
基于参数化分解树的控制流二次平展混淆方法
2015-12-23 09:13周娜琴,齐德昱
华南理工大学学报(自然科学版) 2015年5期
Foundation items: Supported by the Science and Technology Planning Project of Guangdong Province(2011B010200054) and the Team Project Fund of Natural Science Foundation of Guangdong Province(10351806001000000)
基于参数化分解树的控制流二次平展混淆方法*
周娜琴齐德昱
(华南理工大学 计算机系统研究所, 广东 广州 510006)
摘要:针对软件白盒子安全问题,提出了一种基于参数化分解树的控制流二次平展混淆的改进方法.该方法首先根据设定的深度、广度及粒度的上界构建参数化分解树,然后用一个while-switch循环选择结构统筹整棵树,并对树中满足一定条件的节点进行二次平展.实验结果表明:与基于参数化分解树的控制流平展混淆方法相比,文中方法减少了执行开销和解决深层不作为问题;与传统的控制流平展混淆方法相比,文中方法增加了反编译及逆向工程的难度.
关键词:软件保护;控制流平展;代码混淆;逆向工程;分解树;安全
收稿日期:2014-01-03
基金项目:* 广东省科技计划项目(2011B010200054);广东省自然科学基金团队项目(10351806001000000);广州市应用基础研究项目(11C41150785)
作者简介:周娜琴(1982-),女,博士生,主要从事软件安全研究.E-mail: zhou.naqin@mail.scut.edu.cn
文章编号:1000-565X(2015)05-0132-07
中图分类号:TP311
doi:10.3969/j.issn.1000-565X.2015.05.021
据统计,2010年世界范围内使用的软件有42%是盗版的,造成的直接经济损失约58.8亿美元[1].这不仅给软件开发商造成了重大的经济损失,而且对软件企业的成长非常不利.此外,云计算的出现给软件安全带来了新的挑战[2-3].因此,软件白盒子安全已成为科学研究的重大课题,越来越引起学术界和产业界的极大关注.
针对软件白盒子安全问题,学者们提出了多种保护途径,主要包括加密、软件水印、反跟踪技术和代码混淆等技术[4-16].其中代码混淆技术实现相对比较容易,因此被广泛研究及应用.对于代码混淆技术的研究,以Collberg等[4]的成果最为显著[5].
文献[5]提出了一种插入相似性垃圾代码的混淆方法,用于增加反编译以及逆向工程的难度.文献[6]从代码区移除控制流信息,并把它隐藏到数据区,然后在执行时重构.文献[7]根据专家指标评分法建立代码混淆模糊度模型,对代码混淆方法进行了鲁棒性量化评价.文献[8]最早提出了控制流平展化的思想,通过对控制流图进行平展来达到混淆程序的控制流逻辑关系的目的.文献[9]对控制流平展变换方式给出了严格的理论证明.文献[10]把控制流平展化的思想运用到C/C++代码中,给出了相应的算法描述.文献[11]把控制流平展时所需要的调度变量进行动态赋值,进一步隐藏原代码的控制流信息.文献[12]从代码混淆的多样性出发,提出了基于参数化分解树的控制流平展方法,该方法根据所设定的深度、广度和粒度的上界生成不同的混淆代码,增加了逆向工程的难度.
由于基于参数化分解树的控制流平展方法会增加执行开销和出现深层不作为问题,因此,文中提出了一种基于参数化分解树的控制流二次平展混淆方法,以减少执行开销,并进一步增加逆向工程的难度,从而达到保护软件安全的目的.
1参数化分解树相关说明及定义
文中混淆方法是基于参数化分解树的方法,因此首先给出参数化分解树的相关说明及定义.
定义1段是指l个连续的执行语句.
定义2基本块是指程序中顺序执行的段序列,其中只有一个入口和一个出口,入口就是第一个语句,出口就是最后一个语句[13].
定义3if块是由if条件语句和所属的段构成.
定义4while块是由while条件语句和所属的段构成.
定义5do while块是由while条件语句和do所包含的段构成.
定义6for块是由初始语句、条件语句、执行后语句和所属的段构成.
定义7switch块是由switch变量、case值和各自所属的段构成.
定义8X块代表基本块、if块、while块、do while块、for块、switch块中任意一种块.
定义9组合块指程序中顺序执行的X块序列.
为有效地解决混淆老化问题和提供多样化的混淆结果,在控制流平展方法中引入了参数化分解树,通过控制参数动态地调整变换方法,使代码不断地等价更新.参数化分解树是对代码的结构进行划分,使源代码段化成一棵控制树[12].文献[12]中描述了参数化分析树,但未考虑组合块概念,而且缺乏严谨的形式化定义.为此,文中给出了参数化分解树的如下定义.
定义10参数化分解树T(d,h,l)是一棵根据给定的参数(d,h,l)对需要混淆的代码块S分解细化构造而成的树.其中
(1)d、h、l分别为广度、深度和粒度的上界;
(2)当h=1时,T(d,h,l)是只有一个节点的树,该节点为代码块S;
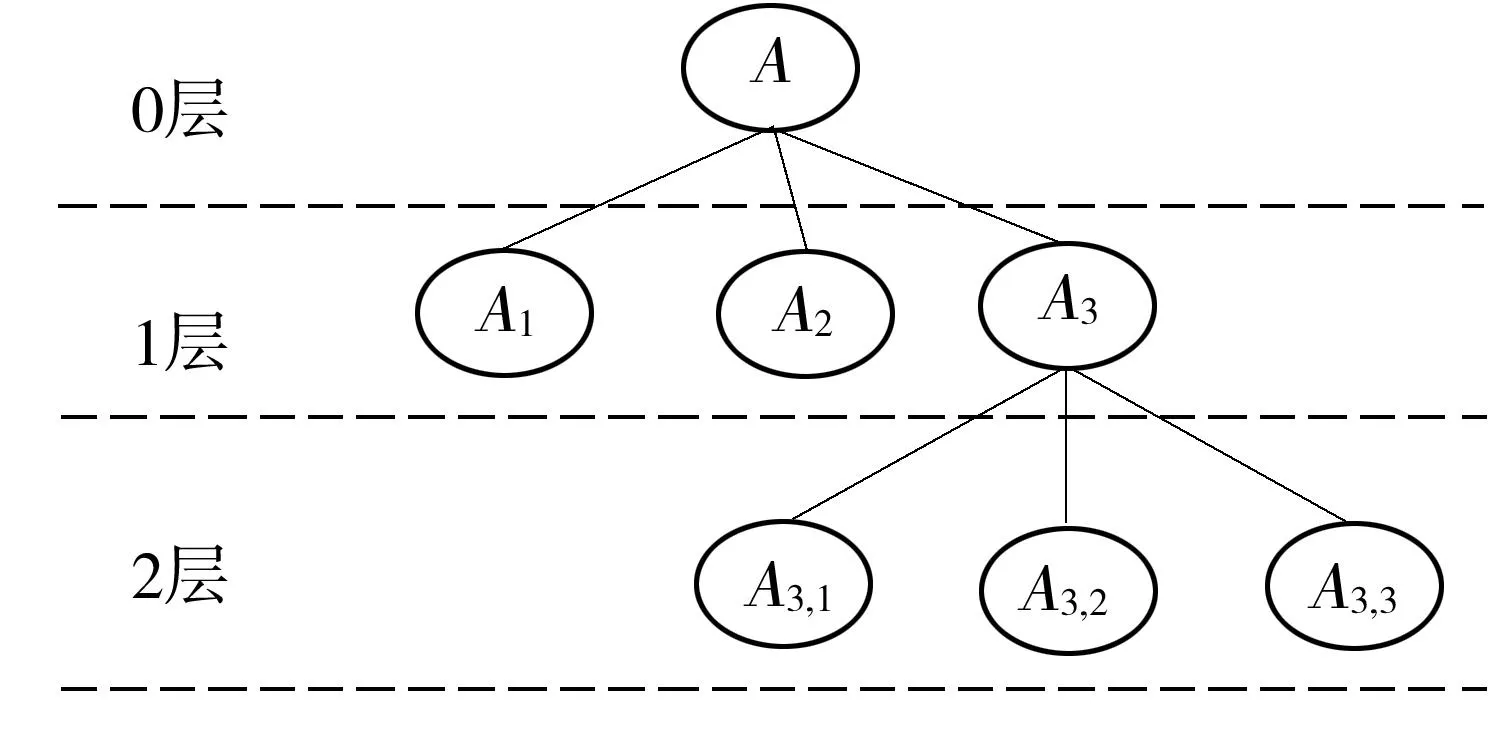
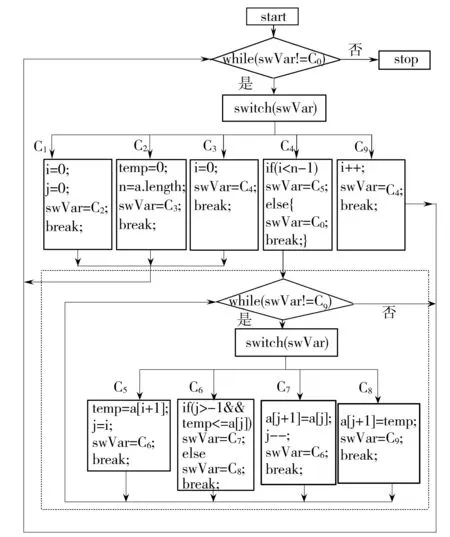
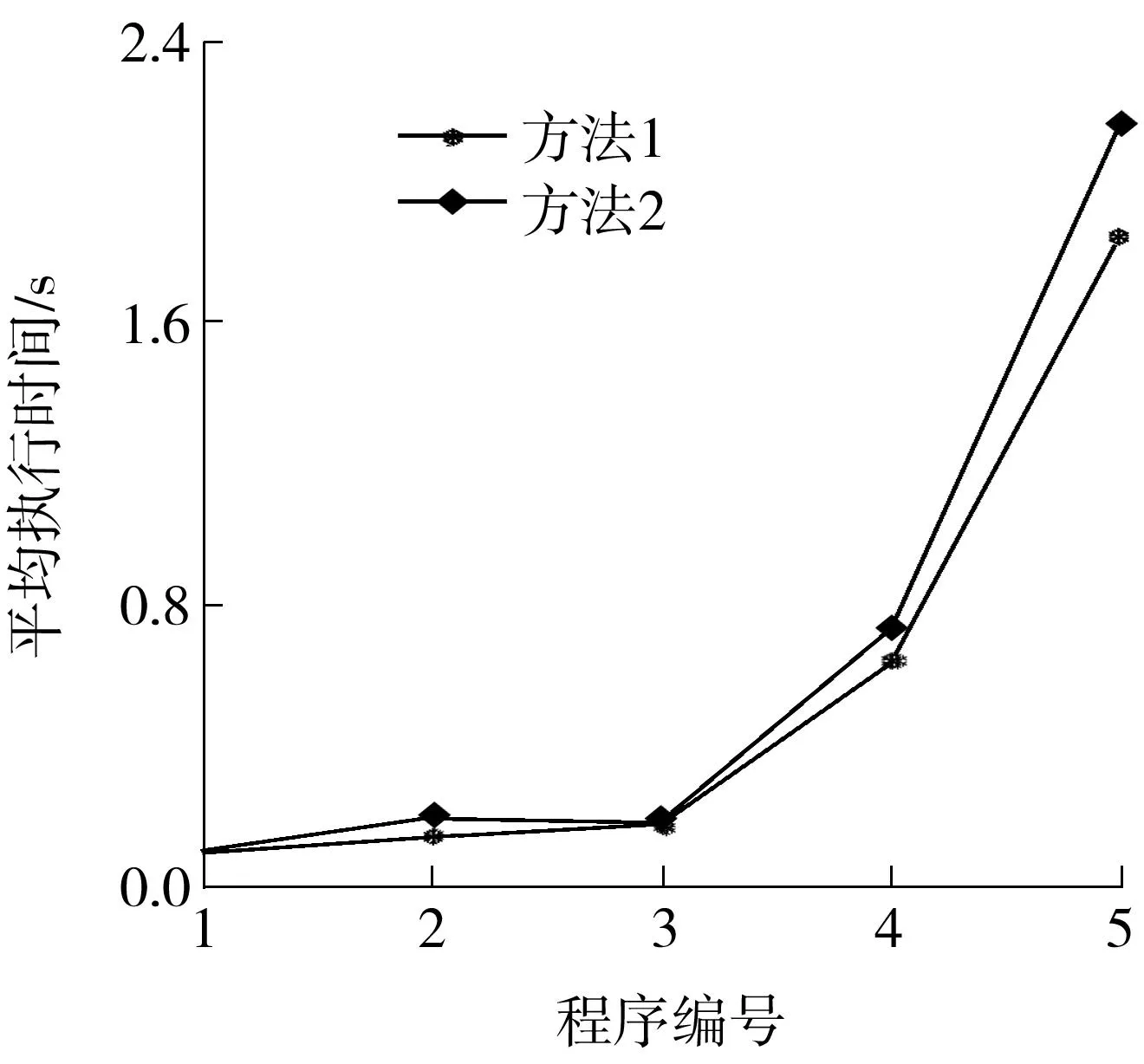
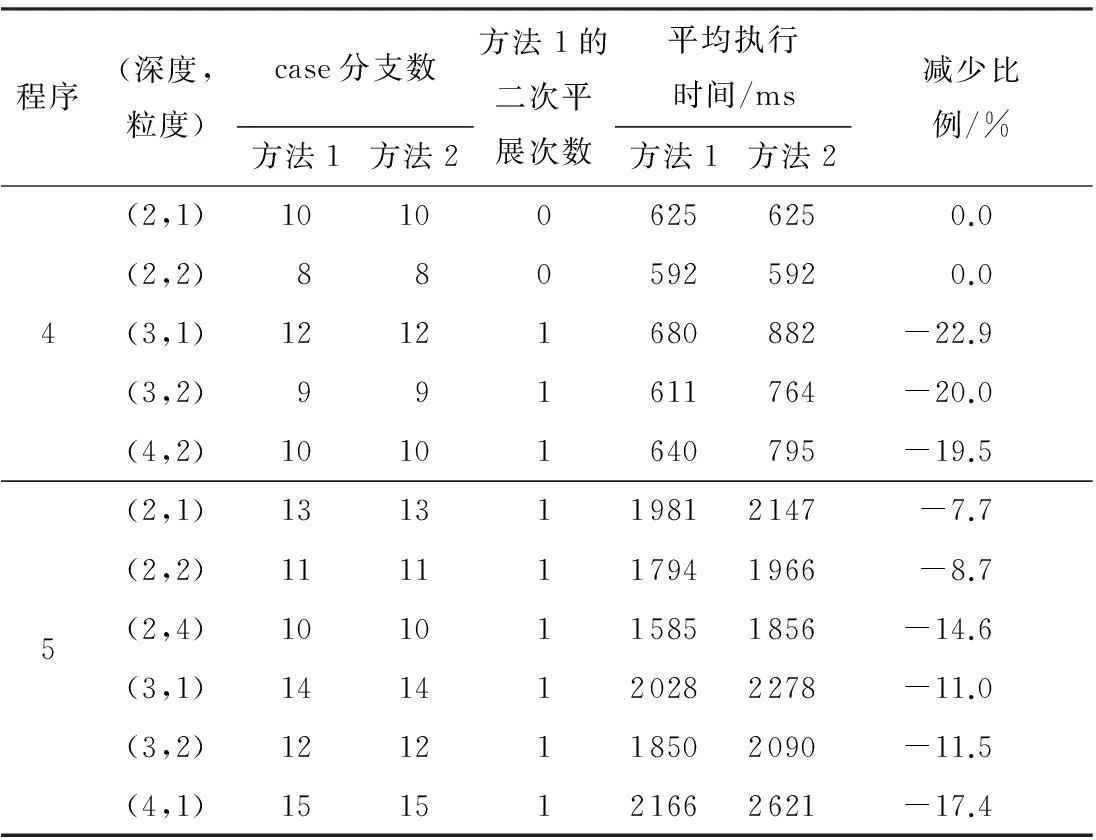
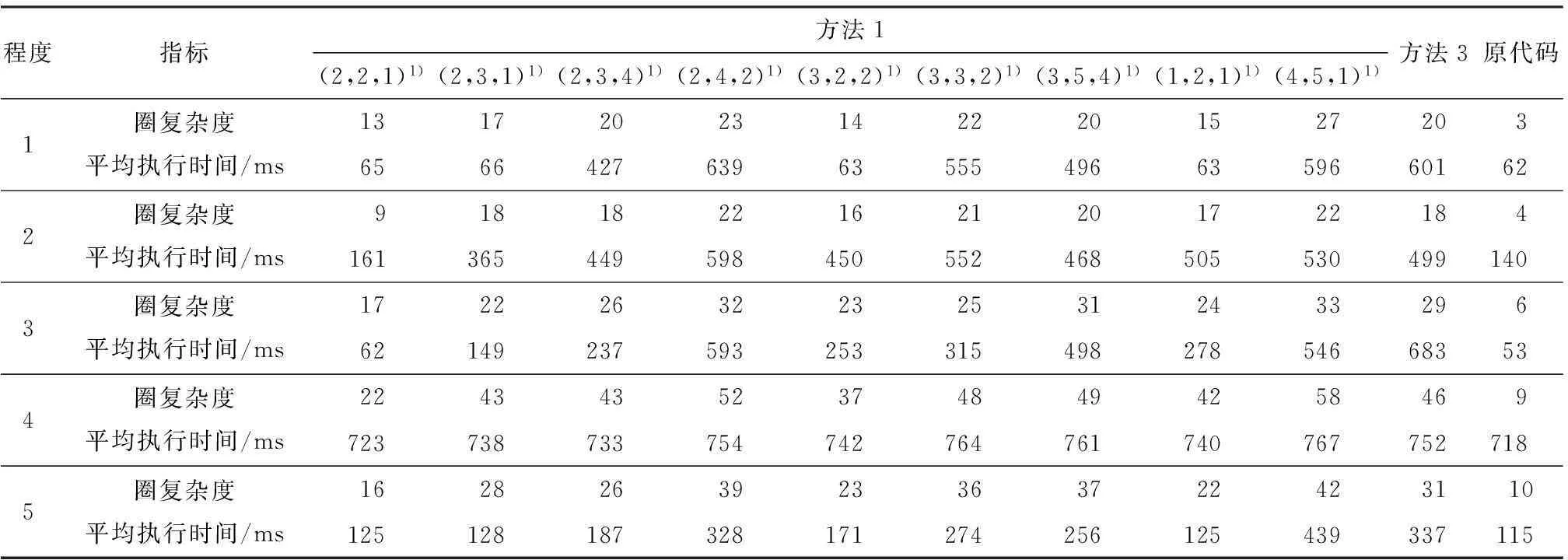
(3)当h>1时,T(d,h,l)以代码块S为根节点,记第m层节点为Ai1,i2,…,im(ij∈[1,d];j=1,2,…,m),根节点为第0层.当m 图1 代码块 1 例如,对于图1所示的代码块,可用参数化分解树T(4,2,2)表示,如图2所示. 图2 参数化分解树 T(4,2,2)示意图 Fig.2Schematic diagram of parameterized decomposition treeT(4,2,2) 2控制流二次平展混淆方法 2.1基本思想 文献[12]中基于参数化分解树的控制流平展混淆方法的基本思想如下:首先根据给定的参数d、h、l构建参数化分解树,但在构建参数化分解树过程中,当某个节点是由X块合并生成的节点(组合块)时,即使该节点所处的层小于h,也不再对该节点做进一步细化分解,即深层不作为问题.然而,深层不作为在一定程序上削弱了混淆后代码的复杂性和混淆种类的多样性,从而降低逆向工程的难度.然后,遍历该参数化分解树,用一个while-switch 循环选择结构统筹整棵树.随着while-switch 循环选择结构中case语句数量的增加,混淆后的代码的执行开销也将大大增加. 为了解决上述方法的深层不作为问题和减少混淆后代码的执行开销,文中在文献[12]参数化分解树中引入组合块,进而提出了基于参数化分解树的控制流二次平展混淆方法.其基本思想如下: (1)根据给定的参数d、h、l分解细化代码块,构建参数化分解树. (2)遍历该参数化分解树,用一个while-switch 循环选择结构统筹整棵树.其中 while-switch 循环选择结构中的case语句由参数化分解树中的节点平展生成;在遍历参数化分解树时,如果某个节点处在第1层,并且在以该节点为根节点的子树中,除根节点外的所有节点包含的case语句数量之和大于等于w(w为自然数),那么需要增加一个while-switch循环选择结构统筹该子树(不包括根节点所产生的case语句),使得该子树中所有的代码段都处于并列位置,拥有共同的前驱节点和后继节点,这一过程称为二次平展混淆. 经过控制流平整后的程序,每个代码段的放置不必遵守执行的顺序,其控制逻辑由一个派遣变量执行决定,从而达到模糊程序控制逻辑、隐藏程序控制流的目的. 例如,当参数值取d=4、h=2、l=2、w=3时,对图1构建参数化分解树(如图2所示),然后用while-switch循环选择结构统筹整棵树(如图3所示).由于以图2中A3为根节点的子树中,除根节点外的所有节点包含的case语句(即图3虚线框中的case语句)数量之和为4(case C5、C6、C7和C8),大于w,因而在图3虚线框中,增加一个while-switch循环选择结构统筹以A3为根节点的子树(不包括根节点所产生的case语句).图3中变量swVar为派遣变量,决定switch的下一跳路径. 图3 混淆后控制流示意图 文中在构建参数化分解树时,引入了组合块,以解决文献[12]中出现的深层不作为问题;此外,文中还对满足一定条件的节点进行二次平展,相比于文献[12]减少了执行开销. 2.2节点平展算法 算法输入:参数化分解树的节点、派遣变量、节点入口值和出口值.其中节点入口值是指进入执行该节点所在代码块的派遣变量值,节点出口值是指离开该节点所在代码块的派遣变量值. 算法输出:混淆后代码. TransFormControl(node,swVar,entry,exit) {(1)根据节点的入口和出口值生成该节点所关联的各子节点的入口和出口值,其中第一个子节点的入口值为该节点的入口值,最后一个子节点的出口值为该节点的出口值,其他子节点的出口值随机生成,入口值为前一个子节点的出口值. (2)随机打乱子节点的物理顺序. (3)按顺序访问子节点,根据节点的类型实施对应的混淆算法,即TransformY(子节点,派遣变量,子节点入口值,子节点出口值),其中Y代表X块混淆或组合块混淆.} 2.2.1X块混淆算法 X块可以是基本块、if块、while块、do while块、for块或switch块.文中仅给出if块混淆算法,其他5种块可以根据if块混淆算法修改得到,此处不再赘述.if块混淆算法输入为if块节点、派遣变量、节点入口值和出口值,输出为混淆后代码. TransformIF(if_node,swVar,entry,exit) {then_entry=Unique_number()∥随机生成then分支入口 else_entry=HasElse?Unique_number():exit ∥如果有else语句,则随机生成入口,否则else_entry的值为if_node节点的出口 ⟹“case”⊕entry⊕“:{”∥混淆后的case语句,⟹和⊕分别表示输出和字符串连接 ⟹“if(”⊕if_condition⊕“)” ∥if_condition是if块的判断条件 ⟹swVar⊕“=”⊕then_entry⊕“;”∥如果if块的条件为真,派遣变量的值是then分支的入口 ⟹“else”⊕swVar⊕“=”⊕else_entry⊕“;”∥如果if块的条件为假,派遣变量的值是else分支的入口 if(countcase(if_node)>=w&&layer(if_node)==1) ∥满足条件进行二次平展 ⟹swVar⊕“=”⊕then_entry⊕“;” ⟹“while(”⊕swVar⊕“!=”⊕exit⊕“){” ⟹“switch(”⊕swVar⊕“){” TransFormControl(then_node,swVar,then_entry,exit); ∥对then_node做更深层的混淆 if(HasElse)∥如果有else分支 TransFormControl(else_node,swVar,else_entry,exit); ∥调用节点平展算法对else_node做更深层的混淆 endif ⟹“} }” ⟹“break;}” else ⟹“break;}” TransFormControl(then_node,swVar,then_entry,exit); if(HasElse)∥如果有else分支 TransFormControl(else_node,swVar,else_entry,exit); ∥调用节点平展算法对else_node做更深层的混淆. endif endif} if块混淆算法的主要思想如下: (1)随机生成then子节点和else子节点的入口值,它们的出口值均等于 if 块的出口值. (2)提取if节点的判断条件,构造并输出一个case分支,实现源程序中if节点条件的判断功能. (3)如果源程序中的if 节点处于第1层,并且以if节点为根节点的子树中,除根节点外所有节点的case语句数量之和不小于w,那么增加一个while-switch循环选择结构统筹该子树(除根节点外),然后调用节点平展算法对 then子节点和 else 子节点做更深一层的混淆;否则调用节点平展算法对then节点和else节点做更深一层的混淆. 2.2.2组合块混淆算法 组合块混淆算法的主要思想如下: (1)以组合块节点Com_node作为输入,若节点不需要更深层的混淆,就把组合块作为基本块处理. (2)如果组合块节点处于第1层,并且以组合块Com_node为根节点的子树中,除根节点外的所有节点的case语句数量之和不小于w,则增加一个while-switch 循环选择结构统筹该子树(除根节点外),然后调用节点平展算法做更深一层的混淆;否则调用节点平展算法做更深一层的混淆. 3性能比较分析 3.1理论分析 在文献[12]中,由X块合并生成的节点被当作基本块处理,不能再进一步分解细化,即出现深层不作为问题.如图4中,当d=2、h=2、l=2时,A2在第2层分解时被当作基本块处理,不再进一步分解细化,出现不作为问题.实际上,在进行第2层分解时,A2可进一步分解为A2,1和A2,2.而文中算法增加了组合块,很好地解决了深层不作为问题. 由于文中混淆方法能根据设定不同的深度、广度和粒度的上界生成不同的参数化分解树,并引入二次平展混淆,使得变换后的代码更加多样化,从而更有效地解决混淆老化问题,因此,相比于传统控制流平展混淆方法[10]和基于参数化分解树的控制流平展混淆方法[12],文中混淆变换方法的整体弹性[4]更强,从而增加了反编译及逆向工程的难度. 图4 代码块2 文中混淆方法会对满足一定条件的节点进行二次平展,即增加一个while-switch循环选择结构统筹以该节点为根节点的子树(不包括根节点所产生的case语句).如图3所示,虚线框中所包含的while-switch循环选择结构是进行二次平展时增加的,用来统筹case C5、case C6、case C7和case C8.一般情况下,如果要为值为Ci的派遣变量找到匹配的case Ci,则需要在整个参数化分解树中查找.但如果所匹配的case Ci由二次平展所统筹,那么只需要在二次平展所统筹的范围内查找,而无需在整个参数化分解树中查找,从而减少判断次数.图3中当派遣变量swVar=C6时,需要为派遣变量查找匹配的case,此时派遣变量swVar要先与二次平展中的while条件和switch条件各比较1次,接着同case C5比较1次,最后与case C6比较1次;但如果去掉虚线框中的while-switch循环选择结构,即不进行二次平展,那么要为派遣变量swVar=C6找到匹配的case语句,就需要先与第1次平展中的while条件、switch条件、case C1、case C2、case C3、case C4、case C5和case C6各比较1次,共需要比较8次.由此可知,与文献[12]方法相比,文中混淆方法因引入了二次平展而减少了派遣变量匹配时的比较次数,从而降低了执行开销. 3.2实验对比 选取八皇后程序、插入排序程序、基数排序程序、快速排序程序和选择排序程序,分别编号为1-5,代码混淆前的运行时间分别为t1-t5,满足t1 由于在方法2中,当对某个节点进行划分时,如果实际代码块大于广度上界d,则可能出现深层不作为问题,为了不影响实验性能对比,假设广度上界d足够大.另外,在方法1中,如果某个节点增加一个while-switch循环选择结构,就增加两次比较,即while表达式和switch平展表达式,为了保证混淆算法的性能,w取值应大于或等于3,本实验选取w=3.实验结果如图5及表1所示. 图5 经过不同方法混淆后代码的平均执行时间 程序执行开销是衡量一个混淆方法性能好坏的重要指.由图5可以看出,代码经文中混淆方法变换比经方法2变换所需要的平均执行时间更少.这是由于文中方法引入了二次平展,减少了平均比较次数,从而减少执行时间开销. 表1显示,经过方法1与方法2变换后的代码拥有相同个数的case语句,说明这两种方法具有相同的潜能[4].另外,对于程序4,当(深度,粒度)取为(2,1)和(2,2)时,经方法1和方法2变换后的代 码的平均运行时间相同.这是由于此时方法1在程序4的混淆过程中并未出现二次平展,因而变换后的代码与采用方法2变换后的代码相同.但当(深度,粒度)取为(3,1)、(3,2)和(4,2)时,由于方法1在程序4的混淆过程中出现了二次平展,因而变换后代码的平均运行时间低于经方法2变换后代码的平均运行时间. 表1 程序4和程序5的实验数据 选取选择排序程序、快速排序程序、统计素数个数程序、基数排序程序和堆排序程序,并将其编号为1-5,代码混淆前的圈复杂度[17]分别为M1-M5,满足M1 表2 执行方法1和方法3后代码块的圈复杂度 1)此处为(广度,深度,粒度). 由表2可知,经方法1混淆不仅可以生成不同圈复杂度的代码,而且生成的代码圈复杂度比经方法3混淆所产生的代码大,因而方法1较方法3增加了反编译及逆向工程的难度.另外,程序1和3经方法3混淆后的执行时间开销大幅度增加,因此,方法3不适用于混淆性能要求高的程序;而经方法1的调节参数混淆后产生开销相对较小的代码,因而方法1相比方法3应用范围更广. 4结论 文中提出了一种基于参数化分解树的控制流二次平展混淆方法,并对其性能进行了分析和比较.结果表明:与基于参数化分解树的控制流平展混淆方法相比,文中方法有效地减少了执行时间开销和解决深层不作为问题;与传统的控制流平展混淆方法相比,文中方法增加了反编译及逆向工程的难度,同时扩大了应用范围.优化参数d、h、l和m使混淆强度和执行时间开销达到更好的平衡,是今后研究的重点. 参考文献: [1]Business Software Alliance.Eighth annual BSA and IDC global software piracy study [R/OL].(2011-05-10) [2013-12-28].http:∥globalstudy.bsa.org/2010/downloads/study_pdf/2010_BSA_Piracy_Study-Standard.pdf. [2]冯登国,张敏,张妍,等.云计算安全研究 [J].软件学报,2011,22(1):71-83. Feng Deng-guo,Zhang-Min,Zhang-Yan,et al.Study on cloud computing security [J].Journal of Software,2011,22(1):71-83. [3]张倩,齐德昱.面向服务的云制造协同设计平台 [J].华南理工大学学报:自然科学版,2011,39(11):75-81. Zhang Qian,Qi De-yu.Service-oriented collaborative design platform for cloud manufacturing [J].Journal of South China University of Technology:Natural Science Edition,2011,39(11):75-81. [4]Collberg C,Thomborson C.A taxonomy of obfuscating transformations [R].Auckland:Department of Computer Science,University of Auckland,1997. [5]蒋华,刘勇,王鑫.基于控制流的代码混淆技术研究 [J].计算机应用研究,2013,30(3):887-889,905. Jiang Hua,Liu Yong,Wang Xin.Code confusion technology research based on control flow [J].Application Research of Computers,2013,30(3):887-889,905. [6]Balachandran V,Emmananuel S.Potent and stealthy control flow obfuscation by stack based self-modifying code [J].IEEE Transactions on Information Forensics and Security,2013,8(4):669-679. [7]付剑晶,王珂.软件迷惑变换的鲁棒性量化评价 [J].软件学报,2013,24(4):730-748. Fu Jian-jing,Wang Ke.Quantitative evaluation on the robustness of software obfuscation transformation [J].Journal of Software,2013,24(4):730-748. [8]Wang C X.A security architecture for survivability mechanisms [D].Virginia:Department of Computer Science,University of Virginia,2000. [9]Chow S,Gu Y,Johnson H,et al.An approach to the obfuscation of control-flow of sequential computer programs [C]∥Proceedings of the 4th International Conference on Information Security.London:Springer-Verlag,2001:144-155. [10]Laszlo T,Kiss A.Obfuscating C++ programs via control flow flattening [J].Annals Universitatis Scientarum Buda- pestinensis de Rolando Eotvos Nominatae,Sectio Computatorica,2009,30:3-19. [11]杭继春.一种基于控制流平整的代码混淆算法研究与实现 [D].西安:西北大学信息科学与技术学院,2010. [12]董劲麟.面向白盒子安全的代码混淆方法及支撑系统的研究与实现 [D].广州:华南理工大学计算机科学与工程学院,2012. [13]王一宾,陈意云.一种基于流图变换的代码迷惑算法 [J].计算机工程与应用,2012,48(11):60-64,81. Wang Yi-bin,Chen Yi-yun.Algorithm of code obfuscation technology based on flow graphs converted [J].Computer Engineering and Applications,2012,48(11):60-64,81. [14]赵楷.基于控制流平展化代码变形技术的研究 [D].哈尔滨:哈尔滨工业大学深圳研究生院,2009. [15]Hou T W,Chen H Y,Tsai M H.Three control flow obfuscation methods for Java software [J].IEE Procee-dings Software,2006,153(2):80-86. [16]王一宾,陈意云.代码迷惑技术研究进展 [J].吉林大学学报:信息科学版,2008,26(4):386-390. Wang Yi-bin,Chen Yi-yun.Progress of research on code obfuscation technology [J].Journal of Jilin University:Information Science Edition,2008,26(4):386-390. [17]McCabe T J.A complexity measure [J].IEEE Transactions on Software Engineering,1976,SE-2(4):308-320. Parameterized Decomposition Tree-Based Obfuscation Method with Double Flattening Control Flow ZhouNa-qinQiDe-yu (Research Institute of Computer Systems,South China University of Technology,Guangzhou 510006,Guangdong,China) Abstract:Aiming at the security problem of software white box, an improved parameterized decomposition tree-based obfuscation method with double flattening control flow is put forward.On the basis of given upper bounds of depth, breadth and granularity, the method builds a decomposition tree, coordinates the whole tree with a cycle selection structure named while-switch, and then applies double flattering to relevant nodes that satisfy certain conditions. Experimental results indicate that, in comparison with the flattening obfuscation method of control flow on the basis of parameterized decomposition tree, the proposed method reduces the execution expense and solves the deep nonfeasance problem; and that, in comparison with the traditional method only with flattening control flow, the proposed method increases the difficulty in decompilation and reverse engineering. Key words: software protection;control flow flattening;code obfuscation;reverse engineering;decomposition tree;security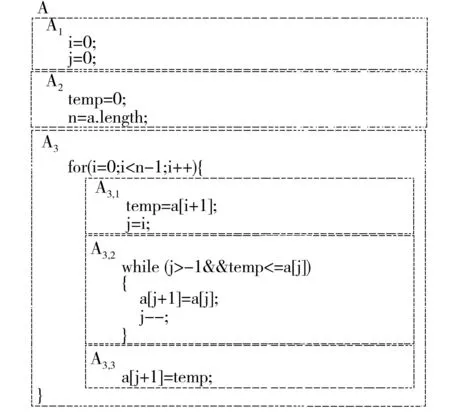

 猜你喜欢
无线互联科技(2016年13期)2017-01-10电脑知识与技术(2016年18期)2016-11-02科技视界(2016年22期)2016-10-18湖南大学学报·自然科学版(2015年10期)2015-11-30科技与创新(2015年10期)2015-07-07
猜你喜欢
无线互联科技(2016年13期)2017-01-10电脑知识与技术(2016年18期)2016-11-02科技视界(2016年22期)2016-10-18湖南大学学报·自然科学版(2015年10期)2015-11-30科技与创新(2015年10期)2015-07-07
