
A Power Optimization Strategy of Directive Cache on DSP*
2015-10-13 07:30:41SHANYueerYANGBingYUZongguangCAOHuafeng
电子器件 2015年1期
SHAN Yueer,YANG Bing,YU Zongguang*,CAO Huafeng
(1.The Internet of Things Engineering,Jiangnan University,Wuxi Jiangsu 214122,China;2.The No.58 Institute of CETC,Wuxi Jiangsu 214035,China)
A Power Optimization Strategy of Directive Cache on DSP*
SHAN Yueer1,2,YANG Bing1,2,YU Zongguang1,2*,CAO Huafeng1
(1.The Internet of Things Engineering,Jiangnan University,Wuxi Jiangsu 214122,China;2.The No.58 Institute of CETC,Wuxi Jiangsu 214035,China)
Power target has become much stricter for high-performance DSP design.An improved Cache power optimization strategy is put forward,directive Cache phased access is realized,and at the same time,the optimization of power cache and static leakage power is taken into account,which improves traditional optimization methods to raise processor performance.As a result,traditional NPOWP strategy has a significant affect on the processor performance.According to the results of different strategy simulations,it is applied to the design of a four-group connected instructions Cache,using the POWP strategy can reduce the average 75.4%of the instruction Cache power and the total processor power consumption 6.7%with the performance loss of only 0.77%.
DSP;cache power optimization;NPOWP strategy;static leakage power;power optimization strategy
随着DSP性能越来越高,在DSP设计中如何解决动态功耗是一个日益突出的问题。指令Cache由于其较高的访问频率,已是DSP动态功耗主要消耗源。随着半导体工艺尺寸的日益缩小,特别是当工艺尺寸降低到65 nm以下时,指令Cache中的漏流功耗已逐渐成为总功耗的主要组成部分。通过使用Wattch[1]功耗模拟器对65 nm工艺条件下主频为2 GHz的DSP指令Cache进行功耗模拟可发现:指令Cache每周期消耗的漏流能量与每次被访问时消耗的动态能量相当。在超深亚微米工艺条件下,降低指令Cache的功耗需要同时考虑漏流功耗和动态访问功耗。本文提出了一种Cache功耗优化策略应用于DSP设计中,在尽可能减少性能损失的前提下,有效地实现更优的处理器能量效率。
1 指令Cache结构
为了减少性能损失,目前对于指令Cache中的存储单元使用的低漏流电路主要是采用昏睡Cache[2]中的状态保留低漏流SRAM结构。Cache块中存储的数据在低漏流昏睡模式下可以保持,额外的访存延迟主要来自于低漏流模式与正常活跃模式之间的状态转换。目前主流的各种面向指令Cache的漏流功耗优化策略都是在降低指令Cache的漏流功耗与减少由唤醒延迟造成的性能损失之间寻找平衡点,以达到最佳的处理器能量效率。
2 Cache功率优化策略
对于DSP昏睡指令Cache的体系结构漏流功耗优化,休眠主要采用未访问策略[3],该策略以Cache块为粒度进行低功耗控制,如果一个Cache块被访问后经过一定时间未再次访问,则设置为低功耗模式。唤醒策略主要有唤醒顺序组(Set)策略[4]、唤醒顺序块策略[5]、按需唤醒策略[6]。利用这几种策略组合提出的PDSR(Periodically Drowsy Speculatively Recover)策略[7-8]采用了简单循环刷新休眠策略与唤醒顺序块的唤醒策略。Chung S W等通过改进前段流水线结构实现了一种改进型的按需唤醒策略[9]。在传统前端流水线中实现使用分支预测的组预测方法比较困难,将通过调整流水线结构,改进传统的基于分阶段访问Cache的按需唤醒策略,提出基于分阶段访问策略,一方面可以解决传统流水线结构中分支跳转情况下的预唤醒失效问题,另一方面可以在提高Cache块关闭率的同时,减少由流水线重启和路预测失效所造成的性能损失。
2.1NPOWP策略
NPOWP(Non-Phased Cache with On-Demand Wakeup Prediction)策略的前端流水线结构通过在取指站与地址产生之间增加一个额外的唤醒站,对Cache块的唤醒操作恰好在该Cache块被访问的前一拍进行,除了正在被访问的Cache块,其他Cache块的标识单元与数据单元均处于昏睡状态,在任何时刻,整个Cache中最多只有被访问的Cache块处于活跃状态,因此NPOWP策略可以实现接近最高的Cache关闭率。虽然NPOWP策略可以解决传统流水线结构中分支跳转情况下的预唤醒路预测失效问题,而且可以实现接近理想的Cache关闭率,但是却引入了新的问题,即性能损失比较明显。
2.2POWP策略
为了在Cache功耗降低和程序执行时间增加之间找到一个最佳平衡点,我们改进了NPOWP策略,主要目的是消除路预测失效所产生的气泡,提高流水线的执行效率,既然在前段流水线中已经增加了额外的唤醒站,我们将充分利用借鉴“分阶段”方式访问Cache的思想,提出基于分阶段访问Cache的按需唤醒策略POWP(Phased Cache with On-Demand Wakeup Prediction),Cache的访问被分为两个阶段,标识整列和数据阵列分别在两个相邻的流水站被访问。在POWP策略的前端流水线中,对指令Cache的标识阵列的访问,从取指站提前到唤醒站,对数据阵列的访问仍然在取指站进行。标识阵列一直处于活跃状态,而且每次访问,被访问Cache组中所有路的标识单元同时被访问。在唤醒站,以“组”为粒度进行唤醒,被访问组中所有路的Cache块的数据单元就可以获得所需的数据。在POWP策略中不再使用路预测器,因为对指令Cache当前被访问组中Cache块数据单元的访问是按照真实的标识匹配信息进行,可以认为实现了100%的路预测命中率。
2.3NPOWP与POWP对比
当使用POWP策略时,由于没有对标识阵列的漏流功耗进行控制,因此总的来说,使用POWP策略时对Cache漏流功耗的优化效果不如使用NPOWP策略时的优化效果。不过,在目前的高性能处理器中,一般会采用大尺寸的Cache块,Cache块中标识单元的位数远远小于数据单元的位数,因此整个标识阵列的漏流功耗在整个Cache漏流功耗中所占的比重较小。例如,一个Cache块的数据单元的容量为256 bit,标识单元的位数为40 bit,标识阵列的漏流功耗约等于16%。
POWP策略的优势在于使用真实的标识比较结果作为访问Cache块数据单元的路选信息,相当于实现了100%的路预测命中率,因此完全消除了传统的NPOWP策略中由于路预测失效所带来的流水线气泡。
先前的指令Cache功耗优化策略要么是针对指令漏流,要么是针对动态功耗,没有很好的将两方面结合起来。因此本文提出了一种面向改进型前段取指流水线结构的指令Cache功耗优化技术:首先阐述NPOWP的工作原理和工作过程,然后建立使用NPOWP的前段流水线结构;最后对模拟结果进行分析并结合实际应用于DSP中的测试结果,对该优化策略做出综合评价。
NPOWP策略的性能损失主要来源于路预测失效和分支误预测。
(1)路预测命中时,唤醒延迟可以通过流水线重叠得到隐藏,不额外消耗系统资源,因此不会占用流水线节拍,但是如果路预测失效的情况下,流水线执行过程需要额外消耗两个节拍,一个节拍是由于需要唤醒当前被访问组中除去被预测Cache块以外的剩余Cache块,另一个节拍是由于需要访问这些剩余的Cache块。因此会产生2个周期的延迟。
(2)假设在传统的昏睡指令Cache中分支预测错误的延时为2个时钟周期,如果指令i在时刻t从取值站取出,当它达到执行站出现分支预测错误,则子下一拍写回站中重新进行地址产生。在理想的情况下,需要对流水线进行细致调整才能隐藏唤醒延时,实际上在通常的NPOWP策略中,分支预测错误会导致1个时钟周期的额外唤醒延时,因此,分支预测所造成的流水线重启会增加3个时钟周期的延时。
综上所述,虽然NPOWP策略可以更大程度的提高昏睡的Cache块数目,但是由于程序执行时间的增加而产生的额外功耗会抵消NPOWP策略对Cache能耗的优化效果,并随之而来的较大性能损失对于高性能DSP处理器来说,是不能接受的。
3 试验结果
通过对SPEC CPU2000测试程序的模拟,可对提出的POWP策略在降低指令Cache综合功耗方面的效果。由于采用的优化策略中需要增加部分的控制逻辑和寄存器,因此会带来额外的功耗,在模拟器中首先对这部分的硬件功耗进行了建模,根据ITRS预测[10]在65 nm工艺下处理器静态能量与动态能量相当,采用的是一个应用于DSP设计中的4路组相连Cache结构,指令Cache容量为64 kbyte、采用4路组相连,Cache块大小为32 byte。
在模拟器上除了实现提出的POWP策略,还实现了4种传统的指令Cache功耗优化策略,包括Noaccess策略,PDSR策略,Noaccess-JITA策略和NPOWP策略,并进行比较。
(1)图1为使用各种指令Cache功耗优化策略时的标准化程序执行时间。传统的NPOWP策略由于增加额额外的流水线站,流水线中的额外节拍或者重启导致了程序执行性能的显著下降,性能损失达到3.23%。传统的Noaccess、PDSR、Noaccess-JITA策略,性能损失分别为0.56%、0.41%、0.49%。使用了我们提出的PWOP策略能够有效的改善对性能的影响,性能损失为0.77%,显著低于NPOWP策略。

图1 各种指令Cache功耗优化策略时的标准化程序执行时间
(2)图2为使用各种功耗控制策略时的路预测命中率。对于Noaccess、PDSR与POWP策略,由于未采用路预测机制可以认为其路预测命中率为100%。使用Noaccess-JITA策略命中率为97.7%,NPOWP策略的命中率为97.6%。
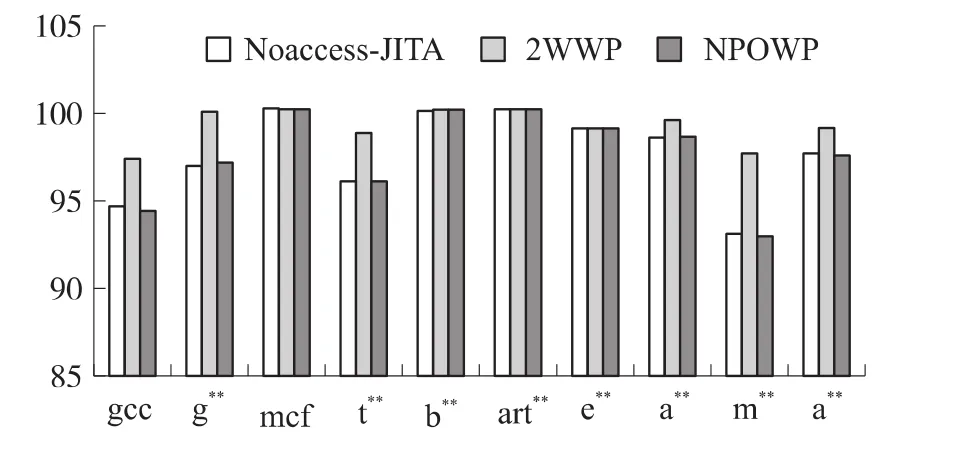
图2 使用各种功耗控制策略时的路预测命中率
(3)图3比较了各种指令功耗优化策略对指令Cache关闭率的影响。更高的关闭率意味着更低的漏流功耗。在Noaccess策略中,Cache块只有在一定的衰退时间内未被再次访问,才会被转换到昏睡状态,因此关闭率较低,平均仅为84.4%。PDSR策略在Noaccess策略基础上,还会额外唤醒Cache中当前被访问组的后继组中的所有Cache块,因此关闭率更低,只有78.7%。Noaccess-JITA由于使用了路预测策略,因此相对于PDSR又提高了关闭率,恢复到与Noaccess策略相当的水平。NPOWP以及我们提出的POWP由于均采用了按需唤醒的策略,因此可以实现最高的Cache关闭率,达到了99%以上。
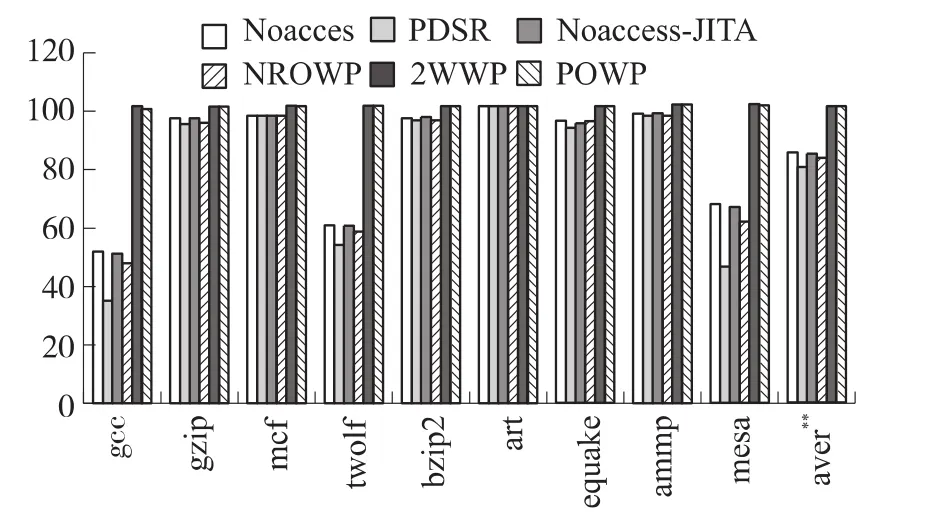
图3 各种指令功耗优化策略对指令Cache关闭率的影响

图4 各策略对指令Cache的功耗的优化能力
(4)图4表示了各策略对指令Cache的功耗的优化能力。NPOWP和POWP策略与传统的Noaccess、PDSR、Noaccess-JITA策略能够更显著地降低功耗,主要原因是传统策略没有将动态和漏流进行综合考虑。使用了NPOWP策略,功耗降低到之前的24.6%,使用POWP策略,功耗降低到之前的36.9%。单从降低功耗考虑,NPWOP是最佳的,但是其付出的性能损失代价是高性能处理器无法接受的,而我们提出的PWOP能够在功耗和性能之间实现更优的平衡。
(5)图5表示了使用标准化处理器功耗作为评价各种指令Cache功耗优化策略最终对处理器功耗的影响。使用POWP策略,处理器功耗降低到优化前的93.3%,性能损失仅为0.77%。使用NPOWP策略时,处理器功耗降低到91.1%,但是性能损失达到3.23%。
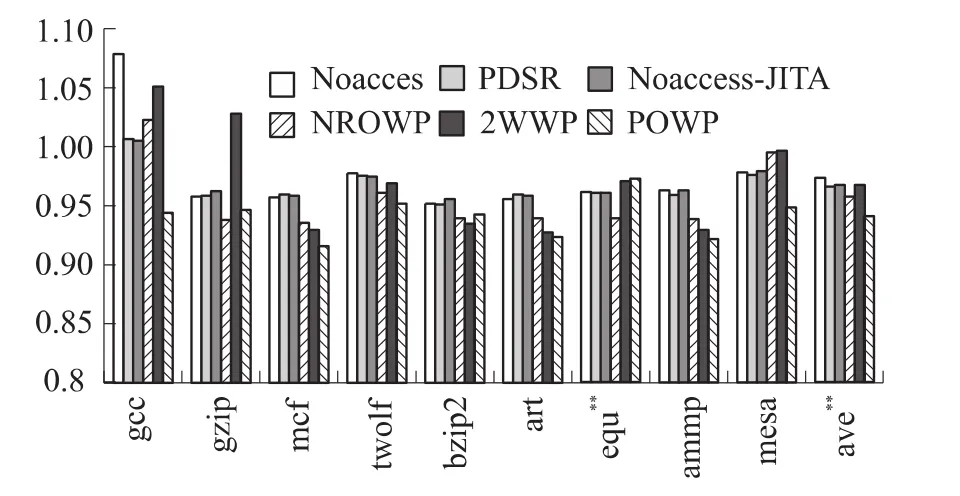
图5 各种指令Cache功耗优化策略最终对处理器功耗的影响
4 结论
试验结果表明,对于增加了唤醒站的改进的前端流水线结构,我们提出的POWP策略改进了传统的NPOWP策略显著影响的处理器性能不足。实现了对指令Cache的分阶段访问,实际的标识匹配结果用于对Cache块数据单元的访问,相当于实现了100%的路预测命中率。该设计应用于DSP设计的4路组相连昏睡指令Cache中,使用POWP策略平均可降低75.4%的指令Cache功耗,降低6.7%的处理器总功耗,性能损失仅为0.77%。与传统指令Cache功耗优化策略相比,明显取得了更好的效果,有效地兼顾了Cache的漏流功耗和动态功耗的优化,进一步改善了处理器的总功耗和能量效率。
[1]Brooks D,Tiwari V,Martonosi M.Wattch:A Framework for Architectural-Level Power Analysis and Optimization[C]//Proceedings of the 27th Annual International Symposium on Computer Architecture(ISCA’00),83-94,June 2000.
[2]Flautner K,Kim N S,Martin S.Drowsy Caches:Simple Techniques for Reducing Leakage Power[C]//ISCA2002,147-157,2002.
[3]Kim N S,Flautner K,Blaauw D.Circuit and Microarchitectural Techniques for Reducing Cache Leakage Power[J].IEEE Transaction on VLSI Systems,2004,12(2):167-184.
[4]Zhang C,Zhou H,Zhang M.An Architectural Leakage Power Reduction Method for Instruction Cache in Ultra Deep Submicron Microprocessors[C]//The 11th Asia-Pacific Conference(ACSAC 2006),588-594,September,2006.
[5]Skadron K,Stan M,Velusamy S,et al.Temperature-Aware Micro Architecture[J].In Proc.Int.Symp.Computer Architecture,1-12,June 2003.
[6]Chung S W,Skadron K.Using Branch Prediction Information for Near-Optimal I-Cache Leakage[C]//The 11th Asia-Pacific Conference(ACSAC 2006),September 2006:24-37.
[7]张承义.超深亚微米处理器漏流功耗的体系结构级优化技术研究[D].长沙:国防科学技术大学研究生院,2006.
[8]Zhang Chengyi,Zhang Minxuan.Reduce Static Power Dissipation of On-chip L2 Cache[C]//The 9th IEEE symposium on Low-Power and High-Speed Chips,IEEE Computer Society,Yokohama,Japan,April 2006:215-222.
[9]Kim N S,Flautner K,Blaauw D.Single-VDD and Single-VT Super-Drowsy Techniques for Low-Leakage High-Performance Instruction Caches[C]//In International Symposium on Low Power Electronics and Desigh.Newport Beach,CA,U.S.A.,August,2004:54-57.
[10]SIA.R-International Technology Roadmap for Semiconductors[R].2003.

单悦尔(1979-),男,江苏无锡人,博士研究生,高级工程师。2001年毕业于东南大学,进入中国电子科技集团公司第五十八研究所工作,从事军用高性能数字信号处理器(DSP)研发工作,曾担任”数字信号处理器系列型谱”首席专家,多次获得集团科学技术进步一等奖、二等奖,reio_shine@126.com;

于宗光(1964-),男,山东潍坊人,中共党员,研究员,工学博士,博士生导师,先后负责了30多项国家重点项目,全部通过部省级鉴定,取得了较好的经济效益,先后获部省级科技进步奖20次,其中作为第一完成人,获部级科技进步一等奖两次,二等奖4次。是江苏省“333工程”领军人物,国防科技“511”学术带头人,国务院政府特殊津贴专家,江苏省有突出贡献的中青年专家,“百千万”人才工程国家级人才,国家核高基重大专项实施专家组成员。在超大规模集成电路设计领域有着较高的学术造诣和丰富的实际工作经验,yuzg@cetc58.com。
EEACC:257010.3969/j.issn.1005-9490.2015.01.045
一种DSP指令Cache的功耗优化策略*
单悦尔1,2,杨兵1,2,于宗光1,2*,曹华锋1
(1.江南大学物联网学院,江苏无锡214122;2.中国电子科技集团公司第五十八研究所,江苏无锡214035)
高性能DSP器件对功耗指标要求越来越高,功耗主要来源于对存储空间的访问,因此提出了一种改进型Cache功耗优化策略,实现了对指令Cache的分阶段访问,同时兼顾了Cache的动态功耗和静态漏流功耗的优化,改进了传统的基于非分阶段访问的按需唤醒策略NPOWP(Non-Phased Cache with On-Demand Wakeup Prediction)显著影响处理器性能的缺点。设计应用于DSP设计的4路组相连昏睡指令Cache中,使用基于分阶段访问的按需唤醒策略POWP(Phased Cache with On-Demand Wakeup Prediction)策略平均可降低75.4%的指令Cache功耗,降低6.7%的处理器总功耗,性能损失仅为0.77%.
DSP;Cache功耗优化;NPOWP策略;静态漏流功耗;功率优化策略
TN47;TN73
A文献标识码:1005-9490(2015)01-0214-04
2014-02-17修改日期:2014-03-29
项目来源:江苏省333工程科研项目(BRA2011115)
猜你喜欢
汉语世界(The World of Chinese)(2023年2期)2023-06-22 14:50:17
科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10
小学科学(学生版)(2020年2期)2020-03-03 13:40:16
测控技术(2018年5期)2018-12-09 09:04:26
电子测试(2018年18期)2018-11-14 02:30:34
个人电脑(2016年12期)2017-02-13 15:24:40
电子制作(2016年19期)2016-08-24 07:49:54
中国资源综合利用(2016年9期)2016-01-22 08:35:22
电子世界(2015年22期)2015-12-29 02:49:44
电源技术(2015年11期)2015-08-22 08:51:02

- 电子器件的其它文章
- The Implementation of CRC Algorithm Based on FPGA
- The Implementation of DDFS by Using Six Segments QLA Algorithm
- Design of Intelligent Indoor Air Purification System*
- Design of Oxygen Concentration Detection Based on WiFi and Cloud Intelligent*
- Design of the Efficient Control System of Automatic Meteorological Station*
- Design and Implementation of Robust Smart Agricultural Control System*