
基于扩展Dewey编码的XML文档关键字查询算法研究
2015-10-26 06:07王磊张红梅郭有强
海南师范大学学报(自然科学版) 2015年4期
王磊,张红梅,郭有强
(1.蚌埠学院计算机科学与技术系,安徽蚌埠233000;2.安徽电子信息职业技术学院软件学院,安徽蚌埠233000)
基于扩展Dewey编码的XML文档关键字查询算法研究
王磊1,张红梅2,郭有强1
(1.蚌埠学院计算机科学与技术系,安徽蚌埠233000;2.安徽电子信息职业技术学院软件学院,安徽蚌埠233000)
为实现XML关键字查询,提出一种基于扩展Dewey编码快速求解SLCA的新算法:FEDA.算法利用Dewey扩展编码快速命中含有N个关键字的集合,将最终交集看做一棵简化的XML树,所有的叶节点即为求解的SLCA.该算法与经典的ILE算法进行对比,效率优于ILE算法.
XML文档;Dewey;扩展编码;SLCA
XML文档大量用于网络数据表达和信息交换. Xpath和Xquery[1]利用正则表达式可以精确地包含XML数据单元间的结构与关联,能充分地表达用户的查询意图,返回结果命中率高.普通用户在没有了解XML数据组织结构及查询语法的前提下,不具备书写复杂查询表达式的能力,因此无法使用这两种正则表达式进行查询.XML关键字查询(Keyword Search)方式借鉴传统的信息检索技术(Information Retrieval,IR),如Xrank[2]、Xseek[3]等;用户无需掌握XML文档细节和复杂的查询语法,即可在终端快捷方便地查询.目前越来越多的研究人员设计算法以提高XML关键字查询命中率和时间响应效率,从而降低普通用户使用XML搜索引擎的门槛,该类算法的研究已成为数据库与信息检索领域的一个重要研究方向.
XML关键字查询算法基于树形存储模型,利用Dewey编码等形式记录XML文档树节点间的层次关系,返回LCA(Lowest Common Ancestor)[4].LCA定义了XML关键字查询结果中的最紧致片段,研究人员发现LCA查询准确率较低,原因是LCA对结果的定义无严格限制,导致结果集中某些LCA节点成为另外一些LCA的祖先节点,这些祖先节点与查询关键字之间的相关度明显降低,从而无法返回用户所需的有效信息.在此基础上,SLCA[5]、VLCA[6]、MLCA[7]等算法相继出现,进一步提高了XML关键字查询的性能.
1 数据模型和相关定义
1.1XML数据模型
一个XML文档可以看成是带标签的有向树D(r,V,E),其中V表示节点集合,E表示边集合,r是根节点.如果v是非叶节点,则tag(v)表示为标签,否则val(v)表示值.图1所示的XML文档树中,所有的非叶节点均使用扩展Dewey编码进行标记,如paper<5,0.0.2>,paper<12,0.0.2.2.0.2>,paper<15,0.0.3>,paper< 22,0.1.2>;而叶节点单独使用Dewey编码,如xml<0.0.2.0.0>和xml<0.1.2.0.0>.

图1 扩展Dewey编码表示的XML文档树Fig.1Extended Dewey encoding XML document tree
1.2相关定义

定义6Dewey编码.给定对应XML文档的标签有向树D(r,V,E),D中任意节点的Dewey编码由下列规则确定:1)根节点r的Dewey编码为“0”.2)在宽度优先遍历D的过程中,如果节点v是节点u的第i个孩子节点,那么,节点v的Dewey编码为“D(u).(i-1)”,其中的D(u)表示节点u的Dewey编码.
2 FEDA查询算法
SLCA对XML最紧致片段的定义较为准确.基于Dewey编码求解SLCA经典算法有堆栈算法(Stack)[7]、ILE(Indexed Lookup Eager)算法[5]和SE(Scan Ea⁃ger)算法[6]等.Stack算法需要逐一扫描关键字集合中节点,频繁的Dewey编码比较、入栈和出栈导致算法效率偏低.ILE算法利用B+树索引快速扫描XML全文结点,使得查询效率得到一定幅度的提高.SE算法本质是ILE的变形,效率与ILE相差不大.
本文提出一种基于扩展Dewey编码快速求解SLCA的新算法FEDA(Fast Encode Dewey Algo⁃rithm),利用XML文档树的特点,在解析XML文档过程中记录下每个非叶节点的深度遍历编号(Encode码).算法中从每个含有关键字的节点出发,回溯到根节点,并记录下回溯过程中的Encode码.设N个关键字命中XML文档树中的M个节点,最终对这M个集合的Encode码求交集ResultSet,对于最终交集的树结构中,所有的叶节点就是最终的求解结果.
例1在图1中查找包含“IR”和“Tom”关键字的SLCA节点,关键字“IR”Encode码的集合Set1={{1,2,5,8,9,12,13},{1,2,15,16}},“Tom”关键字Encode码的集合Set2={{1,2,5,8,9,12,14},{1,2,15,17}};去除Set1中的重复节点后,集合Set1={1,2,5,,8,9,12,13,15,16},同理Set2={1,2,5,8,9,12,14,15,17};Set1与Set2的交集为:ResultSet={1,2,5,8,9,12,15};对应的Dewey编码集合为:DeweySet={0,0.0,0.0.2,0.0.2.2,0.0.2.2.0,0.0.2.2.0.2,0.0.3},在DeweySet集合中,依次遍历每个节点,剔除每个节点的祖先节点,最后得到的叶子节点集合为:{0.0.2.2.0.2,0.0.3},即为求解的SLCA节点.
例2查找包含“xml”和“John”关键字的SLCA节点,“xml”Encode码集合为{1,2,5,6,19,22,23},“John”Encode码集合为{1,2,15,18,19,22,24},二者交集为{1,2,19,22},对应的Dewey编码集合为:Dewey⁃Set={0,0.0,0.1,0.1.2},剔除每个节点的祖先节点后,得到最终求解的SLCA节点为{0.0,0.1.2}.查询S个关键字,只要判断某个节点存在于最终的交集中,即为LCA节点,然后在ResultSet集合中去除LCA的祖先节点即可.
2.1数据预处理
解析XML可以置入任意格式数据库,文中使用MySql数据库.基于文献[8,9]研究基础,解析过程中将深度遍历XML文档树的编号同步记录,形成扩展的Dewey编码,形如<Encode,Dewey>.
2.2FEDA算法描述

2.3FEDA算法复杂度分析
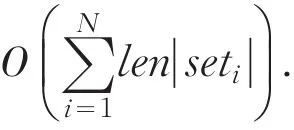
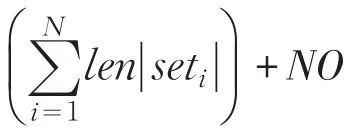
2.4算法正确性证明
证明:对于任意给定的关键字对应的Encode码都是经过深度优先遍历产生的,必然存在于XML文档树中;算法中求得的任意关键字对应的Encode码的集合,是每个含有关键字元素节点不断向其父节点回溯产生的最短路径,终止于根节点.当N个集合求交集过程中,只要交集不为空,就意味着在XML文档树中存在交叉节点,最坏的情况是交叉节点为根节点,这种情况认定为查找失败.其他情况下,在最终返回的结果集中,不仅返回了SLCA节点,连同SLCA的上层节点LCA一并返回.最后,算法通过删除路径集合中的非叶节点,即通过Dewey码去除集合中含有SLCA前缀的LCA节点,使得SLCA节点会一直保持在算法运行的最后集合中.删除LCA过程中,不会删除SLCA节点是因为根据SLCA的定义中,SLCA所在的层要比LCA深,SLCA不存在更小的子树同样包含关键字,若包含则一定含有SLCA的公共前缀.因此,算法是正确可行的.
3 实验结果与分析
本文实验的硬件环境为:Intel Pentium双核2.7 GHz,内存4 GB;软件环境为:Windows7、MySql5.5和MyEclipse8.0.使用Xmark生成大小不同的测试数据集,文档信息见表1.

表1 测试用XML文档信息Tab.1For test XML document information
用本文FEDA算法与文献[7]ILE算法对数据集中的测试样本分别计算SLCA,实验针对不同测试样本的XML节点数,采用不同的关键字个数进行运行时间上的对比,得到的结果如图2~图5所示.测试过程重复3次,分别记录后求平均值.

图2 具有382节点数XML样本测试结果Fig.2Test result with 382 nodes XML

图3 具有14974节点数XML样本测试结果Fig.3Test result with 14974 nodes XML

图4 具有63533节点数XML样本测试结果Fig.4Test result with 63533 nodes XML
从图2~图5中可以看出:使用不同数量的关键字进行查询时,系统消耗时间不同.随着XML文档中元素节点数递增时,算法运行时间随之增加,FE⁃DA与ILE算法均可以得到相同查询结果.影响查询效率的另一方面是XML文档树的深度,XML文档树较深时,查询消耗时间明显增多.图5反映出XML文档树较深时两种算法运行时间差异不大,但FEDA算法执行效率仍优于ILE算法.鉴于用户查询时,使用的关键字一般不会超过5个,当XML文档呈现扁平结构时,FEDA算法进行交运算时间会一定程度降低,相比ILE算法更加具有优势.

图5 具有151289节点数XML样本测试结果Fig.5Test result with 151289 nodes XML
4 结束语
本文提出一种利用扩展Dewey编码快速求解SLCA的新算法FEDA,并给出算法描述和证明,通过实验查询不同节点数和深度的XML文档,与经典的ILE算法进行对比.结果表明,对于关键字较少且XML文档具有扁平结构时,FEDA算法优于ILE算法,具有有效性和可行性.
[1]Xpath,Xquery[EB/OL].[2011-05-11].http://www.w3school.com.cn/.
[2]Guo L,Shao F,Botev C,et al.XRANK:Randed keyword search over XML Documents.In:Halevy AY,Ives ZG,Doan A,eds.Proc.of the 2003 ACM SIGMOD Int’1 Conf.on Management of Data(SIGMOD)[M].San diego:ACM Press,2003:16-27.
[3]Liu ZY,Walker J,Chen Y.X seek:A Semantic XML Search Engine Using Keywords[C]//VLDB Conference,2007.
[4]Hristidis V,Koudas N,Papakonstantitinou Y,et al.Key⁃word proximity search in XML trees[J].IEEE Trans on Knowledge and Data Engineering,2006,18(4):525-539.
[5]Xu Y,Papakonstantinou Y.Efficient keyword search for smallest LCAs in XML databases.In:ozcan F,ed.Proc.of the ACM SIGMOD Int’l Conf.on Management of Data(SIG⁃MOD)[M].Baltimore:ACM Press,2005:537-538.
[6]Li G L,Feng J H,Wang J Y,et al.Effective Keyword Search for Valuable LCAs over XML[C]//SIGMOD Confer⁃ence,2007.
[7]Liu Z,Chen Y.Identifying meaningful return information for xml keyword search[C]//SIGMOD Conference,2007.
[8]李思莉,李娟.XML文档到关系数据库的映射策略[J].计算机工程,2010,36(5):40-42.
[9]王磊,姚保峰,朱洪浩,等.一种无DTD变化约束的XML与关系数据库映射方法[J].辽宁科技大学学报,2011,34(6):588-593.
责任编辑:黄澜
Research on the Algorithm of Keyword Search in XML Document Based on Extended Dewey Encoding
WANG Lei1,ZHANG Hongmei2,GUO Youqiang1
(1.Department of Computer Science and Technology,Bengbu College,Bengbu 233000,China;
2.Software College,Anhui Electron and Information Professional Technology College,Bengbu 233000,China)
For XML query keywords,a new algorithm FEDA based on extended Dewey encoding for fast solving SLCA is proposed.The algorithm gets a collection of N key words quickly by extended Dewey encoding,and the final intersection can be as a simplified XML tree,and the solution to SLCA is all of the leaf nodes.Compared with the classical ILE algorithm,the experimental results showed that the FEDA efficiency was better than the ILE algorithm.
XML document;Dewey;Extended encoding;SLCA
TP 311
A
1674-4942(2015)04-0381-04
2015-10-19
安徽省高校自然科学研究一般项目(113052015KJ09);蚌埠学院自然科学项目(2013ZR06);安徽电子信息职业技术学院自然科学项目(ADZX1303)
猜你喜欢
客联(2022年3期)2022-05-31
华人时刊(2022年1期)2022-04-26
中国新闻周刊(2021年26期)2021-07-27
动漫界·幼教365(大班)(2019年10期)2019-10-28
信息安全研究(2016年4期)2016-12-01
中国卫生(2015年10期)2015-11-10
中国卫生(2015年10期)2015-11-10
中国卫生(2015年10期)2015-11-10
环球时报(2009-11-25)2009-11-25
