
基于科技论文摘要双语平行语料库的科技英语教学模式
2015-10-09 01:58:26江西理工大学外语外贸学院江西赣州341000
江西理工大学学报 2015年2期
(江西理工大学外语外贸学院,江西 赣州341000)
(江西理工大学外语外贸学院,江西 赣州341000)
概述了有色冶金科技论文摘要双语平行语料库的建设过程,利用该语料库作为研究平台,运用Wordsmith,ParaConc等语料库软件引导学生参与数据驱动翻译教学实践,比较基于语料库的数据驱动翻译教学方法与传统翻译教学方法在教学效果方面存在的差异。结果表明,将汉英双语语料库作为翻译教学平台进行数据驱动科技英语翻译教学实践,比传统翻译教学更能激发学生对翻译的兴趣,教学效果更加显著,可有效提高学习者的汉英科技翻译水平。
科技论文摘要;平行语料库;数据驱动翻译教学;传统翻译教学;教学平台
一、引 言
论文摘要指以提供文献内容梗概为目的,不加评论和补充解释,简明、确切地记述文献重要内容的短文。科技论文摘要概括论文的主要信息,对研究的目的、方法、结果和最终结论有一个比较完整的说明,提供了原始文献所包含的主要概念和所讨论的主要问题,是一篇内容高度浓缩的完整短文。科技论文摘要对于论文的发表、收录、检索及科研人员的学术交流等起着重要的作用。当今时代,英语已成为国际交往的世界性语言,英文学术论文摘要的重要性日益显现。近年来,不少学者对论文摘要的语言特点与翻译进行了比较广泛深入的分析,其成果无疑有利于该领域的实践与发展。然而,大多数相关研究都是基于研究者个人的经验,基于选取一定数量例句的传统方法,选取的例句和掌握的语料比较有限。
语料库是指按照一定的语言学原则,运用随机抽样方法,收集自然出现的连续语言运用文本或话语片段而建成的具有一定容量的大型电子文本库[1]。语料库具有语料真实、丰富、代表性强以及融合了计算机技术等特点,在语言研究和教学方面具有较大的优势与应用价值。平行语料库收集原文与译文双语对照的文本,按设定的标准对语料进行句子或段落的对齐。李德超(2010)指出平行语料库常用于考察原文中的某些语言现象如何在译文中得到反映,对其研究可揭示翻译活动中隐性的规律[2]。秦洪武(2007)认为,将双语对应语料库应用于翻译教学有利于创造自主学习的环境,有助于翻译教学和技能培养水平的提高[3]。
数据驱动教学(data-driven learning,简称DDL)是一种新的基于语料库数据的外语教学方法。它的主要思想是指引学生基于大量的语料库数据观察、概括和归纳语言使用现象,自我发现语法规则、意义表达及语用特征。DDL能够使学生根据各自的程序,需求和兴趣,利用高速运行的检索手段进行探索式、发现式或验证式学习,是其他非电脑语料库方式难以实现的。 研究表明,学习者不仅喜欢通过大量真实的语言运用实例来学习,而且享受这种探索式的学习方式[4]。
关于将双语语料库应用于翻译教学和数据驱动教学方法的应用,以上研究大部分是概述性的,主要是介绍这些方法的思想原理、操作方法与特点;从总体上看,有关运用语料库提高翻译效率和质量的研究还没有全面展开,还没有研究系统地探讨基于汉英双语语料库的数据驱动翻译教学的应用方式和应用效果,尤其是缺乏相关实验数据的有效支撑[5]。鉴于此,本文以汉英双语语料库为翻译教学平台,运用数据驱动的教学方法,探讨在现有技术条件下翻译语料用于翻译教学可能产生的积极效果。
二、科技论文摘要汉英双语语料库的建设
在实际调研和文献考察的基础上,我们首先确定了语料库的研究方向,接着进行总体规划与设计,确定建库的目的、用途、规模、构成、语料的代表性和平衡性等。在具体建库的时候,综合考虑了地域、校本特色和应用目的等因素[6],建设的是一个“有色冶金期刊论文摘要汉英双语语料库”。本语料库由一个汉英双语平行语料库子库和一个英语单语可比语料库子库构成。其中的双语平行语料库子库包含中国知网2009~2013年间 SCI、EI来源期刊中的有关“稀土”和“钨”学术论文汉语论文摘要和与之对应的英文翻译,注重语料的代表性和翻译的权威性。研究组在对语料进行整理后,利用软件Paraconc对汉、英对应文本进行句子级别的粗略对齐,之后对每篇摘要人工调整对齐,最后输出并保存文本,总词数近 30万。英语单语可比语料库由英美国家期刊论文摘要和之前下载的国内期刊论文摘要英译本组成。英美国家期刊论文摘要来源于EBSCO外文期刊库的 Academic Search Premier数据库。以Rare Earths和Tungsten为关键词,下载、整理并保存2008~2012年间英美国家学术期刊中的相关论文摘要。此可比语料库包含英国、美国学术期刊论文英文摘要子库和国内期刊论文英译摘要子库各1002篇,总词数36万。
为方便深入检索和研究,研究组对库中的语料进行了词性标注,英文语料通过CLAWS软件完成,中文语料的分词和词性标注通过中科院计算所的ICTCLAS软件完成。本汉英双语语料库的总规模有 66万字词左右,主要应用于语言与翻译研究、教学研究以及行业实践等方面。
三、基于语料库的数据驱动翻译教学研究
结合语料库理论基础和相关研究结果,将科技论文摘要汉英翻译作为教与学的内容,开展了基于语料库的翻译教学实验研究,探索基于汉英双语语料库数据驱动的翻译教学实践活动对学生学习效果的影响,论证基于汉英双语语料库数据驱动的翻译教学的实践可行性,探索、发现、考察和体验该教学过程中可能存在的实际问题,为在大学科技翻译教学中实施基于语料库的教学提供优化策略或建议。
(一)研究问题
1.实验对象在科技论文摘要的汉英翻译方面存在哪些主要问题?
2.与传统翻译教学方法相比,基于双语对应语料库的数据驱动翻译教学方法能否更显著地提高实验对象的翻译成绩和翻译水平?
3.实验对象如何看待基于双语对应语料库的数据驱动翻译教学方法?
4.传统翻译教学方法和基于双语对应语料库的数据驱动翻译教学方法有何区别?
(二)实验对象
课题组选定了江西理工大学研究生2014级(研究生一年级)两个英语教学班分别作为实验班和对照班(见表1),原因在于研究生经过了入学考试,英语基础较好,而且有写作科技学术论文的要求,不少人在读研期间或今后有将学术论文投稿国外期刊的可能。要求实验班和对照班在英语水平、汉英翻译水平方面前测时无显著差异,这一点通过研究生考研升学英语成绩和第一次科技论文摘要的汉英翻译练习等予以确定 (实验班原来有75人,对照班有55人,通过人数调控将其控制在与对照班水平无显著差异的状态)。两班都是同一位老师授课,同一种教材,同样的学习时间,唯一差别就是实验班采用基于双语对应语料库的数据驱动翻译教学方法,对照班则采用传统的翻译教学方法。

表1 实验对象基本情况

表2 实验班和对照班第一次汉英翻译练习成绩统计结果
表2显示了两个班级学生成绩的基本统计情况,包括平均值、标准差和标准误。两班成绩均值、标准差基本相同,说明实验班与对照班成绩的两组数据变化趋势、分布走向非常相似。为进一步比较两班学生整体水平是否有显著差异,验证实验班和对照班能否作为实验对象,我们对两班成绩进行了独立样本 t检验。 结果显示,Levene方差齐性检验结果为:F=.010,p=.921,本研究的方差具有齐性。方差齐性分析分别给出两班成绩在总体方差齐和不齐时的t检验结果。我们选取方差齐时的t检验结果,即表12方差分析结果的第一行数据:t=-1.240,p=.218。从而最终得出统计结论为p>.05。从样本整体和均值来看,两个班级学生学习成绩不存在显著性差异,将实验班和对照班作为实验对象,从统计上来讲是可行的。
(三)实验过程
1.前测
通过前测检验学员在科技论文摘要英译中存在哪些主要问题,同时为后测的结果提供比较参考。除了取得这两个班研究生考研升学英语成绩之外,还通过前测(第一次翻译练习)确认实验班和对照班成员水平相当。具体做法是安排了一次上课时间让实验对象做一次科技论文摘要的汉英翻译练习,练习做完后上交。练习上交后对其复印,下一次上课发还给学生并要求其将电子稿以班级为单位发送到任课教师的邮箱。对这次前测的练习材料,两位老师对其进行了评分,标注并分析其中存在的典型错误,同时计划建一个小的学生翻译练习语料库库进行随后的研究。在做完第一次科技论文摘要的汉英翻译练习后,立即进行一个小型的问卷调查,也要求同学完成后立即上交。
2.采用传统翻译教学法和基于双语对应语料库的数据驱动翻译教学
接下的步骤是在两个班进行不同教学方法的对比操作。在学习之初,教师就向两个班的同学交代清楚,学期结束期末考试卷中一定会包含科技论文摘要汉英翻译的部分。本学期科技论文摘要汉英翻译的学习安排4周左右。传统翻译教学在对照班按计划进行,教师必须注意授课内容、课外作业、学生学习时间与实验班互相参照,确保两班只在教学方法上存在不同。传统翻译教学方法一般是向学生解释科技论文摘要的语言、文本特点及相应采取的翻译策略等。
实验班进行基于双语对应语料库的数据驱动翻译教学时注意以下:在实验班上简要讲授基于汉英双语语料库数据驱动的翻译教学理论依据,宏观方法和具体操作。教师将软件PARACONC和ANTCONC等跟本实验有关的软件操作给学生讲解清楚,同时将具体操作步骤以文字或图片形式保留,供学生随时参考。教师将双语对应语料库、软件、操作步骤等放在班级的公共邮箱,供学生下载。在课堂上,教师要求学生对汉英双语语料库中某些特别词汇、搭配和句型等进行检索、观察、纠错、讨论、归纳和总结,根据相关具体检索任务,教师还让学生自愿或随机指定学生上讲台演示,全班讨论,教师参与讨论等活动。教师建议学生将语料库应用于完成布置的课外作业,将课外与课堂学习相结合。
教师向学生演示如何运用语料库从微观的字词层面逐渐上升至句子、段落和语篇层面,由下至上地对中英文论文摘要的文本结构和文体特点有较深刻的了解,鼓励他们去解决具体的问题[7],如:在双语平行语料库中搜索某些常用的或难把握的词的不同译法,然后再用KWIC(key words in context)方法在类比语料库中检索该词在语境中的用法,归纳出这些词语的用法特点。同时,教师亦建议学生随机考察可比语料库英文科技论文摘要的词汇的特点和句子结构的特点 (如英文句中复合句和被动句的使用频率),还有连接词的使用情况和句子与句子之间逻辑关系的典型表达(如因果关系、递进关系、转折关系等),考察双语平行语料库中某些句型如“把”字句、被动句的翻译,随机考察可比语料库原生英文文本的篇章结构,如开头、顺序形式、文本单位和结尾,并将其最主要特点总结出来[8]。每两周教师布置一篇汉语科技论文摘要要求实验班和对照班的学生翻译成英文。这一阶段的教学过程教师要尽可能保证两个班的学生在课堂和课外花了几乎是同样多的学习时间。
3.后测
后测在期末考试中进行。在试卷中包含了“科技论文摘要汉英翻译”的题目,对学生在该题的表现进行评分和比较分析。在学习阶段结束时进行后测,目的是为了确定基于汉英双语对应语料库的数据驱动翻译教学方法的效果如何,能否比传统翻译教学方法更显著地提高实验对象的翻译成绩和翻译水平。后测之前做一次关于翻译教学方法的问卷调查,了解实验对象如何看待基于双语对应语料库的数据驱动翻译教学方法。对这次后测的材料,老师将同学期末试卷的翻译部分复印,同样由两位老师对其进行评分,标注并分析其中存在的典型错误,同时计划建一个小型学生翻译练习语料库进行随后的研究。
四、研究结果与分析
(一)在实验前选定实验对象时,曾让两个班的实验对象做一次科技论文摘要的汉英翻译练习,之后还立即进行了一个问卷调查。通过分析以上前测和调查的结果,可以清楚地了解实验对象在科技论文摘要的汉英翻译方面存在哪些主要问题
从前测的成绩来看,绝大部分学生的汉英翻译做得较差,平均分只有52-53(见表2)。通过抽样标注并分析其具体错误,发现存在不少共通之处:句子和篇章理解不到位,英文表达错误多(语法、衔接、搭配及拼写等)。这与问卷调查的结果是相一致的。
(二)经过讨论与比较,在此选用的方法是通过比较实验班和对照班后测的分数和翻译中所犯的错误数目来考察它们之间是否存在差异
独立样本t检验结果表明(见表3),实验班和对照班学生在期末汉英翻译测试中的成绩存在着显著差异,t=2.372,p=0.020<0.05,实验班学生的成绩要优于对照班学生,平均分要高出3.33。由此可见,基于双语对应语料库的数据驱动翻译教学方法能比传统翻译教学更显著地提高测试成绩。其主要原因在于双语对应语料库创造了一个自主学习的环境,学生置身其中,直接观察并发现双语的对应规律,从而建立起对翻译转换的感性认识,同时也加深了对翻译活动的整体认识。另外,在这种基于语料库的数据驱动教学中,只有较少部分由教师指导和引领,学生成为教学的主体,在观察、对比、分析和借鉴等过程中,其积极性和主动性大大增强,探索和发现能力得到了锻炼[9]。因为以上特点基于语料库的数据驱动教学要比以教师讲解分析为主的传统翻译教学更具有优势。

表3 实验班和对照班期末汉英翻译后测成绩统计结果
为了进一步考察基于双语对应语料库的数据驱动翻译教学的效果,克服翻译成绩评定方面可能存在的主观性[10],课题组对实验班和对照班学生在翻译中所犯的错误数目进行了统计和比较。在获得两个班的具体数目时,为了减少对严重翻译错误的不同理解而导致统计的数量存在误差,这一判定和计算的工作由两人分别承担,以保证标准的一致性,对存在不同数目的译文最后一起商量确定。为分辨实验班和对照班之间是否存在差异,同样通过SPSS对各自的数目进行独立样本t检验。
独立样本t检验结果表明(见表4),实验班和对照班学生在翻译错误数目方面存在着显著差异,t=-2.189,p=0.031<0.05,实验班学生汉英翻译中的错误数目要少于对照班学生,均值要少0.5368。这一结果与前面的后测翻译成绩的结果完全相一致。基于双语对应语料库的数据驱动翻译教学方法通过向学生展示了丰富、真实的例证,让他们尽快熟悉了科技论文摘要中常用的术语、惯用表达式、搭配及典型的语篇结构[11],加上教师布置的辅助翻译练习,提高了学生的实际翻译技能和翻译水平,他们所犯的错误数目要比对照班的要更少。
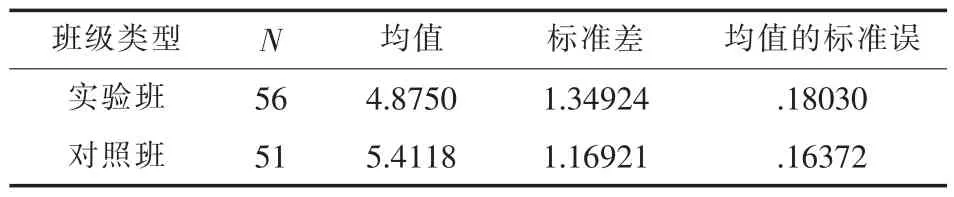
表4 实验班和对照班期末汉英翻译后测中错误目数统计结果
(三)期末后测之前课题组对实验班做了一次关于翻译教学方法的问卷调查,以了解他们对于本学期基于语料库的数据驱动翻译教学方法的态度和建议
根据实验班的态度反馈,绝大部分学生对基于语料库的数据驱动翻译教学方法持肯定的态度,他们喜欢基于语料库的数据驱动翻译教学实践的方式,认为这种教学方法适合自己并且对提高自己的翻译水平有帮助。他们中的多数在做老师布置的论文摘要汉英翻译课外练习时,会经常打开老师提供的“有色冶金期刊论文摘要汉英双语语料库”进行参考。在与普通翻译教学方法比较方面,他们认为基于语料库的数据驱动翻译教学方法更有效果,更加新奇有趣,也能让自己在课堂上更集中注意力。基于双语对应语料库的数据驱动翻译教学方法创造了一个较好的自主学习的环境,满足了学生发现、探索的愿望,极大地激发了学生的积极性和主动性[12]。在他们看来,基于语料库的数据驱动翻译教学方法的教学效果要比普通翻译教学方法更好。
五、结 论
将汉英双语语料库作为翻译教学平台进行数据驱动翻译教学实践,比传统翻译教学更能激发学生对翻译的兴趣,汉英科技翻译的教学效果更加显著。具体表现为:基于双语对应语料库的数据驱动翻译教学方法能使学生提高成绩,少犯翻译错误,学习积极性提高。与传统的翻译教学模式相比,基于语料库的数据驱动翻译教学具有以下三个特点:
第一,在理念上,借助真实的翻译产品帮助学生建立关于翻译的意识。如对翻译教材的认识,不仅局限于以独立的词汇、句子、文本及其参考译文为对象,而是以大规模的各种原文及其译文的电子对应语料作为工具,以计算机作为辅助手段,来帮助学生认识与翻译实践相关的各种因素;第二,在性质上,改变传统翻译教学中规定性方法,将描写性因素融入翻译教学实践中,通过观摩现有的翻译产品,进行对比分析,加深对于翻译活动的认识[13];第三,基于语料库的数据驱动翻译教学的核心原则是让学生成为教学活动的主体,调动学生的主动性,在观察、对比、分析、借鉴中提高学生翻译的意识和应变能力,从感性认识达到理性和自发的反应[14]。因此,语料库及语料库翻译研究的成果应该应用于指导具体的翻译实践,基于汉英双语语料库的数据驱动的翻译教学方法应该应用于辅助翻译教学。
[1]杨惠中.语料库语言学导论 [M].上海:上海外语教育出版社,2002.
[2]李德超,王克非.新型双语旅游语料库的研制和应用[J].现代外语,2010(1):57-59.
[3]秦洪武,王克非.对应语料库在翻译教学中的应用:理论依据和实施原则[J].中国翻译,2007(5):46-49.
[4]Granger,S.The computer learner corpus:A versatile new source of data for SLA research[M].New York:Longman,2004.
[5]陈坚林,史光孝.对信息技术环境下外语教学模式的再思考——以DDL为例[J].外语教学,2009(6):26-29.
[6]王克非.语料库翻译学探索[M].上海:上海交通大学出版社,2012.
[7]甄凤超.语料库数据驱动的外语学习:思想、方法和技术[J].外语界,2005(4):36-39.
[8]史文霞,科技论文英文摘要的经济性研究——一项基于语料库的中美科技论文摘要对比分析[J].西安外国语学院学报,2008 (1):75.
[9]McEnery,Tony.Corpus linguistics [M].Edinburgh:Edinburgh University Press,1996.
[10]Barlow,Michael.Parallel texts in language teaching[M].London: Routledge,2003.
[11]邓军涛,许明武.科技论文摘要汉译英典型问题探究[J].中国科技翻译,2013(1):39.
[12]Wilson,Andrew.Multi-lingual corpora in teaching and research[M]. New York:Routledge.2000.
[13] Husto,Susan.Corpora in applied linguistics[M].Cambridge: Cambridge University Press,2002.
[14]蔡强,张建平.中国高校网页“学校简介”英译词汇特征探讨——基于可比语料库的宏观分析 [J].江西理工大学学报,2013,34 (4):93.
基于科技论文摘要双语平行语料库的科技英语教学模式
张建平, 蔡强
2095-3046(2015)02-0073-05
10.13265/j.cnki.jxlgdxxb.2015.02.016
H06
A
2015-01-09
江西省高校教改省级立项课题(编号:JXJG-13-7-29)
张建平(1974- ),男,副教授,主要从事翻译、科技英语等方面的研究,E-mail:zping1992@163.com.
猜你喜欢
今日农业(2021年6期)2021-11-27 08:05:59
未来教育家(2021年10期)2021-03-11 06:02:34
甘肃教育(2020年2期)2020-09-11 08:01:08
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
中国法学教育研究(2017年4期)2017-05-29 00:53:46
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
外语教学理论与实践(2016年1期)2016-06-11 05:51:46
疯狂英语(双语世界)(2016年4期)2016-06-05 08:37:16
语言与翻译(2015年4期)2015-07-18 11:07:45
语言与翻译(2014年1期)2014-07-10 13:06:14
