
Efficient Array Coding Scheme for Large-Scale Storage Systems
2015-11-18 10:11:35DanTang
Dan Tang
Efficient Array Coding Scheme for Large-Scale Storage Systems
Dan Tang
—A family of array codes with a maximum distance separable (MDS) property, named L codes, is proposed. The greatest strength of L codes is that the number of rows (columns) in a disk array does not be restricted by the prime number, and more disks can be dynamically appended in a running storage system. L codes can tolerate at least two disk erasures and some sector loss simultaneously, and can tolerate multiple disk erasures (greater than or equal to three) under a certain condition. Because only XOR operations are needed in the process of encoding and decoding, L codes have very high computing efficiency which is roughly equivalent to X codes. Analysis shows that L codes are particularly suitable for large-scale storage systems.
Index Terms—Array codes, high computing efficiency, high fault-tolerance, L codes.
1. Introduction
With the development of information technology, data is increasingly becoming an important resource in our daily lives. According to statistics, the total amount of data created, stored, and replicated in 2010 in the world has reached 1.2 ZB, and in 2011 the amount is 1.8 ZB. It will be expected to reach nearly 8 ZB in 2015, while data amount generated by the whole world in 2020 will reach 44 times that of today[1]. The foremost problem brought by the explosive growth of data is the increasing costs of storage equipment and management. The scale of storage nodes in a modern data center is ranging from tens of thousands to hundreds of thousands at present, and storage nodes may be more in a distributed storage system. Disk and storage node failures have become a normal behavior in the huge storage systems although the performance of the hardware has been very stable nowadays. At the same time, the network connection device and other components of the storage node often become invalid. However, data become increasingly important in the information society, the costs of data loss for business, governments, and individuals are staggering even unbearable. In order to satisfy the expanding demand for reliability, availability, and other pertinent characteristics of data storage, some fault-tolerant techniques are necessary to cope with the current situation.
There are two main kinds of highly fault-tolerant technologies: N-way mirroring technologies and erasure-coding technologies. In brief, the N-way mirroring technology is replication, namely create multiple backups of important data and store in separate nodes. The replication scheme is concise and clear, easy to realize, and the high efficiency of parallel data reading is another advantage. N-way mirroring technologies can provide sufficient reliability, but have very low storage efficiency(about 1/N), which will cause significant waste of resources including the storage space and data transmission bandwidth. In contrast, erasure-coding technologies can provide both high fault tolerance and high storage efficiency. Thus, the erasure-coding technology is gained more and more attentions. Under this background, many erasure codes have been proposed in recent years. Aiming at fault tolerance for storage systems, we can divide all erasure codes into two categories: the reed-solomon (RS)erasure code and array code. The RS erasure code is the one of the most widely used in various areas because of its powerful error correcting capability, sophisticated mathematical theories, and some perfect properties. According to information theory, the RS codes meet the Shannon theorem[2], with the maximum distance separable(MDS) property, and it is perfect in the code rate and fault tolerance ability. However, for RS codes, the encoding and decoding procedures are performed as operations over a finite field, so that the systems based on RS codes will become very slow (even unacceptable) with the increase of operational data. Thus the RS code is not suitable for fault tolerance on large scale storage systems. Compared with RS codes, array codes just need XOR (exclusive or)operations, with high operational efficiency, which are more propitious to a scene with large scale data computing. The good news is that so many array codes for storage systems are proposed successively, such as EVENODD code[3], X code[4], STAR code[5], Waver code[6], sector-disk(SD) code[7], grid code[8], and so on. However, there arealso quite a few problems in the practical process. Multiple fault-tolerant (greater than or equal to four faults) array codes do not have the MDS property, and its high fault tolerance is with strict conditions. Array codes with the MDS property (just tolerant there and fewer faults) can have high storage efficiency, but the number of rows (or columns) of the array usually has a prime number restriction, namely the number of rows (or columns) must have some linear relationship with a prime number. So it would be confronted with great troubles in practical applications. For a long time, array codes for storage systems are used to correct erasure errors of entire disks,even if there is only one bit error in a disk, on which all data are considered incorrectness. In other words, for all of array codes early, the unit of failure is the disk. For example, an EVENODD coding system dedicates two parity disks to tolerate the simultaneous failures of any two disks in the system[3]. Larger systems dedicate more disks for coding to tolerate larger numbers of failures[8]. Recent research, however, studying the nature of failures in storage systems, has demonstrated that failures of entire disks are relatively rare. The much more common failure type is the latent sector error or undetected disk error where a sector on a disk becomes corrupted[7].
In this article, we present a new family of erasure codes,named L codes. L codes do not be restricted by the prime number, that is to say, the number of rows (and columns)can be any positive integer. The new array code has the MDS property, so it is perfect in storage efficiency. And the processes of encoding and decoding just need XOR operations, thus it has high computational efficiency. Furthermore, L codes can tolerate at least 2 disk erasures and some sector loss simultaneously, which has very good practicability.
The rest of this paper is arranged as follows. Section 2 contains a few remarks on some necessary notions and basic concepts related to our work. Section 3 describes the coding procedure and critical proprieties of L codes in detail. Section 4 gives an analysis of performance and complexity briefly. Section 5 provides a summary of the entire paper.
2. Basic Concepts
Array codes offer the advantages of block structure and easy encoding and decoding. This contribution is concerned with codes formed by generalizing one or more component codes into arrays codes in two or more dimensions. Array codes were first introduced by Elias[9]and have been proposed for many bursts and random error-control applications. Array codes are most often binary, but in general, they can have symbols from the field of q elements,GF(q), where q is just an integer power of a prime number. In this paper, we only consider binary array codes (namely q=2) unless otherwise stated. Array codes are mainly used to correct burst errors in a communication system for a long time, which have high efficiency of coding and decoding,especially are suitable for scenarios with large-scale data on operations. Because of these characteristics of the array code, it has been introduced to the storage technology for building a fault-tolerant mechanism on storage systems(including disk arrays, distributed storage systems, etc.). In 1993, the first nontrivial array code for storage systems was the EVENODD code introduced in [3], which is a kind of 2 fault tolerance code. After that, a variety of array codes for storage systems have been proposed successively, while some common concepts are used by almost all array codes,which are still used throughout this paper and are listed as follows[8].
Data (information): a chunk of bytes or blocks that hold original unmodified user data.
Parity (redundancy): a chunk of bytes or blocks that hold redundant information generated from user data by a code.
Element (symbol): a fundamental unit of data or parities that can be a bit, a byte, a sector, or a larger disk block. In an array code system, an element is also considered as a basic unit on coding calculations.
Stripe: a maximal set of data and parity elements that are dependently related by a code and the stripe size is defined as the number of disks that hold a stripe. A storage system can be viewed as a collection of many stripes, but stripes are independent from each other.
Strip: a maximal set of elements in a stripe that are stored on the same disk; the strip size is defined as the number of elements contained in a strip. A strip can contain only the data or parity, and also can contain data and parity simultaneously.
Relationship between element, strip, and stripe is shown in Fig. 1 and Fig. 2.
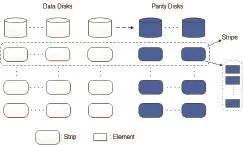
Fig. 1. Element, strip, and stripe in a horizontal code.
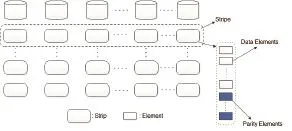
Fig. 2. Element, strip, and stripe in a vertical code.
Horizontal codes: the family of erasure codes in which data and parity elements within a stripe are stored in separate strips. In a horizontal code, the data elements and parity elements of a stripe are stored in different strips,namely, each strip stores only data elements or parity elements. The EVENODD code and the Star code are representative horizontal codes[3],[5]. Fig. 1 shows a representation of our notions of element, strip, and stripe in a typical horizontal code.
Vertical codes: the family of erasure codes in which each strip within a stripe contains both data and parity elements. For example, the X code is a case of the vertical code[4]. Fig. 2 shows the element, strip, and stripe in a typical vertical code.
Fault tolerance: the maximum number of erased strips that an erasure code promises to be able to reconstruct.
Storage efficiency: the ratio of user data to the total of user data plus redundancy data. Let the label Ndbe the number of user data elements, and the label Nrbe the number of redundancy, storage efficiency can be expressed as the formula (1) as follows:
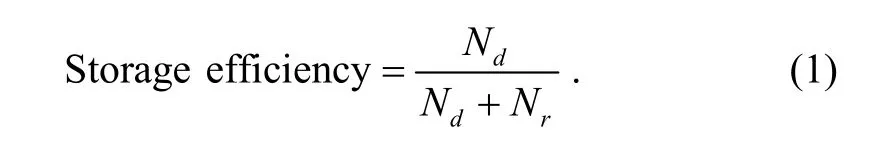
Maximum distance separable codes (MDS codes): the family of erasure codes that attain the Singleton bound and thus provide optimal storage efficiency.
Encoding: the generating process from data to parity elements.
Decoding (reconstruction of loss data): the process of recovering lost data (entire disks loss, or some sectors loss).
Updating: the process of recalculating parity elements when the user data changes.
Definitions and notations above would be used frequently in this paper, and they are useful for understanding other array codes. For ease of description, in this paper, each element (sector) is considered only storing a binary bit, and the coding problem is restricted to one stripe. So in disk arrays using array codes to correct erasure faults, typical data layouts of a horizontal code and a vertical code are shown as Fig. 3 and Fig. 4.
As shown in Fig. 3, and Fig. 4, all elements in a stripe form an array, and giving every column in this array an integer number by a natural sequence, then an assisted definition can be given.
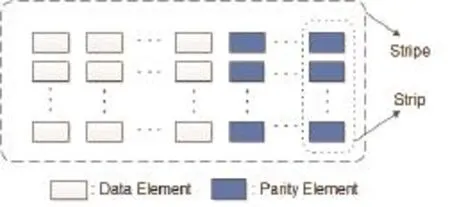
Fig. 3. Data layout of a horizontal code.
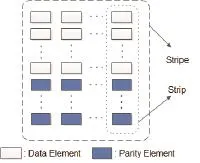
Fig. 4. Data layout of a vertical code.
Geometrical distance: In an m×n array, supposing the column numbers of any two columns are i and j, the geometrical distance from column i to column j can be defined as follows:, where. Generally, the inequalityholds from the definition of geometrical distance.
However, the geometrical distance between two columns with an erasure error needs a special note that only two incremental adjacent error columns have the geometrical distance value. For example, in an array with n columns, assuming that column i, column j, and column k are erasure-error columns, where 1 i j k n≤ < < ≤ . Then the geometrical distance from column i to column j exists,, but the geometrical distance from column j to column i does not exist, we denote that.
3. New Family of Array Codes
Suppose that there are n+1 disks, each strip has m elements, where m and n are positive integers, and an inequalityholds. Different from most array codes, the L code does not have a typical data layout: in a stripe, all strips contain both data and parity elements but a dedicated strip just storing parity elements that exist. In brief,all elements in the last row and the first column are parity elements, while other positions of the disk array are user data. The basic data layout of L codes is shown as Fig. 5. This kind of code cannot be classified as a typical horizontal or vertical array code from the point of the data layout, but this hybrid data layout structure also appeared in various array codes, such as Grid codes[8]and SD codes[7].
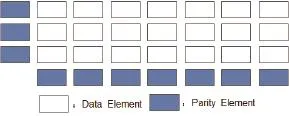
Fig. 5. Data layout of the new code.
Let,ijC be the element at the ith row and jth column(1 1i n≤ ≤ + ,1 j m≤ ≤ ), and using the symbol ‘⊕’ to represent the XOR operation, then the parity elements are constructed according to the following encoding rules:
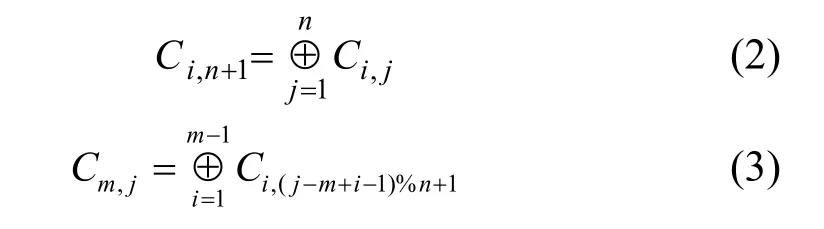
Geometrically speaking, the bottom parity row is XOR summed along the diagonal of slopes 1, and the left parity column is XOR summed along the horizontal direction. The detailed coding process is shown in Fig. 6. The XOR sum of all elements linked by a line is zero, and we call these lines coding chains.
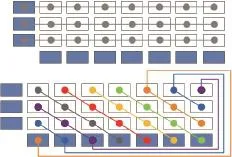
Fig. 6. Encoding process.
And next, other important properties of L codes will be listed and proved.
Property 1. L codes can tolerate any two disk erasures.
Proof. First, assume that the size of the disk array is m n× , and there are just two erasure-error disks labelled as number i, j, where i<j. Thus the bidirectional geometrical distances between i and j exist. Supposing, the inequalityexists according to the definition ofcodes, then, andholds, whereis the ceil function andis the floor function. Hence the first element of the jth column can be recovered,then the first line of the disk array has only one unknown element, thus the first line can be recovered obviously. In the same way, all unknown elements of the two erasure-error disks can be reconstructed. Obviously, L codes have the MDS property, and it is optimum in storage efficiency.
Property 2. There are t ( 3t≥ ) erasure errors in an m n× disk array coded by L codes, if any t-1 error columns meet the following condition:2, ..., t), all t erasure errors can be recovered.
Proof. The proof process of Property 1 can be seen as a decoding method of L codes when there are just two disk erasures. Thus if there are just one unknown element (a sector loss) in a coding chain, which can be recovered easily because the XOR sum of all elements in a coding chain must be zero. From the decoding procedure, there are many coding chains in which all elements are known. Hence L codes can tolerate at least 2 disk erasures and some sector losses simultaneously. Then if all elements in a column(equivalent to disk) are in a coding chain in which no other elements are unknown, L codes can tolerate more than two disk erasures. Depending on the conditions of this theorem,all elements in t-2 error columns can be recovered. Then other elements in the last remaining two error columns can be recovered by Property 1.
4. Analysis and Discussions
From the construction of L codes, it is easy to see that the parity row and the parity column are obtained independently. More specifically, each data element affects exactly two parity elements in the parity row and column respectively. All parity elements only depend on data elements, but not on each other. So, updating one data element results in updating only two parity elements. Thus the L code has the optimal encoding (or updating) property,in other words, it achieves the lower bound of the update complexity 2 for any codes of distance 3.
L codes do not be restricted by the prime number, in a disk array in the size of m× n, m and n can be any positive integer as long as. With the increase of m (strip size) and a constant nthe storage efficiency will improve continuously. Fig. 7 shows the relationship between them.
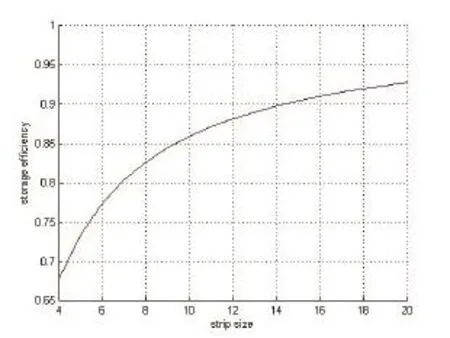
Fig. 7. Relationship between strip size and storage efficiency.
Similarly, the storage efficiency will still improve with the increase of n and a constant m (such as 8), and Fig. 8 shows the relationship between them.
It can be seen from the analysis above that L codes are suitable for storage systems with large scales. To the operation efficiency, the performance of L codes and X codes is roughly equivalent, this paper will do no more analysis. And new disks can be dynamic appended in a running storage system on L codes, and just 2m parity elements on m+1 disks are needed to be recalculated.
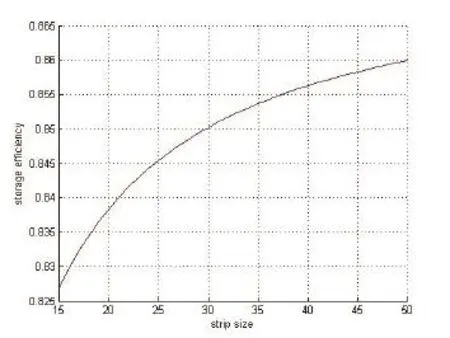
Fig. 8. Relationship between strip size and storage efficiency.
5. Conclusions
A family of array codes is proposed in this paper. Different from most array codes, the proposed code does not be restricted by the prime number, namely the strip size m and stripe size n can be any positive integer as long as. The proposed code can tolerate at least two disk erasures and some sector loss simultaneously, and can tolerate multiple disk (more than 2) erasures under a certain condition. It has the MDS property, and is very suitable for large scale storage systems. The processes of encoding and decoding just need XOR operations, thus it has high computational efficiency. All descriptions are over the binary field, but the proposed code is easy to be extended to other finite fields, so it will have a good perspective.
Acknowledgment
The author would like to express his deepest gratitude to Prof. Xiao-Jing Wang, for his constant encouragement and guidance.
[1] J. Gantz and D. Reinsel, The Digital Universe Decade—Are You Ready, Int. Data Corporation, Framingham, 2010.
[2] F. J. Mac Williams and N. J. A. Sloane, The Theory of Error-Correcting Codes, Amsterdam: North-Holland, 1997.
[3] M. Blaum, J. Brady, J. Bruck, and J. Menon, “EVENODD: An efficient scheme for tolerating double disk failures in RAID architectures,” IEEE Trans. on Computer, vol. 44, pp. 192-202, Feb. 1995.
[4] L. Xu and J. Brunk, “X-Code: MDS array codes with optimal encoding,” IEEE Trans. on Information Theory, vol. 45, no. 1, pp. 272-276, 1999.
[5] C. Huang and L.-H. Xu. (2005). Star: an efficient coding scheme for correcting triple storage node failures. [Online]. Available: http://research.microsoft.com/en-us/um/people/ chengh/papers/huang05star.pdf
[6] J. Lee Hafner, “Weaver codes: Highly fault tolerant erasure codes for storage systems,” in Proc. of the FAST’05 Conf. on File and Storage Technologies, San Francisco, 2005, pp. 211-224
[7] J. S. Plank and M. Blaum, “Sector-disk (SD) erasure codes for mixed failure modes in raid systems,” ACM Trans. on Storage, vol. 10, no. 1, pp. 4: 1-17, 2014.
[8] M. Li, J. Su, and W. Zheng, “Grid codes: strip-based erasure codes with high fault tolerance for storage systems,” ACM Trans. on Storage, vol. 5, no. 4, pp. 15: 1-22, 2009.
[9] P. Elias, “Error free coding,” Trans. of the IRE Professional Group on Information Theory, vol. 4, no. 4, pp. 29-37,1954.

Dan Tang received his Ph.D. degree from University of Chinese Academy of Sciences in 2000. Currently, he is an associate professor with Chengdu University of Information Technology. His research interests include coding theory and secret sharing scheme.
Manuscript received September 23, 2014; revised November 30, 2014. This work was supported by the National Natural Science Foundation of China under Grant No. 61202250.
D. Tang is with the Software Engineering College, Chengdu University of Information Technology, Chengdu 610225, China (Corresponding author e-mail: tangdan@foxmail.com).
Digital Object Identifier: 10.3969/j.issn.1674-862X.2015.02.002
 Journal of Electronic Science and Technology2015年2期
Journal of Electronic Science and Technology2015年2期
- Journal of Electronic Science and Technology的其它文章
- QCM Sensors Based on PEI Films for CO2Detection
- Energy-Based Collaborative Spectrum Sensing for Cognitive UWB Impulse Radio
- Monitoring of PON System Using Compound Surveillance Technique
- Design and Realization of an NFC-Driven Smart Home System to Support Intruder Detection and Social Network Integration
- Modeling of a Planar Nine-Way Metamaterial Power Divider/Combiner
- Robust Stability of a Class of Fractional Order Hopfield Neural Networks