
一种优化的Hadoop副本放置策略*
2015-10-18 22:39:02蔡燕冬张庆磊华侨大学计算机科学与技术学院福建厦门361021
网络安全与数据管理 2015年16期
蔡燕冬,刘 艳,张庆磊(华侨大学 计算机科学与技术学院,福建 厦门 361021)
一种优化的Hadoop副本放置策略*
蔡燕冬,刘艳,张庆磊
(华侨大学计算机科学与技术学院,福建厦门361021)
Hadoop分布式文件系统默认采用三副本策略实现较为简单,未对数据节点负载进行充分考虑。为了改善HDFS中集群负载的均衡性,提高数据节点的资源利用率,提出一种优化的副本放置策略。该策略综合考虑数据节点的实时负载信息和工作进程数,选择负载最小的节点存放数据。实验结果表明,与默认策略相比,优化的Hadoop副本放置策略能使副本分布更加合理,集群的均衡性更加良好,并能减少数据上传响应时间。
Hadoop;副本放置;实时负载;负载均衡
0 引言
HDFS副本放置策略设计是基于节点硬件性能同构的基础之上,其采用三副本冗余机制保证数据的安全性。整体的副本存储策略如图1所示。HDFS整体的副本放置策略的原则为:尽最大可能将其中两个数据块副本存储在一个机架上,将另一个数据块副本存储在另一个机架上,很好地在带宽资源及可靠性方面做了平衡[1]。然而默认副本放置策略具有一定的局限性,已有不少的研究致力于优化Hadoop的数据块副本放置策略。参考文献[2]从数据块热度的角度出发,让经常使用的数据块拥有更多的副本以达到更高的并行处理效率。参考文献[3]将数据块副本更多地放置在性能较好的节点上,有效提升mapreduce的性能。参考文献[4]从节点的网络距离和节点负载两方面进行考虑,为HDFS的远程数据副本选择最优的存储位置。参考文献[5]则优先让使用率低的节点被选中作为存储节点。受这些研究工作的启发,本文提出一种优化的Hadoop副本放置策略旨在提高集群节点负载的均衡性,最终达到提升数据传输效率的目的。

图1 默认副本放置策略
1 HDFS副本放置优化策略
1.1HDFS副本放置策略的局限性
默认HDFS副本放置策略的局限性主要体现如下:在选取副本存储节点时采用了随机方式,HDFS虽然也考虑了数据节点的工作接连数的负载信息,但相对简单,并且是在随机选取存储节点之后才做出判断。这样的副本放置方式将导致副本的分布随意性大,特别在异构环境中很有可能出现分配较多数据副本的节点是性能较差的节点,这些情况将进一步造成有些节点具有很高的负载,有些节点却处于空闲状态造成数据传输效率的下降。
1.2优化HDFS副本放置策略
从1.1节的分析可以看出,在默认策略中,名字节点对于数据节点的状态信息缺乏感知,无法做出更为精确的副本位置选取工作。为此,本文的优化策略将重点考虑如下两个评价指标,增加名字节点副本放置节点选取的准确性、合理性。
(1)节点实时负载:实时负载W由数据节点的多个指标衡量,分别为磁盘IO负载、内存负载、CPU负载、网络负载。W的计算公式为:
W=λio×wio+λmem×wmem+λcpu×wcpu+λband×wband其中,wio、wmem、wcpu、wband分别代表了磁盘IO负载、内存负载、CPU负载、网络负载;λio、λmem、λcpu、λband则代表了衡量节点工作负载时的节点磁盘、内存、CPU、网络带宽所占的比重,λio+λmem+λcpu+λband=1,λio、λmem、λcpu、λband∈[0,1]。权值的选取采用运筹学中的层次分析法(Analytic Hierarchy Process,AHP)来确定。该方法适用于难以定量分析的决策性问题。
(2)HDFS工作进程:即数据节点HDFS写入、读取等工作的连接数。由于这些负载都是比值的关系,在异构环境下有些节点可能由于性能较好,其某些实时负载处于较低水平,在节点性能严重不均衡时将导致集群大量副本存储在个别高性能节点上。该负载信息能控制一个数据节点上进行的HDFS工作进程,抑制某个数据节点进行过多的HDFS服务。
依据上述两个指标,某数据副本放置位置的选取的主要思想是:从指定的机架位置上随机选取一定数量的数据节点集,然后从该集合中进一步选取工作连接数低于集群平均工作连接数的数据节点集合,最后在该集合中选择实时负载最小的节点作为副本位置放置节点。为方便下面的描述,该思想标记为算法1。
整体上副本放置位置的选取依然遵循将副本尽量放在不同机架上以保证可靠性的原则,从最常见的3副本方案出发,其整体副本选取方案如下:
While还需选取的副本数>0
if第一副本选取then
if客户端节点是数据节点then
选择该节点
else通过指定所有集群机架通过算法1去选取节点
else if第二副本选取then
指定除去第一副本所在机架外的所有机架通过算法1去选取节点
else if第三副本选取then
if第一、二副本所在节点在同一机架then
指定除去第二副本所在机架外的所有机架通过算法1去选取节点
else指定第二副本所在机架通过算法1去选取节点
1.3层次分析法的权值确定工作
美国运筹学家Saaty教授提出的层次分析法是多属性决策中的重要方法[6]。对于存在多个影响指标的情况,评价各方案的优劣程度的这类问题可以使用AHP方法来解决。AHP方法的思想是把复杂问题中的各种因素进行分层,分层是有次序的,层次之间也是有联系的,将每个层次的元素两两比较,并定量描述它们的相对重要性。最后使用数学方法计算权值,用权值反映每一层次元素的相对重要性次序。
本文从实时负载的实际情况出发进行建模,如图2所示。

图2 实时负载模型
对准则层的各个因素进行两两对比,构建判断矩阵,如表1所示。

表1 判断矩阵
对表1构成的判断矩阵通过合法的计算方式,求取其最大特征根λmax和归一化的特征向量W。得到λmax=4.119,W=(0153,0.072,0.531,0.245)T,最后进行判断矩阵一致性检验,发现其误差值0.044小于阈值0.10,即通过判断矩阵的一致性检验,因此特征向量W的值是合理的,最终实时负载的权值确定为:λcpu=0.153、λmem=0.072、λio=0.531、λband=0.245。
2 实验与分析
优化的HDFS副本放置策略的实验基于Hadoop-1.0.0。集群中存在两种性能不同的计算机节点,分别标识为性能A节点和性能B节点,其中A节点的主要硬件配置为:3.30GHz的Inter(R)Core(TM)i3-3220CPU,2GB DDR3的内存,7 200rpm的500GB硬盘;B节点的主要硬件配置为:2.93GHz的Inter(R)Core(TM)2Duo(E7500)CPU,GB DDR3的内存,4 500rpm的500GB硬盘。整个集群由1个机架组成,集群配置成1个名字节点、8个数据节点和1个客户端的形式。其中性能A的数据节点编号为1、2、7、8,性能B的数据节点编号为3、4、5、6。实验中涉及的数据读写操作均通过客户端发出。
图3和图4分别展示了在默认策略和优化策略下通过客户端写入1 000个数据块时的副本分布情况。从图3可以看出,在默认策略下,副本放置位置是通过随机算法获取的,因此副本的分布显得较为随意,波动性也比较大。副本的分布不具目的性,例如数据节点1和数据节点5,通过实验配置可知数据节点1在性能上比数据节点5要更优越,然而数据节点1却比数据节点5少存储了100多个副本,这样的分布显然不太合理。而优化策略下,副本的分布显然更具目的性。如图4所示,性能更好的1、2、7、8数据节点存储的副本总量要多于性能较差的3、4、5、6数据节点。这是由于考虑了实时负载,性能更好的节点其负载程度相对较轻,存储副本的概率较大。然而其总量上的区别还算合理,这是因为本文考虑了另一个因素HDFS工作进程,它能有效地限制一个节点进行过量的操作。而且,整体的存储情况是优化策略要显得更加均衡,这也是因为考虑了实时负载因素在无形中增加了低负载节点的工作量,减小了高负载节点的工作量,最终使优化策略的副本分布看起来更加平衡。
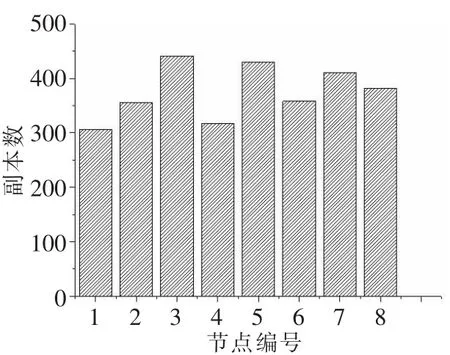
图3 默认的副本放置策略副本分布
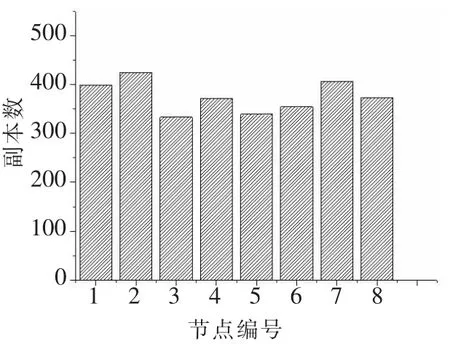
图4 优化的副本放置策略副本分布
最后本文通过客户端写入200、500、1 000个数据块,对比数据传输的时间,结果如图5所示。从图5可以看出由于优化副本策略考虑了节点的实时负载,在一定程度上避开了实时负载繁忙的节点,有效地均衡了节点的负载,并有目的地适当提高了性能较高节点的使用,充分发挥其性能优势,最终实现了缩短存储型数据写入时间的目的。
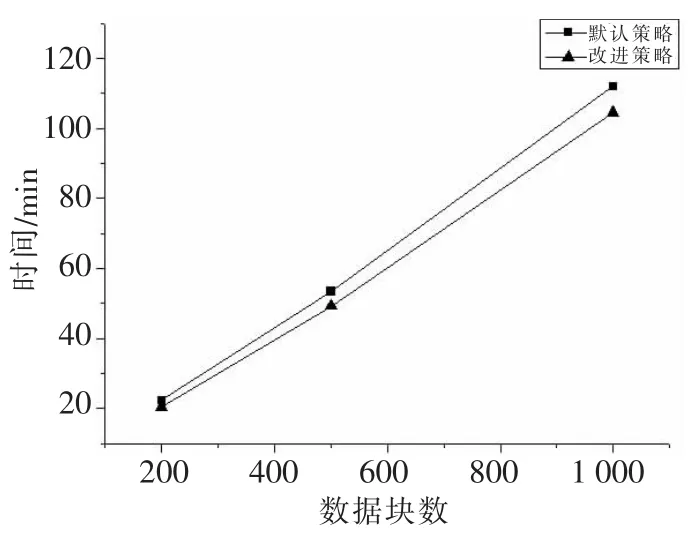
图5 数据写入响应时间对比
3 结论
本文分析了HDFS默认副本放置策略的局限性,并据此提出了一种优化的副本放置策略,该策略综合考虑了实时负载和HDFS工作进程数,有效提高了副本的合理分布。通过实验表明,相比于默认策略,优化的副本放置策略具有更明确的目的性,尽量选择了最低实时负载节点,避开了高负载节点的存储,最终提升了副本传输的时间。本文还通过科学的AHP方法确定了实时负载的权值,更加精确了实时负载的评估准确性。
[1]WHITE T.Hadoop:The definitive guide[M].O′Reilly Media,Inc.,2012.
[2]ABAD C L,Lu Yi,CAMPBELLR H.Dare:adaptive data replication for efficient cluster scheduling[C].Proceedings of the 2011 IEEE International Conference on Cluster Computing,USA:IEEE Computer Society,2011:159-168.
[3]Xie Jiong,Yin Shu,Ruan Xiaojun,etal.Improving mapreduce performance through data placement in heterogeneous hadoop clusters[C].2010 IEEE International Symposium on Parallel Distributes Processing,Workshops and Phd Forum(IPDPSW),Atlanta:IEEE Press,2010:1-9.
[4]林伟伟.一种改进的Hadoop数据放置策略[J].华南理工大学学报(自然科学版),2012,36(1):152-158.
[5]邵秀丽,王亚光,李云龙,等.Hadoop副本放置策略[J].智能系统学报,2013,8(6):489-496.
[6]徐玖平,吴巍.多属性决策的理论与方法[M].北京:清华大学出版社,2006.
An improved replica placement strategy in Hadoop
Cai Yandong,Liu Yan,Zhang Qinglei
(College of Computer Science& Technology,Huaqiao University,Xiamen 361021,China)
Hadoop distributed file system applies default three copies of the random replica placement strategy without taking into account full load of Datanodes.To improve the cluster load balabcing of HDFS and the resource utilization of Datanodes,an improved replica placement strategy is proposed.The strategy considers real-time load of Datanodes and the number of the work process to select the minimum load Datanode storing data.Experiment shows that compared with default three copies of the random replica placement strategy,the improved strategy optimizes the balancing of cluster load and reduces I/O response time.
Hadoop;replacement of replica;real-time load;load balancing
TP391.41,TP911
A
1674-7720(2015)16-0021-03
蔡燕冬,刘艳,张庆磊.一种优化的Hadoop副本放置策略[J].微型机与应用,2015,34(16):21-23.
2015-03-19)
蔡燕冬(1990-),男,硕士研究生,主要研究方向:计算机存储、计算机网络。
刘艳(1976-),女,博士,副教授,主要研究方向:计算机存储、网络存储系统、数据管理。
张庆磊(1989-),男,硕士研究生,主要研究方向:计算机存储、计算机网络。
国家自然科学青年基金项目(61202106)
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
家庭影院技术(2019年12期)2020-01-19 02:07:20
计算机系统应用(2019年2期)2019-04-10 05:08:46
自动化学报(2017年7期)2017-04-18 13:41:02
计算机与生活(2016年11期)2016-11-22 02:07:32
工业设计(2016年4期)2016-05-04 04:00:27
计算机工程与科学(2015年3期)2015-03-27 07:46:15
上海金属(2013年6期)2013-12-20 07:58:02
