
Gm d VFP中使用函数对档案数据库进行模糊查询
2015-10-31 09:17陈元
中国科技纵横 2015年14期
陈 元
(中国建筑西北设计研究院有限公司,陕西西安 710018)
Gm d VFP中使用函数对档案数据库进行模糊查询
陈元
(中国建筑西北设计研究院有限公司,陕西西安 710018)
VFP6.0是一种优秀的小型数据库管理软件,功能齐全,程序语言简洁直观,将它作为工具用于单位工程档案数据库的建立与管理是比较理想的选择。用这两种方法设计的检索程序在投入实际工作后,在快速查找,数据汇总等方面大大提高了工作效率,使用至今,比较稳定可靠,给档案处日常工作带来的便利是实实在在的,目前准备继续扩展功能,从而使其更好地在工作中发挥作用。
VFP 函数 档案数据库
本单位使用VFP的表设计器建立了30多年已归档的工程档案数据,包含设计编号,工程名称,子项名称,设计单位,设总姓名,底图柜,归档时间,设计阶段,电子文件等字段,数据库文件名为shuju. dbf,目前记录了约3万个项目的信息,只列举少数部分如表1。
对数以万计的记录如果靠手工查询统计,效率是很低下的。所以必需设计相应的程序,应当说明的是,数据库处于基础位置,所有程序都是对它进行操作,数据库文件本身的重要性不言而喻。
工作中要求对工程名称,子项名称等实施快速检索,输入关键字后将符合要求的记录输出,如果找不到则输出空白提示。对此,最简单的办法是直接使用查询数据库记录命令FIND和SEEK,但这两个命令都有一个不尽人意的地方,虽然它们也可以模糊查询,并不一定要求输入的关键字与记录的字段内容完全一致,但却要求输入的关键字必须是数据库记录内容字符串前面的一部分才认为匹配成功,而在实际中,我们很难作到输入的关键字一定是数据库记录的前一个或几个关键字,假如,查询子项名称时输入“大厦”,名称为“信息大厦”的记录却被滤掉,这在实际工作中是绝不被允许的,而且如果输入为空时,FIND和SEEK会立即报错并退出整个程序,稳定性也不令人满意。
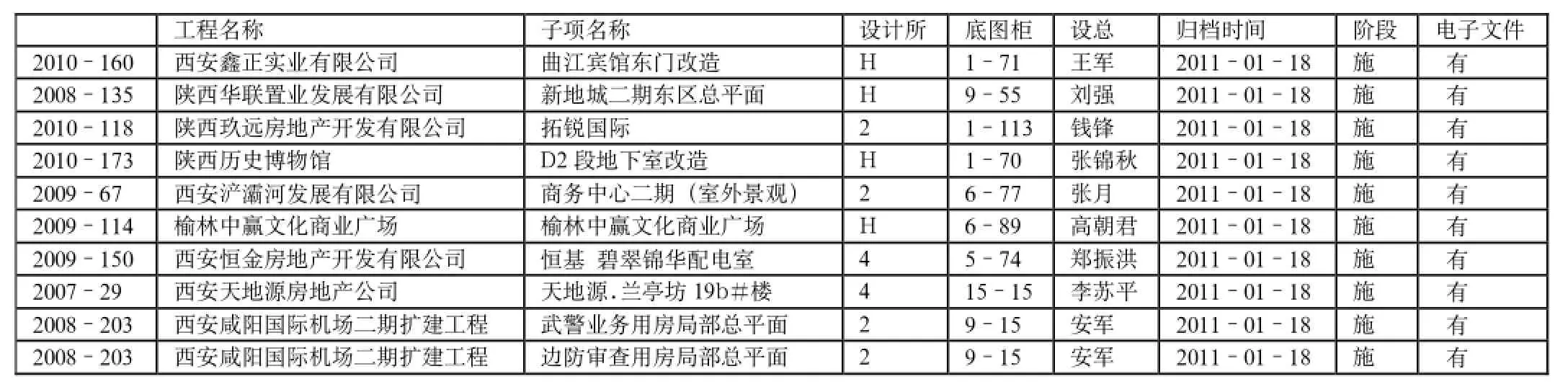
表1
为解决这个问题,可以在VFP中采取了如下两种方法做到真正的模糊查询,首先介绍函数法,使用STORE SPACE()TO和READ命令建立内存变量用于读入用户输入的关键字,建立的内存变量应有能容纳5个汉字以上的空间以确保能够接受内容多少不一的关键字,然后用RTRIM()和LTRIM()函数除去输入内容左右两边的空格,除去空格的目的是,1.绝大多数情况下,空格不是查找的关键字,2.如果输入的关键字未能占满内存变量,那么输入的内容将是“输入的关键字+剩余的几个空格”,所以必需要以经处理的字符串作为查询依据,然后打开数据库,用SORT命令重排数据库——按需要查询的字段名排序(相当于使用FIND、SEEK命令前对数据库的索引),打开新数据库,建立循环,接着就是最关键的一步——利用判断子串函数AT()去判断经处理后的关键字是否为第一个相应字段内容的子串,如果是则将该记录全部或部分字段内容输出,不是则继续用AT()判断下一条记录的相应字段内容。在满足条件记录较多的情况下,可以输出几条记录后就用CLEAR命令清屏,在原位置上重新输出,直到将所有记录判断完毕,结束循环。
如果对子项名称执行检索,程序代码如下:(注:程序后引号内文字是对程序的说明)
SET TALK OFF
CLEAR
DO WHILE.T.
STORE SPACE(12) TO DG
@ 8,18 SAY"请输入关键字:" GET DG
READ “建立并提示输入关键字,并读入”
DG1=RTRIM(DG)
DG2=LTRIM(DG1) “除去空格”
CLEAR
F=2
USE shuju.dbf
SORT ON 工程名称 TO shuju1
USE
USE TUSHU1“对数据库排序,打开新数据库”
DO WHILE .not.eof()
DX=工程名称
IF AT(DG2,DX)<>0 “判断是否满足条件,是则输出全部
@ f,15 say 工程名称 字段内容,否则判断下一条记录”
@ f,87 say 子项名称
F=F+1
@ f,22 say 合同号
@ f,59 say 设计所
@ f,77 say 底图柜
F=F+1
@ f,22 say 设总
@ f,85 say 归档时间
F=F+1
@ F,15 SAY"记录分界线"
SKIP
F=F+1
ELSE
SKIP
ENDIF
if f=18 “屏幕已满,用亮带提示继续查找或结束”
F=F+1
@F,20 PROMPT"继续"MESSAGE""
@F,40 PROMPT"结束"MESSAGE""
SET MESSAGE TO 20
D=1
MENU TO D
DO CASE
CASE D=1
F=2
CLEAR
LOOP
CASE D=2
CLEAR
EXIT
ENDCASE
ENDIF
ENDDO
F=F+1
IF F=3 “提示未能找到符合条件的记录”
@6,35 SAY"未找到匹配的记录"
ENDIF
@F,30 PROMPT"重新开始"MESSAGE"" “数据库查找完毕,用亮带
@F,50 PROMPT"结束退出"MESSAGE"" 提示开始新的查找或结束”
C=1
SET MESSAGE TO 20
MENU TO C
DO CASE
CASE C=1
CLEAR
LOOP
CLEAR
CASE C=2
EXIT
CLEAR
ENDCASE
ENDDO
CLEAR
USE
DELETE FILE TUSHU1.DBF
RETURN
(上述程序在VFP6.0下运行通过)
这种方法实现了真正意义的模糊查询,如果对程序稍加修改,输入多个字符串,在一次循环中使用多次AT()函数,就能实现多字段的复合查找,如果使用在程序中使用SET DEVICE TO FILE(PRINTER)命令,就可以将查找的的内容直接输出到文件或打印机。严格说,这个过程是重组数据库然后再按顺序对其查找,因此速度肯定不及FIND和SEEK命令,但实际使用中是感觉不到的,主要存在的问题是,程序代码比较多,程序设计有相当多“@”命令,只是为了设置屏幕输出的位置,而且,查询结果不能直接生成文件,所以还是有值得改进的地方。
“面向对象”设计的方法具有人机对话界面直观,在设计器中直接建立完成,程序代码相对较少等优点,而且输出结果能够一次完成,拖动滚动条即可全部显示,直接调用菜单栏的“另存”即可生成文件,快捷方便,程序不再需要繁琐的屏幕输出显示设置,因此编程工作得到了简化。首先使用表单设计器直接建立起应用界面如图1。
仍旧使用原来的数据库文件shuju.dbf,直接用于查询的命令语句仍需在对应的设计器内使用函数,除原先的AT函数可用外,SELECT命令同样有此功能且更加简洁,读入输入的数据,首先也要滤掉空格,在SELSCT命令行加入LIKE选项,判断其是否是被查询字段的子串,是则选中,否则对下一条字段内容继续判断,比对完所有数据库后将选中的记录按设定的顺序全部输出,找不到时直接输出空表。选择子项名称后运行界面及源代码如下图2;图3。
点击“确定”源代码如下
PUBLIC GUJ1
DO form GUJ1
PUBLIC M
M=GUJ1.TEXT1.TEXT
M1=RTRIM(M)
M2=LTRIM(M1)
M3="%"+M2+"%"
select 设计编号,子项号,工程名称,子项名称 FROM shuju WHERE 工程名称 LIKE M3 ORDER BY 设计编号
CLOSE ALL
GUJ1.RELEASE
点击“退出”源代码如下
GUJ.RELEASE
(上述程序在VFP6.0下运行通过)
结语:用这两种方法设计的检索程序在投入实际工作后,在快速查找,数据汇总等方面大大提高了工作效率,使用至今,比较稳定可靠,给档案处日常工作带来的便利是实实在在的,目前准备继续扩展功能,发挥档案处已保存有多年的电子文件的优势,将在查询结果追加一个链接输出,指向被查询项目CAD文件在硬盘的存储路径,用户只需选择打开就能看到CAD文件。实现看到文字和数字结果的同时也能迅速找到图形信息的目的。程序设计的目的是为了为现实工作服务,因此,欢迎为以上程序设计的不足提供宝贵的修改意见,使其更好地在工作中发挥作用。
猜你喜欢
华人时刊(2022年1期)2022-04-26
娃娃乐园·综合智能(2022年3期)2022-04-19
动漫界·幼教365(大班)(2019年10期)2019-10-28
军营文化天地(2018年2期)2018-04-20
中国老区建设(2016年9期)2016-02-28
环球时报(2009-11-25)2009-11-25
中国体育(2004年4期)2004-11-16
军事历史(1999年3期)1999-08-20
