
一种改进的协同过滤推荐算法
2015-09-26 02:01:54朱小强张琳
现代计算机 2015年17期
朱小强,张琳
(上海海事大学信息工程学院,上海 201306)
一种改进的协同过滤推荐算法
朱小强,张琳
(上海海事大学信息工程学院,上海201306)
0 引言
在如今这个大数据及电商的时代,个性化推荐系统[1~2]应运而生。在电子商务网站中,使用个性化推荐系统的目的是向拥有不同兴趣的一类客户提供符合其需求的商品。目前主要的推荐技术[3]有3种:基于用户的过滤推荐技术[4],基于内容的过滤推荐技术和基于规则的过滤推荐技术。
在推荐技术的实际应用过程中,面临着刚开始时没有用户对商品给出评价,即冷开始;用户对商品的评价数目过少以及商品数目的不断增加,也就是数据稀疏性以及扩展性等问题,使得推荐的精确度大打折扣。
针对上述不足之处,本文提出了一种基于Mean-Shift聚类的用户协同过滤算法。该算法先利用Mean-Shift聚类算法对所有用户进行聚类,然后将目标用户所属的类作为基于用户的协同过滤算法的输入得到最终的结果。
1 基于用户的协同过滤算法
在个性化推荐中,基于用户的协同过滤算法是应用最为广泛的推荐算法。其基本原理是基于邻居用户的兴趣爱好预测目标用户的兴趣偏好。算法先使用统计技术寻找与目标用户有相同喜好的N个用户作为用户的最近邻居集,然后根据目标用户的这N个邻居的偏好产生向目标用户的推荐。取其中排在最前面的K个资源作为用户的推荐集[5]。具体的流程如图1所示:

图1 基于用户的协同过滤算法的主要步骤

用户的偏好信息决定着系统推荐的效果,所以收集方法很重要。用户提供个人偏好信息的方式有很多,例如游览网页的时长,点击的相关物品以及用户注册时提供的一些个人信息等。根据不同用户的行为,可以得到用户偏好的二维评分矩阵,列表示物品,横表示用户,数值是用户对物品的评分,一般是[0,4]之间的数值 (0表示非常不满意,1表示基本满意,2表示满意,3表示很满意,4表示非常满意),如表1所示:
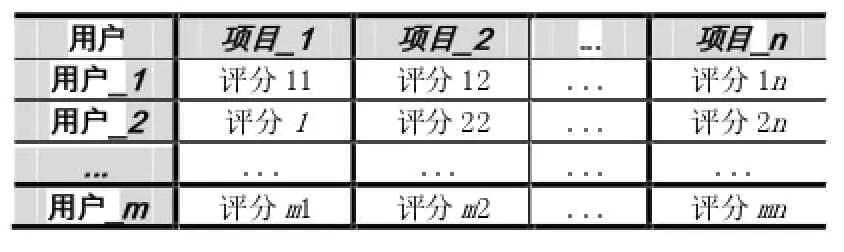
表1 用户对项目的评分表
根据已有的用户对项目的评分表计算出相似用户或项目,再依据计算得到的相似用户或者项目进行推荐。首先需要做的是选用合适的方法计算相似度。
在协同过滤算法中,计算相似度的方法主要有:Pearson相关相似性、余弦相似性和修正的余弦相似性这3种,为了准确性和方便,本文采用了Pearson相关相似性。由此可得两个用户之间的相似度Sim(i,j)为[6]:
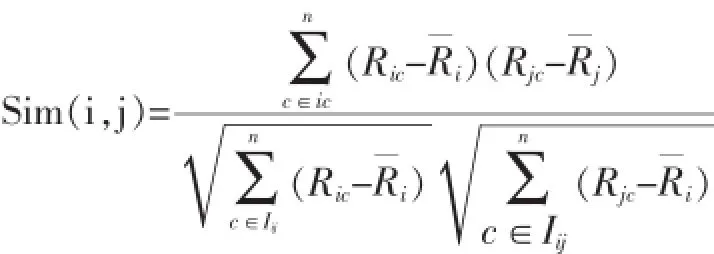
其中Ric,Rjc分别为用户ui,uj对项目c的评分,分别表示用户ui,uj已评分项目的平均分,Iij为用户ui,uj共同评分的项目。

得到用户之间的相似度之后,接下来要做的就是根据相似度找到目标用户的最近邻居集,可选用如下两类方法计算用户的最近邻居集:
(1)固定数量的邻居:选取离目标用户距离最近的K个用户作为目标用户的最近邻居集。
(2)相似度门槛的邻居:提前设定一个阈值t,选取离目标用户的距离小于或等于阈值t的所有用户作为目标用户的最近邻居集。
假设集合Nu为目标用户u的最近邻居集合,则可以预测用户u对项目j的评分
Pu,j为[7]:
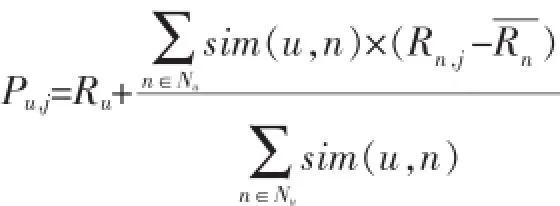
2 改进的算法
由于采用传统协同过滤推荐算法的推荐系统具有数据稀疏性,推荐的精确度,算法的伸缩性等问题,本文提出了一种改进的新型推荐模型。其中,采用奇异值分解的方法来降低评分矩阵的稀疏性;运用项目语义相似度来提高推荐的精确度;采取基于项目聚类的方法来改善算法的伸缩性。
改进的算法的设计流程图如图2所示:
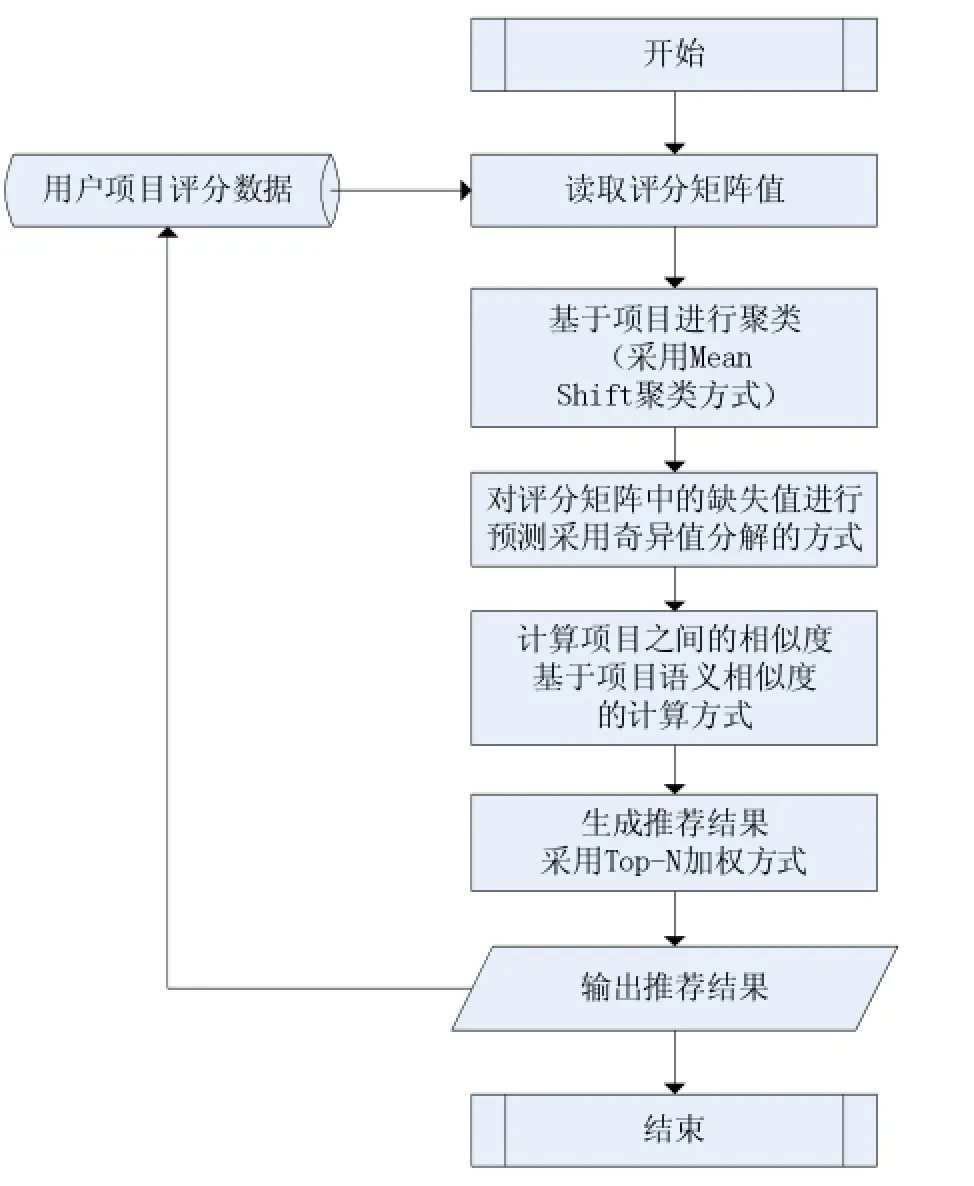
图2 改进的算法流程图
聚类中,常用的是K-means聚类算法。其优点是可以离线预处理数据,能够很好地响应实时性;可以通过缩小最近邻居查找空间范围的方法来提高搜索效率。但也有许多不足之处,其中最重要的就是聚类的数目K不是算法自动生成的,而是人为的随机选取的,不同的K值会产生不同数目的聚类中心,这样得到的聚类个数也就不同。显而易见,采用这种聚类方法得到的结果带有一定的随机性,从而聚类的准确性也会不尽如人意。
综上所述,本文采用的聚类算法为MeanShift聚类算法。MeanShift算法的特性之一是不需要提供一个明确的聚类数目,其二是该算法还能根据数据的特征发现任意形状的聚类簇 (这点和 Canopy算法不同,Canopy算法发现的是圆形簇)。该算法首先为每个数据创建一个固定半径的窗口,循环遍历每个窗口,通过一个本地的密度函数计算一个均值漂移向量 (这个向量是指最大增长速度的方向)。然后每个窗口根据计算出来的均值漂移向量移动到一个新的位置,并且又开始新的循环。循环退出的条件是当通过本地密度函数计算出来的向量变得很小的时候,满足一个阈值就退出。
改进算法使用距离阈值T1作为每个窗口的固定半径,使用距离阈值T2来决定两个canopy什么时候合并为一个 (即当两个canopy的距离小于T2时就把它们合并)。每个canopy包含一个或者多个被限制在某个范围的点。下面是MeanShift聚类的过程[8]:
算法在初始时为每个输入样本数据点创建一个canopy。
针对每一个canopy,把输入与当前canopy的距离小于阈值T1的归为当前canopy)
(比如,一共有三条记录,如果它们彼此的距离都小于T1,那么以第一条记录为canopy的点有两个,分别为记录2和记录3;以第二条记录为canopy的点有两个,分别为记录1和记录3;以第三条记录为canopy的点有两个,分别为记录1和记录2)。每一个canopy计算它的均值漂移向量,计算方法:使用每个canopy包含的点的全部维度相加除以包含点的数目就得到了一个新的canopy中心向量,即均值漂移向量。这个中心向量的权重通过它包含的点的数目来表示。
针对步骤2中新的canopy计算它们之间的距离,当距离小于阈值T2时就把它们归为一个canopy,同时相应的属性也叠加。
算法结束的条件:当每一个canopy的前后两次的差值都满足小于一个给定的阈值delta时,该算法结束。
算法结束后,剩下的canopy的数目就是聚类的数目。
准确性是传统协同过滤的一大不足,因为物品或用户之间的相似度只通过用户评分矩阵计算获得是一个不明智的做法,它没有考虑项目之间的语义关系。例如手机和充电器这两个物品除了表面计算得到的相似度外它们还有内在的联系。所以本文最终的相似度是把采用传统方法计算得到的相似度和采用基于领域本体[8]的方法计算得到的相似度按一定比例进行组合得到的,以此来提高项目或用户的相似度,使得到的项目或用户的最近邻更加准确,从而提高推荐的准确度。
(1)基于领域本体的项目相似度计算:
什么是领域本体,它是一种对学科概念的阐述。其定义如下:(其结构为树的模型)
①对于一个给定的分类本体树r,定义它的根节点为R,则R的高度或者深度可表示为Dep(R)=1;
②概念D为上述所建树中的任一非根节点,它的父节点可用parent(D)来表示,则概念D的高度或者深度为从概念D到根节点R的路径长度,记为Dep(D),则由树的概念可知其高度或深度为:Dep(D)=Dep(parent(D))+1;
I为概念C的实例,则I的深度Dep(I)为Dep(I)=Dep(C)+1。任意2个概念m,n的最小共同祖先LCA(Least Common Ancestor)为m,n祖先中深度最大的共同祖先,记为LCA(m,n),可以表示为:
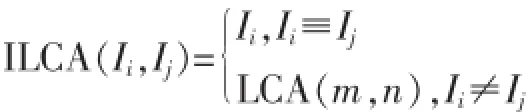
说明如下:Ii,Ij分别为概念m,n的实例。由此可得Ii,Ij之间相似度为:
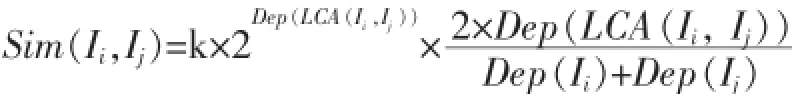
由上述相似度公式可知,相似度Sim(m,n)的值在0到1之间,且LCA(m,n)越大,概念m,n的相似度Sim(m,n)就越大,当Sim(m,n)=1时,表示这两个概念相同。
最终的相似度组合公式为:
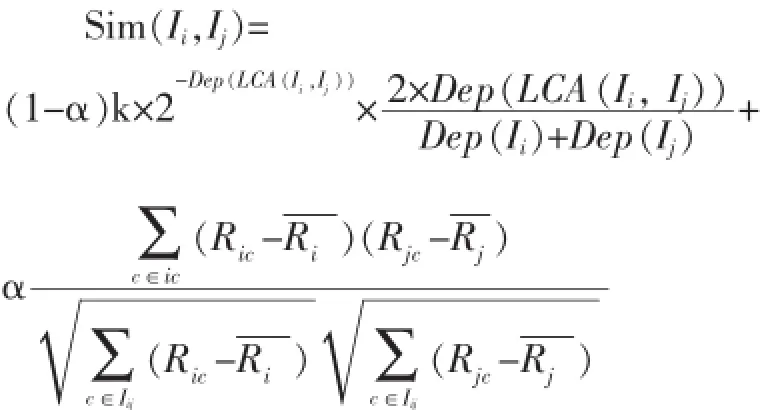
其中,α为在0到1之间可调节的值。当α=1时就是传统的协同过滤方法,反之当α=0时其相似度就是完全采用基于领域本体的方法计算得到的。
协同过滤的另一个问题就是评分矩阵的稀疏性问题,相对于系统中的庞大物品数量,用户对物品的评价可谓冰山一角,这也是评分矩阵稀疏性问题的由来。
奇异值分解(SVD)的简单介绍:它是用来简化矩阵维数的一种常用方法,它将一个m×n的矩阵A分解为3个矩阵。A=N×S×VT,其中N是一个m×m的正交矩阵,V是一个n×n的正交矩阵,S是一个m×n的对角矩阵,对角线上的元素由上往下一次递减,并且对角线上的元素都是大于0的,非对角线上的元素全为0,对角线上的元素从小到大排列,称为奇异值,奇异值分解可以产生与原始矩阵秩相等的并且与原始矩阵最近似的矩阵。
预测采用奇异值分解的评分公式为:
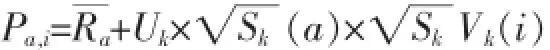
3 实验结果及分析

本文的数据集为Movielens的数据集,从用户数据库中选择包含1200个用户和4000部电影的共199050条评分的实验数据集。将实验数据集分为测试集[9]和训练集,通常比例为1:4,这样可以使建立模型在大量的训练集中得到完善,使得最后的实验结果更具有说服力。

本文采用的电影数据集的稀疏等级为:1-199050/ (1200×4000)=0.9585。
将本文提出的改进算法与基于K-means聚类的传统的用户的过滤推荐算法在其他外在条件相同的情况下进行测试比较。

本文采用平均绝对偏差的方法来作为推荐系统推荐质量的评价标准,将实际的用户评分与预测的用户评分进行比较,从而得到预测预测的评分与实际评分的偏差,偏差值越小,那么推荐的准确度就越高[10]。
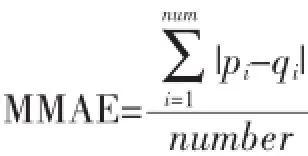
其中,qi为测试集中用户原始的评分;pi是预测的评分;number是评分项目数目。
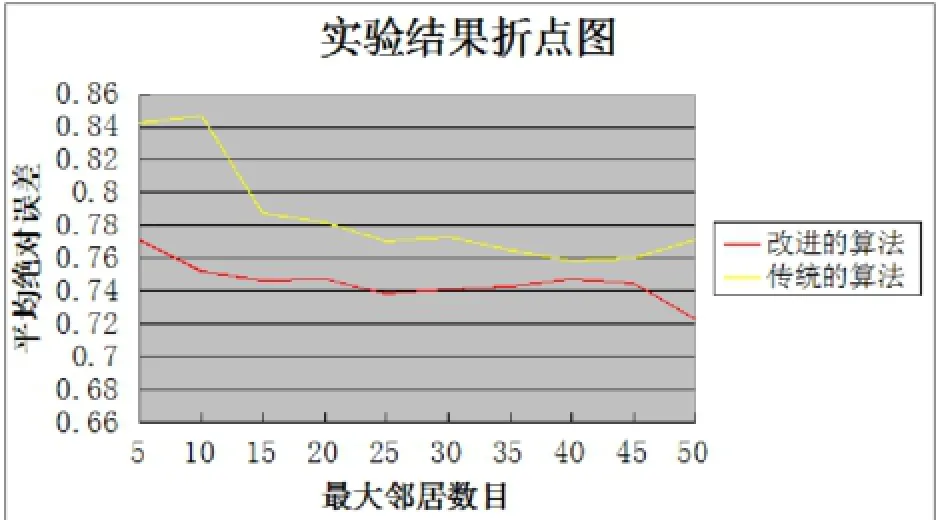
图3 实验结果折点图
从图3可看到,改进的推荐算法在精度方面明显高于传统的推荐算法。同时,随着折线图的升降可以看出推荐的准确度受最大邻居数目的影响,所以在选择邻居的数目时要慎重。
4 结语
本文提出了基于MeanShift聚类的协同过滤算法,降低了用户空间的维数。在评分数据极其稀疏条件下,能够较精确的给出评分预测,是一种更合理的用于推荐的选择。
[1]张树良,冷伏海.Web环境下个性化信息的获取和个性化服务的实现[J].中国图书馆学报,2007,33(170):77~81
[2]王翠萍,杨冬梅.知识门户的个性化服务现状及优化研究[J].中国图书馆学报,2009,35(183):117~122
[3]Resnick,Varian.Recommender Systems[J].Communications of the ACM,1997,40(3):56~58
[4]傅鹤岗,彭晋.基于模范用户的改进协同过滤算法[J].计算机工程,2011,37(3):71~74
[5]周强.基于用户的协同过滤推荐算法研究[J].南昌高专学报,2006(3):88~89
[6]王茜,王均波.一种改进的协同过滤推荐算法[J].计算机科学,2010,37(6):226~228
[7]程岩,肖小云,吴洁倩.基于聚类分析的电子商务推荐系统[J].计算机工程与应用,2005(24):175~177
[8]MeanShift,Mode Seeking,and Clustering(1995)
[9]彭玉,程小平,徐艺萍.一种改进的Item-based协同过滤推荐算法[J].西南大学学报,2007,29(5):146~149
[10]颜丰,张琳.一种混合模式的协同过滤算法[J].现代计算机,2014.
Recommendation System;Collaborative Filtering Algorithm;Clustering;Singular Value Decomposition
Collaborative Filtering Algorithm Based on MeanShift Clustering
ZHU Xiao-qiang,ZHANG Lin
(College of Information Engineering,Shanghai Maritime University,Shanghai 201306)
1007-1423(2015)17-0031-05
10.3969/j.issn.1007-1423.2015.17.007
朱小强(1989-),男,江苏泰州人,硕士研究生,研究方向:个性化推荐系统、自然语言处理、模式识别
2015-04-24
2015-05-26
在这个电商及大数据的时代,个性化推荐系统应运而生。由于传统的协同过滤算法存在新使用者、新项目、扩展性以及稀疏性等问题,提出一种基于MeanShift算法的项目或用户聚类,奇异值分解和项目语义相似度的推荐模型,有针对性的对传统的协同过滤推荐系统的不足之处进行改进。实验结果表明,与传统的推荐算法相比,改进算法具有更高的准确性。
推荐系统;协同过滤;MeanShift聚类;矩阵稀疏
张琳(1973-),女,河南信阳人,博士,副教授,研究方向为港航信息化技术、智能信息处理、信息检索、本体与知识工程等
In this era of electricity and big data,the personalized recommendation is mainly used in e-commerce sites.To solve the traditional collaborative filtering algorithm existing the new user,new project,scalability and sparsity problems,proposes a collaborative filtering algorithm based on MeanShift clustering,Semantic similarity between items and Singular Value Decomposition.To deal with the disadvantages that the traditional collaborative filtering recommendation system facing.The experimental results show that,compared with the traditional recommendation algorithm,the improved algorithm has higher accuracy.
猜你喜欢
中学化学(2024年4期)2024-04-29 22:54:35
制造技术与机床(2019年9期)2019-09-10 07:36:54
西南交通大学学报(2018年6期)2018-12-18 02:22:28
电子测试(2017年15期)2017-12-18 07:19:27
河北遥感(2017年2期)2017-08-07 14:49:00
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
中国民族医药杂志(2016年5期)2016-05-09 07:43:50
作文大王·低年级(2016年3期)2016-03-11 00:48:53
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
