
XQuery并行实现中的任务调度算法
2015-12-20 06:58权跃龙廖湖声高红雨
计算机工程与设计 2015年1期
权跃龙,廖湖声,高红雨
(1.北京工业大学 计算机学院,北京100124;2.北京工业大学 软件学院,北京100124)
0 引 言
利用多核环境提供的并行计算能力和多线程技术提高XQuery语言处理性能是可扩展标记语言 (extensible markup language,XML)数据查询领域的研究热点。任务调度作为XQuery并行实现过程中的一个重要环节,调度策略的选择是影响系统性能的关键因素。针对XQuery函数式语言的特点,充分利用XQuery内在并行性实现任务调度是提高系统整体处理效率的重要途径。研究人员针对并行系统中存在的不同并行方式提出很多调度方法,如基于任务并行的多核环境平台的调度[1];基于线性规划思想,通过将任务并行与数据并行相结合的方式提高系统性能[2];针对多核或集群环境下的任务调度问题,采用任务并行与流水线并行相结合的方式实现任务调度[3-6]。然而,这些算法大多针对并行系统中存在单一或两种并行方式的情况,不能适应XQuery查询请求中3种并行方式同时存在的场景。这些调度算法也不能根据系统负载状态动态决定任务的并行执行策略,满足XQuery并行实现中动态调度需求。
为了更好地解决XQuery并行实现中的任务调度问题,本文从XQuery语言内在并行性入手,提出了一种以任务节点出度和任务执行代价为优先级,结合并行方式选择策略和负载均衡机制的调度算法,达到了提高XQuery并行处理效率的目的。针对XQuery语言中的流水线并行执行方式,建立了一种流水线局部并行自动机模型,利用流水线节拍之间的空闲等待时间实现系统资源的有效利用。
1 动 机
作为一种函数式语言,XQuery程序描述的XML 数据查询请求表现为多个表达式与函数调用的求值。对于相互之间没有数据依赖关系的表达式,其计算次序的改变不会对查询结果产生影响,可以按照任务并行方式进行求值;同时,在XQuery语言描述的查询中,许多计算表达式将作用于数据集的每个元素,具有数据并行特点;而XQuery以序列作为数据模型,使得函数表达式之间又具有流水线方式工作的潜力[7]。
例如对于图1 (a)中的XQuery查询程序,该程序中前两个let子句描述了来自不同XML 文档的查询,相互之间没有数据依赖关系,因此可以作为2个独立的任务,采用任务并行的方式处理;FLWOR 语句作为XQuery语言的核心表达式,用于对其输入数据序列中的每一个元素进行同样的操作处理,而通常其输入数据序列的数据量很大,可以将输入序列划分为多个子序列,利用数据并行的方式处理,对于图1 (a)中第2-4行和第5-8行所示的表达式均可采用数据并行方式处理。此外,一些不同子句之间存在着生产者和消费者关系,前一表达式的输出序列是后一表达式的输入序列,例如图1 (a)中第2 行的for子句从bookstore.xml文档获取元素book,并将结果交给第3行的筛选表达式进行逐个处理。对于这种存在生产者-消费者关系的2个查询任务,可以采用流水线并行的方式进行处理。图1 (b)给出了该查询程序的执行计划。
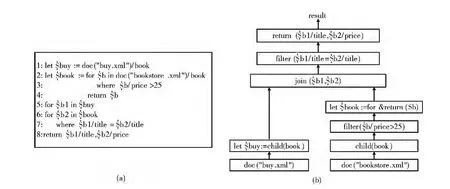
图1 XQuery语言的内在并行性
图1中可以看出XQuery语言存在任务并行、数据并行和流水线并行的内在特性。任务并行和数据并行是两种重要的空间并行技术,对于提高系统的吞吐率具有重要作用。而流水线并行作为一种时间并行技术,能够有效地缩短程序的整体执行时间。充分利用XQuery函数式语言内在并行性,将空间并行技术和时间并行技术相结合提高XQuery语言的查询效率是本文研究的主要动机。
2 任务图模型与设计思想
本节介绍XQuery语言的并行实现框架,并在此基础上给出本文调度算法的任务图模型和算法的设计思想。
2.1 XQuery语言的并行实现框架
图2 给出了XQuery 语言的并行实现框架。在该XQuery并行查询系统中,一个XQuery查询程序经过如下执行过程得到最终查询结果:首先,词法语法分析器对XQuery源程序进行词法分析语法分析,生成XQuery语法树。然后,XQuery语法树经过任务生成器,生成用来描述XQuery查询计划的任务图,任务图中标示出各个任务是否适合流水线并行、数据并行等并行方式以及各个任务节点之间的数据依赖关系。最后,由并行处理引擎结合任务图和对应的XML文档进行计算求值,获得查询结果。其中,并行处理引擎包括调度模块和执行模块两部分:调度模块负责对任务图中当前就绪任务按照调度算法进行调度处理;执行模块负责将调度模块所提交的候选任务进行查询处理。
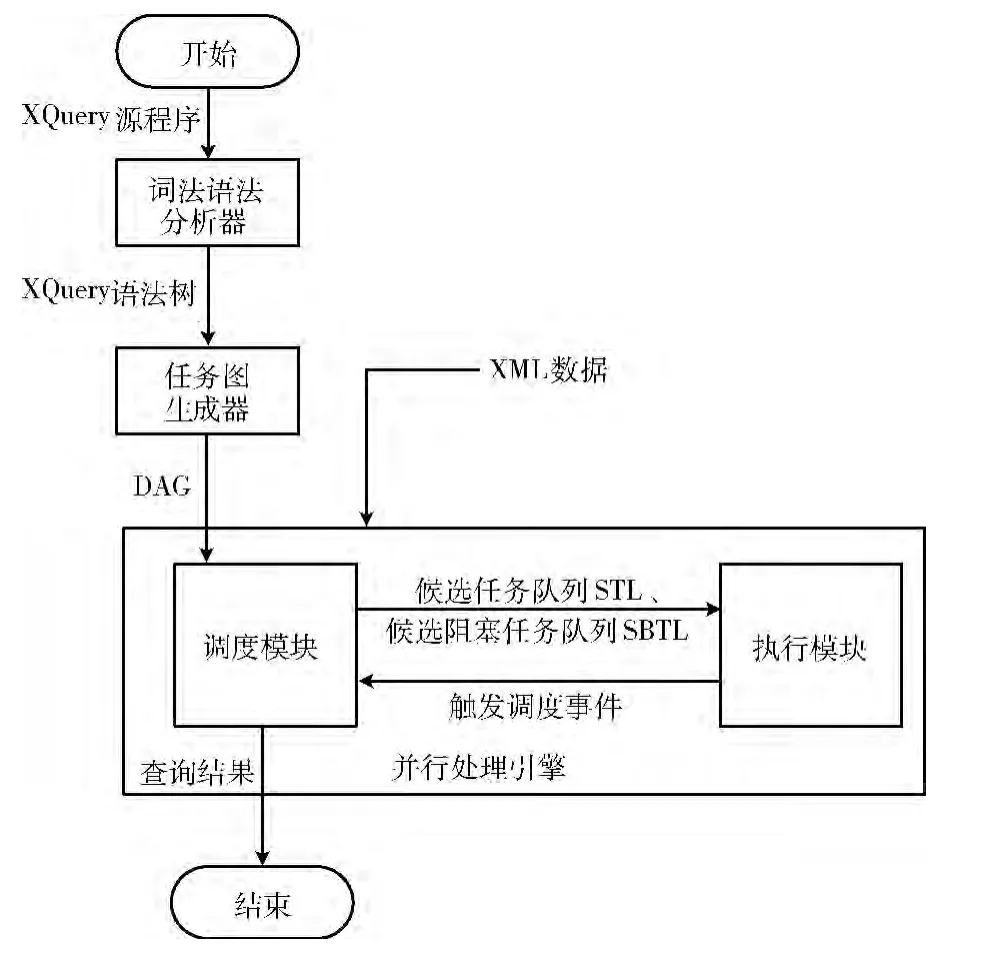
图2 XQuery语言的并行实现框架
2.2 任务图模型
一个XQuery程序的任务图由一组既有前后数据传递约束关系,又有并行关系的多个任务组成,可以通过有向无环图 (directed acyclic graph,DAG)来表示,图3 给出了图1 (a)中XQuery查询程序的DAG 表示形式。XQuery查询的任务图可以表示为一个二元组,DAG= (V,E),这里V= {v1,v2,…,vi,…}表示图中任务节点v 的集合,一个任务节点代表一个可独立运算的任务。vi表示第i个任务。E= {e1,e2,…,ej,…}表示图中有向边e 的集合,e在任务图中表示任务之间的数据依赖关系,弧的方向代表了数据流的方向。ej表示第j 条边。由于算法设计仅考虑共享内存环境,这里忽略任务之间的通信开销。一个XQuery查询程序的任务图可以有多个叶子节点,作为初始就绪任务,但仅有一个根节点,表示查询任务的结束。根据vi描述的查询任务的特征,vi可以有多种并行处理方式。任务节点的定义为
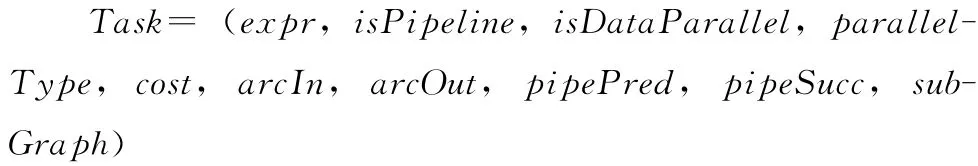
其中,expr是描述该查询任务的表达式;isPipeline和is-DataParallel分别表示能否支持流水线并行和数据并行处理;parallelType表示该任务在调度时选择的执行方式,parallelType取值1、2、3 分别表示任务并行、数据并行和流水线并行;cost是该任务的执行代价;arcIn、arcOut都是有向弧集合,分别表示连接当前任务的前驱后继。pipePred、pipeSucc分别指向流水线中前驱任务和后继任务。由于表达式可能存在嵌套的情况,subGraph 用来表示当前任务包含的子任务。例如图3中的v8节点代表的任务为Task= (child (book),true,true,2,0,{e9},{e7},null,{v7},null)。因为任务并行是并行调度的基础,在图3中所有的节点均适合任务并行方式。其中,v1、v2、v4、v5、v7、v8适合数据并行,v5、v7、v8和v1、v2适合流水线并行。
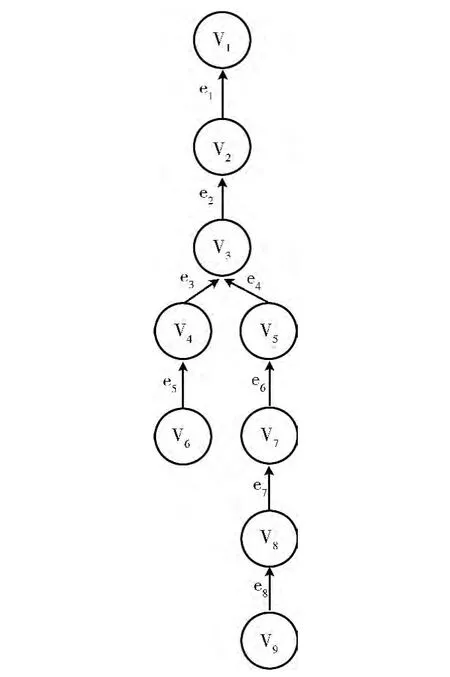
图3 DAG 任务图模型
2.3 设计思想
在XQuery并行实现中,针对DAG 中各个节点之间的数据依赖关系在任务调度开始时已知和任务执行代价在任务就绪时才能计算的特点,采用任务节点出度和执行代价为调度算法中优先级的两个参数。将DAG 中入度为0的任务作为就绪任务存入就绪任务队列,按照依赖度从大到小排列,依赖度相同的按照执行代价从大到小排列。在调度过程中,依次对就绪队列中的任务确定其并行方式,存入候选任务队列。选择任务节点出度和执行代价为优先级能够降低代价模型[7]带来的优先级误差,并能很好的适用于DAG 中任务节点少的场景,保证系统的吞吐率。
在并行方式选择过程中,如果任务适合数据并行时,根据任务执行代价与就绪任务的平均执行代价的比值确定将要处理的数据划分份数,以保证每一份数据的处理时间基本一致,达到负载均衡的目的;如果任务适合流水线并行时,根据系统当前可用工作线程数量和任务所在流水线长度,确定该流水线任务所在流水线的任务数量。之后将当前流水线任务存入候选任务队列,而流水线中其它数据未就绪的流水线任务存入到阻塞任务队列,执行时通过流水线局部并行自动机模型完成任务的查询处理;对于即适合数据并行又适合流水线并行的任务根据该任务在数据并行和流水线并行两种方式下的可并行任务数量进行比较,选择可并行任务数量较大的并行方式进行处理。
由于任务图中各个任务的执行代价在任务就绪时才能获取,而各个工作线程的负载不均衡会对整体执行时间带来影响。在任务调度之后,对负载较小的工作线程追加适当粒度的就绪任务使得各个工作线程的负载基本一致:从未被调度的就绪任务中追加新的任务到候选任务队列中,直到当前工作线程的负载大于所有工作线程的平均负载为止。
3 调度算法与流水线优化
本节将给出本文调度算法的描述、任务并行方式选择算法以及针对流水线并行优化问题建立的流水线局部并行自动机模型。
3.1 算法描述
针对2.2节的任务图模型,本文调度算法的处理过程如下:
(1)从DAG 中找出所有入度为0的任务,作为就绪任务存入就绪任务队列RTL。
(2)按照任务代价模型计算所有就绪任务的执行代价T.cost及其平均执行代价avgCost。
(3)将RTL中的就绪任务按照出度从大到小排列,出度相等的按照执行代价从大到小排列。
(4)当可用工作线程数量num>0且RTL 中有未被调度的任务时,从RTL 中依次选择任务,调用P-S算法进行并行方式选择处理,并将处理后的任务移动到候选任务队列STL,其中流水线阻塞任务存入候选阻塞任务队列SBTL 中,更新可用工作线程数量num。重复该步骤直到num=0或RTL 为空。
(5)当可用线程数量num=0且RTL 中存在未被调度的任务时,对候选任务队列STL 中的任务进行负载均衡处理。从RTL 中向负载小于avgCost 的工作线程追加适当粒度的任务到STL。
(6)将STL、SBTL 分别提交给执行模块的执行任务队列TQ、阻塞流水线队列BTL。
其中,第(4)步处理过程中确定各个任务并行方式时的选择策略参见3.2节中的并行方式选择算法P-S。在执行模块完成本次调度过程中所有任务的查询处理后,判定DAG中所有的任务是否均已执行完毕,如果是,则返回XQuery的查询处理结果,否则更新DAG 中各个任务节点的入度信息。重新调用第(1)步,完成下一次的调度处理。
3.2 并行方式选择算法P-S
在任务调度时需要确定每个候选任务的并行方式,本节给出任务T 并行方式的选择算法。其中,num 代表当前可用工作线程个数;T.cost代表任务T 的执行代价;avg-Cost代表就绪任务的平均执行代价;T.pipeLength 代表任务T 所在流水线的长度。其中,不同并行方式的最大并行度计算公式如下

并行方式选择算法P-S:
输入:任务T、就绪任务平均执行代价avgCost、可用工作线程数量num、候选任务队列STL、候选阻塞任务队列SBTL
输出:候选任务队列STL、候选阻塞任务队列SBTL
算法:


3.3 流水线局部并行自动机模型
对于流水线并行任务,由于流水线上各个任务处理数据的速度的不一致性,容易造成一些流水线任务处于空闲等待状态。为了减少各流水线任务的空闲等待时间,充分利用计算资源,本文建立了一种流水线局部并行自动机模型,用于描述一个流水线任务的工作状态。如图4 所示,各流水线任务根据要处理数据是否到达,将流水线任务的状态分为就绪、阻塞、执行和完成4种状态。执行模块剥夺处于阻塞状态的流水线任务所占用的计算资源,以满足其它任务的执行。待阻塞状态的流水线任务要处理的数据就绪时,再将该任务存入待执行任务队列TQ 中,等待被其它工作线程获取执行。其中,就绪、阻塞和执行状态的任务分别处于系统中的TQ、BTL 和工作线程中。
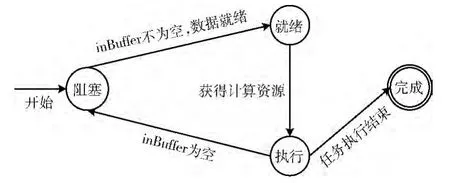
图4 流水线局部并行自动机模型
对于每一个流水线任务,均对应一个输入数据缓冲区inBuffer和输出数据缓冲区outBuffer。每个流水线任务均从inBuffer获取数据进行查询处理,并将处理后的结果存入outBuffer 中。对于流水线中非起始节拍任务而言,每一个流水线任务的输入缓冲区均为前一节拍的输出缓冲区。只有流水线任务对应的inBuffer中有数据时,该流水线任务才能进行执行。否则该任务处于数据未就绪状态,即阻塞状态。当流水线任务在执行时,如果输入缓冲区数据尚未到达,则工作线程将当前流水线任务保存到执行模块的BTL 中。当前工作线程从TQ 中重新获取其它待执行的任务进行查询执行。当流水线中非结束节拍的任务产生输出数据时,判断其后续任务是否处于阻塞状态,如果是,则将后续任务从BTL 移入TQ 中,等待被工作线程执行。这样一条包含n个流水线任务的流水线,可以看作n-1个流水线局部并行自动机。流水线任务的执行,可以理解为n-1个并行自动机的多次迭代,直到流水线任务执行结束,达到提高程序的查询执行效率,减少由于不同流水线任务处理数据速率的差异带来的性能影响的目的。
4 实 验
我们将第3节中的调度算法和并行方式选择算法及流水线局部并行自动机模型在基于JDK6.0的XQuery并行查询系统中进行了实现。根据不同并行方式的组合分别实现了任务并行、任务并行和数据并行、任务并行和流水线并行以及3种并行方式同时存在的4种版本。针对流水线优化的实验,在3种并行方式共存的场景下,实现了包含流水线局部并行自动机模型和不包含流水线局部并行自动机模型的两种版本。实验平台为HP Z600 工作站,E5504 CPU (4核×2),4GRAM。查询案例采用W3C 的标准查询 (http://www.w3.org/TR/2007/NOTE-XQuery-usecases-20070323/),所选取测试程序结构特点各异,充分考虑到了不同并行方式、单/多数据源的分布。实验数据采用XML基准数据集XMark。不同并行方式下的性能对比和流水线优化性能对比采用的数据集大小为32 M,工作线程数量为4。而不同核数下算法性能对比实验中,分别针对32 M 数据集和64 M 数据集在串行和工作线程分别为2、4、8共4种情况下进行测试。
4.1 不同并行方式下的性能比较
表1给出了测试案例在不同并行方式下的查询时间对比。通过实验我们可以看出充分利用查询任务中存在的并行方式可以提高查询任务的执行效率。由于q7中查询条件的约束,使得查询结果规模较小,从而使得不同并行方式下的性能提升不明显。以任务并行为基准,我们可以发现q1-q6中,任务并行、数据并行组合下性能提升最低的是q1为7.6%,最高的是q3为19.9%,平均提高的执行时间为13.4%;任务并行、流水线并行组合下性能提升最低的是q5为4.8%,最高的是q6为11.5%,平均提高的执行时间为8.8%;3种并行方式同时存在时,性能提升最低的是q5为11.3%,最高的是q1为19.3%,平均提高的执行时间为16.9%。由此,我们可以发现不同并行方式下性能的提升与XQuery程序结构有重要关系。不同测试案例在不同并行组合下的性能提升效果各不相同。综合来看,数据并行方式带来的性能提升优于流水线并行方式,而3种并行方式同时存在时对于XQuery整体并行的效率提升效果最明显。
4.2 不同工作线程下算法性能比较
表2给出了测试案例在不同数据规模和不同工作线程数下的性能对比。同时,给出了本文算法与串行执行方式下的比较。通过实验我们发现大部分查询案例在本文算法下能够很好利用多核环境的计算资源提高系统的执行效率,减少查询程序的执行时间。其中存在个别测试案例没有达到预期的执行效果,原因在于这些测试案例的查询结构过于简单,查询结果规模较小。查询结构简单导致并行方式处理和数据并行时的数据划分操作会带来额外开销。从表2中我们可以看出,随着线程数量的增加,XQuery测试案例的执行时间在逐步减小,但减小的幅度在逐步降低,例如q5在32 M 数据集下的测试结果。另外,本文的调度算法具有较好的内存使用效率。对于测试案例q6在64 M 数据集下的测试中,串行方式下会出现内存溢出错误,不能得到执行结果。而在工作线程数量为2、4、8 时,通过流水线并行方式可以减少中间结果存储,提高内存的使用效率,从而最终得到查询结果。

表1 不同并行方式下的性能对比 (时间单位/ms)
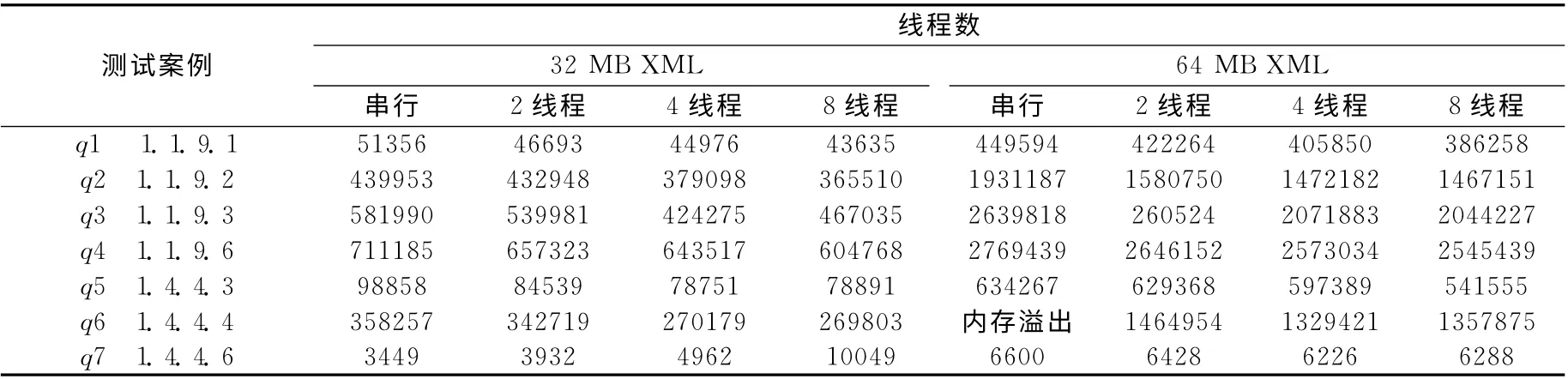
表2 不同工作线程下的算法性能比较 (时间单位/ms)
4.3 流水线并行优化
表3给出了测试案例在含有流水线优化和不含流水线优化两种情况下的性能对比。通过实验数据,我们可以发现本文提出的流水线局部并行自动机模型能够充分利用各流水线节拍之间的等待时间,提高系统资源的利用率,降低XQuery程序的整体执行时间。但同时我们也应该注意到,在q7测试案例中,查询规模较简单且查询结果规模较小时,流水线局部并行自动机模型带来的性能优化效果不明显。

表3 流水线优化的性能比较 (时间单位/ms)
5 相关工作
近年来,研究者根据DAG 中任务所适用的不同并行方式,提出了多种不同的调度方法。PF.Dutot等人针对任务并行方式研究了多核平台下的调度问题[8]。T.Ntakpe等人研究了任务与数据并行方式下的并行调度算法,结合数据并行提高了系统的处理效率[9]。针对流水线并行方式,Antonino Tumeo等人研究了异构嵌入式系统中流水线并行调度问题,提出了一种基于贝叶斯的优化调度算法[10]。针对任务并行、数据并行及流水线并行同时存在的调度场景,H Yang等人提出了一种利用ILP 思想的调度算法[11]。然而,该调度算法所针对的任务图模型具有一定的限制性,其模型假设各个任务的执行代价在调度开始时已知,各个任务执行时所采取的并行方式在调度之前是确定的,不能随系统资源的改变而改变。当前的调度算法不能很好的利用XQuery内在的多种并行方式特点,将空间并行技术与时间并行技术相结合。同时,也不能很好的支持XQuery并行实现中根据系统资源动态改变任务的执行方式,满足动态调度的需求。
6 结束语
本文针对XQuery整体并行查询实现过程中的任务调度问题,提出了一种适用于基于共享内存多线程环境下的调度算法。利用函数式语言的特点,将XQuery程序划分为可并行执行的计算任务,在运行时代价模型基础上,针对不同任务采用任务并行、数据并行和流水线并行进行处理,在一种新型的综合调度策略的指导下,提高了XQuery语言查询处理XML数据的性能,满足了动态调度的需要。实验结果表明这种调度算法能够很好解决共享内存多线程环境下,并行任务存在多种并行方式场景下的调度问题。本文提出的面向多种并行方式的调度算法比单一并行方式或两种并行方式下的执行效率更好,与串行算法相比,本文算法能够很好的利用多核环境的计算资源提高程序的执行效率。同时,在流水线并行优化方面,建立的流水线局部并行自动机模型,能够充分利用计算资源,提高程序的局部并行效率,减少流水线各节拍之间的等待时间。然而,目前方案中负载均衡、流水线局部并行自动机模型等方面仍有改进的余地。如何针对XQuery程序的特点利用多线程技术来充分发挥多核环境的并行计算能力,仍然是值得探索课题。
[1]Lakshmanan K,Kato S,Rajkumar R.Scheduling parallel real-time tasks on multi-core processors[C]//Real-Time Systems Symposium,2010:259-268.
[2]Yang H,Ha S.ILP based data parallel multi-task mapping/scheduling technique for MPSoC [C]//Proceeding of ISOCC,2008:134-137.
[3]Tony Minoru Lopes,Andre Augusto Cire,Cid Carvalho Souza,et al.A hybrid model for a multi-product pipeline planning and scheduling problem [J].Constraints,2010,15 (2):151-189.
[4]Frederic Desprez,Frederic Suter.A bicriteria algorithm for scheduling parallel task graphs on clusters [C]//Proceedings of the 10th IEEE/ACM International Conference on Cluster,Cloud and Grid Computing,2010:243-252.
[5]Wang Zheng,Michael FP.Mapping parallelism to multi-cores:A machine learning based approach [C]//Proceedings of the 14th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming,2009:75-84.
[6]Stephen L Olivier,Allan K Porterfield.Scheduling task parallelism on multi-socket multi-core systems [C]//Proceedings of the 1st International Workshop on Runtime and Operating Systems for Supercomputers,2011:49-56.
[7]LIAO Husheng.The principle and implementation technology of XQuery language [M].Beijing:Science Press,2013:187-189 (in Chinese).[廖湖声.XQuery语言原理和实现技术 [M].北京:科学出版社,2013:187-189.]
[8]Dutot PT,Ntakpe T,Suter F,et a1.Scheduling parallel task graphs on(almost)homogeneous multi-cluster platforms[J].IEEE Transactions on Paralllel and Distributed Systems,2009,20 (7):940-952.
[9]NtakpeT,Suter F.Concurrent scheduling of parallel task graphs on multi-clusters using constrained resource allocations [C]//Proceedings of the 10th IEEE International Workshop on Parallel and Distributed Scientific and Engineering Computing,2009:1-8.
[10]Antonino Tumeo,Marco Branca.Mapping pipelined applications onto heterogeneous embedded system:A Bayesian opti-mization algorithm based approach [C]//Proceeding of the 7th IEEE/ACM International Conference on Hardware/Software Codesign and System Synthesis,2009:443-452.
[11]Yang H,Ha S.Pipelined data parallel task mapping/scheduling technique for MPSoC [C]//Design,Automation and Test in Europe Conference and Exhibition.2009:69-74.
猜你喜欢
数学物理学报(2021年3期)2021-07-19
小学科学(学生版)(2020年2期)2020-03-03
网络安全技术与应用(2020年1期)2020-01-07
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
西北大学学报(自然科学版)(2018年2期)2018-04-18
环球市场(2017年36期)2017-03-09
中国资源综合利用(2016年9期)2016-01-22
福建人(2015年10期)2015-02-27
自动化博览(2014年6期)2014-02-28
