
基于图像特征索引的并行检索技术研究
2015-10-13 01:02:53蔡晓东陈文竹
电视技术 2015年13期
蔡晓东,华 娜,吴 迪,陈文竹
(桂林电子科技大学 信息与通信工程学院,广西 桂林 541004)
基于图像特征索引的并行检索技术研究
蔡晓东,华 娜,吴 迪,陈文竹
(桂林电子科技大学 信息与通信工程学院,广西 桂林 541004)
为了提高建立索引、检索图像的速度,提出云架构上基于图像特征索引的并行检索系统。该检索系统主要有3个模块:海量小图片分布式存储(Store)、并行建立图像特征索引(Indexing)、并行图像检索(Retrieve)。在Store模块中提出针对海量图片的合并存储,Indexing模块中提出索引缓存模式,避免重写索引的输出接口,Retrieve模块中对索引进行分片管理,以及并行检索。实验结果表明,相对于其他图像检索系统,基于图像特征索引的检索系统有效减少了图像特征索引建立时间,缩短了图像的检索时间,提高了图像检索速率。
分布式存储;特征索引;并行检索;分片管理
近年来,图像数据量急剧增长,如何有效地检索这些海量图像成为一个迫切需要解决的问题。传统图像检索方法是基于文本的,检索结果依赖于对图像的文字描述而不是图像的内容,造成图像的查准率不高,因此需要直接从待查找的图像视觉特征出发,通过图像的颜色、形状、纹理等特征进行图像检索。基于内容的图像检索[1]中提取的图像特征都是高维的,特征匹配就意味着检索高维的数据。当图像数据量很大时,单机上基于内容的图像检索速率面临巨大的挑战。
Hadoop[2]是Apache下用于分布式计算的开源软件框架,可以使大量的数据在集群上并行处理,在大数据领域得到广泛应用。因此,本文提出Hadoop平台上基于内容的图像检索系统。
1 相关工作
1.1 基于内容的图像检索
基于内容的图像检索技术分为两步,即特征提取和特征匹配。
1.1.1 特征提取
图像特征提取是基于内容的图像检索的基础,常用的特征是颜色特征、形状特征、纹理特征。由于一种特征总是存在无法克服的缺陷,或者检索太慢,或者匹配效果差,目前很多检索技术都是综合多种特征,因此本文采用图像局部不变特征SIFT与颜色特征相结合。
SIFT[3]是一种基于尺度空间对图像缩放、旋转、光照、变化甚至裁剪、遮挡等保持不变性的点特征提取算法。主要包括4个步骤:1)检测尺度空间的极值;2)定位关键点;3)根据图像的局部梯度方向,给关键点分配方向;4)用特征向量来描述关键点。
颜色特征是图像特征中最显著、最可靠的视觉特征,它对图像本身的尺寸、方向、视角的依赖性较小,从而具有较高的鲁棒性。本文用颜色直方图来表达颜色特征。 颜色直方图表达了颜色的空间分布信息,统计每种颜色分量的像素数占图像总像素数的比例。
给定一幅图像(fxy)M*N,fxy表示像素点(x,y)处的颜色值,M×N表示图像的尺寸,图像所包含的颜色集记为C,则图像的颜色直方图可表示为

(1)
1.1.2 特征匹配
特征匹配过程是计算样本图像与目标图像之间的相似度,获得与样本图像最相似的图像。测量两幅图像之间相似度通常是计算图像特征向量之间的距离,如欧氏距离、马氏距离。本文采用欧氏距离来比较图像相似度,欧氏距离定义如下
(2)
式中:Ai和Aj表示两幅图像的特征向量;r是向量的维数。特征向量间欧氏距离越小,则相似度越大。
1.2 Hadoop
Hadoop[5]是一个分布式的计算框架,主要由HDFS、MapReduce组成。HDFS是用于存储大数据的分布式文件系统。MapReduce是用于处理数据的分布式框架,数据处理过程分为两步:Map和Reduce。Map阶段处理输入的数据分片,并输出中间的key-value对。将具有相同key值的key-value对输入Reduce,处理后输出最终的key-value对。
2 并行图像内容检索系统设计
2.1 系统结构
本文设计的并行图像内容检索系统主要3个模块:海量小图片分布式存储(Store)、并行建立图像特征索引(Indexing)、并行图像检索(Retrieve),结构如图1所示。

图1 Hadoop平台上基于内容的图像检索结构图
2.2 海量小图片分布式存储(Store)
Hadoop是针对大数据来设计的,处理海量小文件时非常消耗内存资源,导致效率很低。为了避免Hadoop处理海量的小文件,通常是将小文件组织起来生成MapFile,并自动上传至HDFS进行分布式存储。但MapFile一般针对于文本文件,因此本文提出了针对海量图片数据生成MapFile。
MapFile是排序后的SequenceFile,由两部分组成:分别是data和index。index作为文件的数据索引,主要记录了每个图片的文件名,以及该图片在MapFile文件中的偏移位置。在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定图片所在文件位置,并且添加图像时,需要先将图像的文件名按照字典序排序。
2.3 并行建立图像特征索引(Indexing)
图像索引模块中,本文设计了MapReduce[4]框架上并行建立图像特征索引。由于索引Document不支持MapReduce输出类型的Writable接口,所以不能直接使用Document作为MapReduce的输出。因此本文提出了一种索引缓存模式,在内存中并行建立索引,map任务结束后将内存中的索引存入HDFS,该方法有效提高了建立索引的速度。图像特征索引创建流程如图2所示。

图2 用MapReduce并行创建图像特征索引
1) InputFormat:将HDFS中图像的MapFile作为输入,由于MapFile是排序后的SequenceFile,因此将文件输入格式写为SequenceFileInputFormat。
2)SequenseFileRecordReader:该类将读入的MapFile分片解析成键值对(Text key,BytesWritable value),key为图像文件名,类型为Text,value为图像内容,类型为BytesWritable。
3)Mapper:Mapper阶段处理由SequenceFileRecordReader解析出的(key,value)键值对。提取出图像的SITF与颜色特征,通过Lucene在内存中根据图像特征建立特征索引,特征索引建立结构如图3所示。最后在close()阶段将内存中的索引存入HDFS。

图3 索引结构图
2.4 并行图像检索(Retrieve)
在科技配置方面,锐骐6也毫不含糊。一键启动、无钥匙进入、倒车影像、倒车雷达、胎压监测等诸多乘用车配置均出现在锐骐6车上。高清倒车影像,附带彩色动态辅助线,便于驾驶员判断车辆与障碍物的距离,引导驾驶员安全倒车。胎压监测系统,则能时刻监测胎压情况,保障用车安全。
图像检索时需要在很短的时间内获取检索结果,而MapReduce框架是用来做离线处理的,因此MapReduce并不适用于图像检索。本文提出一种在线并行检索系统,将存储在HDFS中的索引用Katta进行分片部署,将索引分片存储在各子节点上。检索时,同时读取各节点的索引分片进行检索,然后将获得的所有检索结果中前10个合并,并按照从小到大的顺序排序。最终得到特征距离最小的10张图像的名称,只需从图像的MapFile中按文件名获取图像。
3 实验分析
3.1 实验环境
软件环境:Linux操作系统,JDK1.7,Hadoop1.2.1,Opencv、Javacv计算机视觉库,Lucene。
硬件环境:实验使用3个节点,每个节点配置双核Intel CPU,4 Gbyte内存。
3.2 并行创建索引实验结果分析
实验图像总共50 000张,来源于加州理工学院101类图像数据库,加州理工学院256类图像数据库,其中部分图像重复,但具有不同的文件名。将不同张数的图像生成MapFile分别上传至HDFS,使用MapReduce进行离线并行图像特征索引创建,实验对单机建立索引和分布式建立索引的时间进行对比,如图4所示,图中横轴为图像的张数,纵轴为建立索引所用时间。
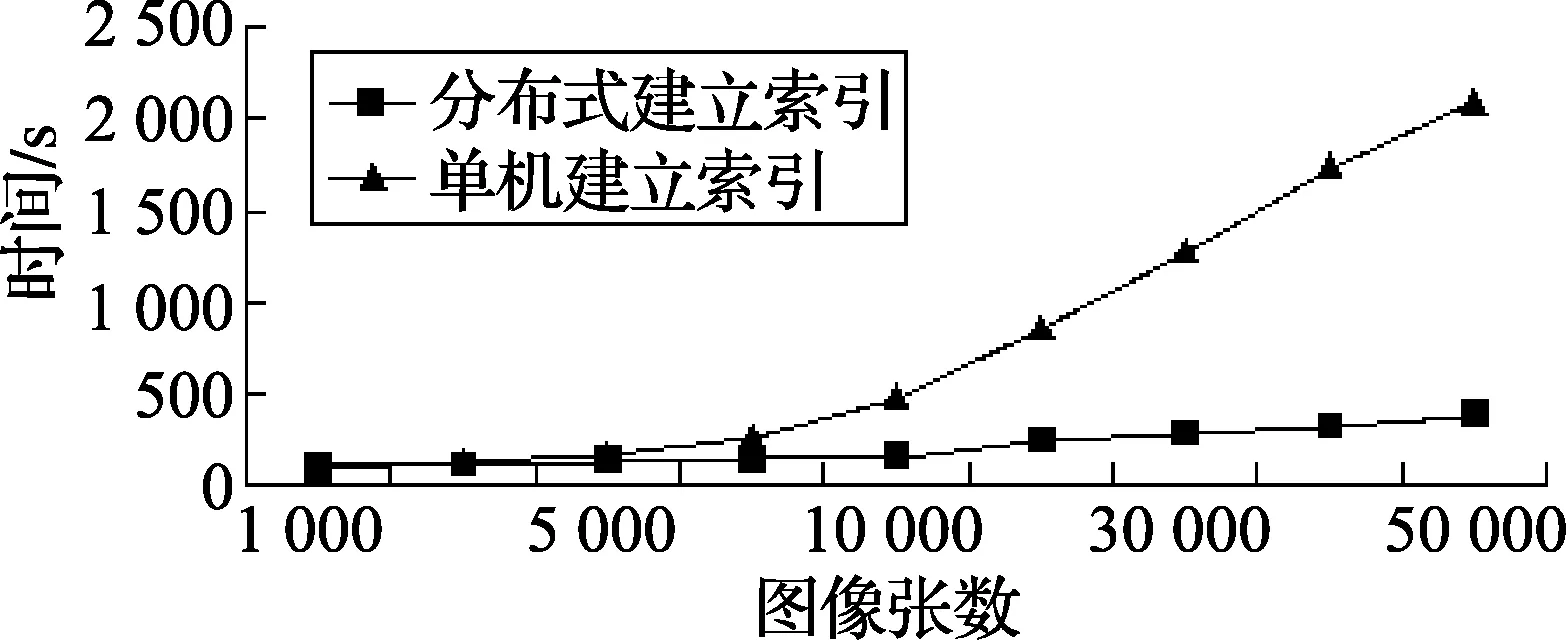
图4 单机建立索引与分布式建立索引时间对比
3.3 在线图像检索实验结果分析
实验HDFS中的索引进行分片管理,将索引分片存储在各子节点本地上,由此进行图像的并行检索,实验对图像单机检索和并行检索的时间进行对比,结果如图5所示,图中横轴为图像的张数,纵轴为图像检索所用时间。
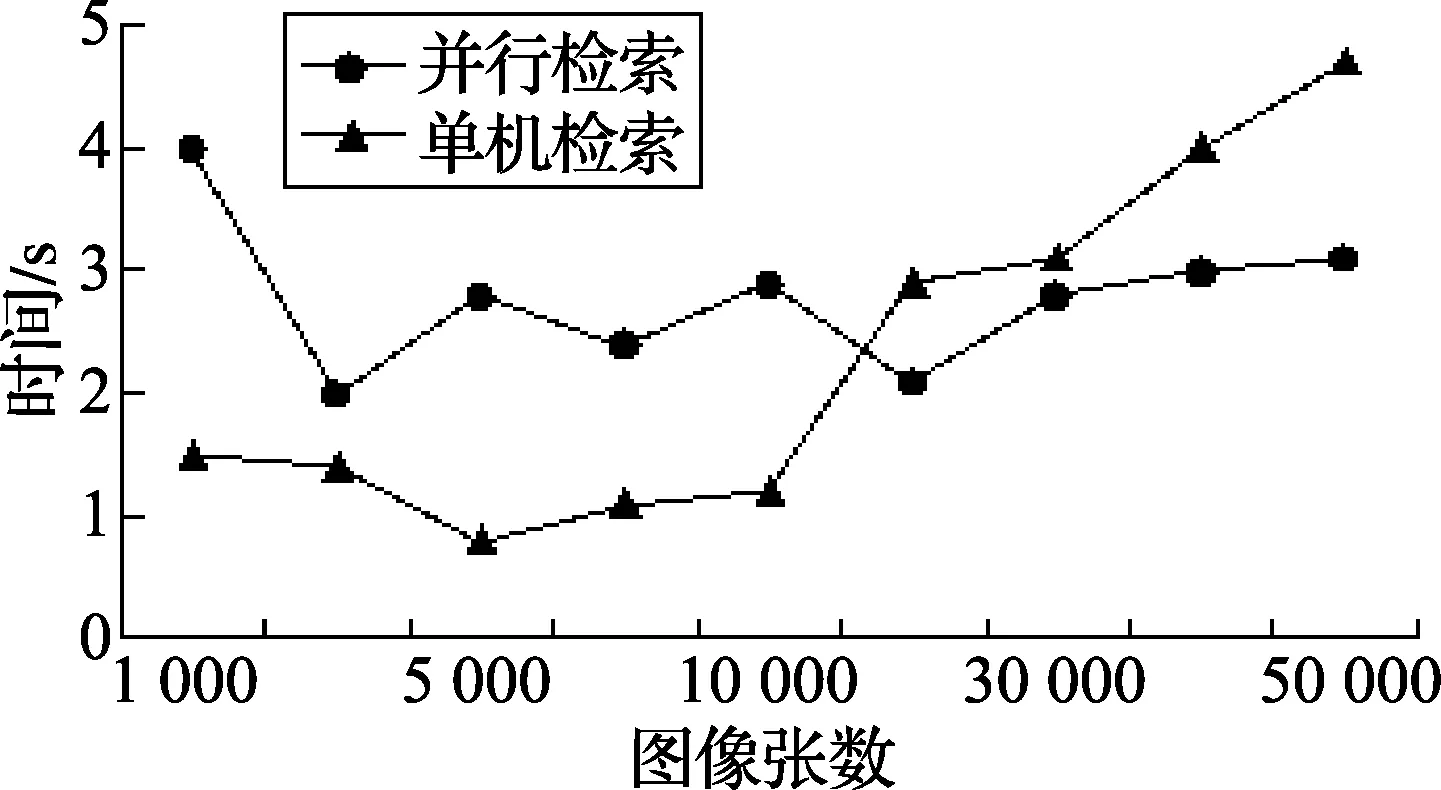
图5 单机检索与分布式检索时间对比
由图5可知,图像数据少时,单机进行检索所需时间较少,由于节点间需要通信,所以并行检索所需时间较大;随着数据量增大,单机检索所花费的时间在直线增长,而并行检索花费的时间增长缓慢。当图像数量到5万张时,并行检索速度较单机检索速度提高了33 .3%,并行检索速度与文献[6]相比提高了20%。
3.4 图像查准率、查全率
本实验采用信息检索中标准的评估方法:查准率、查全率来对提出的设计进行评估。
查准率是指在一次查询过程中,返回的查询结果中的相关图像数目r与在所有返回图像数目N中占有的比例,表示为
Precision=r/N
查全率指在一次查询过程中,返回的查询结果中相关图像的数目r在图像库中所有相关图像数目R中占有的比例,公式表示为
Recall=r/R
实验在50 000张图像中随机抽取4张图像进行检索,在图像库中每张图像的相关图像共10张,将检索结果按照图像间的距离升序排列,图像查准率、查全率如表1。

表1 图像差准率、查全率 %
以上实验结果表明,本文提出的基于图像特征索引的并行图像检索系统具有相对较高的查全率与查准率。
4 小结
经过以上分析,基于图像特征索引的并行检索系统大大减少了建立图像特征索引时间和基于内容检索图像的时间;SIFT特征与颜色特征结合建立索引,达到了较好的检索效果,该系统有效解决了单机下对海量图像检索效率低的问题。
[1] ZHANG C,CHEN T. An active learning framework for content-based information retrieval[J].IEEE Trans. Multimedia,2002,4(2):260-268.
[2] Hadoop[EB/OL]. [2014-04-16].http://www.Hadoop.org.
[3] DAVID G L. Distinct image features from local scale-invariant keypoints[J]. International Journal of Computer Vision,2004,60(2):91-110.
[4] DEAN J,GHEMAWAT S. MapReduce:simplified data processing on large clusters[C]//Proc. Symposium Conf. Opearting Systems Design & Implementation.[S.l.]:IEEE Press,2004:107-113.[5] 刘炳均,戴云松.基于超算平台和Hadoop的并行转码方案设计[J].电视技术,2014,38(7):123-126.
[6] JAI-ANDALOUSSI S,ABDELJALIL E. Medical content based image retrieval by using the hadoop Framework[C]//Proc. Casablanca Conf. Telecommunications(ICT).[S.l.]:IEEE Press,2013:1-5.
蔡晓东(1971— ),博士,副教授,主研并行化图像和视频处理、模式识别与智能系统;
华 娜(1988— ),女,硕士生,主研云计算、视频图像数据挖掘;
吴 迪(1989— ),女,硕士生,主研云计算、智能视频图像处理;
陈文竹(1988— ),硕士生,主研云计算,视频图像数据挖掘。
责任编辑:时 雯
Parallel Retrieval System Based on Image Feature Index
CAI Xiaodong,HUA Na,WU Di,CHEN Wenzhu
(SchoolofInformationandCommunicationEngineering,GuilinUniversityofElectronicTechnology,GuangxiGuilin541004,China)
In order to improve the speed of indexing and retrieving images,the parallel retrieval system based on image features index in cloud is proposed. The retrieval system mainly consists of three parts,the distributed store of massive small images(Store),building index of image features in parallel(Indexing),image retrieval in parallel(Retrieve). In the part of store,the combined storage for massive small images is proposed,in the part of Indexing,in order to avoid rewriting the output interface of index,the mode for caching index is proposed,in the part of Retrieve,by the fragmented management for features index,it proposes the image retrieval in parallel. The experimental results show that the retrieval system reduces the time for indexing and retrieving effectively,it improves the speed for image retrieval.
distributed store;features index;retrieve in parallel;fragment management
【本文献信息】蔡晓东,华娜,吴迪,等.基于图像特征索引的并行检索技术研究[J].电视技术,2015,39(13).
国家“863”计划项目(2012BAH20B01;2014BAK11B02);广西自然科学基金项目(2012GXNSFAA053232;2013GXNSFAA019326);广西高校科学技术研究项目(2013YB092)
TN911.73;TP3
A
10.16280/j.videoe.2015.13.005
2014-10-07
猜你喜欢
词学(2022年1期)2022-10-27 08:06:12
新疆钢铁(2021年1期)2021-10-14 08:45:36
数学物理学报(2020年5期)2020-11-26 06:06:48
广东通信技术(2020年10期)2020-10-26 06:36:52
航天工业管理(2019年11期)2019-04-20 07:05:38
火控雷达技术(2018年4期)2019-01-15 05:07:22
信号处理(2018年1期)2018-09-03 07:53:04
信号处理(2018年5期)2018-06-28 02:16:02
信号处理(2018年4期)2018-06-27 03:34:16
信号处理(2018年3期)2018-06-27 03:30:18
