
面向大数据基于知识的决策信息需求动态生成方法
2015-12-23 00:55:52金欣宗士强李友江吴姗姗闫晶晶
计算机工程与设计 2015年7期
金欣,宗士强,李友江,吴姗姗,闫晶晶
(南京电子工程 研究所信息系统工程重点实验室,江苏 南京210007)
0 引 言
在军事、公安、交通、银行、通信等大型企业机构中,通常都有一套用于企业决策制定的数据系统,其中的数据通常都经过了良好的组织、严格的定义和规范的表达。因而当决策者产生信息需求时,相应的信息服务能够自动地从相应地数据来源处获取信息,并提供给决策者。这是一种 “固定信息服务模式”,即在用户的信息需求和对应的信息来源之间存在某种固定的映射关系,需要时即可从固定来源处直接 “取”信息。这种模式在过去[1,2]工作得很好。
大数据时代的到来引起了学术界、工业界乃至政府的广泛关注[3-5]。大型企业纷纷转向互联网上的大数据,希望能够从中挖掘到有价值的信息用于制定更加高明的企业决策。然而,大数据环境下,信息来源多样、种类繁多、内容冗余、表达异构,决策者在产生信息需求时通常无法预知提供相应信息的来源位置,只能到大数据环境中去 “找”信息。因此,固定信息服务模式在大数据环境下几无用武之地,取而代之的是一种动态信息服务模式——搜索。
使用搜索的前提是对信息需求进行建模,描述信息需求的特征。常用的信息需求建模语言有搜索关键词、数据库查询语言、实时信息订阅请求等。然而,面对大数据环境精确建立信息需求模型殊非易事,用户需要耗费大量的时间在信息需求的表达上,包括仔细斟酌关键词以避免跨领域的歧义,估计信息的可能来源类型,从而决定使用哪种需求建模语言 (事实上,在结构化数据库、非结构化网页和实时信息系统之间存在严重的内容交叠,很多情况下难以确定所需信息的来源类型)。信息需求表达不准确的结果就是要不断地修改。所有这些工作严重分散了决策者的精力,从而导致决策效率低下。
针对上述问题,一种直接的解决思路是将信息需求表达的过程做成自动化的,而实现这种自动化的前提是基于一种新型的领域知识。通过研究发现,当企业决策者在制定同一类决策时,他们所需的信息不论在内容上、粒度上,还是范围上都存在较高的相似性,也就是说,在决策事务类型和用户信息需求之间很可能存在某种潜在的关联关系,而这种关联关系就是前面所述的领域知识。
基于该原理提出了一种方法,发掘决策事务与信息需求间的潜在关联关系并固化为知识,进而依据该知识及动态感知到的用户当前决策事务类型和要素,自动地生成信息需求,将大数据环境中符合需求的信息自动地提供给决策者。实验结果表明,该方法能有效减少决策者的信息需求表达耗时,能够保证一定的准确度,提高决策效率。
1 相关研究
在互联网搜索领域,有很多帮助用户完善需求表达的方法,如关键词生成 (keyword generation)[6]和查询推荐(query recommendation)[7]等。其中运用的知识包括用户搜索记录的分析[8]、词汇关联关系[9]等。这些方法在基于知识优化用户搜索需求表达的同时,也为搜索引擎广告的植入提供了便利,在巨大商业利益的驱动下发展得很快。然而,所有这些方法都需要用户输入初始的关键词,作为优化和推荐的依据。而在本文提出的方法中,信息需求是根据动态感知到的用户决策事务自动生成的,无需输入任何初始关键词。
在基于知识的方法应用上,谷歌和IBM 走在了世界前列。其中,谷歌的知识图谱[10]能够依据领域知识结构,根据用户的输入定位到结构上相关联的一组知识片段;而IBM 的沃森机器人[11]能理解用户使用自然语言表述的问题,并从一套庞大的知识库中快速、准确地定位到正确答案。其中大量运用了从词典、百科全书、新闻报刊等公共渠道中获得的通用型知识 (常识)。众所周知,领域内的问题比普适性问题更容易解决,利用领域知识提升领域系统能力效果会更好。例如在一些决策支持系统中[12-14],领域知识的应用很好地提升了一些算法的性能。然而,在运用领域知识处理面向大数据的决策信息需求生成方面,尚未发现相关研究成果。
其实企业决策系统中的用户信息需求带有明显的领域特征,与其处理的决策事务有很大的关联性。利用这种关联性能够根据用户的决策事物准确估计并自动生成信息需求表达。本文基于的就是这种理念。
2 信息需求建模语言
如上文所述,要从大数据环境中获得决策所需的信息,首先要对信息需求进行建模。因此需要一种强大的建模语言,能够描述所需信息的各方面期望特征,包括内容特征、范围限定、时效性限定、载体类型限定、优先来源限定、排序方式限定等。另一方面,该建模语言应当足够精确,能够描述信息需求的语义内涵,从而避免发布出去的信息需求被各类信息来源错误地理解和转换。
作为建议,设计了一种信息需求建模语言TIRML(task info-req modeling language)。其语法规范见表1,包含7个主要部分。

表1 TIRML语法规范
LABEL是对信息需求的一段自然语言描述,为的是方便人工阅读理解。
USER、OPERATION、MISSION 从3 个维度定义决策事务类型。USER 用于描述决策者的角色类型,如指挥员,参谋等。OPERATION 用于描述用户当前的决策作业类型,如态势分析、任务规划等。MISSION 用于描述用户当前受领的任务类型,如袭击某机场,组织某救援行动等。不同用户角色类型、决策作业类型、受领任务类型对应的信息需求有较大的区别。
SELECT 和WHERE字段沿袭于SQL语言。不同的是将其后面所跟的数据表字段改为了 “主体-属性”的描述形式。逻辑上一个主体可以有一个或多个属性,SELECT 后面跟的是一个主体的未知属性,WHERE 后面跟的是其已知属性,用于限定主体类型。“主体-属性”的形式赋予SELECT 和WHERE 以一种浅层的语义表达能力,其相比SPARQL的语义表达能力较弱,但适用面更广,不一定是纯三元组形式的数据。在关系数据库中,可以将表格的一行当作一个主体,一列当作一个属性。在P/S (发布/订阅)系统中,订阅请求中包含了主体的已知属性,返回的报文中包含了其未知属性。在非结构化文本中,主体和属性隐藏在文字中,例如“北京是中国的首都”变为三元形式即为“<中国,首都,北京>”。因此,“主体-属性”在各类信息组织形式中都有对应的解释,可以通过各种方法被转换成相应地搜索/查询/订阅请求格式,并保持语义不变。
有些时候决策者对所需信息有较为倾向的信息来源,例如信任等级较高的来源、更加稳定、更容易访问的来源等。用户可以将这些优先来源列在FROM 字段之后,以缩小搜索范围,提高搜索精度。
每个信息都有其载体类型,如文本、图像、视频、音频、数据库、格式化消息等,可以用MEDIATYPE 进行限定。
WHEN 字段用于描述对所需信息的时效性要求,分持续性和一次性两种。持续性需求表示在一个时间段内需要持续的更新。可以用START、END 来描述这个时间段,用PERIOD 和REPEAT 分别描述针对实时信息的更新时间间隔和对非实时信息的定期搜索查新时间间隔。一次性需求表示当第一个搜索结果返回时该需求就失效了。分别用EARLIEST 和LATEST 来描述所需信息的最后更新时间的范围。REALTIME则用来表示所需信息是实时信息还是非实时信息。
ORDERBY 字段用于描述对搜索结果的排序要求。可以使用 “|-”连接符来表达综合排序的要求。例如 “相关度|-来源信任等级”表示先按相关度排序,当两条结果的相关度相等时再按来源信任等级排序。
3 信息需求生成方法
不像人们日常浏览互联网那样随意,企业决策者的信息需求有一定规律性,与其正在处理的决策事务是相对应的。分析决策者的信息查询操作记录不难发现,同一类用户在处理同一类决策事务时所需的信息类型是基本相同的,只是根据涉及到不同对象及时空上下文时会有细微差别。以军事领域为例,指挥员在针对某个目标制定打击方案时,通常要了解目标的防御能力及运动状态等信息,只是具体的目标和打击时间、地域不同而已。如图1 所示,在用户决策事务类型与信息需求之间存在某种潜在的关联映射关系,目前还是一个黑盒子,有待开发。
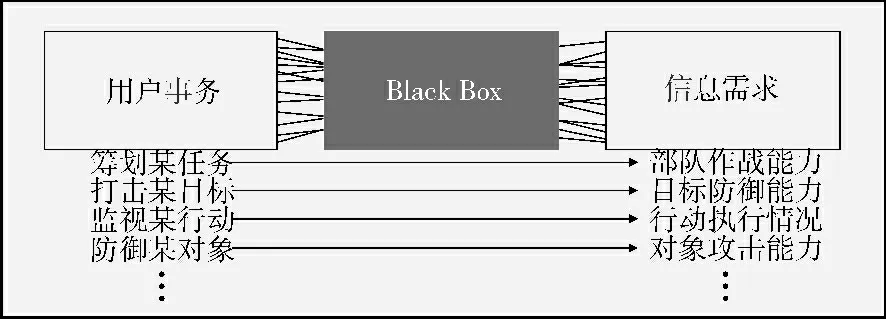
图1 事信映射原理
基于上述原理,对企业领域中的用户决策事务分门别类,然后将每一类事务所需信息类型写成一个模板 (称为“事信映射模板”),对其中变化的因素留出空来,待遇到实际事务时,选调相应的模板并根据实际变量数值填空,从而生成实际的信息需求,进而根据领域术语的表达方式,对需求进行准确描述,以上便是本方法的核心思想。方法如图2所示,分为准备和使用两个阶段。接下来从领域知识构建、用户决策事务感知、信息需求生成、需求语义描述、需求发布管理5个方面展开说明。
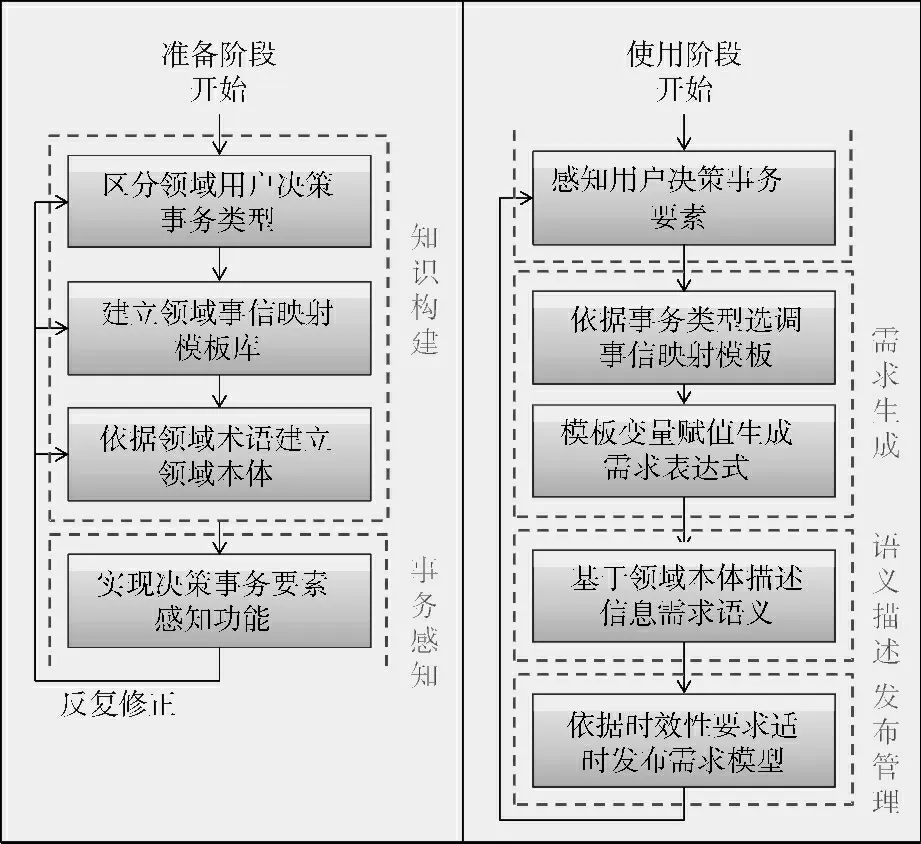
图2 方法概述
3.1 领域知识构建
(1)区分领域内的用户决策事务类型。区分的依据是两类事务所需信息之间的差别无法用变量表示。例如打击敌方目标和防御敌方进攻所需信息类型截然不同,而打击两个同类目标所需信息的差别则可以体现为一个变量。变量的粗细粒度可以灵活把握。
(2)确定事务类型判别要素,即依据哪些要素判别一个事务属于哪个类型。不同事务类型的判别要素可以不同。作为一种建议,提出了6个常用要素,分为两组:一是<用户类型 (UserType),决策作业类型 (OperationType),作业对象类型 (ObjectType)>,描述决策作业;二是<执行者类型 (ActorType),行为类型 (ActionType),目标对象类型 (TargetType)>,描述决策所关注的背景任务/事件。几乎任何一个决策事务都可以理解为针对一个背景任务/事件执行某个决策作业。因此,<U,O,O,A,A,T>6元组可以从两个维度上唯一地刻画一个用户决策事务类型,可作为其全局唯一的标识。
(3)建立事信映射模板库,将用户决策事务类型与所需信息类型之间的映射关系写成模板。发掘事信映射关系的方法有两种:一是依据经验,即邀请领域专家,尤其是长期从事某类决策事务的用户,根据经验列出处理每类事务所需的信息类型;二是通过学习,即对用户决策过程进行记录,包括其每次执行的决策事务要素和相应的信息查询操作,通过自动挖掘与人工分析相结合的方式,学习可能的事信映射关系。对于模板的编写语法规范这里并不做限定,可以参考TIRML语法规范,一种能够为各类信息资源解析转换的统一需求描述语言。一个例子如图3所示。
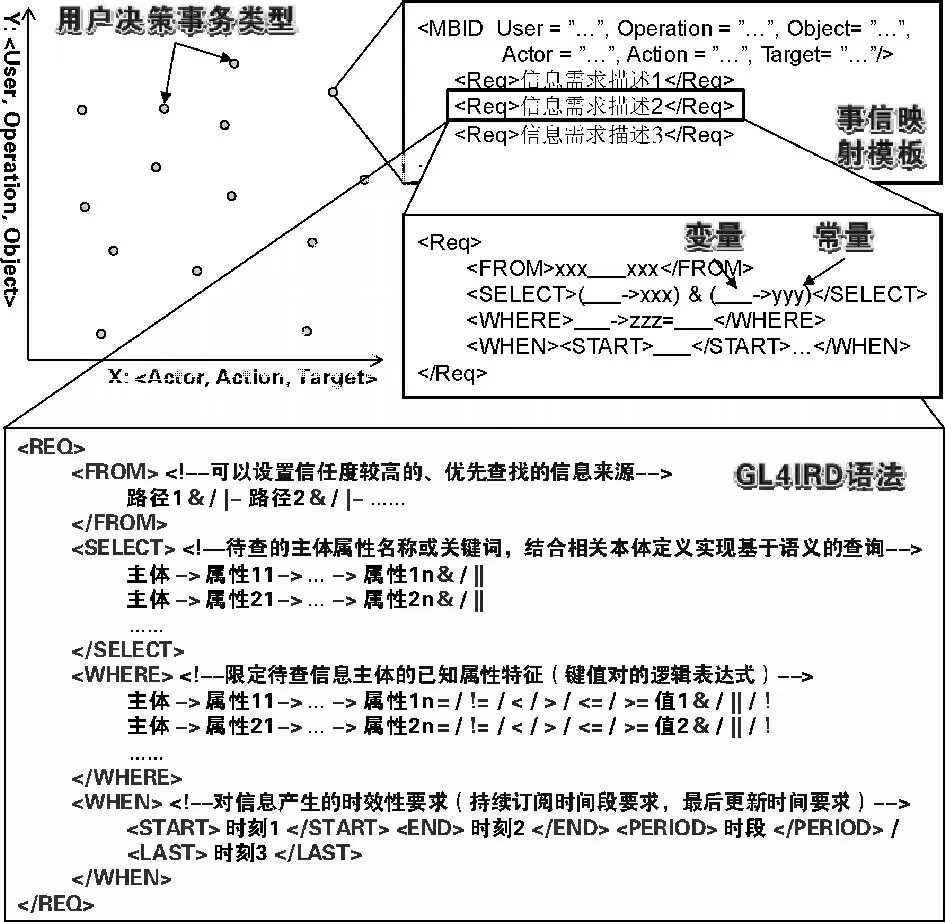
图3 事信映射模板
(4)建立关于领域术语的本体知识。众所周知,领域术语可用来规范领域内的信息表达,使得领域内的用户或系统能够在语义一致的基础上进行交流。本体是对领域术语的概念和关系的严格定义,通过RDF、OWL等本体语言可描述为机器能够理解的形式。因此,建议定义企业领域本体,并采用本体中的术语来描述事信映射模板,以便用户端描述的需求能够为资源端正确理解。然而,用户端和资源端往往不在同一个领域,所采用的领域本体也很难统一。可以借助于本体匹配技术,实现不同领域本体之间的关联映射。企业可以利用已有的本体匹配工具[15]建立本领域和其它相关领域本体之间的映射关系。
事信映射模板、领域本体及本体映射关系是本方法中用到的领域知识。接下来将详细介绍如何使用这些知识来实现决策信息需求的自动生成。
3.2 用户决策事务感知
用户端程序要实现对上述用户决策事务要素的感知功能。具体的,包括以下几类:
感知用户身份:可以通过用户登录操作识别用户身份,判别用户类型,为UserType赋值;
感知作业过程:监听用户界面操作,包括切换作业界面、使用作业工具、操作作业对象等。预先定义这些操作对应的作业类型码,根据实际监听到的操作对Operation-Type和ObjectType赋值;
感知背景任务/事件:背景任务/事件通常会通过某种方式导入到决策作业软件中,例如在军事领域可以是作战任务文书的形式,其中说明了任务的执行者、行为和行为目标对象,可以解析其数值并赋给ActorType、ActionType和TargetType;
感知实体和时空上下文变化:实时采集决策中涉及的各类实体对象标识、地理区域标识,以及时间信息,用于为模板中设定的各种变量赋值。
由于具体的感知功能实现方法与具体应用相关,这里不做限定,只要能够实时采集上述信息即可。
3.3 信息需求生成
将实时感知到的用户决策事务要素与事信映射模板的标识进行匹配。由于模板标识是全局唯一的,不会出现同时匹配上多个模板的情况。另一方面,如果在模板设计时全面考虑了所有可能的要素取值组合,也不会出现匹配不上任何一个模板的情况。
模板选调与模板填空如图4所示。
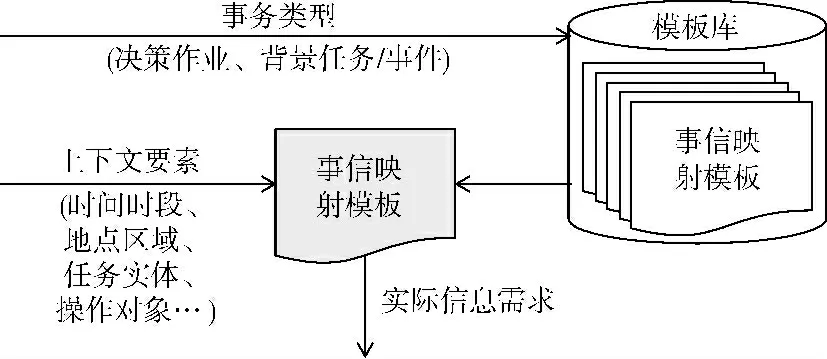
图4 模板选调与模板填空
将匹配上的模板选调出来,将感知到的实体、时空上下文等信息的取值赋给模板中的变量,即模板填空。当模板中所有的留空都被填满时,一个实际信息需求的模型就建立出来了。
3.4 需求语义描述
此时生成的信息需求可以直接提交给信息资源,转换成各类信息资源支持的查询语法。但为了获得精准地信息反馈,还要依据领域本体对需求的语义进行准确描述。
在TIRML的语法中,支持 “主体-属性”形式的语义描述,即将每一条信息需求描述为对某个主体的某个属性值的需求,而其中的主体和属性都是在相关本体中定义过的,通过名字空间保证标识的唯一性,如 “wp:林肯”。基于前面建立的领域本体之间的映射关系,能够保证跨领域的信息资源对其内在含义的一致理解,从而在解析转换时不改变、不减损信息需求的语义内涵。例如,“林肯 (航母)”不会被错误的理解为“林肯(汽车)”或“林肯(总统)”。
在实际使用过程中经常出现这样的情况,即在编写模板时,所设变量的粒度较粗,取值范围较宽,导致 “主体-属性”的描述难以细化。例如 “飞机-对地打击能力”是一个较为宽泛的概念,不能直接用于查询或搜索,需要转换成更具体的属性。但根据机型不同,对地打击能力可以细化为不同的属性参数,如对轰炸机细化为 “空地导弹射程范围”,对直升机则细化为 “机枪扫射最大频率”等。总之,当主体作为变量而其取值可以是多类对象时,属性本身也是不确定的。解决方法定义如图5 所示的领域本体。这样,当 “飞机”的实际取值为 “轰炸机”时,“对地打击能力”属性就会自动转变为 “空地导弹射程范围”,对 “直升机”则自动转变为 “机枪扫射最大频率”。
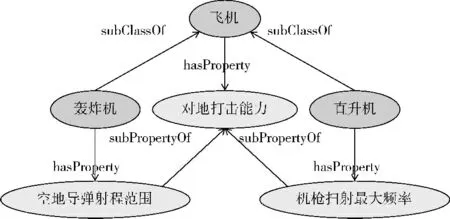
图5 基于本体的语义扩展
在实际使用过程中往往还会遇到这样的情况,即同一个主体有多种不同的标识名称,如 “F-18”与 “大黄蜂”指的是同一类机型。如果单使用 “F-18”进行搜索,会漏掉一部分关于 “大黄蜂”的信息,反之亦然。为了保证需求描述的全面性,要对需求描述中的主体进行共指扩展。维护一张 “实体标识共指扩展表”,对每一类实体的所有可能的共指标识进行穷举性扩展,可以在平时使用中不断积累形成。这样,就可以将 “F-18-最大航程”扩展为 “(F-18-最大航程)or(大黄蜂-最大航程)”进行搜索,以避免遗漏。类似的,对属性也可以进行同义词扩展,例如 “林肯号航母-排水量”可以扩展为 “(林肯号航母-排水量)or(林肯号航母-吨位)”。
3.5 需求发布管理
需求生成的最后一步,是将需求模型发布出去,提交给各类信息资源解析转换。除了需求模型内容的准确性外,生成时机的准确性也很重要。不够适时的需求生成对用户不但不能提高效率,反而是负担。
用户决策事务感知的灵敏性是保证 “适时”的一方面,另一方面可以将对信息需求的时效性要求写在模板中。在TIRML 的语法中提供了START、END、PERIOD、REPEAT、EARLIEST、LATEST、REALTIME 这7 个字段表达时效性要求。
一般而言,将需求分为持续性和一次性两种。持续型需求指用户在一段时间内需要获得持续更新。START 和END 用于描述持续时间段,PERIOD 和REPEAT 用于描述实时信息的更新频率和非实时信息查新周期。实时信息资源会将START、END、PERIOD 分别转换成订阅请求中的起始时间、结束时间、发送间隔;而对于非实时信息资源,则需要按照REPEAT 中设定的周期从START 到END期间,定期向非实时信息资源提交重复的需求模型以捕获新发布的信息。这要求信息资源支持增量搜索/查询,否则需要对每次返回的结果做去重处理。一次型需求指从用户提交一次需求到获得一次结果为止,就完成一次信息搜集的过程。EARLIEST 和LATEST 字段可以描述信息的新旧程度,例如1个月内或1天内发布的信息。非实时信息资源会依据此字段值对结果进行筛选,取决于其是否支持按更新时间搜索/查询。最后,依据REALTIME 的取值决定将信息发送给实时或非实时信息来源。
关于7个字段取值的设定依据,可以依据领域专家的经验,也可以通过统计分析学习的方法获得。
4 实 现
为了验证上述方法的可行性和有效性,选取军事领域中的典型应用背景开展了软件实现工作。
(1)对防空作战应用领域中的用户决策事务进行了分类,将决策作业过程分为搜集情况判断、航路规划、打击进入方向分析、打击行动监控、战后总结评估5 类事务,将背景任务/事件分为航空兵拦截敌机、防空火力拦截敌机、航空兵打击敌方基地、航空兵打击敌方航母编队等11类事务,通过两两组合构成了55类用户决策事务,并分别编写事信映射模板,建立了模板库。其中,模板内容的填写遵循了TIRML规范,依据的是领域专家的经验,涉及到实时战场动态、非实时战场环境、结构化装备数据、非结构化情报数据等各种类型的信息需求。对领域中的术语建立了包含共计84个概念,28 个关系,约2000 个实例的4套相互异构的领域本体,并利用本体匹配方法Falcon-AO[15]建立了映射关系。其中定义了25条实体共指关系和10条属性共指关系。
(2)对现有的防空作战指挥软件进行了改进,加入了包括用户登录身份识别、文书导入解析处理、阶段转进操作监控、行动更替变化监听、作业工具操作监控、图上军标操作监控、系统时间采集、区域选定操作监控等功能在内的用户决策事务感知模块,实现了对用户决策事务要素的动态采集和赋值。
(3)在企业决策系统服务器上设计开发了需求生成和过程管理等功能模块,实现了从感知用户决策事务到生成信息需求模型的全过程,如图6所示。
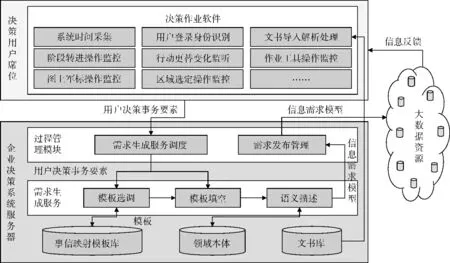
图6 系统实现
5 实 验
为了验证方法的可行性和有效性开展了实验。针对55类用户决策事务中的每一个实例,请一名决策者手工输入信息需求表达式,并与自动生成的需求表达式进行比较,一方面比较完成需求建模的耗时,另一方面通过搜集的信息结果比较需求表达的准确度。
5.1 信息需求建模耗时
测试结果如图7所示,手工完成表达式的平均耗时约半分钟 (还是保守计算,减去了用户依据搜索结果修改表达式的耗时),而自动生成需求的平均耗时约为0.5s(2.8 GHz,2GB)。很明显,自动生成需求的方法能够有效缩短需求建模的耗时。
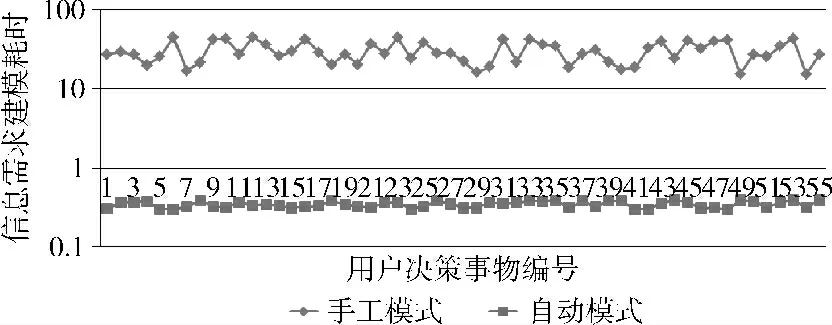
图7 信息需求建模耗时比较
以作战参谋针对航空兵拦截来袭敌机任务进行航路规划为例,需求生成过程如图8所示。其中,战斗机 “机动能力”信息依据领域本体被细化为 “最大机动过载”、 “最大飞行速度”、“最大爬升角度”3个属性,“F-18”的共指标识 “大黄蜂”也得到了扩展。通过该实例不难发现,即便“战斗机机动能力”这样一条简单的信息需求,都需要很长的篇幅去精确描述。这样的工作如果手工完成,需要耗费相当多的时间和精力。而基于预先构建的领域知识,机器能够在极短的时间内完成上述工作。更大的好处在于,需求生成的自动化,带动了信息服务的整体自动化,即伴随着用户的决策作业过程,系统后台会适时自动地搜集适当的信息提供给决策者,因而更加便于将决策者的注意力集中在处理决策问题本身上。
5.2 信息需求建模准确度
通过比较自动生成的和手工建立的需求模型,不难发现,自动生成的需求表达式往往比较复杂,因为在模板中设定了很多限定条件,并基于领域本体自动进行了共指标识扩展,表达式中包含的信息量比较大。相比之下,不论经验多么丰富的决策者,要在短时间内全面考虑各种因素是很难的,要根据搜索结果反复修正表达式才能达到同等复杂度。
不过,就搜索结果而言,自动的方法在结果的查全、查准率上并没有非常显著的提升。通过分析认为,主要原因在于目前建立的领域知识还不够成熟,尤其是不够精细,对一些信息需求的细节刻画不够精密,相比人工描述还显得 “笨拙”。而且,实验中也发现,一些决策者的个性化需求在自动生成的表达式中没有体现。这是因为领域知识是依据大众共识建立的,不包含个性化的成分,因此生成的需求往往不能十分贴切地满足每个用户的个性化需求。
针对上述问题,在系统实现中增加了一道确认机制:自动生成的信息需求可以选择要求经过用户确认,之后再发布出去。这样,用户可以通过修改自动生成的表达式来保证其准确地反映了自己的真实需求。而另一方面,机器记录下用户的每一次修改操作,挖掘分析其中的规律,以促进领域知识的不断完善。虽然上述机制在某种程度上增加了人工参与的工作量,但相对于纯手工方式仍然具有优势。而且随着领域知识的不断完善,手工修改的工作量会逐渐减少,优势的体现会更加明显。

图8 需求生成实例
6 结束语
大数据改变了企业决策系统中的信息服务模式,但也为用户获取决策信息带来了困难。为了获得精确的结果,用户需要花费大量时间和精力在信息需求的表达上。应用领域知识能够有效解决这个问题。提出了一种主动感知用户决策事务,依据领域知识自动生成精准的信息需求语义描述的方法,能够有效减少用户消耗在信息需求表达上的时间和精力。但生成信息需求内容和时机的准确性取决于领域知识的完备性,因此使用该方法的主要难度在于领域知识的构建,是一个需要长期积累和反复验证的过程。
下一步的研究工作将重点针对领域知识的构建展开。事信映射模板是领域知识的一种初级表现形式,在用户决策事务和信息需求之间的映射是有规律可循的。下一步拟通过实验数据分析挖掘这种规律,建立事信映射规则,以取代目前的事信映射模板,目的是提高领域知识的表达和应用能力。
[1]CHEN Zhixin,TAN Xingqiu.Technology on C2system flow control[J].Command Information System and Technology,2013,4 (3):20-24 (in Chinese). [陈志新,谈兴秋.指挥信息系统流程控制技术 [J].指挥信息系统与技术,2013,4(3):20-24.]
[2]ZHANG Jian,CHEN Zhaobing.Intelligence delivery control system for joint intelligence support system [J].Command Information System and Technology,2013,4 (2):33-36 (in Chinese).[张坚,陈召兵.联合情报保障体系情报信息分发控制系统 [J].指挥信息系统与技术,2013,4 (2):33-36.]
[3]Agrawal D,Bernstein P,Bertino E,et al.Challenges and opportunities with big data-a community white paper developed by leading researchers across the united states[EB/OL].[2012-10-15].http://cra.org/ccc/docs/init/bigdata/whitepaper.pdf.
[4]Manyika J,Chui M,Brown B,et al.Big data:The next frontier for innovation,competition and productivity [R].Technical Report,McKinsey Global Institute,2011.
[5]Office of science and technology policy.fact sheet:Big data across the federal government[EB/OL].[2012-03-29].http://digital-scholarship.org/digitalkoans/2012/03/29/fact-sheet-big-data-across-the-federal-government/.
[6]Hao W,Guang Q,Xiaofei H,et al.Advertising keyword generation using active learning [C]//Proceedings of WWW MADRID.Madrid,Spain:ACM Press,2009:1095-1096.
[7]Aris A,Luca B,Carlos C,et al.An optimization framework for query recommendation [C]//Proceedings of the 3rd ACM International Conference on Web Search and Data Mining.New York,USA:ACM Press,2010:161-170.
[8]Marco G,Carlo S,Oliviero S.Ecological evaluation of persuasive messages using Google AdWords [C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics,Stroudsburg.PA,USA:ACM Press,2012:988-996.
[9]Abhishek V,Hosanagar K.Keyword generation for search engine advertising using semantic similarity between terms[C]//Proc of the 9th International Conference on Electronic Commerce.Minnesota,USA:ACM,2007:94.
[10]Singhal A.Introducing the knowledge graph:Things,not strings [EB/OL ]. [2012-05-24]. http://googleblog.blogspot.com/2012/05/introducing-knowledge-graph-thingsnot-strings.html.
[11]Ferrucci D,Brown E,Chu-Carroll J,et al.Building watson:An overview of the DeepQA project [J].AI Magazine,2010,31 (3):59-79.
[12]Samuel W,James F.A text-based decision support system for financial sequence prediction [J].Decision Support Systems,2011,52 (1):189-198.
[13]Calabrese F,Corallo A,Margherita A,et al.A knowledgebased decision support system for shipboard damage control[J].Expert Systems with Applications,2012,39 (9):8204-8211.
[14]Iftikhar U S.Knowledge-based spatial decision support systems:An assessment of environmental adaptability of crops[J].Expert Systems with Applications,2009,36 (3):5341-5347.
[15]Wei H,Yuzhong Q.Falcon-AO:A practical ontology matching system [J].Web Semantics:Science,Services and Agents on the World Wide Web,2008,6 (3):237-239.
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
作文大王·低年级(2022年12期)2022-12-23 02:16:15
中国交通信息化(2022年10期)2022-11-17 08:19:42
纺织科学研究(2021年9期)2021-10-14 08:52:10
中国音乐学(2020年4期)2020-12-25 02:58:06
河南水利年鉴(2020年0期)2020-06-09 05:43:44
中学生数理化·七年级数学人教版(2019年6期)2019-06-25 01:01:34
文学教育(2016年27期)2016-02-28 02:35:15
卷宗(2013年6期)2013-10-21 21:07:52
长春大学学报(2013年8期)2013-06-21 09:04:04
