
数据密集型计算环境下的离群点挖掘算法
2015-09-09 18:02陈亚丽张龙波张树
计算技术与自动化 2015年2期
陈亚丽+张龙波+张树
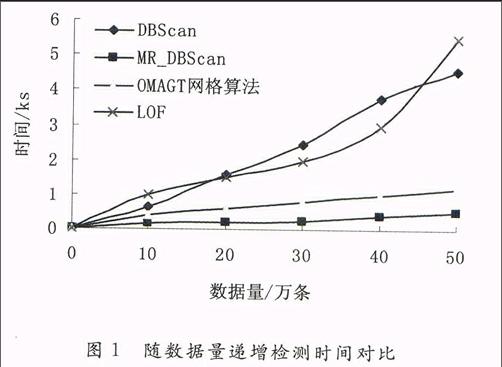
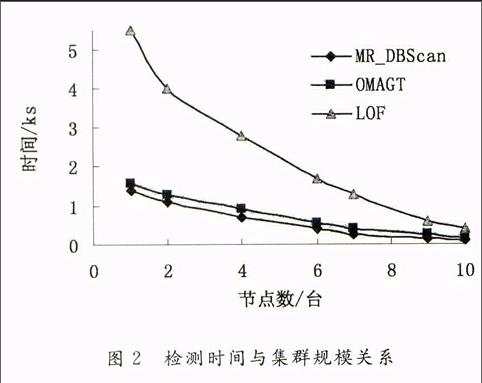

摘要:在数据密集型计算环境中,数据的海量、高维、分布存储等特点,为数据挖掘算法的设计与实现带来了新的挑战。基于MapReduce模型提出网格技术与基于密度的方法相结合的离群点挖掘算法,该算法分为两步:Map阶段采用网格技术删除大量不可能成为离群点的正常数据,将代表点信息发送给主节点;Reduce阶段采用基于密度的聚类方法,通过改进其核心对象选取,可以挖掘任意形状的离群点。实验结果表明,在数据密集型计算环境中,该方法能有效的对离群点进行挖掘。
引言:
随着数据海量增长、数据类型日益增多,如何快速处理数据密集型计算环境中数据是目前急需解决的问题。我们把以高效的方式获取、管理、分析和理解海量且高速变化的数据来满足目标需求的计算过程称为数据密集型计算[1]。数据可能以极高的速度生成,对数据的过滤、整合和存储等一系列操作必须能适应数据的生成速度。另外,数据密集型计算任务需要在合理的时间内分析和处理数据。但是,大多数情况下,数据以分布方式存储。因此,决定因素不再是计算能力,而是传输速度能否跟得上系统收集、处理和分析数据的速度[2]。Google基于大规模数据集的并行运算编程模型MapReduce将所有数据操作类型通过统一的编程模型连接起来,使海量、高速变化、异构和分布存储的数据能够在由普通计算机组成的集群中运行,在一定程度上实现了全局化的资源管理与调度。
数据密集型计算环境中数据的海量、快速变化、分布、异构等特点给离群点数据的挖掘带来了新的挑战。数据量的增长速度甚至超过了单个主存储器或硬盘容量增长的速度[3,4], 地理位置的分布性和网络传输速度限制了大量数据在不同机器间的自由移动[5]。通过只传输中间处理结果等少量信息减小数据传输量以提高网络传输速度。采用分布式集群进行离群点挖掘成为了一种趋势。
相关工作:现有的方法大多是基于统计分布、深度、距离、聚类或网格等的离群点挖掘方法。文献[6]基于统计分布提出了100多种针对不同数据分布的离群点挖掘方法。为减少距离计算,引进空间索引结构KD-树、R-树和X-树等查找数据点的k邻近[7]。这些方法在低维空间中时间复杂度接近O(NlogN)。但是,随着维度的增加,方法失效。基于聚类的DBScan[8]算法检测出聚类的同时也检测出了离群点。缺点是数据量增大时,对内存容量要求高,I/0开销很大。张净等人提出的IGDLOF算法根据邻居网格[9]中数据分布情况判断该单元格是否为稀疏单元,依次进行数据筛选。基于网格的OMAGT[10]算法,降低了挖掘大数据集时对内存的要求,但是需计算局部可达密度。基于网格和密度思想的FOMAUC[11]算法能有效提高算法效率和挖掘准确度,但是该算法不适用于高维大数据集,其整个过程都是在内存中进行的,对内存要求比较高。目前,基于MapReduce模型的离群点挖掘算法研究相对较少。
MapReduce是由Google提出的主要用于海量数据处理的软件框架。它将数据看作一系列的<key,value>,处理过程包括Map映射和Reduce规约两个阶段。用户实现一个Map函数来处理输入<key,value>,产生相应的中间<key,value>。Reduce函数合并所有具有相同key值的中间键值对,并作为后续MapReduce的输入,在此基础上完成用户所需的功能。MapReduce程序可自动分布到一个由普通机器组成的超大集群上并发执行[12]。因此,此模型在一定程度上能满足数据密集型计算环境下离群点挖掘的需求。
在MapReduce模型基础上,利用DBScan算法对离群点敏感的特点,将网格重心确定为DBScan算法核心对象,能有效防止由于核心对象选取不当而产生的波动现象,并通过设置阈值判断集体离群点的存在。
算法分析与描述
在数据密集型计算环境中,离群点只占整个数据集的一小部分,而且有可能分布在不同的区域。基于MapReduce模型,各分节点将不可能成为离群点的数据删除,再对剩余数据在主节点进行全局离群点挖掘。分节点采用网格方法处理数据,将产生的代表信息和拟离群点信息发送到主节点。key为网格ID,value为网格五元组信息。网格方法可用来处理任意类型的数据,处理时间与数据的数目和输入顺序无关。因此,一定程度上可减少检测数据量,降低网络数据传输量。主节点将各个分节点发送的代表点信息整合,合并key值相同的网格单元信息,进行全局范围的数据筛选。将网格重心初始化为MR_DBScan核心对象,依次由高密度到低密度从未访问数据集中选取,避免了因核心对象选取不当而引起波动现象的发生。利用网格删除大量正常数据,降低了数据集聚类数,减小了存储核心对象信息所需的内存容量,提高了算法的执行效率。
网格单元为一个五元组U(T,P,G,Max,Min),即U(网格类型,点数,重心,最大值,最小值)。P为每个U中的数据点总数,也称为单元格密度。U中去掉最大值、最小值,每一维上数据坐标的算术平均值为重心G的值。若U中的数据点总数P不小于某一给定的阈值N,即|P|N,U是稠密单元; |P| MR_DBScan算法概述: 输入:d维数据集D、网格阈值N、阈值Num; 输出:离群点的集合Outlier; 算法过程及形式化描述如下: 1)MapReduce框架将输入数据分配给9台PC机(实验中的分节点)。 2)网格单元U中各维空间划分相对独立,每一维划分的间隔不同。每一维的划分以各相邻数据点间的分布情况作为依据。 3)随机选择一个未经访问的点,根据预先设定的维度间隔距离值计算该点所属的网格单元。输入数据的同时,计算U的五元组信息。
4)若U为稠密单元,且其L均为稠密单元,保存U和L的五元组信息,L放入C(候选集合)中。对C中网格的L进行遍历查询,直到所有L均为空,将U及所有L中数据全部删除;L均为空单元,标记U和空单元并删除U中数据。若U为稀疏单元,其L均为空,则U标记为离群单元并删除U中数据,否则将其保留。位于数据分区边界的单元格不为空时,全部保留。
5)分节点将代表点和拟离群点信息发送给主节点。
6)主节点将不同分节点发送的代表点划分到相应的U中,实时更新U的五元组信息,直到所有数据全部录入网格。
7)重复4)中步骤,筛选数据,得候选离群数据集及部分离群点。
8)在主节点进行全局离群点挖掘,伪代码为:
输入:
.D:7)中生成的候选离群数据集。
.ε:半径参数。
.MinPts:领域密度阈值。
.Num:判定密度阈值。
输出:离群点
方法:
标记所有重心点为unvisited;
do
选择一个单元数据点数最多的unvisited重心点p;
标记p为visited;
if p的ε-领域至少有MinPts个对象
创建一个新簇C,将p添加到C;
令M为p的ε-领域中的对象集合;
for M中每个点p
if p是unvisited
标记p为visited;
if p的ε-领域至少有MinPts个点,将这些点添加到M;
if p还不是任何簇的成员,将p添加到C;
end for
if C中数据点数小于Num
标记C为集体离群点;(判断是否有集体离群点存在)
输出C;
else标记p为离群点;
输出p;
until没有标记为unvisited的对象;
9)将4)、7)、8)步骤中检测出的离群点信息汇总输出。
主节点执行任务的总体分配和调度,分节点通过步骤2)、3)、4)、5)将大量非离群数据删除,并将代表信息发送给主节点做进一步的全局离群点挖掘。主节点执行步骤6)、7)、8)、9)对分节点发送的数据做全局离群点挖掘。改进的核心对象选取算法能很快检测出簇,进而加快了对离群点的挖掘。
实验结果与分析
实验平台配置如下:10台相同配置的PC机(通过局域网连接),CPU Pentium Dual-Core E6500,内存2G,YLMF OS(Ubuntu) 操作系统,Hadoop0.20,1个主节点master,9个分节点slaves,用装有Hadoop插件的eclipse进行代码编辑,编译jdk1.7。测试数据来自KDD Cup 1999,是MIT林肯实验室进行的一项网络入侵检测评估中所采集的真实数据。共有41个属性,34个为连续属性,7个为离散属性。数据对象包括五大类,正常连接、dos、u2r、r2l、probe入侵和攻击。
本实验在ε=3,MinPts=4时,检测到离群点数为40,较真实离群点数多2,能检测出所有离群点数据,误检率为5%。分节点算法时间复杂度为O(N),N为网格单元数。主节点时间复杂度为O(N/P)+O(nlogn),P为分节点数,n为数据量。因为O(N/P)<<O(nlogn),所以算法时间复杂度为O(nlogn)(n远小于原始数据数目)
结论
本文针对数据密集型计算环境下离群点挖掘问题提出了基于MapReduce模型的分布式离群点数据挖掘算法MR_DBScan。该算法利用MapReduce框架,将网格方法与基于密度的聚类方法DBScan有效结合,对DBScan算法核心对象选取作出改进、并通过设置阈值判断是否存在集体离群点。由实验结果分析可知,MR_DBScan算法能有效地解决海量、分布、高速变化的密集型数据中离群点挖掘问题。但是,本文算法也存在一定的不足,网格单元密度阈值、ε、MinPts均需要人为设置。进一步研究的方向是,怎样以自适应的方式来设定阈值,使该算法对数据的处理趋于智能化。
猜你喜欢
科技研究(2021年15期)2021-09-10
电脑知识与技术(2020年32期)2020-12-29
中国计算机报(2020年15期)2020-05-13
作文新天地(初中版)(2019年6期)2019-08-15
数学教学通讯·初中版(2019年3期)2019-04-29
奋斗(2018年4期)2018-05-14
分析化学(2017年12期)2017-12-25
中国知识产权(2016年12期)2016-12-12
中国对外贸易(2016年11期)2016-12-12
现代电子技术(2009年14期)2009-09-05
