
Review Expert Collaborative Recommendation Algorithm Based on Topic Relationship
2015-08-09 04:54:08ShengxiangGaoZhengtaoYuLinbinShiXinYanandHaixiaSong
Shengxiang Gao,Zhengtao Yu,Linbin Shi,Xin Yan,and Haixia Song
Review Expert Collaborative Recommendation Algorithm Based on Topic Relationship
Shengxiang Gao,Zhengtao Yu,Linbin Shi,Xin Yan,and Haixia Song
—The project review information plays an importantrole in the recommendation of review experts.In this paper,we aim to determine review expert’s rating by using the historicalrating records and the final decision results on the previousprojects,and by means of some rules,we construct a rating matrix for projects and experts.For the data sparseness problem of the rating matrix and the“cold start”problem of new expertrecommendation,we assume that those projects/experts with similar topics have similar feature vectors and propose a review expert collaborative recommendation algorithm based on topic relationship.Firstly,we obtain topics of projects/experts based on latent Dirichlet allocation(LDA)model,and build the topic relationship network of projects/experts.Then,through the topic relationship between projects/experts,we find a neighbor collection which shares the largest similarity with target project/expert,and integrate the collection into the collaborative filtering recommendation algorithm based on matrix factorization.Finally,by learning the rating matrix to get feature vectors of the projectsand experts,we can predict the ratings that a target projectwill give candidate review experts,and thus achieve the review expert recommendation.Experiments on real data set show thatthe proposed method could predict the review expert rating moreeffectively,and improve the recommendation effect of review experts.

Currently,recommendation methods and techniques in the field of electronic commerce have had a considerable development and a wide range of application.More and more researches on recommending algorithms and techniques have laid a very good theoretical foundation for review expert recommendation of project activities.Among these recommendation methods,collaborative filtering algorithm has been the most widely used[1].The method renders its recommendation by analyzing products’historical ratings data made by users. At present,collaborative filtering recommendation algorithms are mainly classified as two types,the method based on nearest neighbor and the other based on model.The collaborative filtering algorithm based on K-nearest neighbor(also known as KNN)makes its recommendation by calculating the similarity between users or products.It includes useroriented KNN method(UKNN)[2]and item-oriented KNN method(IKNN)[3].The other collaborative filtering algorithms based on model[4-9]learn a corresponding model on users’rating data to predict a product rating.These models mainly include clustering model,probabilistic correlation model,singular value decomposition(SVD),latent semantic analysis model(LSA)and so on.Recently,relevant scholars have put forward a matrix factorization technique[10-14],which learns low-dimensional feature vectors of users and products from a sparse rating matrix and then uses the low-dimensional rating matrix to predict product rating given by users.Their studies have shown that the matrix factorization algorithm is more effective than the nearest-neighbor algorithm.Similarly,in the case of sparse rating data,the recommendation effect of matrix factorization algorithm is better than that of the algorithm based on model.
The traditional collaborative recommendation algorithm mentioned above assumes that users/products are mutually independent and ignores structural relationships between users (products).Thus,some scholars excavated relevant relationships between users(products),and added them into the existing collaborative filtering algorithm to improve the accuracy of recommendation[15-19].Among them,Guo et al.[18],on the basis of the rating matrix,added a users’social relationship matrix,which improved the algorithm’s recommendation effect greatly.Wu et al.[19]proposed a matrix factorization model based on neighborhood relationships,which calculated similar neighbors by label information,added prior neighbor relationships for users’(products’)feature vectors,and achieved a good recommendation effect.
Up to now,there are a lot of historical project review information which were retained in project application’and project evaluation’activities.Every evaluated project contains its content information,its decision(status)information (such as funded after meeting review,unfunded after meeting review,unfunded before meeting review),its review expert information,its rating information from review experts.There is no doubt that the historical project information would play an important supporting role on recommending review experts to new projects.In this study,therefore,we use the historical project information,and employ the collaborative filtering recommendation algorithm to recommend review experts.Using the project status information and the project rating information given by review experts,we build a projectexpert rating matrix through some rules.In addition,for each reviewed project,its review experts must have been a few,thus will result in a serious data sparseness problem of the rating matrix;new experts do not have any historical rating records, thus they cannot be recommended by using collaborative filtering technology,known as“cold start”problem about new experts.To solve the above problems effectively,therefore, we combine content features of projects or experts,assume that those projects/experts with similar topics have similar feature vectors,introduce the relationships on topics between projects/experts,and propose a matrix factorization algorithm based on topic relationship for review expert recommendation(in short Topic MF).The method, firstly,through the topic relationship between projects/experts, finds the neighbor collection which shares the largest similarity with the target project/expert.Then,it integrates the neighbor set into the collaborative filtering recommendation algorithm based on matrix factorization.Finally,experiments are conducted on a real dataset,and the results show that the proposed Topic_ MF can predict a review expert rating for a new project more effectively and consequently improve recommendation effect.
II.PROBLEM DEFINITION AND MATRIX FACTORIZATION MODEL
At first,let us explain two important concepts which will be mentioned in the paper.One is project rating and the other is expert rating.Project rating is a score or a rating that an expert gives to a reviewed project and it represents the viewpoint that an expert holds on how good a project is.Expert rating is a score or a rating that a reviewed project feedbacks to its review expert and it represents the expert’s working ability.
In this study,the collaborative recommendation algorithm mainly makes corresponding calculation using the projectexpert rating matrix to predict the rating of review experts. If there is a setPofMprojects,P={p1,...,pM},a setEofNexperts,E={e1,...,eN},and a project-expert rating matrixR(p,e)M×N,its elementrijrepresents the expert rating that the projectigives the expertj.In fact,in the historical information of a reviewed project,there are a final decision(status)and project ratings made by its each expert. And in our accessible project database,the project rating is from 0 to 7.To some extent,the final decision and a project rating made by an expert could reflect the expert working ability which is labeled as expert rating.Therefore,according to the status information of a reviewed project,we turn a project rating from an expert into an expert rating that the project inversely gives the expert through some rules,and set the expert rating value asrij,rij∈[0,7].
In the collaborative filtering algorithm based on matrix factorization model,it is generally assumed that expert rating is only influenced by a few factors.The projects/experts are mapped to a low-dimensional feature space.In the space, by rebuilding a low-dimensional rating matrix,the algorithm predicts the review expert rating to make an appropriate recommendation.Assume thatP∈RD×Mrepresents the feature matrix of projects,E∈RD×Nrepresents the feature matrix of experts,andDexpresses the feature vector dimension.The model may learn the feature vectors of projects and experts, then predict the review expert rating based on the feature vectors.The matrix factorization graph model is shown in Fig.1.

Fig.1.The matrix factorization graph model.
In the model,the conditional probability of the rating data of the projects and experts is defined as(1):


To prevent over-fitting,the feature vectors of projects and experts are both subject to the Gaussian distribution with zero mean:
According to Bayesian inference,the posterior probability of the feature vectorPandEis given by(3):

The feature vectors of projects and experts could be learnt by maximizing the posterior probability.
III.REVIEW EXPERT COLLABORATIVE RECOMMENDATION
ALGORITHM BASED ON TOPIC RELATIONSHIP
A.Rating Matrix Construction
In the historical information of the reviewed projects,there is an important field,project rating from experts which represents how good a project is.However,when recommending review experts for projects,we need an expert rating which characterizes expert working ability.For project application, funding agencies firstly do a project preliminary examination or carry out a project peer review to decide whether a project can be accepted for a review meeting so as to further discuss it for approval.And for the above selected candidate projects, after discussion in a meeting,they will be given a final decision whether to be funded or not.So every declared project mainly takes on three status“unfunded before meeting review”,“unfunded after meeting review”and“funded after meeting review”.To some extent,project status and project rating from experts could reflect experts’working ability(That is expert rating.).For example,a reviewed project’s status is“unfunded before meeting review”while a review expert gave a high rating to this project,this indicates that the review expert’s evaluation has a deviation or his working capability is low,thus,he should get a low expert rating from the project inversely.If a reviewed project’s status is“funded after meeting review”and a review expert gave a high rating to this project,this indicates that the review expert’s evaluation is good and rational or his working capability is high,thus,he should get a high expert rating from the project, conversely,he should get a very low rating from this project. Here,we use status information and rating information of the historical projects reviewed to build a project-expert rating matrixR(p,e)by the above rules,that is,according to status information of the reviewed projects,we turn a project rating from an expert into its expert rating from the project.The transformation rules of the expert rating are defined in Table I.The expert rating after being transformed could reflect the experts’working ability effectively.
For those experts who have not participated in the project,in order not to bring additional information,their expert ratings are set as zero.Using the above rules,we construct a rating matrix for projects and experts.
B.Matrix Factorization Model Based on Topic Relationship
In the matrix factorization model based on topic relationship,one key step is to obtain topic relationship of projects and experts.In order to find potential topic relationship between projects/experts,in this study,using LDA[20],we extract project topics from project application documents.In order to improve extraction accuracy of project topics,it is necessary to preprocess project application documents by removing noises including author introductions and references.Then we use topic similarity to define topic relationship between projects/experts.The topic relationship network of projects is shown in Fig.2.

TABLE I THE TRANSFORMATION RULES OF THE EXPERT RATING

Fig.2.Topic relationship network of projects.
The relationship network of project topics in Fig.2 may be described asG={P,E,W}.Pis the project set;Eis the edge set;Wrepresents the weight of the edge,which is the topic similarity between projects;(T1,T2,...,Tni)is the projectpi’s topics.According to this relationship network,we define the similarity weight between projects as(4).

Here,ni,njrepresents topic number of projectpi,pjrespectively;S im(Ti,Tj)is similarity between topics,which can be obtained by calculating cosine similarity between topic vectors with(5).

Here,wTikrepresents thekdimensional value of the corresponding vector to topicTi;wTjkrepresents thekdimensional value of the corresponding vector to topicTj;nrepresents the dimensions of topic vector.
Likewise,using ES-LDA model[21],we extract expert topics from expert evidence documents such as experts’homepages, experts’blog pages,experts’Baidu Encyclopedia pages,experts’Wikipedia pages and experts’papers.In these expert evidence documents,there is some important information,such as page-link,expert-metadata,expert-metadata relationship, expert-metadata co-occurrence and so on.This information has a very good guiding function,and may greatly support expert topic clustering,thus can improve accuracy of expert topic extraction.We integrate this guiding information into LDA model and finally obtain expert topics.For the case of homonymous experts,it is necessary to do name disambiguation to obtain high-quality expert evidence documents.According to the characteristics of Chinese names and expert attributes, we use spectral clustering disambiguation method for Chinese experts by fusing page relationship[22].The main idea can be concluded as follows:First,we use term frequency-inverse document frequency(TF-IDF)method to calculate feature weight based on word,utilize cosine angle formula to calculate page similarity,and obtain an initial similarity matrix of experts’pages;then,we take expert relationship features as semi-supervised information to correct the initial similarity matrix.The experiments show that the method has a good effect in the related work.Using these expert topics,we build a topic relationship network of experts shown in Fig.3.Similar to topic relationship network of projects,(T1,T2,...,Tmi) is the expertei’s topics.The similarity computation between experts is similar to that between projects,and we define the similarity weight between experts as(6).

Fig.3.Topic relationship network of experts.
Using topic similarity degree,we look for the neighbor set of the maximum similarity for a target project(expert).In order to avoid that the nearest neighbors with low similarity impact recommendation results,using the dynamic threshold method,we take those projects/experts whose similarity exceeds the threshold as the nearest neighbors of the target project(expert).Assume that the similarity threshold isβ, the setNi={i|w(i,ik)≥β,i/=ik}represents the nearest neighbors of the target project or expert.Using the dynamic method,we find the nearest neighbor setNpof the project and the nearest neighbor setNeof the expert,p=1,2,...,Kp,e=1,2,...,Ke.Further,we integrate the neighbor setNpandNeinto the collaborative filtering model based on matrix factorization to improve the recommendation accuracy of project review experts.The probabilistic graph model is shown in Fig.4.

Fig.4.The matrix factorization graph model based on topic relationship.
In this model,we assume that the feature vector of each project(expert)not only obeys Gaussian distribution with zero mean to prevent over-fitting,but also is similar to the feature vectors of other projects/experts in the nearest neighbor set. The formulas for the same are as follow:
By probability transformations,(7)and(8)are converted into (9)and(10):

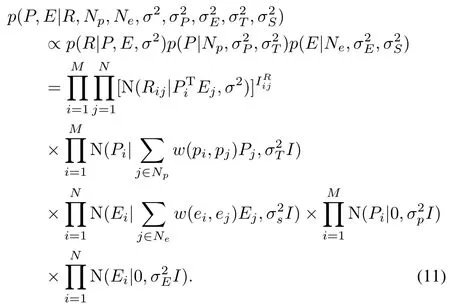
In order to maximize the posterior probability,we apply logarithm on both sides of(11)and get(12).

Here,C is a constant that does not depend on any parameter. Maximizing the posterior probability is equivalent to minimizing the following sum of squared errors.The objective function of minimization is(13):
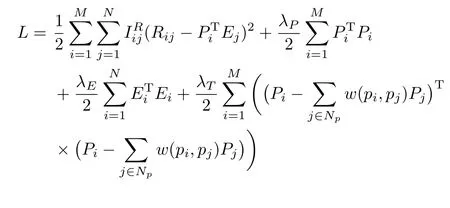
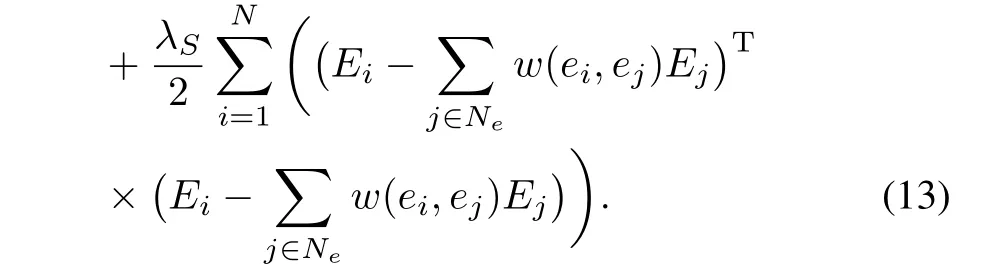

The initial value of feature vector P and E is randomly obtained by Gaussian distribution with zero mean.Then,in each operation,the value of feature vector P and E is iteratively updated based on the value of the previous generation,until it converges.We get the project feature vector P and expert rating feature vector E by gradient descent algorithm.Finally, the predicted rating of expert is as follows(16):
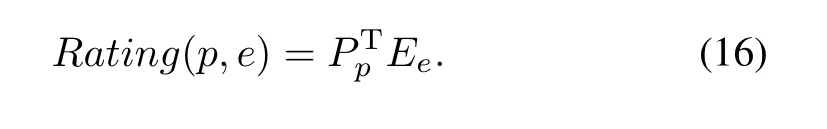
C.Complexity Analysis
In the review expert collaborative recommendation algorithm based on topic relationship,the recommending process will be divided into three steps.The first step is to build the project-expert rating matrix.The second step is to establish the topic relationship network of projects and that of experts.The third step is to make these topic relationships converge to the matrix factorization algorithm to achieve a recommendation. If there are M projects and N experts,the time complexity of building the project-expert rating matrix is O(M×N). For construction of topic relationship networks of projects and experts,the time complexity of obtaining project topics and expert topics is O((M2+N2)×V),in which V indicates vocabulary size;and the time complexity of computing similarity between projects/experts is O((M(M-1)+N(N-1))/2). For the third step,according to the analysis of[23],the time complexity of calculating gradient is O(N¯pD+N K2D+ M¯eD+M K2D),in which K represents the neighbor number of target project(expert),and¯p,¯e respectively represent theaverage rating for each project and that for each expert.From the above analysis,it is concluded that the time complexity of the proposed algorithm is not high.
IV.EXPERIMENT AND RESULT ANALYSIS
A.Experimental Data and Analysis
Because there is no open authoritative corpus resource, our historical project data are taken from the Science and Technology Department of Yunnan Province.We sorted out 4 129 historical project data and 8 124 experts’basic information from the project document library.All these data are from five domains,information,metallurgy,chemical industry, biology and medicine.The data contain content information of projects,project rating information from review experts, status information of projects and so on.Rating range is [0,7].As expert’s basic information cannot well reflect its topic information,in order to ensure the accuracy of obtained expert topic information,we collect these experts’evidence documents manually,including experts’homepages,experts’blog pages,experts’Baidu Encyclopedia pages and experts’Wikipedia pages.Experimental data sets are shown in Table II.
For experimental data in Table II,let us analyze sparsity of the rating matrix.Actually,sparsity of a rating matrix is mainly measured by density of the rating matrix.The density is formulized as(17):

whereNsindicates the number of rating records;Neindicates the number of experts;Npindicates the number of projects. For each domain,according to(17),the sparsity of its rating data is calculated and listed in Table III.It is obvious that there exists serious data sparseness problem in the five domain datasets and the total dataset.
B.Evaluation Standard
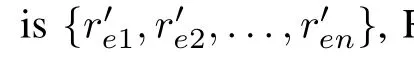

C.Experiment Design and Analysis
In experiments,the history project data in Table II are randomly divided into training dataset and test dataset.We respectively conduct experiments according to differentlysized training data.The training data are obtained by random selection.Then,on them,five-fold cross-validation is used. Finally the experimental results on five different test datasets are taken by taking their average as the RMSE value.In order to reduce the complexity of the algorithm,according to the experimental result in[11],we setλP=λE=0.001,λT=λS=λ.In order to verify the effectiveness of the proposed algorithm,in this study,we design six groups of comparative experiments:1)the recommendation effect of the algorithm under different feature dimension numbers;2)the influence of different values of parameterβon the algorithm performance; 3)the influence of different values of parameterλon the algorithm performance;4)the algorithm’s recommendation performance under different rating sparseness;5)the algorithm’s recommendation performance on new experts;6)the algorithm’s recommendation performance on differently-sized training datasets.
Experiment 1.The recommendation effect of the algorithm under different feature dimension numbers
In this experiment,we will compare the recommendation effects of SVD[8],Gaussian pLSI[7],PMF[11]and Topic MF under different feature dimension numbers.Here,we set feature dimension numberDas 5,10,20 and 30 in sequence, and respectively conduct experiments to observe what influence these different feature dimension numbers have on the algorithms.In order to do these comparable experiments under the same parameters,exceptD,the other parameters are setto the corresponding values of the optimal algorithm performance,so we setβ=0.8,λ=20.These experiments are made on the whole dataset,of which 80%are randomly extracted as training data and the others as test data.The experimental results are listed in Table IV.

TABLE II EXPERIMENTAL DATASETS

TABLE III ANALYSIS OF DATA SPARSITY(%)

TABLE IV RMSE COMPARISON UNDER DIFFERENT FEATURE VECTOR DIMENSIOND
From Table IV,the following conclusions are drawn:1) As feature dimension numberDincreases,the accuracies of the four algorithms have some improvement;but with the dimensionDincreasing continuously,their speed of improving accuracy slows down while their time complexity goes up. 2)Under the sameD,PMF’s RSME values are smaller than those of SVD and Gaussian pLSI;this further proves that PMF algorithm has better recommendation effect than other modelbased collaborative filtering recommendation algorithms in the condition of sparse data.3)Topic MF’s RSME values are much smaller than those of the former three algorithms;this shows that in the case of rating data sparseness,introducing topic relationship between projects/experts into our algorithm plays an important role on improving recommendation quality.
Experiment 2.The in fluence of different values of parameterβon the algorithm performance
Because the rating matrix has serious data sparseness problem,in order to avoid that the nearest neighbors with low similarity impact the recommendation results,in this study, a dynamic threshold method is used to select the nearest neighbors of target project(expert).Given similarity thresholdβas 0.9,0.8,0.7,0.6,0.5,0.4 in sequence,the experiments are respectively performed on the five domain datasets to observe the influence ofβvariation on the recommendation results from the proposed algorithm.In order to conduct the comparable experiments under the same parameters and reduce the complexity of the algorithm,we setλ=1,D=5.The experimental results are shown in Fig.5.

Fig.5.The impact of parameterβon the algorithm performance.
From Fig.5,it is observed that the parameterβhas a great impact on the algorithm performance.With the parameterβincreasing,the RMSE value has constantly decreased; consequently,the recommendation quality has unceasingly improved.This also shows that the nearest neighbors with low similarity would affect the recommendation effect.In addition,whenβ>0.8,the RMSE begins to rise,which indicates that the accuracy begins to fall.The reason is that when the similarity threshold is too high,the nearest neighbors of target project(expert)decrease greatly,thereupon,the recommendation quality of review experts also falls.
Experiment 3.The influence of different values of parameterλon the algorithm performance
In the proposed algorithm,parameterλis a value to measure the degree that the feature vector of a project(an expert)is influenced by its nearest neighbors.The greater the value is, the greater the influence on the feature vector caused by its nearest neighbors,and the greater the effect on our algorithm caused by topic relationship between projects/experts.Settingλas 0.5,1,5,10,20,30 in sequence,we conduct experiments on the five domain datasets respectively to observe the influence of parameterλon the algorithm performance.In order to reduce the complexity of the algorithm,we setD= 5,β=0.8,in the experiments.The experimental results are shown in Fig.6.

Fig.6.The impact of parameterλon the algorithm performance.
According to the experimental results,we can see that the parameterλhas a great impact on algorithm performance. With parameterλincreasing,the accuracy of the algorithm has continuously improved,and this fully proves that topic relationship between projects/experts is very effective on review expert recommendation.Whenλ>20,the algorithm accuracy begins to decrease;the reason is that a too largeλleads to the algorithm over-fitting and thus affects the recommendation effect.
Experiment 4.The algorithm’s recommendation performance under different rating sparseness
In order to compare the effects of the algorithm under different sparse datasets,in this study,we divide the five domain data into three groups based on the density of rating matrix.The three groups of datasets and the density of their rating matrix are shown in Table V.
To compare the recommendation effects of SVD,Gaussian pLSI,PMF and Topic MF under different rating sparsity,we do experiments on the three groups of datasets respectively to observe the impact of different rating sparseness on the algorithm performance.Similarly,givenβ=0.8,λ=20,D=5,the experimental results are shown in Fig.7.

TABLE V THREE GROUPS OF DATASETS AND THEIR RATING MATRIX SPARSENESS

Fig.7.RMSE comparison on different sparse dataset.
As can be seen from Fig.7,with the increasing of rating data sparseness degree,the accuracies of the four algorithms decrease.On any dataset,Topic MF algorithm is signi ficantly better than the other algorithms,and it can get better recommendation effect.This further proves that introducing topic relationship between projects/experts can signi ficantly improve the performance of recommendation system.
Experiment 5.The algorithm’s recommendation performance on new experts
In order to prove that the Topic MF algorithm proposed in this paper can solve the recommendation problem of new experts,we randomly pick out 300 experts from the five domain data sets,remove their rating records,and then do experiments to observe the recommendation performance of SVD,G-pLSI,PMF and Topic MF on the 300 experts.In the experiments,similarly,we set parametersβ=0.8,λ=20,D=5,and the experimental results are shown in Table VI.From the experimental results,we can find that Topic MF can successfully recommend new experts while the other algorithms cannot achieve this goal.

TABLE VI THE ALGORITHM’RECOMMENDATION PERFORMANCE ON NEW EXPERTS
Experiment 6.The algorithm’s recommendation performance on differently-sized training datasets
In order to verify whether the expert recommendation effect of the proposed Topic MF algorithm is obvious related to the size of training dataset,we averagely divide the whole data set into three groups of data(Dataset1,Dataset2 and Dataset3),then change the proportion of training data and test data in each group dataset,and conduct our experiments on the three groups of data respectively to observe the impact of differently-sized training data on the algorithm performance. In order to make comparable experiments under the same condition,we setβ=0.8,λ=20,D=5,and the experimental results are shown in Fig.8.As can be seen from Fig.8,with size of training data increasing,the recommendation accuracy is continuously improved.When the size of training dataset reaches 80%of its own data group,the change of RSME will be smaller and smaller.After that,with training data size increasing continually,the corresponding RSME nearly remains unchanged.Thus it can be seen that the proposed Topic MF algorithm is relatively stable.

Fig.8.RMSE comparison on differently-sized training data.
V.CONCLUSION
This paper focuses on the problems of rating data sparseness and new experts’“cold start”,introduces topic relationship between projects and experts,supposes that projects/experts with similar topics would have similar feature vectors,and puts forward a collaborative filtering recommendation algorithm based on topic relationship.The algorithm uses LDA to extract the topic information of projects/experts,constructs the topic relationship network of projects/experts,finds the nearest neighbor set that has the maximum similarity with target project(expert),and then integrates the neighbors into the collaborative filtering algorithm based on matrix factorization to improve the predicting accuracy of expert rating.The experimental results show that this algorithm can solve the problems of rating data sparseness and new expert recommendation well, can predict the review expert rating more effectively than the mentioned traditional algorithms,and consequently improve recommendation accuracy of review experts.In this paper,we just consider the topic relationship between projects/experts, but we do not consider the influence relationship between them.Our further work will focus on the influence relationship between projects/experts.
REFERENCES
[1]Adomavicius G,Tuzhilin A.Toward the next generation of recommender systems:a survey of the state-of-the-art and possible extensions.IEEE Transactions on Knowledge and Data Engineering,2005,17(6):734-749
[2]Herlocker J L,Konstan J A,Borchers A,Riedl J.An algorithmic framework for performing collaborative filtering.In:Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,SIGIR’99.New York,NY,USA: ACM,1999.230-237
[3]Sarwar B,Karypis G,Konstan J,Riedl J.Item-based collaborative if ltering recommendation algorithms.In:Proceedings of the 10th International Conference on World Wide Web,WWW’01.New York,NY, USA:ACM,2001.285-295
[4]Ungar L H,Foster D P.Clustering methods for collaborative filtering.In: Proceedings of the 1998 Workshop on Recommender Systems.Menlo Park:AAAI,1998.114-129
[5]Getoor L,Sahami M.Using probabilistic relational models for collaborative filtering.In:Proceedings of the 1999 Workshop on Web Usage Analysis and User Profiling.San Diego:Springer-Verlag,1999.83-96
[6]Chien Y H,George E I.A Bayesian model for collaborative filtering.In: Proceedings of the 7th International Workshop on Artificial Intelligence and Statistics.San Francsico,CA:Morgan Kaufmann,1999.187-192
[7]Hofmann T.Collaborative filtering via Gaussian probabilistic latent semantic analysis.In:Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,SIGIR’03.New York,NY,USA:ACM,2003.259-266
[8]Sarwar B M,Karypis G,Konstan J A,Riedl J.Application of dimensionality reduction in recommender system—a case study.In:Proceedings of the 2000 ACM-SIGKDD Conference on Knowledge Discovery in Databases,Web Mining For E-Commerce Workshop,WEBKDD’2000. Boston,MA,USA:ACM,2000.1-12
[9]Hofmann T.Latent semantic models for collaborative filtering.ACM Transactions on Information Systems,2004,22(1):89-115
[10]Koren Y,Bell R,Volinsky C.Matrix factorization techniques for recommender systems.IEEE Computer,2009,42(8):30-37
[11]Salakhutdinov R,Mnih A.Probabilistic matrix factorization.In:Proceedings of the 2007 Conference on Advances in Neural Information Processing Systems 20.Vancouver,BC,CA:Curran Associates Inc., 2007.1257-1264
[12]Tak´acs G,Pil´aszy I,N´emeth B,Tikk D.Matrix factorization and neighbor based algorithms for the netflix prize problem.In:Proceedings of the 2008 ACM Conference on Recommender Systems.New York, NY,USA:Association for Computing Machinery,2008.267-274
[13]Zhen Y,Li W J,Yeung D Y.Tagicof i:tag informed collaborative filtering.In:Proceedings of the 3rd ACM Conference on Recommender Systems.New York,NY,USA:Association for Computing Machinery, 2009.69-76
[14]Zhou T C,Ma H,King I,Lyu M R.Tagrec:leveraging tagging wisdom for recommendation.In:Proceedings of the 12th IEEE International Conference on Computational Science and Engineering,CSE 2009. Vancouver,BC,CA:IEEE Computer Society,2009.194-199
[15]Ma H,Yang H X,Lyu M R,King I.SoRec:social recommendation using probabilistic matrix factorization.In:Proceedings of the 17th ACM Conference on Information and Knowledge Management,CIKM’08. New York,NY,USA:ACM,2008.978-991
[16]Ma H,King I,Lyu M R.Learning to recommend with social trust ensemble.In:Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval,SIGIR’09.New York,NY,USA:ACM,2009.203-210
[17]Jamali M,Ester M.TrustWalker:a random walk model for combining trust-based and item-based recommendation.In:Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,KDD’09.New York,NY,USA:ACM,2009.397-406
[18]Guo L,Ma J,Chen Z M,Jiang H R.Learning to recommend with social relation ensemble.In:Proceedings of the 21st ACM International Conference on Information and Knowledge Management,CIKM’12. New York,NY,USA:ACM,2012.2599-2602
[19]Wu L,Chen E H,Liu Q,Xu L L,Bao T F,Zhang L.Leveraging tagging for neighborhood-aware probabilistic matrix factorization.In: Proceedings of the 21st ACM International Conference on Information and Knowledge Management,CIKM’12.New York,NY,USA:ACM, 2012.1854-1858
[20]Blei D M,Ng A,Jordan M.Latent Dirichlet allocation.Journal of Machine Learning Research,2003,3(1):993-1022
[21]Zhang Y M.Research on Expert-level Network Relationships Construction Integrating Explicit and Implicit Relationships[Master dissertation], Kunming University of Science and Technology,China,2013.
[22]Tian W,Shen T,Yu Z T,Guo J Y,Xian Y T.A Chinese expert name disambiguation approach based on spectral clustering with the expert page-associated relationships.In:Proceedings of the 2013 Chinese Intelligent Automation Conference.Yangzhou,JS,China:Springer,2013. 245-253
[23]Jamali M,Ester M.A matrix factorization technique with trust propagation for recommendation in social networks.In:Proceedings of the 4th ACM Conference on Recommender Systems.New York,NY,USA: ACM,2010.135-142
[24]Koren Y.Factorization meets the neighborhood:a multifaceted collaborative filtering model.In:Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’08.New York,NY,USA:ACM,2008.426-434

Shengxiang Gao Ph.D.candidate at Kunming University of Science and Technology,Kunming, China.She received the bachelor degree in industrial automation and the M.S.degree in pattern recognition and intelligent system from Kunming University of Science and Technology in 2000 and 2005,respectively.Her research interests include nature language processing,machine translation,and information retrieval.

Zhengtao Yu Professor at the School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming,China.He received the Ph.D.degree in computer application technology from Beijing Institute of Technology, Beijing,China,in 2005.His research interests include natural language processing,machine translation,and information retrieval.Corresponding author of this paper.

Linbin Shi graduated from Jiangxi University of Science and Technology,China,in 2011.He received the M.S.degree in computer application technology from Kunming University of Science and Technology,China,in 2014.His research interests include natural language processing,machine translation,and information retrieval. Xin Yan Associate professor at the School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming, China.Her research interests include natural language processing,machine translation,and sentiment analysis.

Haixia Song graduated from North China University of Water Resources and Electric Power,China, in 2011.She received the M.S.degree in computer technology from Kunming University of Science and Technology,China,in 2014.Her research interests include natural language processing,sentiment analysis,and data mining.
I.INTRODUCTION
t
February 28,2014;accepted May 27,2015.This work was supported by National Natural Science Foundation of China (611750 68,61472168,61163004),Natural Science Foundation of Yunnan Province(2013FA130),and Talent Promotion Project of Ministry of Science and Technology(2014HE001).Recommended by Associate Editor Tiejun Zhao.
:Shengxiang Gao,Zhengtao Yu,Linbin Shi,Xin Yan,Haixia Song.Review expert collaborative recommendation algorithm based on topic relationship.IEEE/CAA Journal of Automatica Sinica,2015,2(4):403-411
Index Terms—Review expert recommendation,topic relationship,collaborative filtering,matrix factorization.
W ITH the development of society,all kinds of project presenting,establishing,quality checking,completing and other related activities are increasing in China.More and more projects need to be reviewed every year.At present, the selection of project review experts is mainly adopted by artificial means.The artificial selection not only requires that funding organizations are very familiar with project topics and review experts’research areas,but also brings about some disadvantages,such as high manpower cost,unfairness and so on.To avoid the drawbacks,it is very significant and essential to propose a solution that can automatically recommend experts for project review activities.
 IEEE/CAA Journal of Automatica Sinica2015年4期
IEEE/CAA Journal of Automatica Sinica2015年4期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Logic-based Reset Adaptation Design for Improving Transient Performance of Nonlinear Systems
- Security Risk Assessment of Cyber Physical Power System Based on Rough Set and Gene Expression Programming
- Security-aware Signal Packing Algorithm for CAN-based Automotive Cyber-physical Systems
- A Priority-aware Frequency Domain Polling MAC Protocol for OFDMA-based Networks in Cyber-physical Systems
- Function Observer Based Event-triggered Control for Linear Systems with Guaranteed L∞-Gain
- A Systematic Approach for Designing Analytical Dynamics and Servo Control of Constrained Mechanical Systems