
基于四层结构的风险建模及自动发现
2015-12-20 06:58李石君
计算机工程与设计 2015年1期
陈 丹,李石君
(武汉大学 计算机学院,湖北 武汉430072)
0 引 言
利用计算机技术进行税收风险[1]评估,不仅能够提高工作效率,而且可以降低税收征管成本。但是,目前我国的税收信息化管理仍存在很多问题[2,3],不能有效满足税收风险评估的需要。文献 [4]中设计的税收分析系统虽然在一定时期内能够有效堵塞税收征管漏洞,但是没有考虑到税收政策的改变带来的影响,其设计的风险指标不能实现动态更新和添加,这将导致不能及时进行税收风险评估。文献 [5]中通过引入ILog JRules业务规则引擎和Infor-Flow 工作流,将评估方法逻辑转化为业务规则,在一定程度上解决了税收政策不断变化的问题,但是其设计的业务规则过于繁琐。为满足税收政策不断变化以及系统使用的灵活性和简便性的需求,本文提出一种基于四层结构的风险评估模型,并用巴克斯-诺尔范式定义其语法规则,使其业务规则更简洁和精确,更易于被不同的用户接受。根据分层的思想建立的税收风险评估模型去掉了紧耦合的枷锁,整个体系都是松耦合的,在实际应用中也取得了较好的效果。
1 风险评估模型
1.1 风险评估模型定义及巴克斯-诺尔范式表示
为了便于进行风险评估和满足业务的需求,本文提出一种基于四层结构的风险评估模型。该风险评估模型主要分为4级:因子、指标、模型和风险自动发现引擎。在风险评估模型的基础上,建立了用巴克斯-诺尔范式形式化定义的因子表达式、指标取数规则和指标预警区间语法规则的语言。其中,巴克斯-诺尔范式 (Backus-Naur form)是由John Backus初次引入的一种形式化符号来描述给定语言的语法[6,7]。它是一种表示上下文无关语法的语言,用于形式化定义语言语法的数学方法[8]。
风险评估模型的层次结构如图1所示。
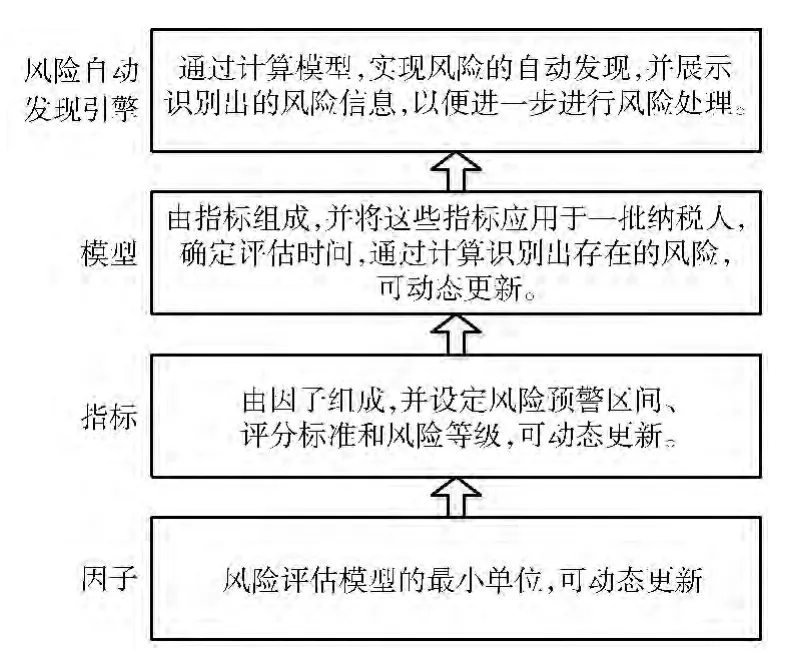
图1 风险评估模型的层次结构
因子是风险评估模型的第1 级,是整个模型的基础;指标是风险评估模型的第2级,由因子组成,指标确定了风险的评判标准,决定了能识别出的风险数量,以及风险识别的准确率;模型是风险评估模型的第3级,由指标组成,通过计算模型可以识别出存在的风险信息;风险自动发现引擎是风险评估模型的第4级,通过计算建立的模型,可以实现风险自动发现,并展示风险信息,以利于及时进行风险处理。
1.1.1 因子
首先给出因子的定义。
定义1 因子是与数据库直接关联的元素。以F 表示所有的因子集合,f∈F 表示某个具体的因子。
从图1可知,因子是风险评估模型的最小单位,是风险评估模型的第1级。每一个因子都有一个唯一的名称和表达式,下面给出因子表达式的定义。
定义2 因子与数据库关联的规则,称为因子表达式。以f.E 表示某因子f 的表达式,其中f∈F。
因子表达式具有多种形式,我们将其归纳为以下两种:①数据库中一个表的某个字段或对某个字段的求和、求平均、求总数等;②多个字段 (或字段的求和、求平均、求总数等)的相加或相减,并且这些字段可能在不同的表中。基于因子表达式的特点,我们用BNF范式将其语法规则形式化定义为:
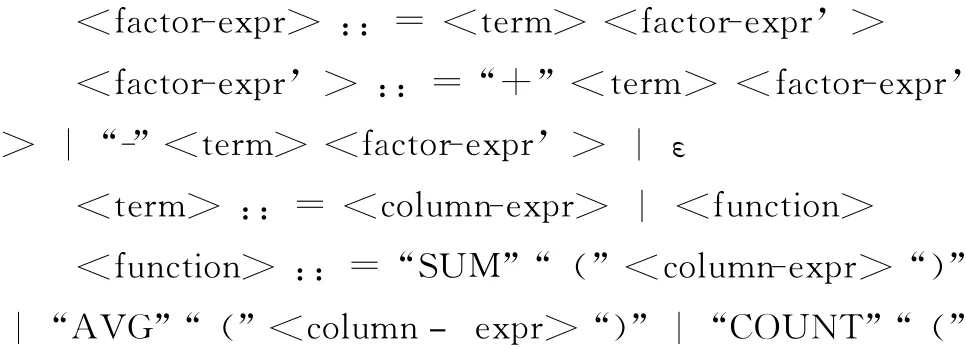
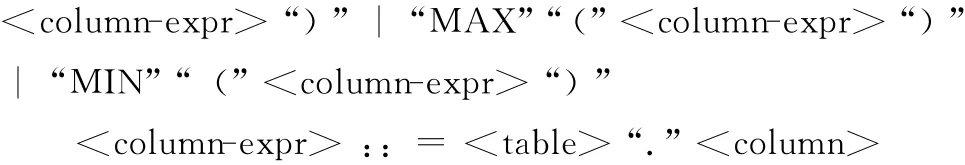
其中,factor-expr是语法的起始符,代表因子表达式。factor-expr和factor-expr’的产生式规则组合表示一则加减法运算公式,term 非终结符代表组成运算公式的项,而factor-expr’是为消除左递归而设置的非终结符。columnexpr非终结符代表字段的表达式,由表名table和字段名column组成,是term 的一种形式,其中table和column都有其各自的产生式规则。function是非终结符,代表SQL函数,包括求和、求平均、求总数、求最大值和求最小值。
为了能更好地理解因子,下面给出因子的一个例子。
例1:“年度营业收入”因子。“年度营业收入”因子取值于 《利润表》中的营业收入,根据BNF范式形式化定义的语法规则,其因子表达式为:SUM (NSPG_CW _LRBA.d1),其中NSPG_CW _LRBA 代表数据库中的利润表,d1代表利润表中的营业收入字段,SUM 是对一年的营业收入求和。
1.1.2 指标
指标,是在因子的基础上建立的,是风险评估模型的第2级。参考文献 [9,10],我们将指标定义为:
定义3 指标是反应税收风险状况,进行税收风险评估的规则或标准。以I 表示所有的指标集合,i∈I 表示某个具体的指标。
指标有2个主要的属性:取数规则和预警区间,下面给出这些属性的定义。
定义4 我们把为进行风险评估而设定的公式或规则,称为指标的取数规则。以i.R 表示某个指标的取数规则,其中i∈I。
定义5 指标的预警区间是决定风险评估对象是否存在风险的依据。以i.W 表示某个指标的预警区间,其中i∈I。
根据业务需求,指标的取数规则主要有两种形式:①由因子组成的一个或多个四则运算公式;②由因子组成的一个或多个比较运算公式。我们用BNF范式形式化定义指标取数规则的语法规则为:


其中,index-rule非终结符是起始符号,代表指标的取数规则,rule代表一个四则运算公式或者比较运算公式,在index-rule的产生式中,符号 “;”用来分隔相邻的公式。expression非终结符的产生式规则表示四则运算公式的语法规则,其中expression’和term’是为消除左递归而设置的非终结符,factor’非终结符代表组成运算公式的因子,而factor’产生式规则中的factor非终结符代表风险评估模型中的因子。digit非终结符代表数字 (整数或小数),并有其自己的语法规则。sign是非终结符,代表算术比较算子。
由定义5可知,指标的预警区间决定风险评估对象是否有风险。其主要有两种形式:①含有字母X 的比较公式,其中X 表示根据取数规则计算出的结果;②含有因子的比较公式。同样,我们也用BNF范式定义了预警区间的语法规则,如下:

其中,warn-interval非终结符是起始符,代表预警区间表达式,X-expr表示含有字母 “X”的比较公式,F-expr代表含有因子的比较公式。X-expr’的产生式规则定义了含有字母X 的比较公式的各种形式,F-expr产生式中的符号 “&”和 “|”分别表示 “并”和 “或”的意思。expression和sign非终结符的产生式与指标取数规则的语法规则中的一致。另外,sign1非终结符表示大于或者大于等于算术比较算子,sign2非终结符表示小于或者小于等于算术比较算子。
为了更好的阐述指标,我们给出指标的2个例子。
例2:“营业税计税依据与收入、预收配比”指标。企业缴纳营业税依据与当期 (销售)收入、预收账款净增加额合计数基本一致,否则存在未按规定申报营业税的问题。当期 (销售)收入、预收账款净增加额合计数通过用年度营业收入加上预收账款年末数与预收账款年初数之差,再依次减去建安分包金额合计和增值税计税依据销售额计算得出,所以营业税计税依据与收入、预收配比通过企业年度营业税计税金额除以当期 (销售)收入、预收账款净增加额合计数计算得出。当营业税计税依据与收入、预收配比不为1时为非正常,比例在0.8 (含)至1的积3分,比例低于0.8的积6分,通过专家打分的方式,该指标被评为二级指标。对这段文字进行分析后,可以得出该指标的取数规则为:企业年度营业税计税金额/ (年度营业收入+(预收账款年末数-预收账款年初数)-建安分包金额合计-增值税计税依据销售额),以及预警区间为:0.8<X<1;X<0.8。
例2是指标取数规则和预警区间第一种形式的一个示例,下面通过例3来阐述指标取数规则和预警区间的第二种形式。
例3:“住房公积金未按标准扣除风险”指标。比对纳税人个人所得税明细申报中收入总额与住房基金扣除额,如果超过规定标准和限额,存在超标准扣除住房公积金的风险。住房公积金扣除标准需小于等于收入总额乘以12%,以及住房公积金扣除限额需小于等于1370元,如果住房公积金扣除标准大于收入总额乘以12%,或者住房公积金扣除限额大于1370元,则存在住房公积金超标扣除风险。通过分析和提取关键信息,并参照定义的BNF语法规则,得出其取数规则为:住房公积金扣除标准≤收入总额×12%;住房公积金扣除限额≤1370。以及预警区间为:住房公积金扣除标准>收入总额×12% |住房公积金扣除限额>1370。
1.1.3 模型
定义6 我们将模型定义为三元组M= (I,P,t),其中I、P 分别为指标和纳税人信息的非空可数有限集,t表示评估时间。
模型是在指标的基础上建立的。通过从指标集中选择一些指标,然后将这些指标应用于一批纳税人,确定评估时间,可以建立一个模型。下面,给出模型的一个例子。
例4:模型示例。指标集合I= {营业税计税依据与收入、预收配比,住房公积金未按标准扣除风险},纳税人信息集合P= {纳税人1,纳税人2,纳税人3,纳税人4},评估时间t=2013年。该模型用来评估纳税人1、纳税人2、纳税人3、纳税人4和纳税人5在2013年是否存在营业税计税依据与收入、预收配比风险和住房公积金未按标准扣除风险。
1.1.4 风险自动识别引擎
风险评估模型的第4级是风险自动识别引擎,在依次建立了因子库、指标库和模型库后,通过计算模型,可以实现风险自动识别,并将识别出的风险信息以列表或图表的形式展示,以便进一步进行风险处理。
1.2 算法描述
根据风险评估模型的特点,以及BNF范式定义的语法规则,本文提出一种高效的风险自动发现算法RAD (risk automatically discover)。
算法1:风险自动发现算法RAD(I,P,t)
描述:本算法是通过计算一个指标集合为I,纳税人信息集合为P 和评估时间为t 的模型,判断被评估纳税人中是否存在税收风险,并返回风险信息集合R。
输入:指标集合I,纳税人信息集合P 和评估时间t。
输出:风险信息集合R。
1.R=;符号集合S= {>,<,≥,≤,=,≠};
2.While(I≠和P≠)Do
3. For I中的每一个指标i Do
4. For P 中的每一个纳税人p Do
5. If i.R 中不包含集合S 中的字符THEN
result1=CI(i.R,p,t);//调用指标计算算法CI(Calculate Index)
6. result2 =WI(i.W,i,result1,p,t)//调用预警区间计算算法WI(Warn Interval)
7. If result2≠THENresult2加入R 中;
例4.MARY:What is a lie!Now you're talking in riddles like Jamie. Edmund! Don't! There's your father coming up the steps now. I must tell Bridget.
8. End For
9. End For
10.End While
11.Return R;
算法RAD 主要由初始化、模型计算和结果返回3个部分构成。在模型计算部分,调用了子算法CI(i.R,p,t)和WI(i.W,i,result1,p,t)。CI算法主要是计算指标的取数规则i.R,该算法要求i.R 的形式必须为四则运算公式,如例2中所示。对于例3中的形式,只需调用子算法WI,即可判断被评估对象是否存在税收风险。
算法2:指标计算算法CI(i.R,p,t)
描述:本算法主要计算指标的取数规则i.R,并返回计算结果result1。
输出:指标的计算结果result1。
1.result1 =;
2.解析出i.R 中的所有因子,得到因子集合F;
3.For F 中的每一个因子f Do
4. factorValue=CF(f,p,t);//调用因子计算算法CF (CalculateFactor)
5. i.R.replace(f,factorValue);//用factorValue替换i.R 中的因子f
6.End For
7.计算i.R,将计算结果赋值给result1;
8.Return result1;
子算法CI的关键思想在于,需要求出组成指标取数规则的每一个因子的值,然后用因子的值来替换因子,当所有的因子都被替换后,就可以按照四则运算法则进行计算,得出最后结果。
算法3:因子计算算法CF(f,p,t)
描述:本算法主要根据纳税人信息p 和评估时间t 计算因子表达式f.E,并返回计算结果factorValue。
输入:因子f,纳税人p,评估时间t。
输出:因子计算结果factorValue。
1.factorValue=;
2.解析f.E,计算f.E 中的SUM、AVG、COUNT、MAX、MIN 函数;
3.解析出f.E 的所有字段,得到字段集合C
4.For C 中的每一个字段c Do
5. 根据p 和t,取得字段值columnValue;
6. f.E.replace(c,columnValue);
7.End For
8.计算f.E,将计算结果赋值给factorValue;
9.If factorValue<0Then
factorValue =“(”+factorValue +“)”;
10.Return factorValue;
因子计算算法CF的思想与CI算法相似,但比CI算法复杂。因子表达式中可能含有SUM、AVG 等函数,我们需要先解析出SUM、AVG 等函数,求出SUM、AVG 等函数的值。步骤4至步骤7为求解因子表达式中字段的值,步骤8是根据四则运算法则计算f.E,得到因子值factor-Value。如果最后计算出的因子值为负数,我们需要加上括号,以利于CI算法的调用。
算法4:预警区间算法WI(i.W,i,result1,p,t)
描述:本算法通过比较指标取数规则计算结果result1与设定的预警值,或通过计算和分析区间范围,得出风险评估结果。
输入:指标预警区间i.W,指标信息i,取数规则计算结果result1,纳税人信息p 和评估时间t。
输出:风险评估结果riskResult。
1.riskResult=;风险标识字段flag=false;
2.If i.W 中包含字符X Then
比较result1与i.W,如果result1在区间范围内,则flag=true;
3.Else flag=WI1(i.W,p,t)
4.If flag==true then
将风险信息存入riskResult中;
5.Return riskResult;
指标的预警区间主要分为两种形式:①含X 的比较公式,如例2所示;②含因子 (不含X)的比较公式,如例3所示。对于第1种形式,我们需要判断指标取数规则计算结果result1是否在设定的区间范围内,如果是,则表明存在风险,需记录风险信息。对于第2种形式,需调用预警区间子算法WI1进行计算和比较。
算法5:预警区间子算法WI1 (i.W,p,t)
描述:本算法主要处理形如 “A>B*10%|C>1730”形式的预警区间,通过计算和比较,并进行逻辑与和逻辑或操作,得出最后结果 (true或false)。
输入:指标的预警区间i.W,纳税人信息p 和评估时间t。
输出:风险标识字段flag。
1.flag=false;计算结果集合resultList=;符号集合signList=;
2.将i.W 根据字符 “&”和 “|”分割,得到字符串数组splitStrs。
3.For splitStrs中的每个字符串splitStrsiDo
4. If splitStrsi不是字符 “&”或 “|”then
计算splitStrsi,将计算结果 (true或false)添加到splitStrsi中;
5. Else将字符 “&”或 “|”加入到signList中;
6.End For
7.组合resultList 和signList,形成一个新的字符串
resultString;
8.If resultString 中不包含字符 “&”和 “|”Then
flag =resultString;
9.Else根据逻辑运算规则,计算resultString,将计算结果存于flag中;
10.Return flag;
2 系统实现及结果分析
2.1 系统实现
在风险评估系统的实现过程中,我们使用了当前最为流行的面向对象的程序设计语言之一——Java,使用的开发工具为MyEclipse 8.5,应用服务器为BEA 的WebLogic 10,数据库管理系统为Oracle 11g。目前,该模型已投入到某地税局的实际工作中。
2.2 结果分析
在项目的实际应用中,指标主要有11大类,包括营业税风险指标、城市维护建设税风险指标、教育费附加风险指标、个人所得税风险指标、土地增值税风险指标、土地使用税风险指标、房产税风险指标、印花税风险指标、企业所得税风险指标、建安业风险指标和电信业税收风险指标,我们用字母A-K 依次表示这11类指标。我们将这11类指标分别应用于1000 名纳税人,表1 显示了风险评估结果。
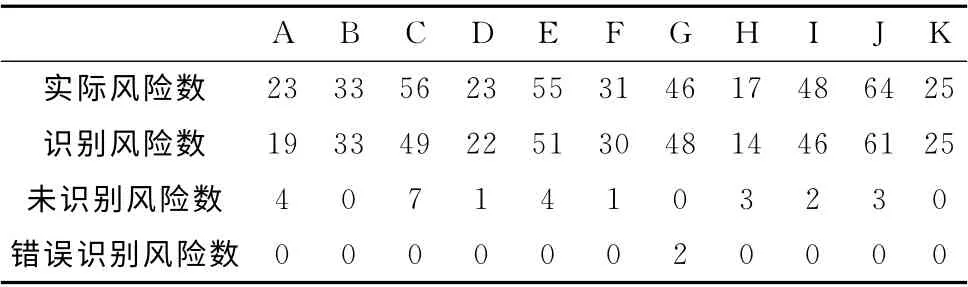
表1 风险评估结果
表1中,实际风险数是通过实地考察和税务核查确定的风险数量;识别风险数是风险自动发现引擎识别出的风险数量;未识别风险数是风险自动发现引擎未能识别出而实际上是风险的数量;错误识别风险数是风险自动发现引擎将不是风险的信息识别为风险信息的数量。从表1可知,该风险自动发现引擎具有较高的风险识别准确率,其准确率几乎达到100%
指标的预警区间决定了能识别出的风险数量,当扩大或缩小指标的预警区间时,识别出的风险数量都有着明显的变化。表2和表3分别显示了扩大或缩小指标的预警区间后风险评估结果。
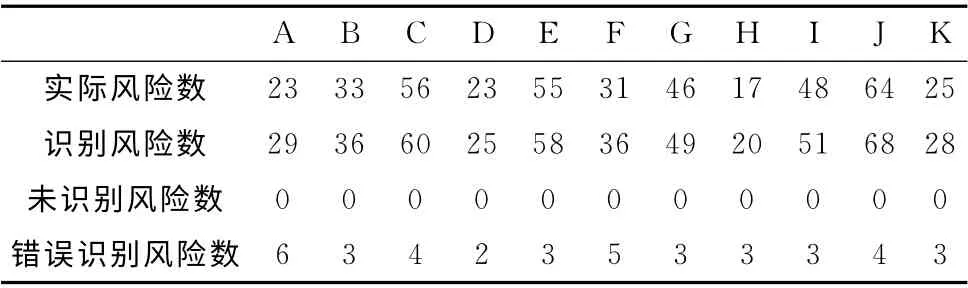
表2 扩大预警区间后风险评估结果
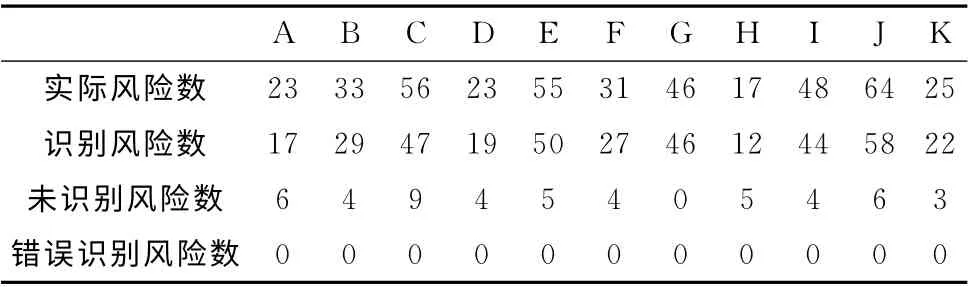
表3 缩小预警区间后风险评估结果
通过对比表1和表2中的数据可知,扩大指标的预警区间后,识别出的风险数量有了明显的增加,但是有些识别出的风险,并不是实际存在的风险,提高了风险的误判率。同样,通过对比表1和表3中的数据可知,缩小指标的预警区间后,识别出的风险数量有着明显的减少,对一些实际存在的风险,并未能识别出来,降低了风险评估的正确率。因此,指标预警区间设置的合理性,直接影响风险评估结果的正确性。
3 结束语
本文在传统税收风险评估系统的基础上,提出了一种基于四层结构的税收风险评估模型,该风险评估模型包括因子、指标、模型和风险自动发现引擎4 层,其中因子组成指标,指标组成模型,通过计算模型实现风险的自动发现。文中分别给出了因子、指标、模型的定义,并用BNF范式表示了因子取数规则、指标取数规则和预警区间的语法规则。应用该语法规则提出了一种高效的风险自动发现算法,并在实际项目中验证了算法的正确性,以及模型的可行性和灵活性。目前,本模型已编制成软件,投入到实际项目当中。下一步工作是优化指标预警区间设置的规则,从而提高风险评估的正确率。
[1]LI Hanwen.Discussion on the definition and hazards of tax risk[J].Taxation Research,2008 (8):66-68 (in Chinese).[李汉文.刍议税收风险的定义及危害 [J].税务研究,2008(8):66-68.]
[2]ZENG Changsheng.Analysis of the effective implementation of tax risk management from the perspective of information management optimization [J].Taxation Research,2011 (1):83-86 (in Chinese).[曾长胜.从信息管理优化角度探析税收风险管理的有效实施 [J].税务研究,2011 (1):83-86.]
[3]ZHANG Xin,AN Tifu.Rethink on the present situation of tax informatization in China and international reference [J].Tax and Economic Research,2012 (5):1-13 (in Chinese). [张新,安体富.对我国税收信息化现状的反思与国际借鉴 [J].税收经济研究,2012 (5):1-13.]
[4]WANG Qi.Design and implementation of taxation analysis system [D].Shandong:Shandong University,2010:1-50 (in Chinese).[王祺.税收分析系统的设计与实现 [D].山东:山东大学,2010:1-50.]
[5]GAO Ping,HU Heng,SONG Xingbin,et al.Research application of business rules and workflow management in tax evaluation [J].Computer Engineering and Design,2010,31 (9):2135-2139 (in Chinese).[高萍,胡恒,宋兴彬,等.规则和流程管理在纳税评估系统中的应用研究 [J].计算机工程与设计,2010,31 (9):2135-2139.]
[6]JIANG Ye,GUAN Renchu,LIANG Yanchun.BNF syntax unifying Dmoz and Yahoo syntax and its implementation [J].Computer Engineering and Design,2009,30 (19):4520-4523(in Chinese).[姜冶,管仁初,梁艳春.整合Dmoz和Yahoo标签的BNF文法及其实现 [J].计算机工程与设计,2009,30 (19):4520-4523.]
[7]Alkin Nasuf,Atul Bhaskar,Andy J Keane.Grammatical evolution of shape and its application to structural shape optimisation [J].Structural and Multidisciplinary Optimization,2013,48 (1):187-199.
[8]YUAN Limiao,BAO Guangyu,ZHU Li.Method for formalizing battle management language grammar based on BNF [J].Journal of Military Communications Technology,2010,31(4):35-39 (in Chinese).[袁黎苗,鲍广宇,朱立.一种基于BNF的作战管理语言语法表示 [J].军事通信技术,2010,31(4):35-39.][9]ZHAO Lianwei.Think to construct China’s tax risk identification method system [J].Taxation Research,2012 (7):77-80 (in Chinese).[赵连伟.构建我国税收风险识别方法体系的思考 [J].税务研究,2012 (7):77-80.]
[10]HONG lianpu.Discussion on the construction of tax risk management mechanism [J].International Taxation in China,2011 (3):66-70 (in Chinese).[洪连埔.浅谈税收风险管理机制的构建 [J].涉外税务,2011 (3):66-70.]
猜你喜欢
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
小猕猴智力画刊(2022年3期)2022-03-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
中国外汇(2019年13期)2019-10-10
今日农业(2019年12期)2019-08-13
现代园艺(2017年22期)2018-01-19
Coco薇(2017年11期)2018-01-03
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
火控雷达技术(2016年3期)2016-02-06
