测试顺序,dsp_height和dsp_volume标准有着很大的优势,并且跟optimal和greedy排序方法结果大体一致。
由表2可知,对于系统中依赖性相对弱的测试场景,采用改进后的测试集排序方法WDC 和WDVC,其APFD结果明显比文献中的测试结果理想并更接近optimal和greedy的测试结果。

表2 开放依赖结构的APFD
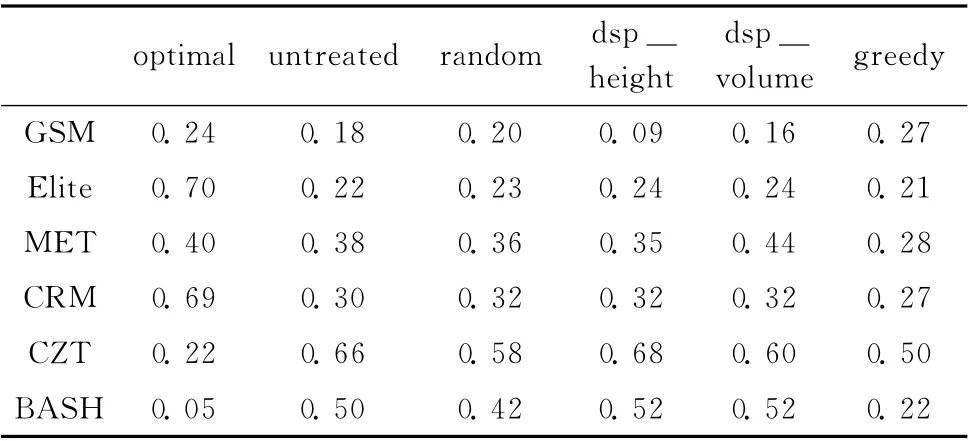
表3 开放依赖结构的AF
从开放依赖结构的实验对比中可以得到,本文对DSP改进的方法在APFD 和AF 这两种度量方法上都有一定的优越性,所以也验证了我们的假设。但本文在考虑测试用例之间依赖结构和代码覆盖率结合来对测试集进行综合排序,随着在提高错误检错率方面有显著的提高,测试成本也有所增加,这是以后测试技术需考虑的问题。同理对封闭的依赖结构的实验也可以得到两组同样的实验结果。
5 结束语
本文重点从两个方面研究了基于依赖结构来优化优先级的技术:①基于测试用例交互的复杂性进行权值分配;②基于直接的传递闭包算法和直接的深度优先搜索算法的核心思想,对测试集进行优先排序。结合这两方面来计算测试用例的APFD 和AF,得出节约时间和成本的测试用例优先顺序。在今后研究有关根据依赖性计算权值与排序之间的关系是将来研究工作的重点。
[1]WANG Dan,PAN Qiangzong,ZHU Luhua.Fuzzing model based on control dependence path coverage [J].Computer Engineering and Design,2012,33 (8):3078-3082(in Chinese).[王丹,潘强宗,朱鲁华.基于控制依赖路径覆盖的Fuzzing模型 [J].计算机工程与设计,2012,33 (8):3078-3082.]
[2]CHEN Shufeng,ZHEN Hongyuan.Dependence analysis and regression testing of object-oriented software [J].Computer Application,2009,29 (11):3110-3113 (in Chinese).[陈树峰,郑洪源.面向软件的依赖性分析与回归测试 [J]].计算机应用,2009,29 (11),3110-3113.]
[3]GAO Xuejuan,WU Xiaochun.UML sequence based interlocking test case generation [J].Application Research of Computers,2013,30 (9):2740-2743 (in Chinese). [高雪娟,吴晓春.应用UML顺序图的联锁测试用例生成方法 [J].计算机应用研究,2013,30 (9):2740-2743.]
[4]CHEN Jianxun,XIAO Yiran.Class-integration testing sequence research based on dynamic dependency [J].Chinese Journal of Sensors and Actuators,2014,27 (1):64-69 (in Chinese).[陈建勋,肖亦然.基于动态依赖的类间测试顺序研究 [J].传感技术学报,2014,27 (1):64-69.]
[5]Haidry S,Miller T.Using dependency structures for prioritization of functional test suites [J].IEEE Trans on Software Engineering,2013,39 (2):258-275.
[6]Chen Yangjun,Chen Yibin.Decomposing DAGs into spanning trees:A new way to compress transitive closures[C]//IEEE 27th International Conference on Data Engineering,2011:1007-1018.
[7]LUO Wenbing,ZHAO Liang,ZHAO Hongyu.Test suite optimization based on graph analysis [J].Journal of Computer Engineering,2010,36 (15):92-102 (in Chinese).[罗文兵,赵亮,赵洪宇.基于图分析的测试用例集优化 [J].计算机工程,2010,36 (15):92-102.]
[8]Selvan S,Nataraj RV.Efficient mining of large maximal Bicliques from 3Dsymmetric adjacency matrix [J].IEEE Trans on Knowledge and Data Engineering,2010,22 (12):1797-1802.
[9]Wahid Nasri,Wafa Nafti.A new DAG scheduling algorithm for heterogeneous platforms [C]//IEEE 2nd International Conference on Parallel Distributed and Grid Computing,2012:114-119.
[10]Marinescu R.Best-first vs.depth-first AND/OR search for multi-objective constraint optimization [C]//IEEE 22th International Conference on Tools with Artificial Intelligence,2010:439-446.
[11]Kundu D,Sarma M,Samanta D,et al.System testing for object-oriented systems with test case prioritization [J].Software Testing,Verification,and Reliability,2009,19 (4):97-333.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
铁道通信信号(2020年6期)2020-09-21 09:23:22
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
传感器与微系统(2018年7期)2018-08-29 00:44:18
自动化学报(2017年7期)2017-04-18 13:41:02
